方案概述
基于腾讯云 RTC 全球传输网络,AI 智能语音服务提供语音转文本(ASR)、多语言实时翻译及文本转语音(TTS)的全链路语音处理能力,支持多种场景灵活使用。
通过 ASR 语音识别引擎,可高效将语音转化为文本,广泛应用于直播实时字幕、会议内容记录、视频通话与语聊房转写、录音文件离线转写等场景。
在语音转文本的基础上,实时翻译能力可实现跨语言内容的同步转写与沟通。
TTS 文本转语音技术,可将文本转化为自然流畅的语音输出,轻松构建语音播报、智能客服回复、无障碍朗读等多样化应用。
实时语音场景
TRTC 接入(实时会议、实时通话等):音频流经过 TRTC 全球网络节点传输到服务端进行音频处理后,由语音识别引擎(ASR)将语音转写为文本。支持多语种、热词权重配置、VAD 检测以及流式识别。对于需生成字幕或实时内容记录的场景,在此流程即可直接输出最终转写结果回调。 针对跨语言理解的场景,可在语音转写的基础上选择开启翻译功能。系统会将转写后的文本通过 LLM 翻译引擎进行翻译处理,支持同时输出转写内容和多语种翻译结果。
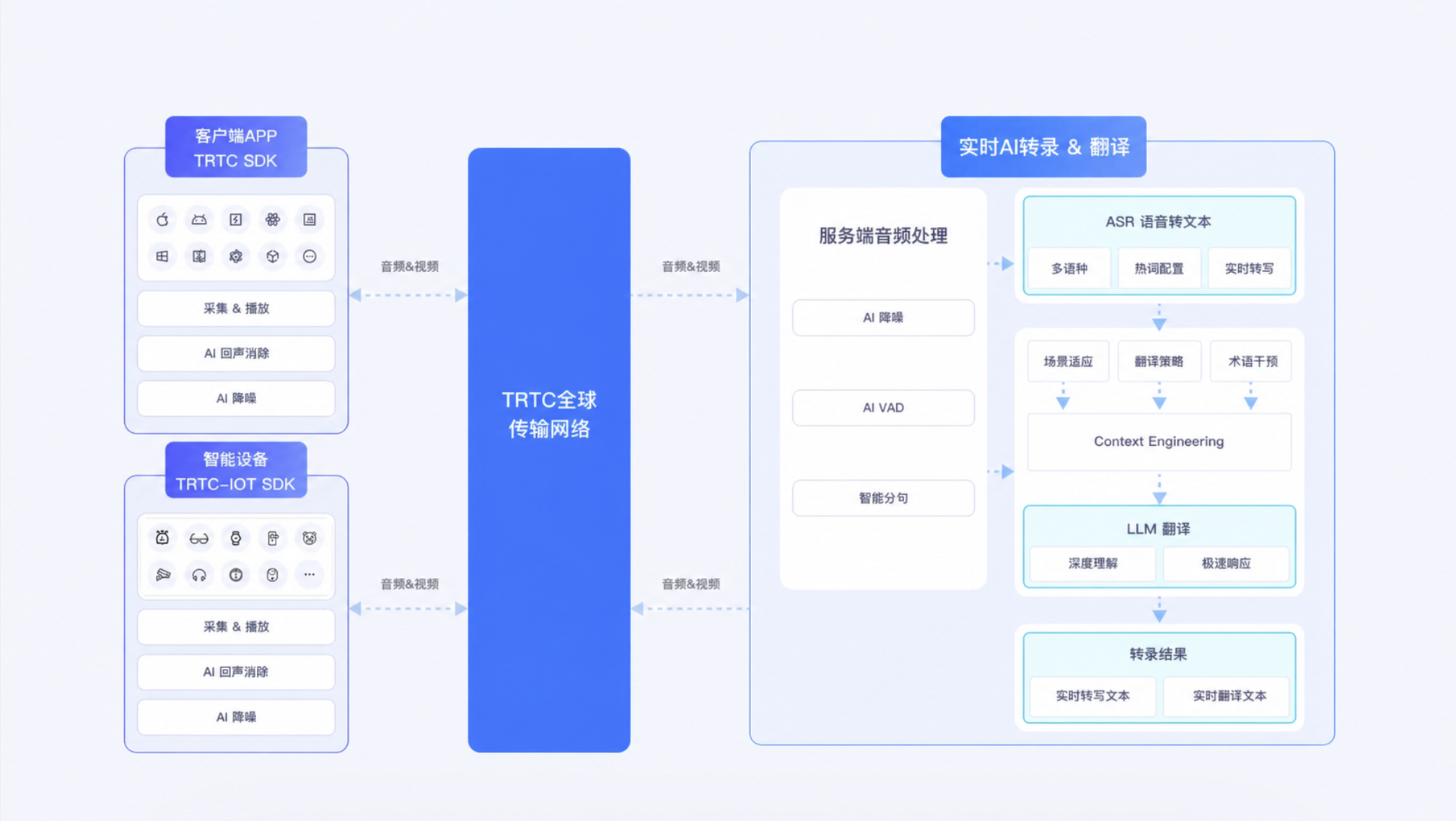
WebSocket 接入(物联设备等):物联设备可通过 WebSocket 长连接接入服务,支持流式音频双向传输,集成流式语音识别、流式语音合成能力。设备持续上传音频流即可实时返回识别文本,下发文本可即时回传合成语音流,满足物联网终端低时延实时语音交互业务需求。
其他场景
一句话识别(IM 消息): 适用于 60s 以内的音频,支持中文普通话、英语、粤语、多地方言,也支持日语、韩语、法语、西班牙语等小语种。
录音文件识别(TRTC 会议录制文件):适用于长音频场景的离线转写,支持中文普通话、英语、粤语、多地方言,也支持日语、韩语、法语、西班牙语等小语种。
一、语音转文本(ASR)
1. 实时语音识别
支持的语音引擎和语种见下表。
功能 | 版本类型 | 特性说明 | 语种与模型型号 |
实时语音识别 | 基础版语言引擎 | 基础通用语音识别模型。在近场、非复杂噪声的声学环境下具备良好的响应速度与识别准确率。 | "zh":8k 采样率中文识别模型,主要用于电话音频。 |
标准版语言引擎 | 基于大模型引擎,语音识别性能大幅增强,在噪声回音大、人声远小等复杂音频环境的识别准确率显著提升。 常见应用场景如会议、直播、语聊、游戏等实时字幕以及实时转写记录等。高度契合 RTC 实时互动相关场景。 | "8k_zh_large":8k 中文大模型引擎,针对电话音频支持较好。 "16k_zh_large":16k 大模型引擎, 同时支持中文、英文、多种中文方言口音等语言的识别。 "16k_zh_en":最新 16k 中英大模型引擎, 同时支持中文、英语、多种中文方言口音的识别,对中英混说场景识别更优。 | |
高级版语言引擎 | 覆盖小语种、方言的精准识别需求。 | 越南语、日语、韩语、 印度尼西亚语、泰语、葡萄牙语、土耳其语、 阿拉伯语、西班牙语、印地语、法语、马来语、菲律宾语、德语、意大利语、俄语、瑞典语、丹麦语、挪威语、中国粤语 | |
V2 | 基于大模型引擎,在含噪音,专有名词、方言、小语种等音频环境的识别准确率显著提升。 | bigmodel:可支持中文普通话、中英混、方言和小语种,包括:zh(中文)、en(英语)、yue(粤语)、ar(阿拉伯语)、de(德语)、fr(法语)、es(西班牙语)、pt(葡萄牙语)、id(印尼语)、it(意大利语)、ko(韩语)、ru(俄语)、th(泰语)、vi(越南语)、ja(日语)、tr(土耳其语)、hi(印地语)、ms(马来语)、nl(荷兰语)、sv(瑞典语)、da(丹麦语)、fi(芬兰语)、pl(波兰语)、cs(捷克语)、fil(菲律宾语)、fa(波斯语)、el(希腊语)、ro(罗马尼亚语)、hu(匈牙利语)、mk(马其顿语)。 |
说明:
上文表格中列出的“模型型号”参数值对应配合 TRTC 使用时转录服务端 API 接口
AsrParam 中的 Lang 字段,完整的参数说明请参阅 服务端转录 API 说明。通过含 UI 的场景方案接入或者 SDK 客户端接入转录功能无需填写模型型号,仅需填写语种参数。ASR 默认中英使用标准版 16k_zh_en 模型。
2. 录音文件识别
通过 REST API 上传音频文件进行离线识别。
功能 | 语种与模型型号 |
录音文件识别 | "zh":8k 采样率中文识别模型,主要用于电话音频。 "16k_zh_en":最新 16k 中英大模型引擎, 同时支持中文、英语、多种中文方言口音的识别,对中英混说场景识别更优。 bigmodel:可支持中文普通话、中英混、方言和小语种,包括:zh(中文)、en(英语)、yue(粤语)、ar(阿拉伯语)、de(德语)、fr(法语)、es(西班牙语)、pt(葡萄牙语)、id(印尼语)、it(意大利语)、ko(韩语)、ru(俄语)、th(泰语)、vi(越南语)、ja(日语)、tr(土耳其语)、hi(印地语)、ms(马来语)、nl(荷兰语)、sv(瑞典语)、da(丹麦语)、fi(芬兰语)、pl(波兰语)、cs(捷克语)、fil(菲律宾语)、fa(波斯语)、el(希腊语)、ro(罗马尼亚语)、hu(匈牙利语)、mk(马其顿语)。 |
3. 一句话识别
通过 REST API 上传 60 秒以内的短音频,同步返回识别结果。适用于语音指令、语音搜索等短语音场景。
功能 | 语种与模型型号 |
一句话识别 | "zh":8k 采样率中文识别模型,主要用于电话音频。 "16k_zh_en":最新 16k 中英大模型引擎, 同时支持中文、英语、多种中文方言口音的识别,对中英混说场景识别更优。 bigmodel:可支持中文普通话、中英混、方言和小语种,包括:zh(中文)、en(英语)、yue(粤语)、ar(阿拉伯语)、de(德语)、fr(法语)、es(西班牙语)、pt(葡萄牙语)、id(印尼语)、it(意大利语)、ko(韩语)、ru(俄语)、th(泰语)、vi(越南语)、ja(日语)、tr(土耳其语)、hi(印地语)、ms(马来语)、nl(荷兰语)、sv(瑞典语)、da(丹麦语)、fi(芬兰语)、pl(波兰语)、cs(捷克语)、fil(菲律宾语)、fa(波斯语)、el(希腊语)、ro(罗马尼亚语)、hu(匈牙利语)、mk(马其顿语)。 |
二、实时翻译
功能 | 版本类型 | 特性说明 | 语种与模型型号 |
实时翻译 | 实时翻译引擎 | 基于最新大语言模型技术的深度语义理解能力,系统能够自主适应目标语言表达习惯,实现自然流畅翻译效果。相较于传统翻译,翻译结果的机械感显著降低,在非正式标准的口语对话交流、泛娱互动等复杂场景下的效果提升明显。 | 支持15种语言翻译:中文、英语、西班牙语、葡萄牙语、法语、德语、俄语、阿拉伯语、日语、韩语、越南语、马来语、印度尼西亚语、意大利语、泰语。 |
三、文字转语音(TTS)
支持语言:中文、英语、日语及粤语
声音克隆:基于少量音频样本生成专属音色
计费方式
接入方式
TRTC AI 智能语音解决方案支持以下接入方式:
场景(含 UI)方案接入:目前已经支持 视频通话 AI 实时字幕和翻译 方案和 多人会议 AI 实时字幕和翻译 方案。助力快速上线含 UI 的场景化实时转录功能。
通过 API 调用 ASR / TTS 能力,适用于自有音频采集链路或仅需单点能力的场景:
应用场景
应用场景 | 使用方式与价值 |
在线教育 | 通过 AI 转录对讲师与学员发言实时转写,课上提供实时字幕辅助理解,同步实时沉淀课程笔记与关键发言,可用于实时总结,课后复习、回放、存档。开启翻译功能后,可支持多语课堂或跨国教学场景。 |
社交娱乐 | 在社交娱乐场景中,通过 AI 转录能够对在线直播、游戏语聊、互动问答等场景,对发言内容进行实时转写,为观众提供准确字幕增强理解。同时支持输出多语言翻译内容,让不同地区用户能够更自然地参与互动。 |
办公协作 | 在线会议、线上面试、商务沟通、研讨会等场景下,通过 AI 转录生成实时字幕与内容记录,会中提升理解效率,会后可用于内容纪要整理。开启翻译功能后,可同时输出多语言转写,支持跨国团队无障碍协作。 |
客服中心 | 在线客服、智能外呼、呼叫中心等场景中,通过实时转写帮助客服准确理解用户内容。通话结束后沉淀完整文本记录,用于质检、合规与服务分析。开启翻译功能后,支持客服快速处理跨语言咨询,提高响应效率。 |
有声内容与语音播报 | 通过 TTS 将文本内容转换为自然语音,适用于新闻播报、有声读物、通知朗读、无障碍播报等场景。支持多音色切换和声音克隆,满足个性化语音输出需求。 |



