《Python自然语言处理》-- 1. 概述(笔记)

《Python自然语言处理》-- 1. 概述(笔记)

爱学习的程序媛
发布于 2023-01-03 20:21:05
发布于 2023-01-03 20:21:05

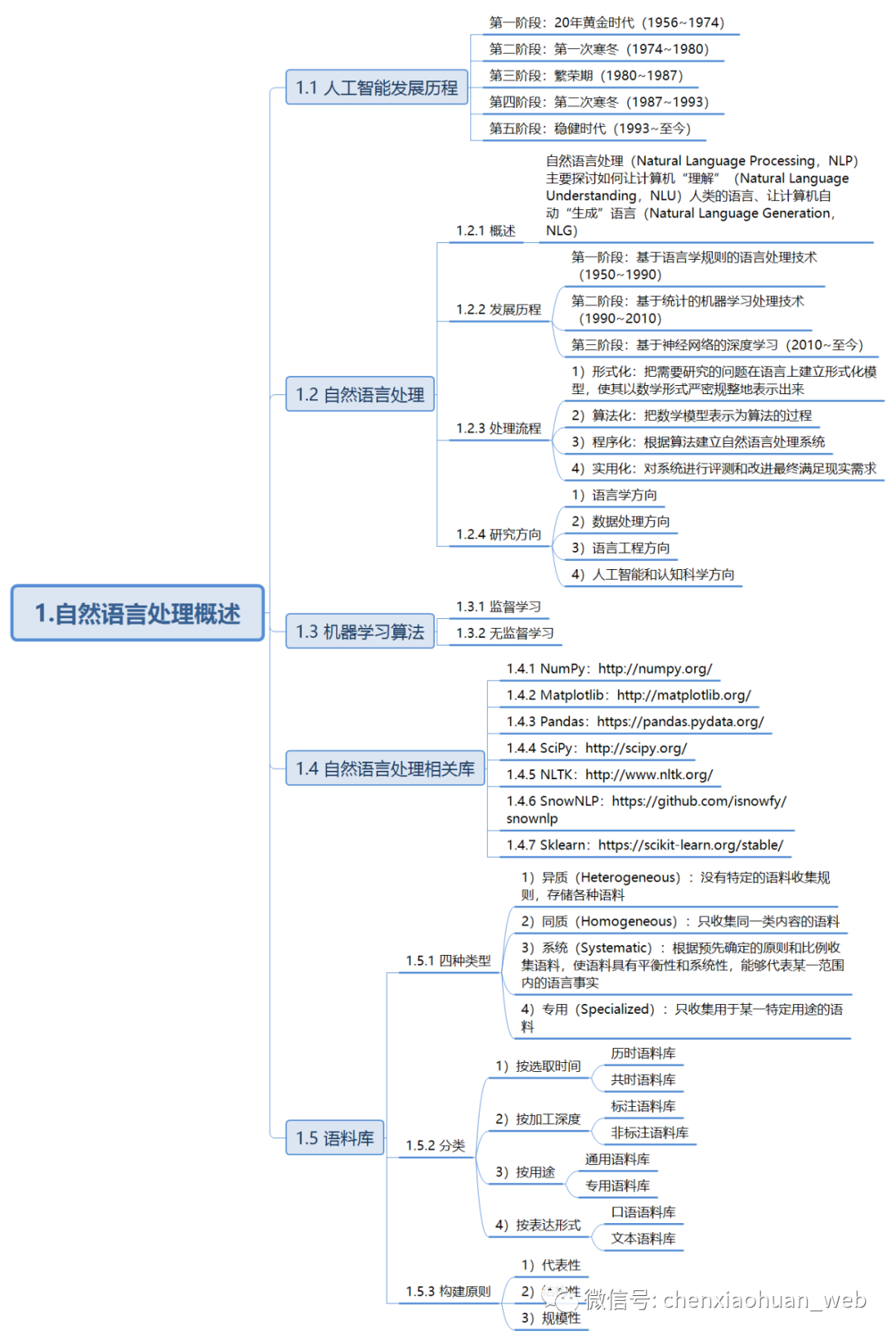
1.1 人工智能发展历程
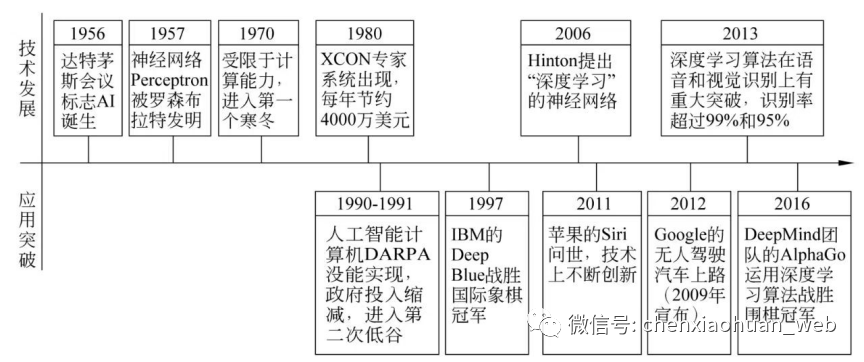
1.2 自然语言处理
1.2.1 概述
自然语言和编程语言对比:

自然语言处理是一门融合了计算机科学、人工智能及语言学的交叉学科,研究如何通过机器学习等技术,让计算机学会处理人类语言、理解人类语言。
1.2.2 发展历程
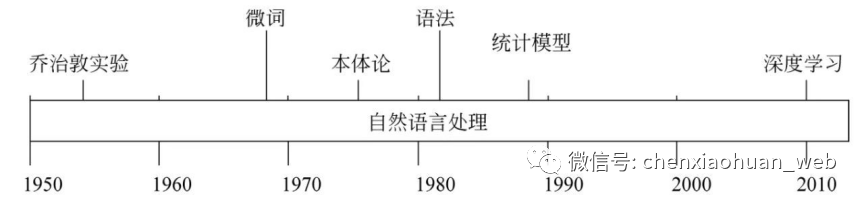
1.2.3 处理流程
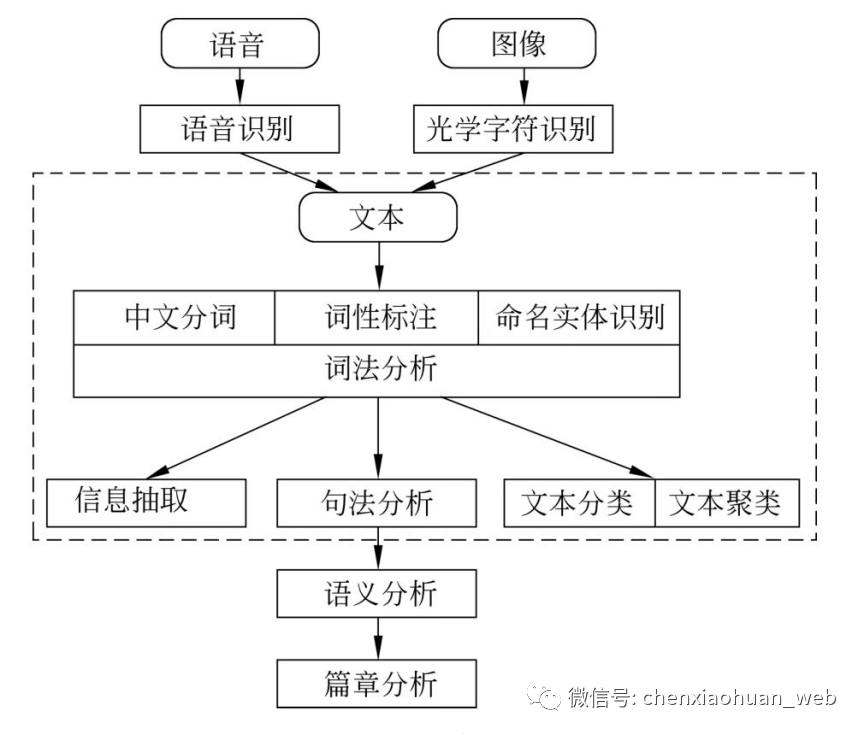
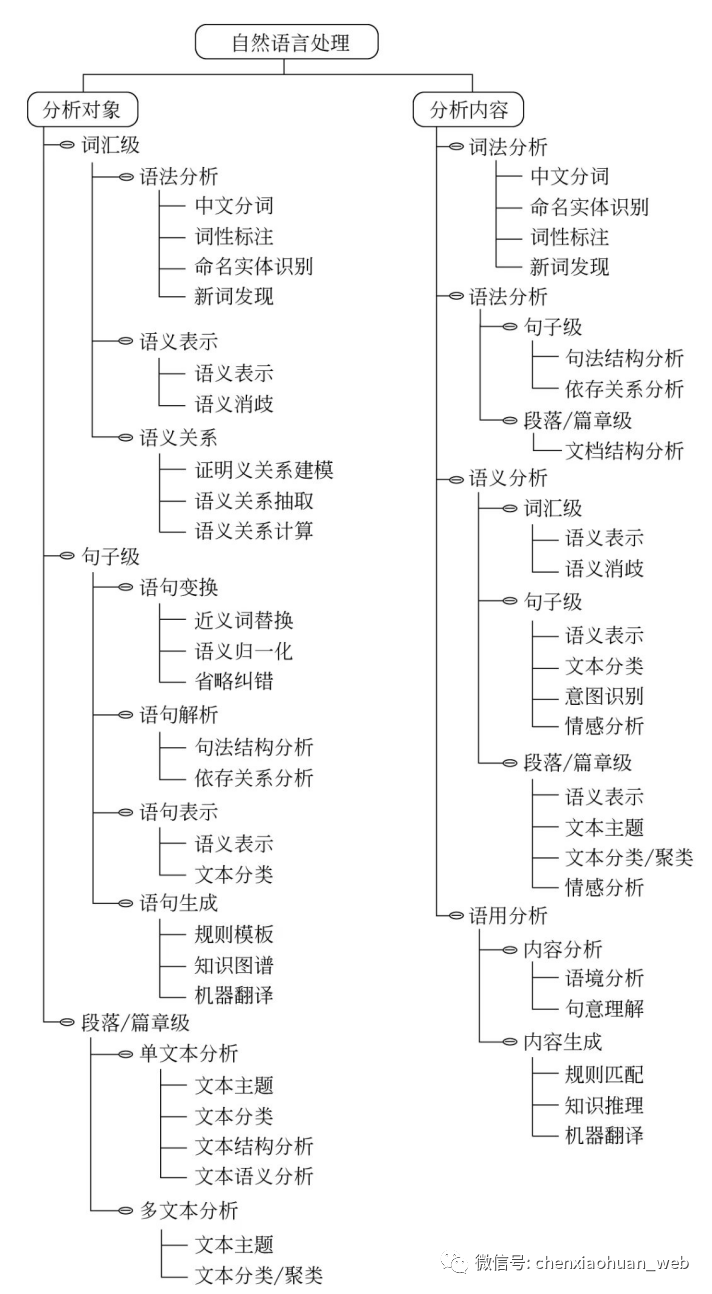
1.2.4 研究内容
1)句法语义分析:对于给定的句子,进行分词、词性标记、命名实体识别和链接、句法分析、语义角色识别和多义词消歧;
2)信息抽取:从给定文本中抽取重要的信息,如时间、地点、人物等,涉及实体识别、时间抽取、因果关系抽取等关键技术;
3)文本挖掘:包括文本聚类、分类、信息抽取、摘要、情感分析以及对挖掘的信息和知识的可视化、交互式的表达界面;
4)机器翻译:把输入的源语言文本通过自动翻译获得另外一种语言的文本,可分为文本翻译、语音翻译、图形翻译等;
5)信息检索:对大规模的文档进行索引,在查询时,对表达式的检索词或者句子进行分析,在索引里面查找匹配的候选文档,通过排序机制把候选文档排序,输出得分最高的文档;
6)问答系统:对自然语言查询语句进行某种程度的语义分析,包括实体链接、关系识别,形成逻辑表达式,在知识库中查找可能的候选答案,通过排序机制找出最佳的答案;
7)对话系统:系统通过一系列的对话,跟用户进行聊天、回答、完成某一项任务,涉及用户意图理解、通用聊天引擎、问答引擎、对话管理等技术。
1.3 机器学习算法
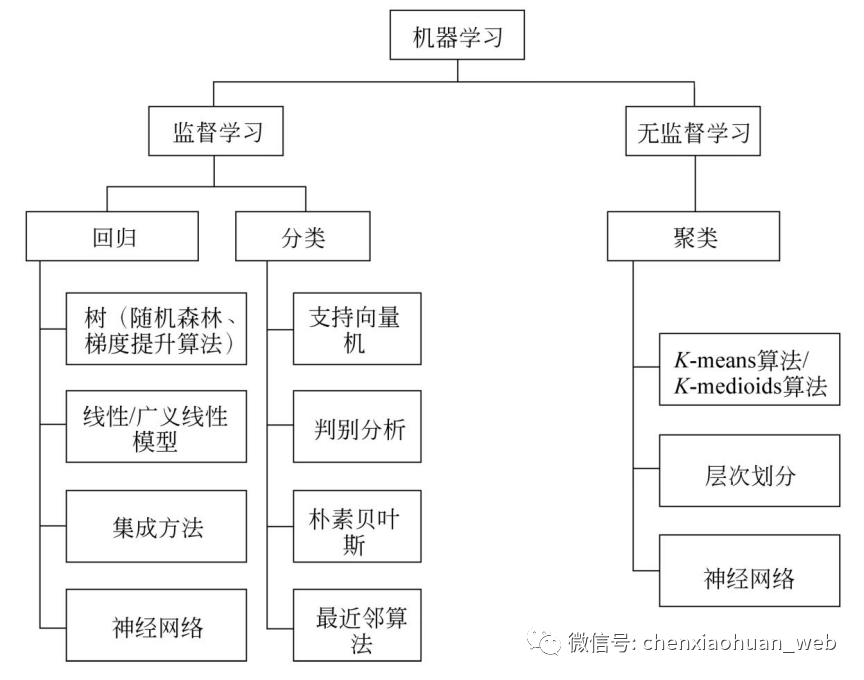
1.3.1 机器学习分类
1.3.2 机器学习模式总结
1.4 自然语言处理相关库
1.4.1 NumPy
NumPy 是 Python 数据分析的基本库,是在 Python 的 Numeric 数据类型的基础上,引入 Scipy 模块中针对数据对象处理的功能,用于数值数组和矩阵类型的运算、矢量处理等。
官网:http://numpy.org/
1.4.2 Matplotlib
Matplotlib 发布于2007年,用于将数据进行可视化,可以绘制线图、直方图、饼图、散点图以及误差线图等各种图形。
官网:http://matplotlib.org/
1.4.3 Pandas
Pandas 作为 Python 进行数据分析和挖掘时的数据基础平台和事实上的工业标准,功能非常强大,支持关系型数据的增、删、改、查,具有丰富的数据处理函数,支持时间序列分析功能,可以灵活处理缺失数据等。
官网:https://pandas.pydata.org/
1.4.4 SciPy
SciPy 是2001年发行的类似于 Matlab 和 Mathematica 等数学计算软件的 Python 库,用于统计、优化、整合、线性代数模块、傅里叶变换、信号和图像处理等数值计算。
官网:http://scipy.org/
1.4.5 NLTK
NLTK(Natural Language Toolkit,自然语言处理工具包)是 NLP 领域中最常使用的 Python 库,可以访问超过50个语料库和词汇资源,并有一套用于分类、标记化、词干标记、解析和语义推理的文本处理库。
官网:http://www.nltk.org/
1.4.6 SnowNLP
SnowNLP 是 Python 开发的类库,用于处理中文文本。
源码文档地址:https://github.com/isnowfy/snownlp
1.4.7 Sklearn
Sklearn(又称为Scikit-learn)是简单高效的数据挖掘和数据分析工具,建立在 NumPy、SciPy 和 Matplotlib 基础上,作为基于 Python 语言的开源工具包,是当前较为流行的机器学习框架。
官网:https://scikit-learn.org/stable/
1.5 常用语料库
语料库是指经过科学取样和加工的大规模电子文本库。
1.5.1 情感/观点/评论的语料库
1)ChnSentiCorp_htl_all 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/ChnSentiCorp_htl_all/intro.ipynb
2)waimai_10k 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/waimai_10k/intro.ipynb
3)online_shopping_10_cats 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/online_shopping_10_cats/intro.ipynb
4)weibo_senti_100k 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/weibo_senti_100k/intro.ipynb
5)simplifyweibo_4_moods 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/simplifyweibo_4_moods/intro.ipynb
6)dmsc_v2 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/dmsc_v2/intro.ipynb
7)yf_dianping 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/yf_dianping/intro.ipynb
8)yf_amazon 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/yf_amazon/intro.ipynb
1.5.2 中文命名实体识别的语料库:dh_msra 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/dh_msra/intro.ipynb
1.5.3 推荐系统的语料库
1)ez_douban 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/ez_douban/intro.ipynb
2)dmsc_v2 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/dmsc_v2/intro.ipynb
3)yf_dianping 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/yf_dianping/intro.ipynb
4)yf_amazon 数据集
https://github.com/SophonPlus/ChineseNlpCorpus/blob/master/datasets/yf_amazon/intro.ipynb
1.5.4 搜狗新闻语料库
http://www.sogou.com/labs/resource/cs.php
专业术语:
人工智能(Artificial Intelligence,AI):是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术学科。
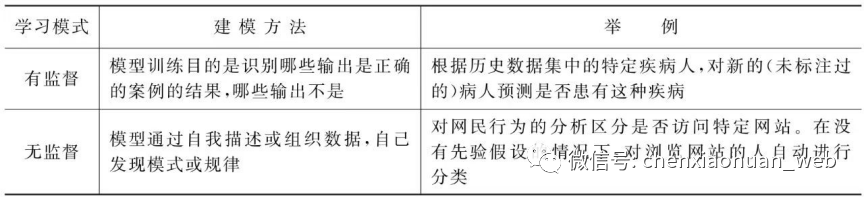
监督学习(Supervised Learning):是通过训练数据集得出建模,再用模型对新的数据样本进行分类或者回归分析的机器学习方法。
无监督学习(Unsupervised Learning):又称为非监督学习,是在没有训练数据集的情况下,对没有标签的数据进行分析并建立模型,发现数据本身的分布特点。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-10-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号