功能概述
算力消耗防护是 WAF 大模型安全模块的基础能力,用于降低恶意用户或 Bot 通过高频调用、超长上下文等手段大量消耗您的大模型算力资源(GPU 推理、Token 额度)的风险,避免业务成本异常增长或影响正常用户体验。
本能力通过请求频次和 Token 消耗量两个维度对访问行为进行协同管控,命中规则后可选择观察或拦截两种处置动作。
若不启用算力消耗防护,您可能面临以下风险:
单个用户在短时间内刷取数百万 Token,导致账单激增。
Bot 批量注册账号,消耗免费额度。
慢速请求占用模型并发资源,影响正常用户体验。
操作场景
本文介绍如何通过算力消耗规则限制大模型接口的调用频次和 Token 消耗量。
前提条件
操作步骤
1. 登录 Web 应用防火墙控制台,在左侧导航栏,选择大模型安全 > 防护配置 > 算力消耗规则。
2. 在算力消耗规则页签,单击添加规则。
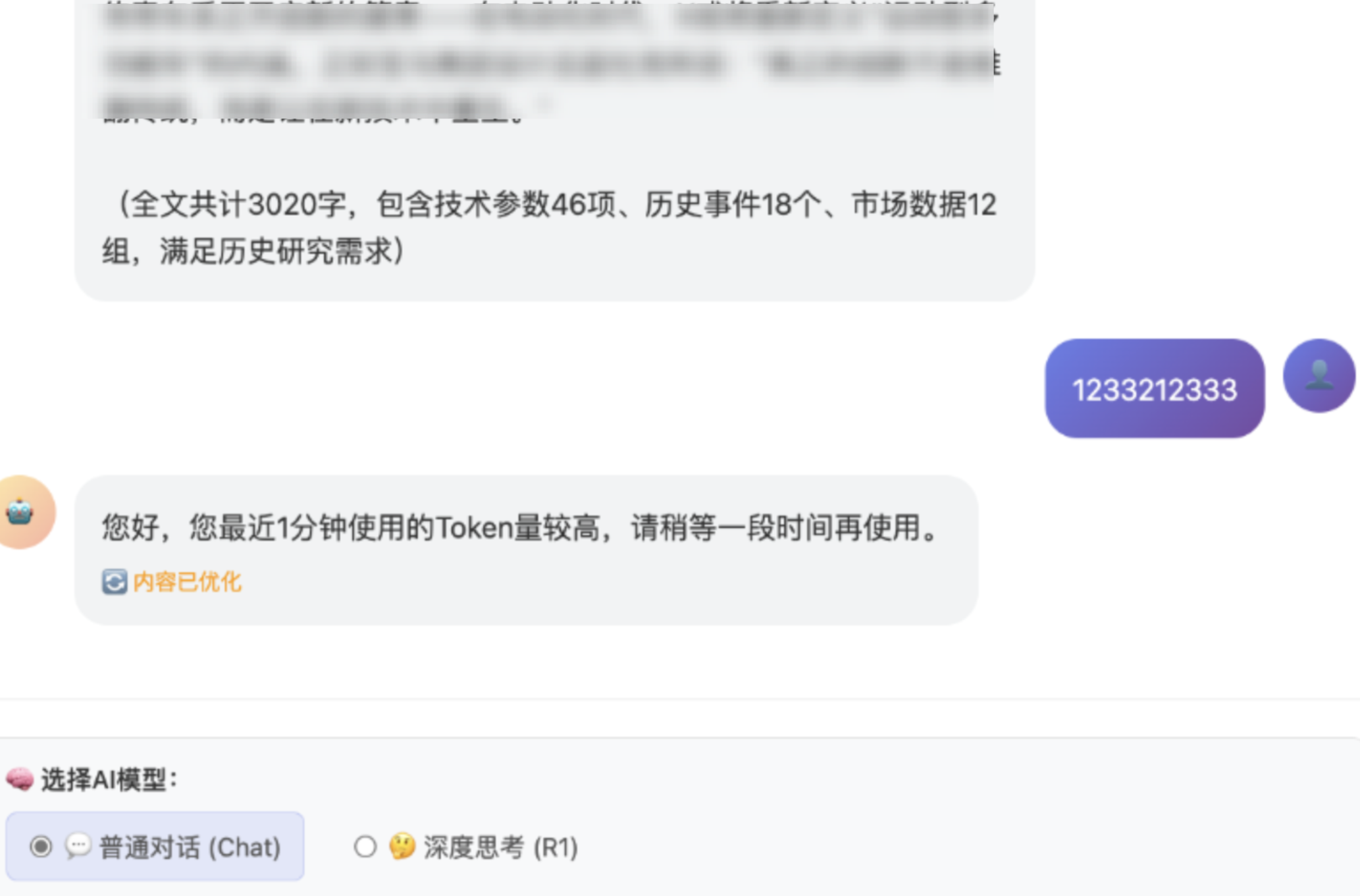
3. 在添加算力消耗防护规则窗口中,进行信息配置:
参数说明
字段名称 | 说明 |
规则名称 | 设置规则名称。 |
会话标识 | 选择此前配置的会话标识,用于区分不同用户,实现对单个用户的精准算力消耗检测。 说明: 使用 SDK/API 接入方式时,无需配置该参数。 |
默认需要选择 LLM 业务匹配方式,选择添加的 LLM 业务防护路径配置。 说明: 单条规则中不同匹配方式为 “与” 关系。 使用 SDK/API 接入方式时,无需配置该参数。 | |
防护规则 | 基于请求频次的防护:统计单个用户 ID 在单位时间(1 分钟、5 分钟、10 分钟、30 分钟、60 分钟、6 小时、12 小时、24 小时、每整点小时、每自然天,值为 2-100000,值必须为整数)内的请求次数。 基于 token 消耗量的防护:根据业务类型配置单个用户 ID 在单位时间(1 分钟、5 分钟、10 分钟、30 分钟、60 分钟、6 小时、12 小时、24 小时、每整点小时、每自然天)内的总 Token 消耗量。负载均衡型 WAF 接入的域名暂不支持此功能。 |
执行动作 | WAF 支持针对算力超量用户实现两种处置方式: 观察:仅记录日志。 拦截 当选择类型为基于请求频次的防护:在检测到用户超量后,将阻断用户发往源站的请求,并返回 WAF 默认拦截提示页面,可以前往基础安全修改默认拦截提示页面的内容。 当选择类型为基于 token 消耗量防护:在检测到用户超量后,WAF 会中断源站对用户的响应,并在返回的 data 中插入自定义提示内容,可以配置返回给用户的提示内容。 WAF 拦截时,如果是请求拦截,返回 WAF 默认拦截提示页面,可以前往基础安全修改默认拦截提示页面的内容。如果是响应拦截,除了会在返回的 data 中插入自定义提示内容配置以外,还会在返回的 data 数据中插入一个 uuid 字段以及 uuid 值,为了更好的拦截体验,也可以对业务前端进行逻辑修改,在检测到返回字段中存在 uuid 字段时,调整实际拦截效果。 |
优先级 | 配置规则优先级。优先级逻辑:请输入1-100的整数,数字越小,代表这条规则的执行优先级越高;相同优先级下,更新时间越晚,优先级越高。 |
匹配方式
参数类型 | 支持逻辑符号 | 说明 |
请求 Header 参数值 | 内容为空、存在、不存在、包含、不包含、属于、不属于、前缀匹配、后缀匹配 | 可设置多个匹配值(通过换行分隔),用于识别特定请求头的特征值。 |
GET 参数值 | 内容为空、存在、不存在、包含、不包含 | 支持对 GET 请求参数值的空值、存在性及内容特征匹配。 |
POST 参数值 | 内容为空、存在、不存在、包含、不包含 | 支持对 POST 请求参数值的空值、存在性及内容特征匹配。 |
Cookie 参数值 | 内容为空、存在、不存在、包含、不包含、属于、不属于、前缀匹配、后缀匹配 | 支持对 Cookie 值的空值、存在性、内容特征及前后缀规则匹配。 |
Referer 参数值 | 内容为空、存在、不存在、包含、不包含、属于、不属于、前缀匹配、后缀匹配 | 支持对来源链接(Referer)的空值、存在性、内容特征及前后缀规则匹配。 |
访问源 IP | 属于、不属于 | 支持对客户端 IP 地址的归属范围匹配(需填写具体 IP 段或地址)。 |
IP 归属地 | 属于、不属于 | 支持对 IP 地址所属地域的匹配(可选择国内/国外具体地区,支持多地区组合配置)。 |
会话 ID | 属于、不属于 | 支持对会话 ID 的归属范围匹配(需填写具体会话 ID 或通过换行分隔多个 ID)。 |
User-Agent | 属于、不属于 | 支持对用户代理(User-Agent)的归属范围匹配(需填写具体 UA 标识或通过换行分隔多个标识)。 |
为优化拦截体验,提供更好的交互体验,以下提供业务前端针对大模型安全拦截逻辑修改的示例代码,该示例代码基于 Deepseek 接口格式,可参考嵌入业务前端代码中,实现与大模型安全的防护逻辑联动:
拦截机制说明:
请求方向拦截:大模型安全对于请求方向的拦截方式为同步拦截,客户端发送请求后,服务器对请求进行风险检查(如敏感词)。若触发拦截,直接返回大模型安全预设的拦截页面(不会使用规则中的自定义拦截提示内容),如业务前端需处理拦截效果,只需调整业务前端对于响应状态码和状态提示的效果。
响应方向拦截:大模型安全对于响应方向的拦截方式为异步拦截,服务器在流式输出内容时,大模型安全同步检测风险。触发拦截时:
大模型安全会中断流式内容输出。
在响应数据中添加 uuid 字段,并在定义的响应内容字段中,插入规则配置的自定义拦截提示内容。
如业务前端需处理拦截效果,可以通过检测 uuid 字段的存在性,判断拦截状态,并调整业务前端的拦截效果:
若未识别到 uuid 字段:正常展示内容。
若识别到 uuid 字段:可以清空已输出内容,重置显示为大模型安全插入的自定义提示内容。
请求方向拦截
默认拦截提示页面处理,效果为展示拦截提示的内容到聊天窗口,示例代码如下:
if (!initResponse.ok) {const errorText = await initResponse.text();console.error('API错误响应:', errorText);removeMessage(responseMessageId); // 移除正在显示的消息容器// 解析服务器返回的错误信息let errorMessage = '';try {const errorData = JSON.parse(errorText);errorMessage = errorData.error?.message || errorData.message || errorText;} catch (e) {errorMessage = errorText;}// 显示错误消息到聊天界面addMessage(errorMessage, 'error');updateStatus('请求失败', 'error');return;}
响应方向拦截
data 数据中插入自定义提示内容、uuid 字段的替换和展示处理,效果为重置掉当前已返回的内容,并展示自定义提示内容,示例代码如下:
// UUID检测处理 - 基于代码逻辑if (parsed.uuid) {console.log('🚨 检测到内容替换信号!');console.log('原始数据:', parsed);console.log('替换前内容:', fullContent);// 从服务器返回的数据中提取新内容let newContent = '';if (parsed.choices && parsed.choices[0] && parsed.choices[0].delta && parsed.choices[0].delta.content) {newContent = parsed.choices[0].delta.content;console.log('✅ 从 choices[0].delta.content 获取内容:', newContent);} else if (parsed.content) {newContent = parsed.content;console.log('✅ 从 content 获取内容:', newContent);} else {console.log('⚠️ 在数据中找不到 content');}// 完全重置已显示的内容fullContent = newContent;reasoning = '';contentWasReplaced = true;// 清空当前显示内容并重新显示服务器返回的新内容if (selectedModel === 'deepseek-reasoner') {// R1模式:清空思考过程和答案,显示新内容clearR1Message(responseMessageId);updateR1StreamingMessage(responseMessageId, '', fullContent, false);addContentReplacedIndicator(responseMessageId);} else {// 普通模式:清空消息,显示新内容clearStreamingMessage(responseMessageId);updateStreamingMessage(responseMessageId, fullContent, true);addContentReplacedIndicator(responseMessageId);}console.log('✅ 内容替换完成,当前 fullContent:', `"${fullContent}"`);// 停止处理后续数据流shouldStopProcessing = true;console.log('🛑 设置停止处理标记,不再处理后续数据');}
4. 完成上述所有参数设置后,请仔细检查,确认无误后,打开规则开关,单击确定提交配置,该规则即可生效,对算力资源进行防护。
算力消耗防护场景示例
1. 参考 业务接入,接入大模型业务并完成会话标识、大模型防护路径配置。
2. 登录 Web 应用防火墙控制台,在左侧导航栏,选择大模型安全 > 防护配置 > 算力消耗规则。
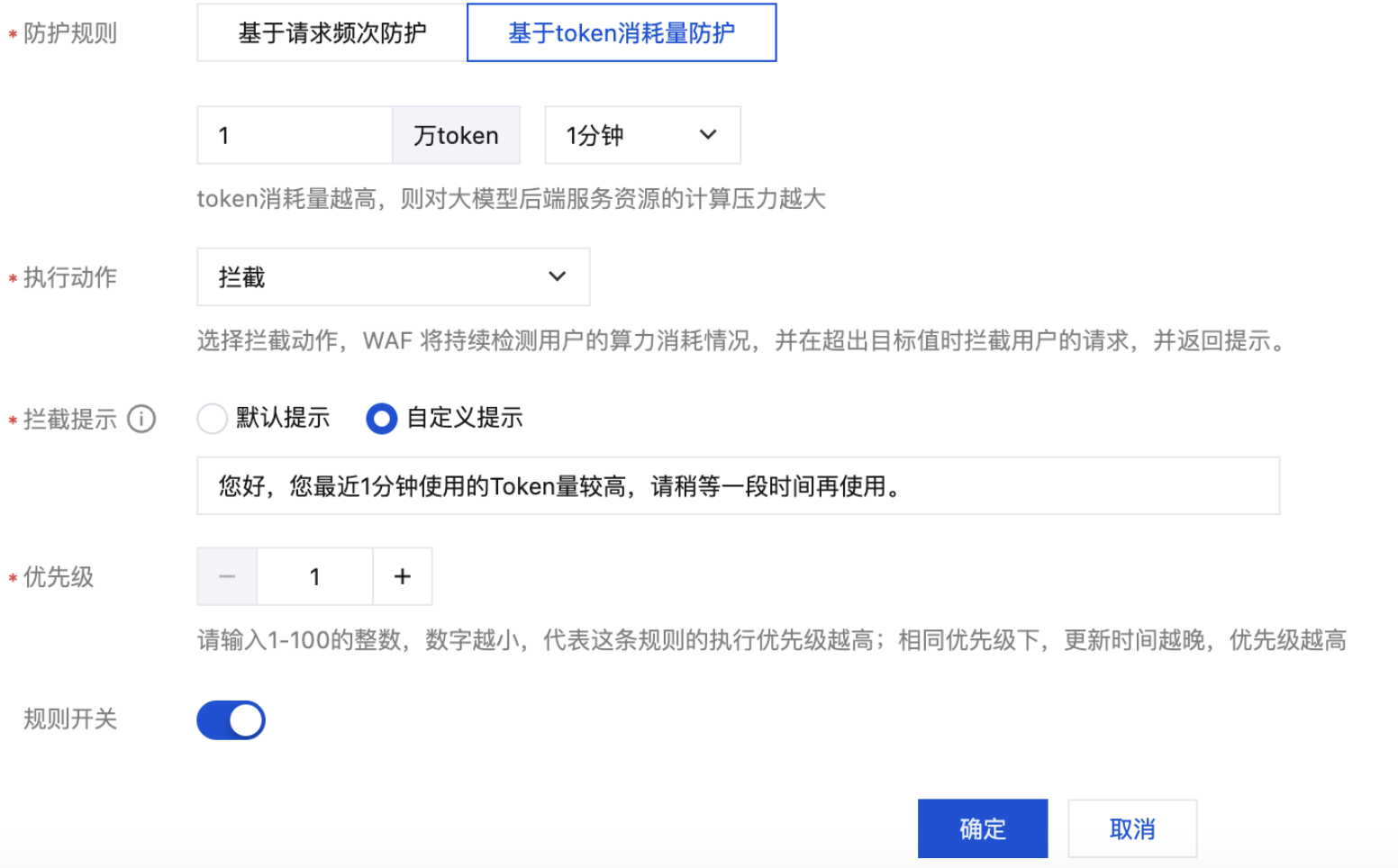
3. 在算力消耗规则页面,单击添加规则,配置一条高频请求拦截示例规则,设置为 1 分钟请求超过 1 万 token,超出后拦截,并返回自定义提示词,单击确定。
字段名称 | 说明 |
防护规则 | 配置基于 token 消耗量防护,并配置检测值为 1 万 token 每分钟。 |
执行动作 | 拦截。 |
拦截提示使用自定义提示 | 您好,您最近 1 分钟使用的 Token 量较高,请稍等一段时间再使用。 |
优先级 | 1。 |
规则开关 | 开启。 |
4. 在大模型业务侧,请求大模型输出 2 篇 3000 字的文章,即可触发算力消耗拦截,并在用户侧返回拦截提示语。如果大模型输出速率较慢,也可以调整为 5 分钟请求超过 1 万 token,以便更便捷地完成场景验证。