概述
根据 Kubernetes 的设计规范,Pod 运行过程中若需要临时修改容器参数,只能更新
PodSpec 后重新提交,这种方式会触发 Pod 删除重建,很难满足业务侧应对流量突发时无损变配诉求。原生节点针对 Pod 的 CPU、内存提供原地升降配能力,通过对 API Server 和 Kubelet 进行升级改造,支持在不重启 Pod 的情况下修改 CPU、内存的 request/limit 值。本文主要介绍 Pod 资源原地更新功能的适用场景、工作原理和使用方式。前提条件
集群支持 Kubernetes 版本在 1.16~1.30 之间的原生节点,需同时保证小版本满足以下条件:
kubernetes-v1.16.3-tke.30 及以上
kubernetes-v1.18.4-tke.28 及以上
kubernetes-v1.20.6-tke.24 及以上
kubernetes-v1.22.5-tke.15及以上
kubernetes-v1.24.4-tke.7 及以上
kubernetes-v1.26.1-tke.2 及以上
kubernetes-v1.28.3-tke.17 及以上
kubernetes-v1.30.0-tke.12 及以上
说明:
由于和社区特性冲突,1.32 版本不支持通过设置 feature-gates = EnableInPlacePodResize=true 使用本文所述的 TKE 原地升降配功能。
1.34 及以上版本不支持 feature-gates = EnableInPlacePodResize=true 参数。Kubernetes 1.33 起,社区已将
InPlacePodVerticalScaling 特性升级为 Beta 并默认开启,TKE 1.34 及以上版本集群可直接使用社区原生的 Pod 原地调整资源能力,无需额外设置 feature-gates 参数。详情请参见 Kubernetes 原地调整 Pod 资源(Beta)。在创建节点的高级设置中设置自定义 kubelet 参数:feature-gates = EnableInPlacePodResize=true,如下图所示:

警告:
已有节点增加当前 feature-gates 参数后会触发节点上的 Pod 重启,建议预先评估对业务的影响后再执行。
适用场景
1. 应对流量突发,保障业务稳定性
场景描述:动态修改 Pod 资源参数功能适用于临时性的调整,例如当 Pod 内存使用率逐渐升高,为避免触发 OOM(Out Of Memory)Killer,在不重启 Pod 的前提下提高内存的 Limit。
推荐动作:提升 CPU/ 内存的 limit 值。
2. 满足业务降本诉求,提高 CPU 利用率
场景描述:为保障线上应用的稳定性,管理员通常会预留相当数量的资源 Buffer 来应对上下游链路的负载波动,容器的 Request 配置会远高于其实际的资源利用率,导致集群资源利用率过低,造成大量资源浪费。
推荐动作:降低 CPU/ 内存的 request 值。
使用限制
为优先保障业务 Pod 运行的稳定性,需要对 Pod 原地升降配能力进行一些操作限制:
1. 只允许修改 Pod 的 CPU 和 Memory 资源。
2. 只有
PodSpec.Nodename 不为空的情况下才能修改 Pod 资源。3. 资源修改范围:
Pod 内每个 Container 的 limit 值可以调高或者降低,降低 CPU 可能会导致业务降频,降低 Mem 可能失败(kubelet 会在随后的 syncLoop 中重试降低 Memory)。
Pod 内每个 Container 的 request 值可以调高 / 调低,但向上修改不能超过 Container 的 limit 值。
4. Container 未设置 request/limit 值场景:
没有设置 limit 值的 Container 不允许设定新值。
没有设置 request 值的 Container 向下变更配置时不允许低于100m。
5. 修改 request/limit 值不允许切换 QoS 类型,即不允许在 burstable/guaranteed 之间变化。升降配时需要同时修改 request 和 limit 以保证 QoS 不变。
6. 示例: [cpu-request: 30, cpu-limit: 50] 最多只能调整为 [cpu-request: 49, cpu-limit: 50],禁止调整为 [cpu-request: 50, cpu-limit: 50]。
工作原理
1. kubelet 将 Pod 当前的实际使用资源和变配状态以 JSON 格式存入 Annotation "tke.cloud.tencent.com/resource-status" 。其中 resizeStatus 字段代表升降配状态,详情请参见 升降配状态。
Annotations: tke.cloud.tencent.com/resource-status:{"allocatedResources":[{"limits":{"cpu":"500m","memory":"128Mi"},"requests":{"cpu":"250m","memory":"64Mi"}}],"resizeStatus":""}
2.
pod.spec.containers.resources 中的资源代表期望资源,即期望分配给 Pod 的资源。当期望资源被修改后,kubelet 会尝试修改 Pod 的实际资源,并将最终结果写入 Annotation 中。说明:
升降配状态
社区在高版本中的 Pod.Status 中添加了一些字段展示变配操作的状态,该状态同时和 kube-scheduler 配合来完成调度工作。TKE 原生节点将类似的字段放在 Pod 的 Annotation 中,其中包括 Pod 的真实资源以及当前升降配操作执行状态。
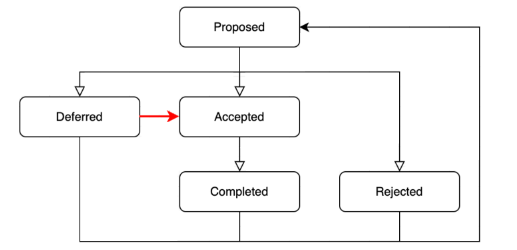
状态 | 描述 | 备注 |
Proposed | 代表该 Pod 升降配的操作请求被提交。 | - |
Accepted | 代表 kubelet 发现 Pod 资源被修改,且节点上的资源足够 Admit 这个升降配后的 Pod。 | - |
Rejected | 代表 Pod 升降配请求被驳回。 | 驳回原因:Pod 变配后 Request 的资源值大于节点的 Allocate 值。 |
Completed | 代表 Pod 资源被成功修改,并变配后的资源设置在了容器上。 | 该状态下展示的实际值为空,即 "resizeStatus":""。 |
Deferred | 代表由于某些问题当前升降配操作被推迟,推迟到 Pod 下次发生状态变化时再次触发变配。 | 可能出现的问题如下: 当前节点资源不够:节点 Allocate 资源量 - 其他 Pod 占用资源量 < 升降配 Pod 要求资源量。 状态落盘失败。 |
执行状态如下图所示:
案例演示
验证场景
正在运行的业务 Pod,将其内存 limit 值由 128Mi 提升至 512Mi,修改后 limit 值生效且 Pod 不重建。
验证步骤
1. kubectl 创建 pod-resize-demo.yaml 文件,YAML 内容如下所示。内存设定的 request 值为64Mi,limit 值为128Mi。
# Kubectl 命令:kubectl apply -f pod-resize-demo.yaml
apiVersion: v1kind: Podmetadata:name: demonamespace: defaultspec:containers:- name: appimage: ubuntucommand: ["sleep", "3600"]resources:limits:memory: "128Mi"cpu: "500m"requests:memory: "64Mi"cpu: "250m"
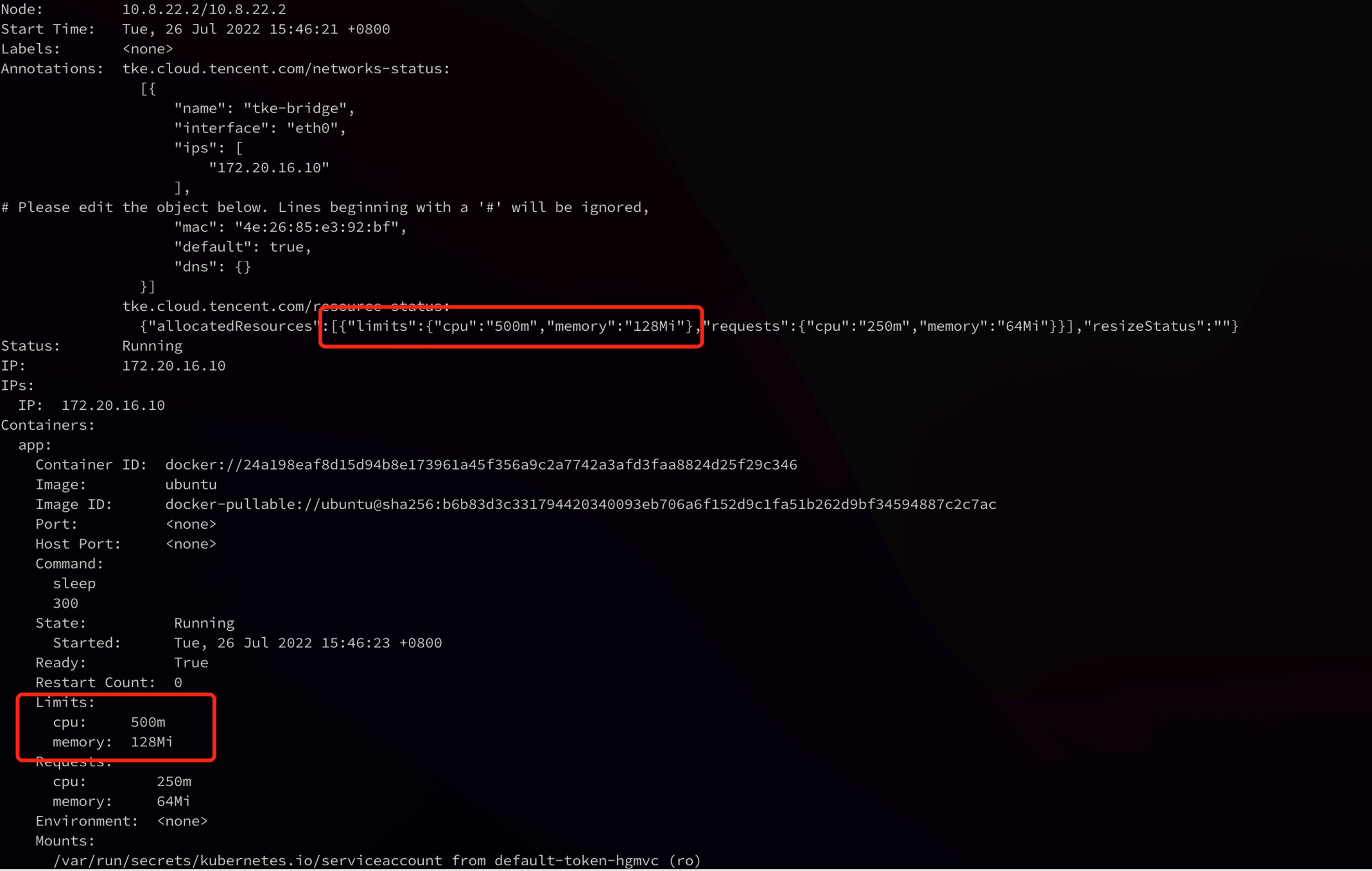
2. 查看待变配 Pod 的 Resource 值。
# Kubectl 命令:kubectl describe pod -n default demo
如下图所示,可变配 Pod 的 Annotation 中会有 tke.cloud.tencent.com/resource-status 字段,它标记了当前 Pod 实际使用资源和 Pod 的变配状态,Pod 的期望资源值会标记在每个 container 上。
3. 更新 Pod 配置:以提高 Pod 内存 Limit 值为例,kubectl 修改字段
pod.spec.containers.resources.limits.memory(由 128Mi 提升至 512Mi)。# Kubectl 命令:kubectl edit pod -n default demo
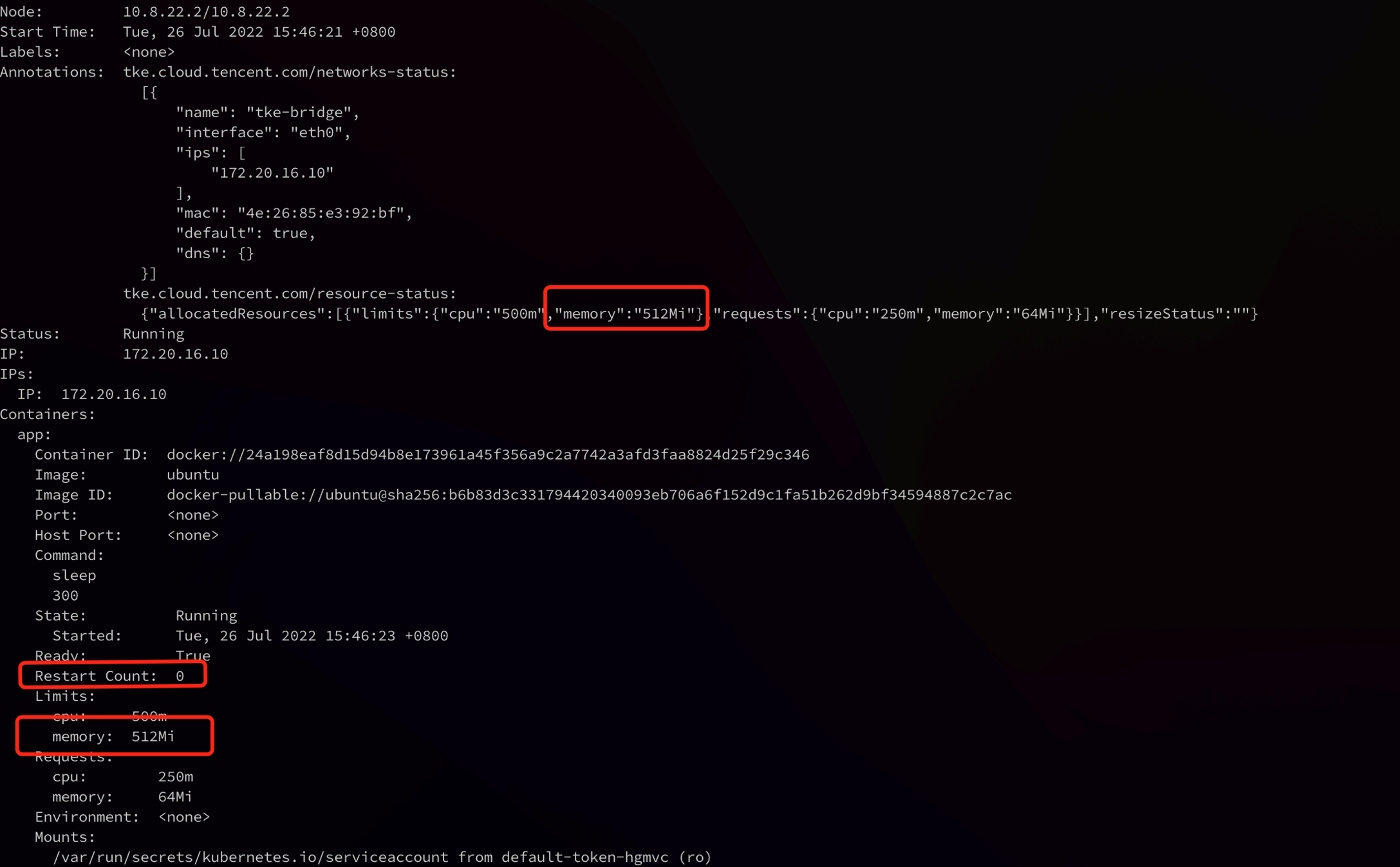
4. 执行以下命令,查看 Pod 运行情况。
# Kubectl 命令:kubectl describe pod -n default demo
如下图所示,Pod spec 中的资源和 Annotation 中的资源都变成了预期值“512Mi”,同时 Restart Count 为 0。
5. Pod 原地变配验证:登录到部署了该 Pod 的服务器然后通过 docker 或 ctr 命令找到容器后,可以发现容器的元数据对于 memory 的限制已经被修改;同时,进入 memory cgroup 会发现对于内存的限制也被改成了期望值“512Mi”。
docker inspect <container-id> --format "{{ .HostConfig.Memory }}"
find /sys/fs/cgroup/memory -name "<container-id>*"
cat <container-memory-cgroup>/memory.limit_in_bytes
如下图所示:




