使用ChatGPT实现同城双活部署
原创

前言
今天老板让我写一篇腾讯云云原生的微服务项目部署实践,还要实现同城双活。听说ChatGPT已经“出圈”了,无所不能,还可以帮人写文章,刚好最近比较懒,看看他能否帮我写完这篇实践,并教会我实现同城双活部署。
ChatGPT官网
ChatGPT介绍
先来看看我的助手,是如何介绍自己的
看起来技术、学术、文化无所不知,很强大,那话不多说,开始干活!
项目介绍
需要部署的项目,是一个基于Dubbo的微服务系统——Q云书城(QCBM),它由多个功能模块组成,比如收藏、购买、用户管理和订单查询。
Q云书城
计划从数据层,应用层和接入层,对项目进行依次部署,其中:
- 数据层使用腾讯云 MYSQL 和腾讯云 Redis 搭建,保存书城信息,选择跨区高可用版本,提供灾备切换能力。
- 应用层采用容器方式,在腾讯云 TKE 中进行部署,包括以下单元:
- QCBM-Gateway:Dubbo网关服务,接受前端REST请求,转化为Dubbo调用。
- User-Service:提供用户注册、登录、鉴权等功能。
- Favorites-Service :提供用户图书收藏功能。
- Order-Service :提供用户订单生成和查询等功能。
- Store-Service :提供图书信息的存储等功能。
3. 接入层使用腾讯云 CLB,结合 K8S Ingress 和 Service 实现流量接入和转发,采用跨区高可用模式部署。整体架构图如下所示:
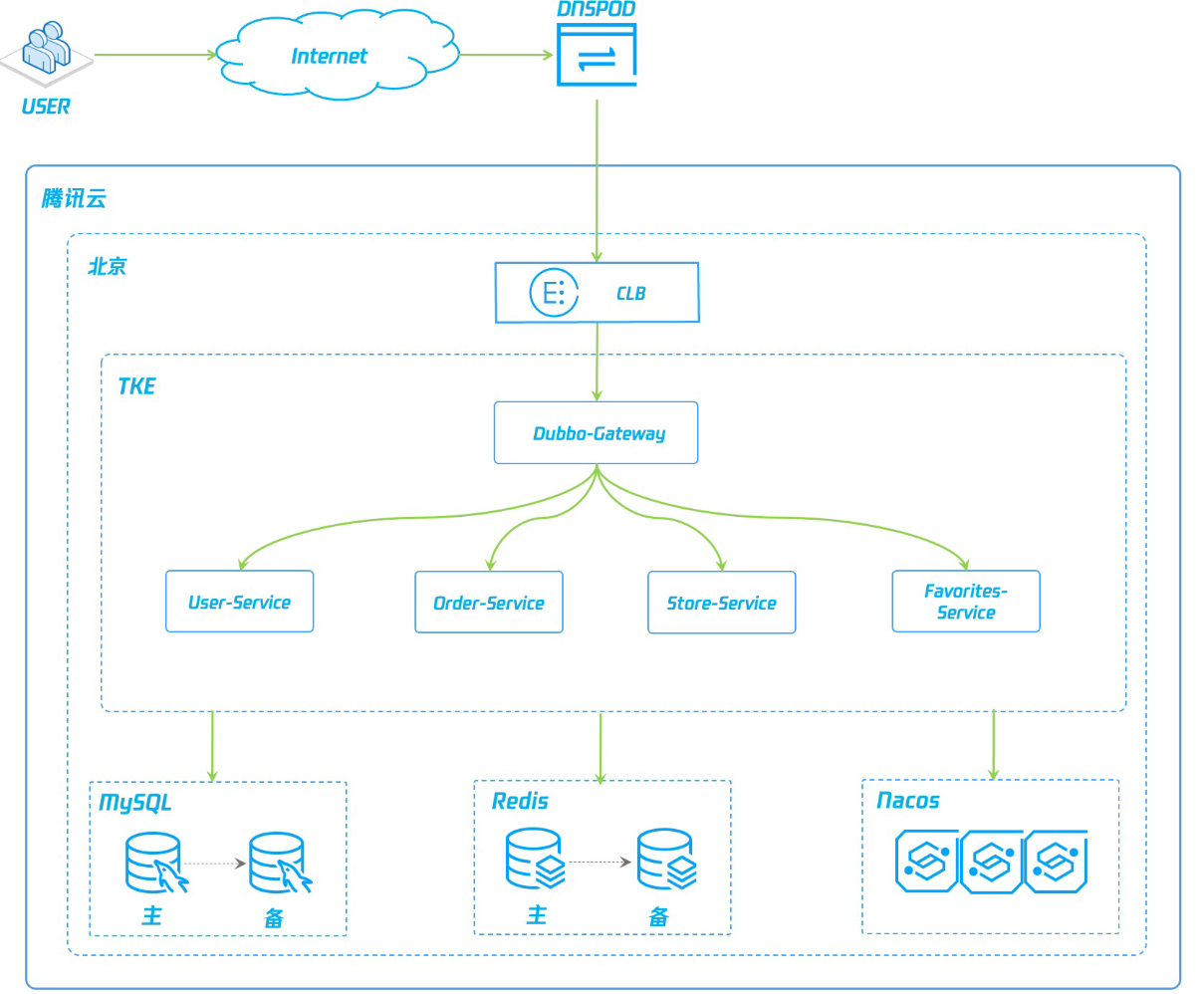
Q云书城服务架构图
数据层部署
首先开通多可用区版本的MySQL、Redis和Nacos,跨区部署可以提供访问连续性保证,这里记录下IP、账号和密码,为后续部署做准备。
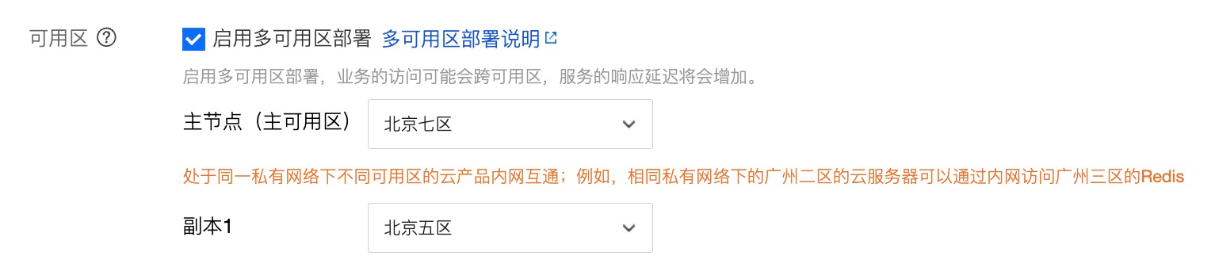
Redis多可用区部署
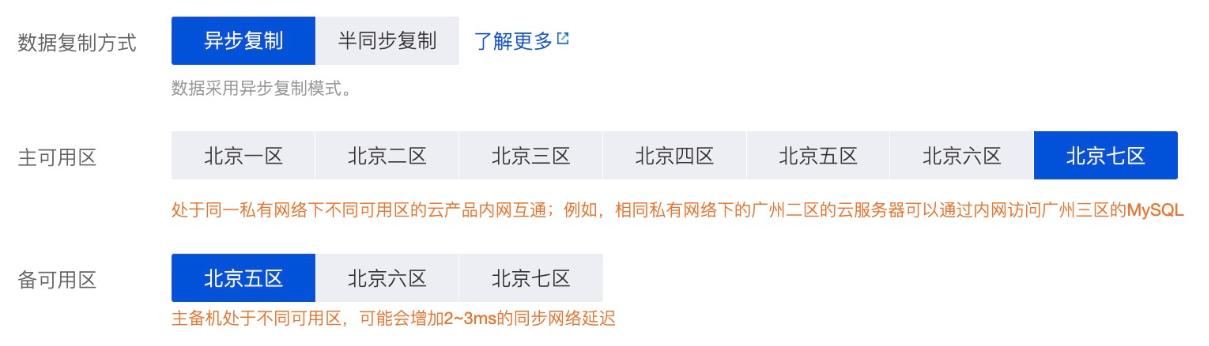
MySQL多可用区部署
应用层部署
开始第一个挑战,首先部署应用层的各业务模块,看看ChatGPT状态如何。
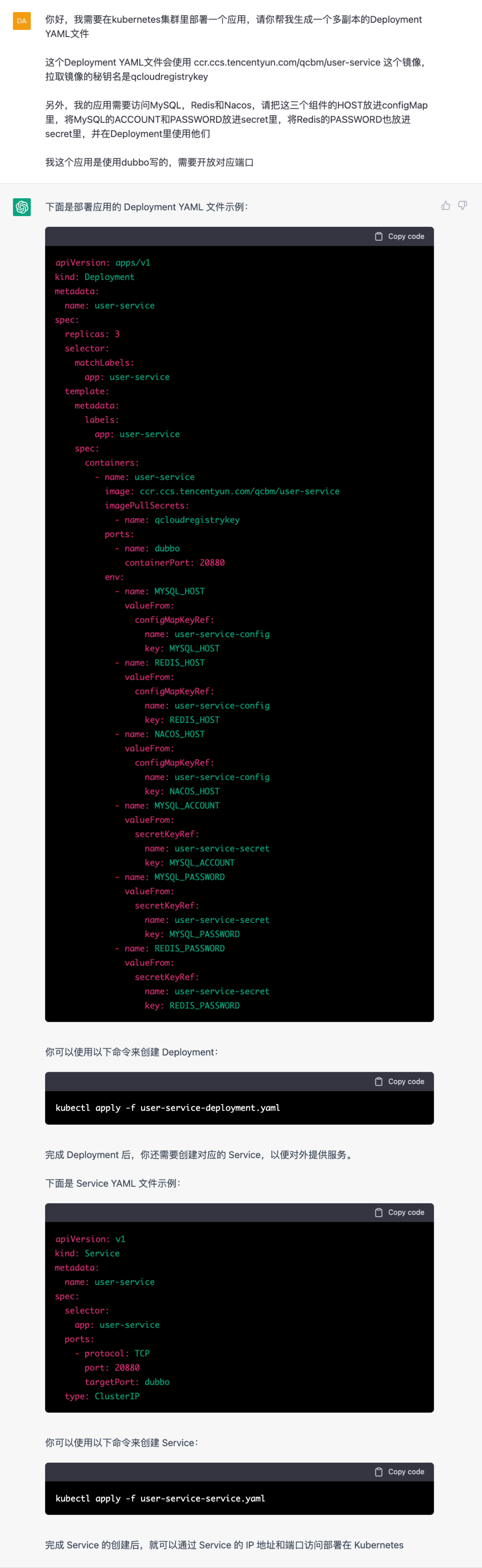
ChatGPT:Deployment
他好像忘记把ConfigMap和Secret给我了,提醒他一下
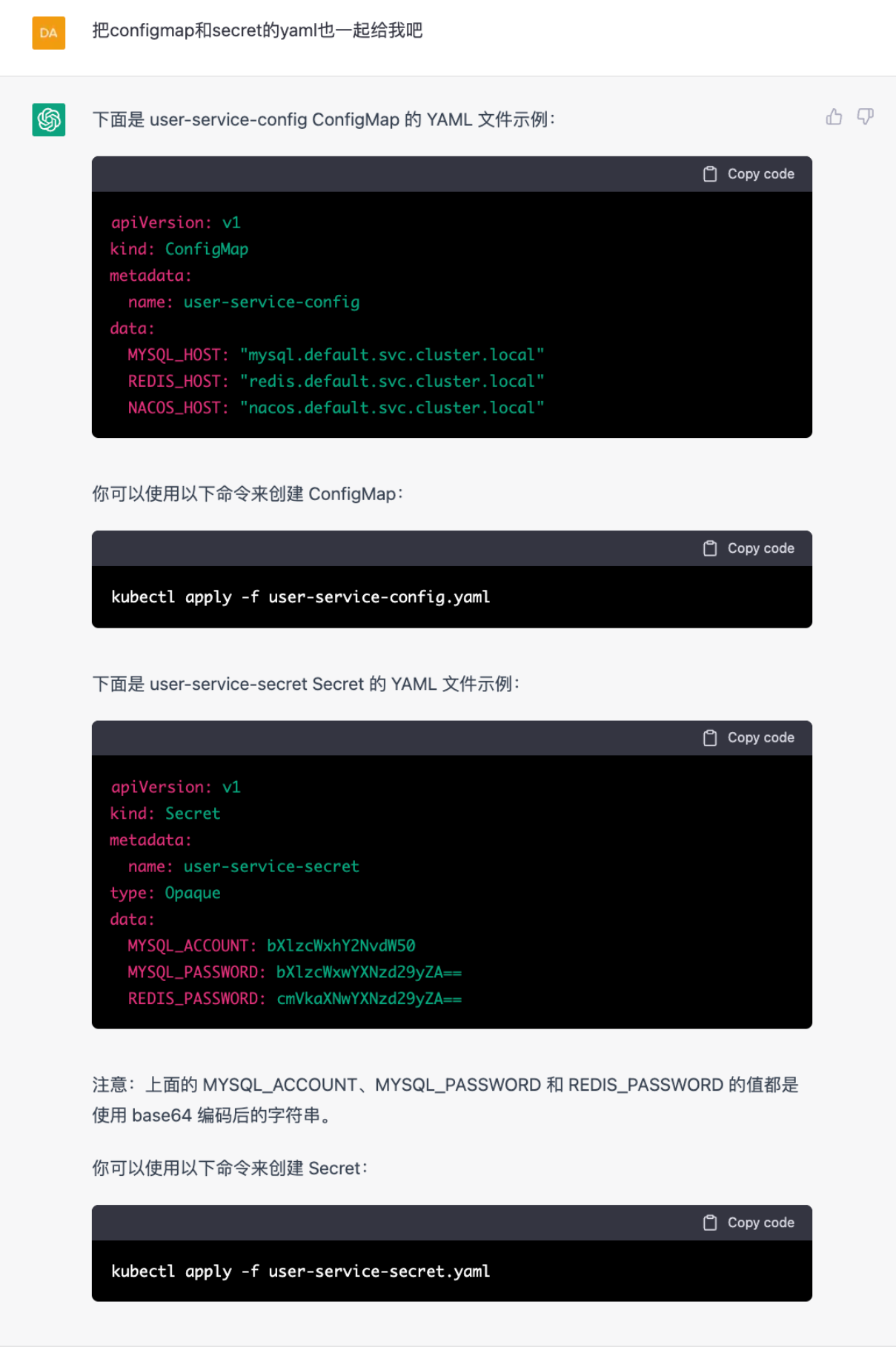
ChatGPT:ConfigMap及Secret
从TKE上开启集群后,按照ChatGPT给我的方案,替换configMap和secret里的值和数据,填入云上开通的MySQL、Redis和Nacos端口和地址。接着,创建包含登录名和密钥的secret,因为其他服务,也需要复用这里的configMap和secret,我对资源名称进行了修改。ChatGPT还提示secret需要使用base64编码后的字符串,非常贴心。
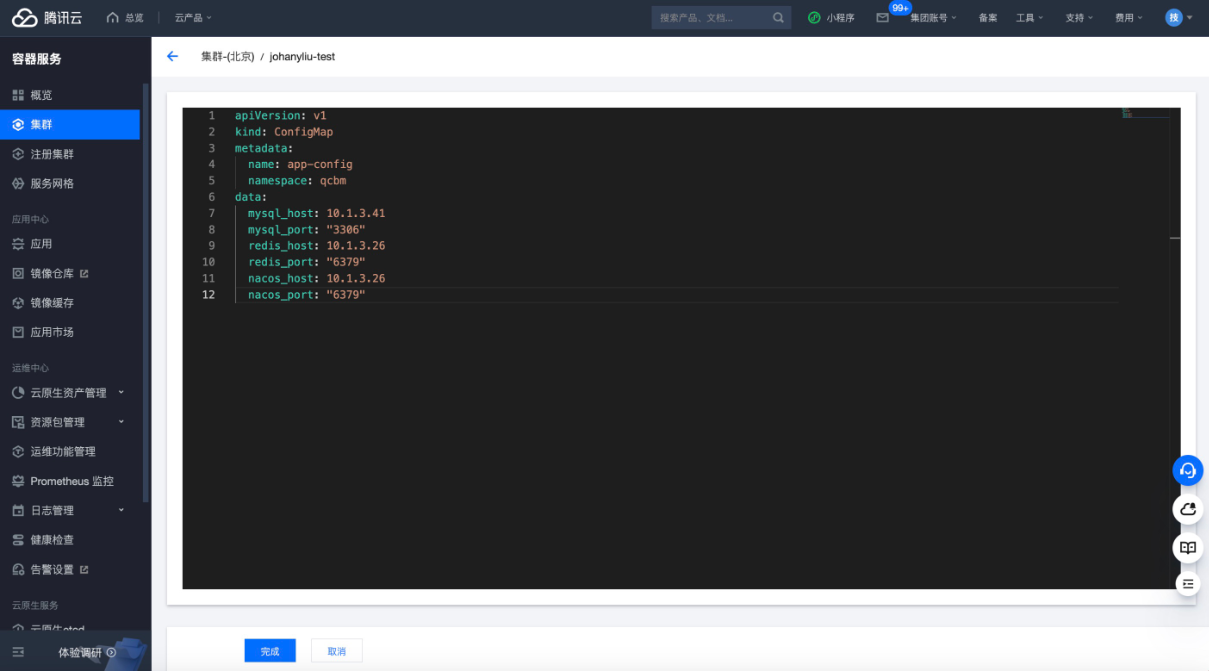
腾讯云TKE创建ConfigMap
完成configMap和secret的部署后,开始下发deployment。ChatGPT提供的YAML文件很准确,基本没有什么需要修改的,从user-service模块开始,直接复制粘贴操作。
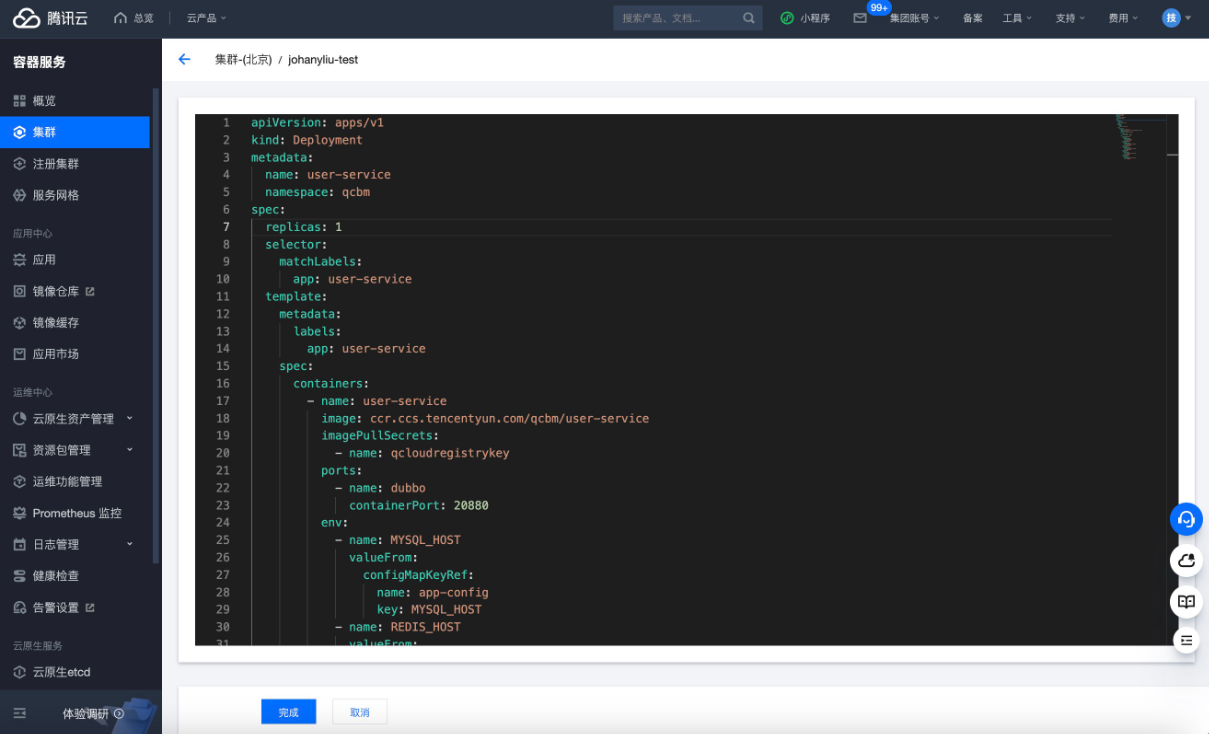
腾讯云TKE创建Deployment
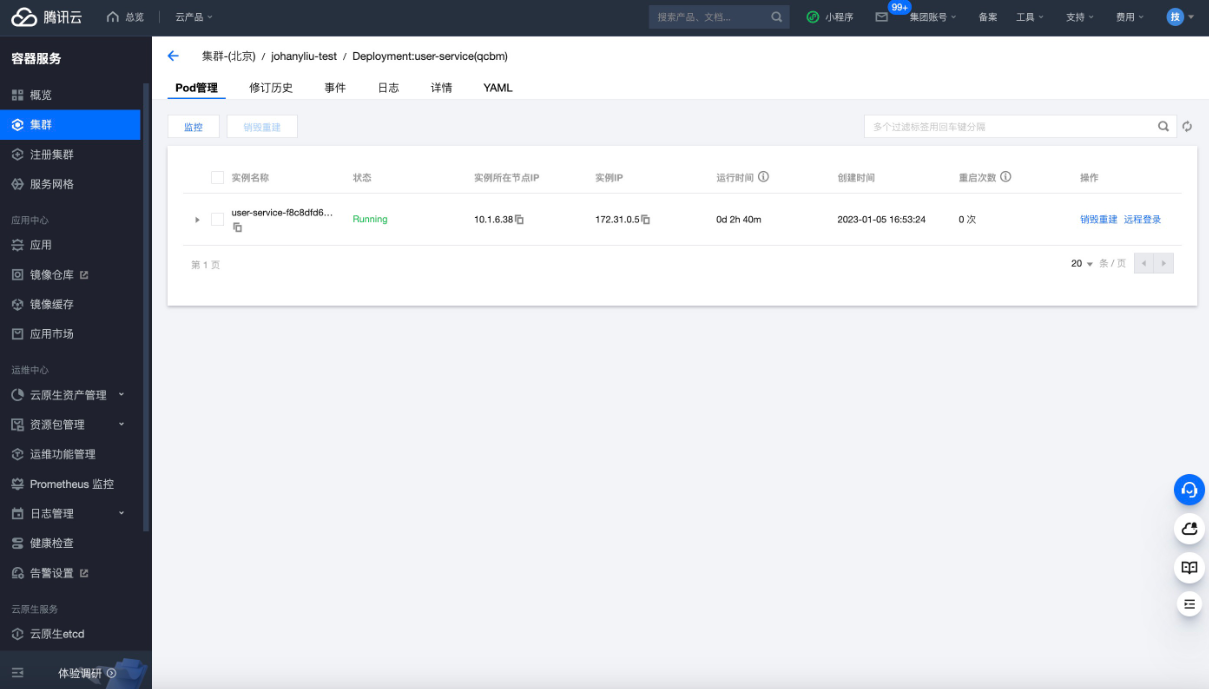
User-Service Deployment部署情况
没有意外,运行成功。接下来按照同样的方法,修改favorite-service,store-service及order-service的image及name,依次下发,4个服务都正常启动。
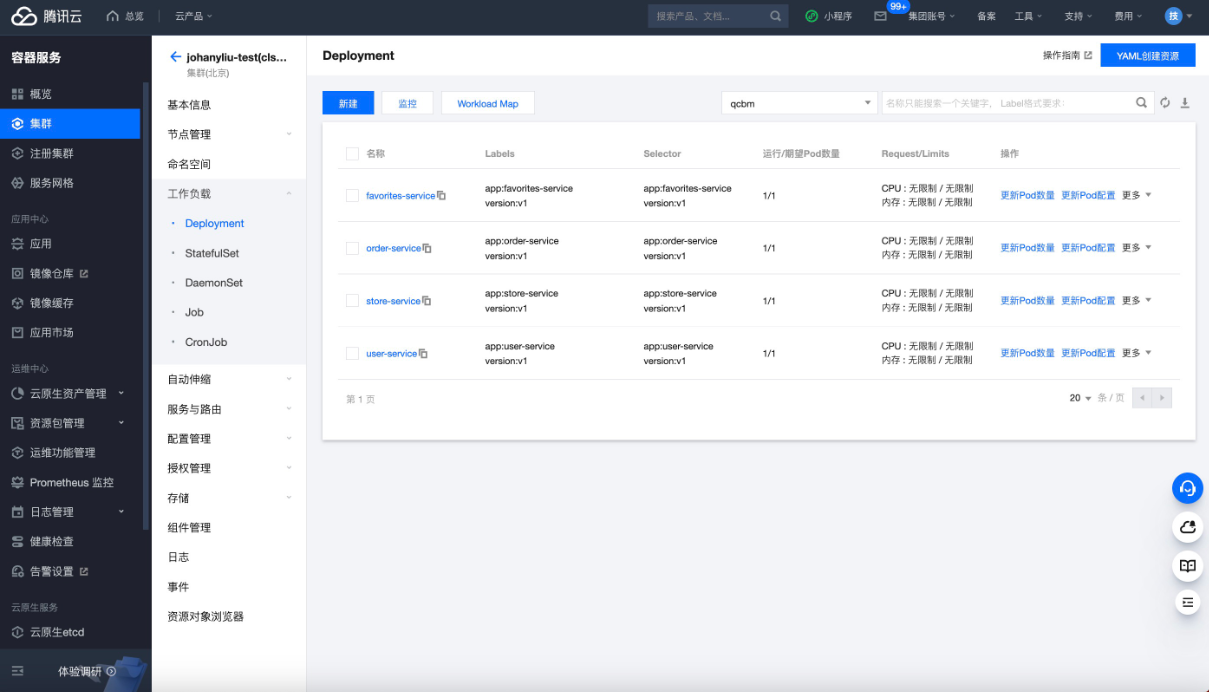
各服务Depolyment部署情况
接入层部署
完成4个业务模块的部署后,开始部署qcbm-gateway。qcbm-gateway为接入层访问模块,需要同时包含depolyment,service和ingress三部分。
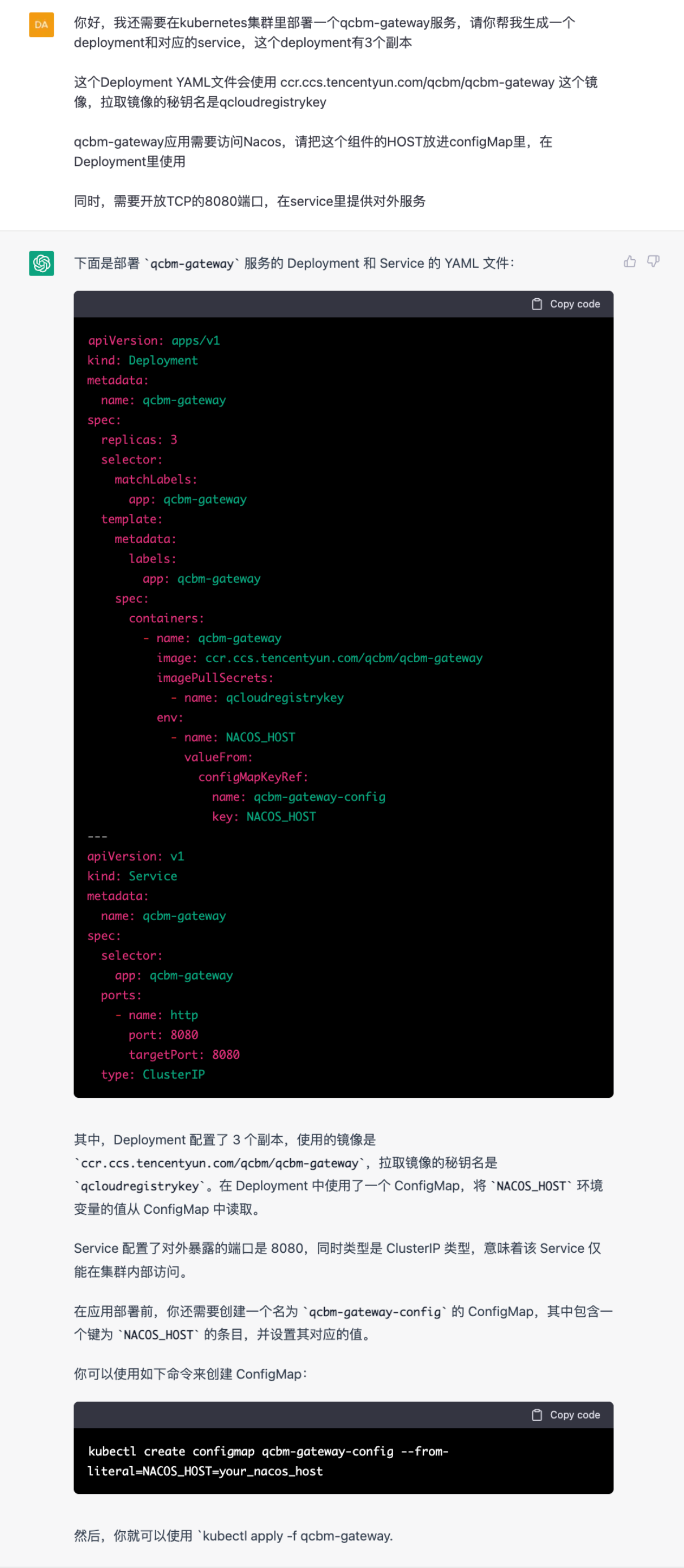
ChatGPT:Deployment及Service
当然,我们已经完成了configMap的部署,这里直接复用,只需要下发qcbm-gateway的deployment和service文件。
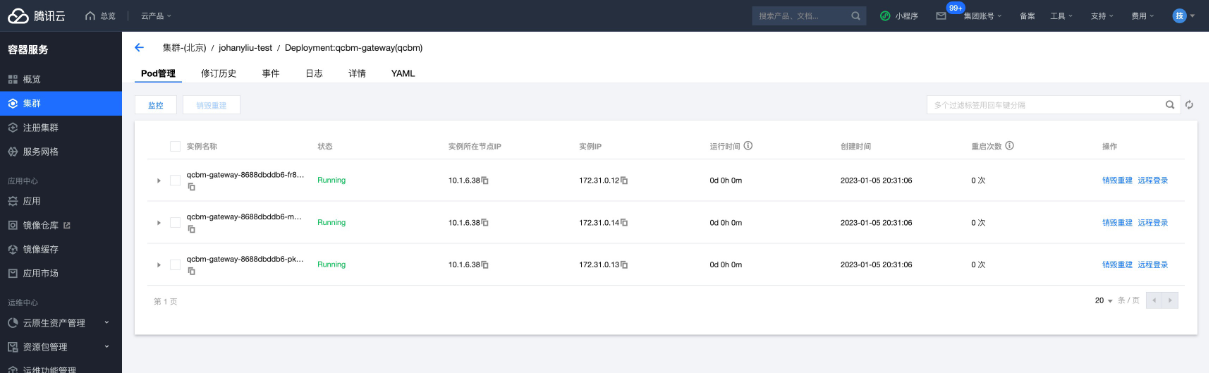
QCBM-Gateway Deployment部署情况
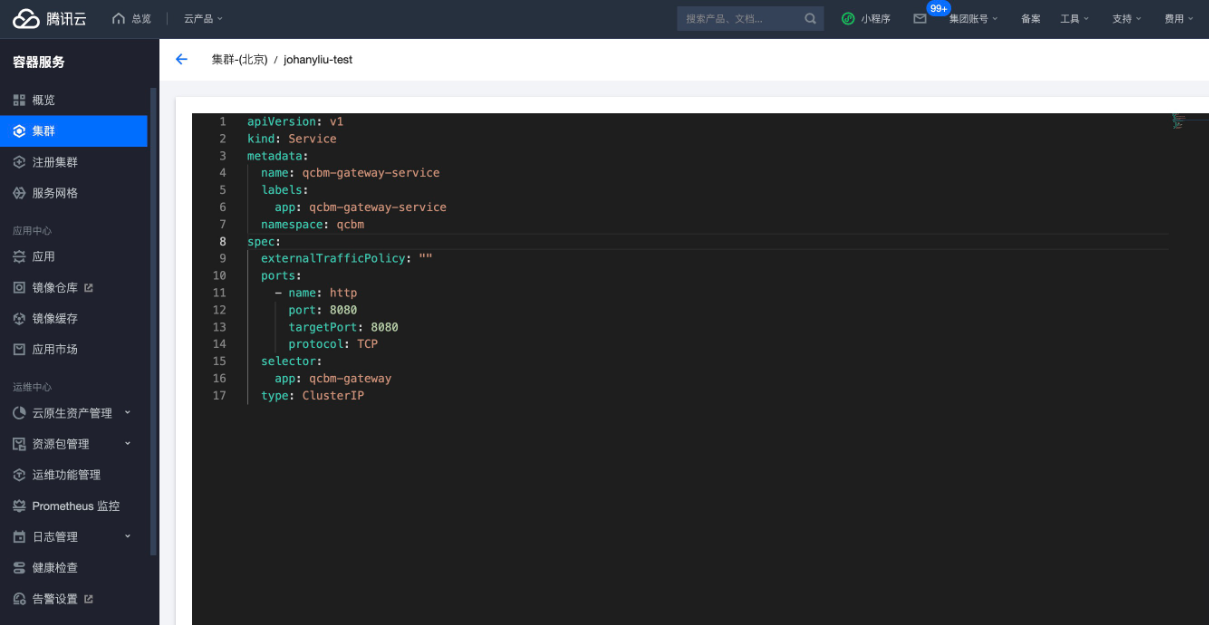
QCBM-Gateway Service
接下来,暴露网站的7层访问接口。
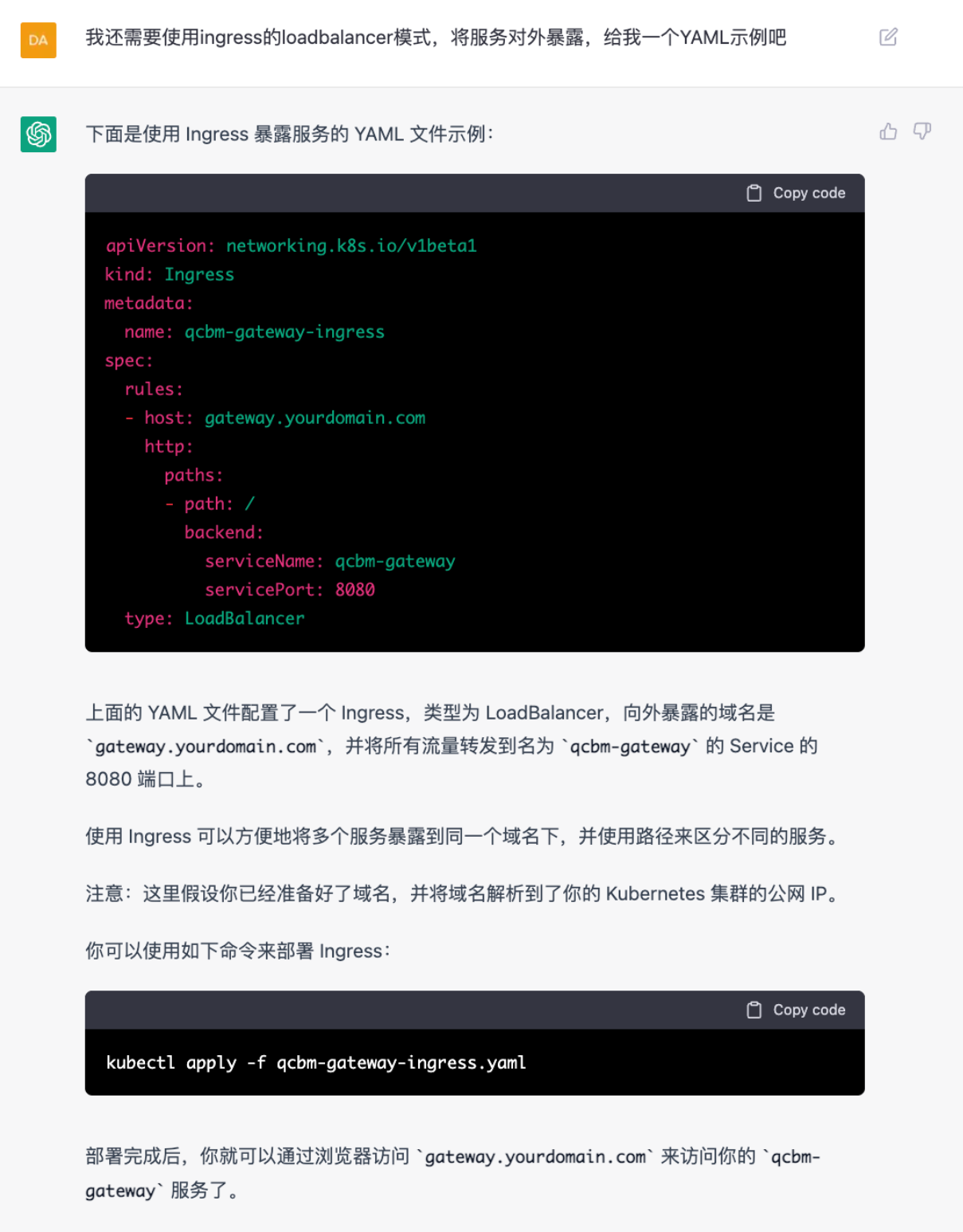
ChatGPT:Ingress
在ChatGPT给出的答案基础上,添加腾讯云ingress annotation,创建公网CLB类型的ingress,该annotation如下所示:
kubernetes.io/ingress.class: qcloud为了让CLB具备跨区高可用特性,将它同时部署在北京5区和北京7区,也是采用annotation的方式,如下所示:
kubernetes.io/ingress.extensiveParameters: '{"AddressIPVersion":"IPV4","MasterZoneId":"ap-beijing-5","SlaveZoneId":"ap-beijing-7"}'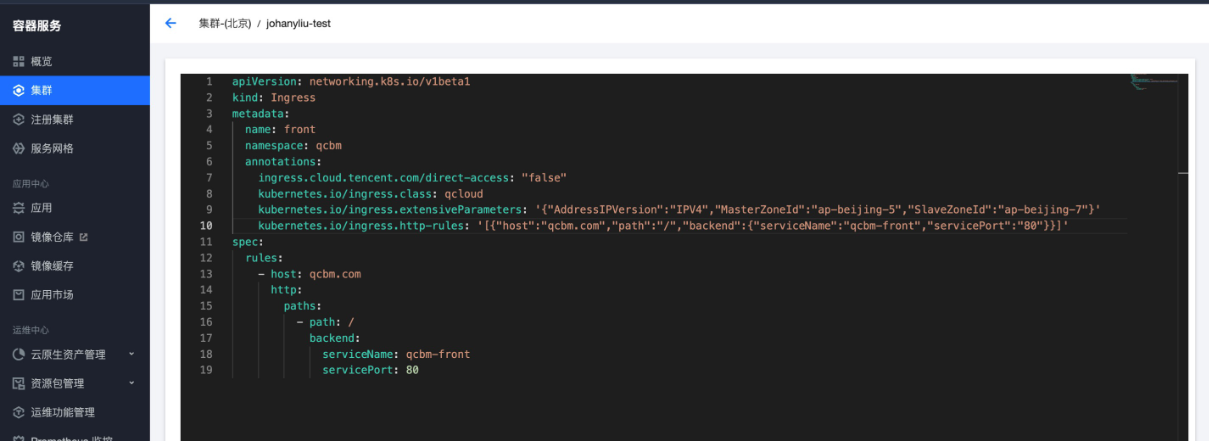
QCBM-Gateway Ingress
部署完成后,通过公网CLB地址,查看我们的云书城网站,访问成功!
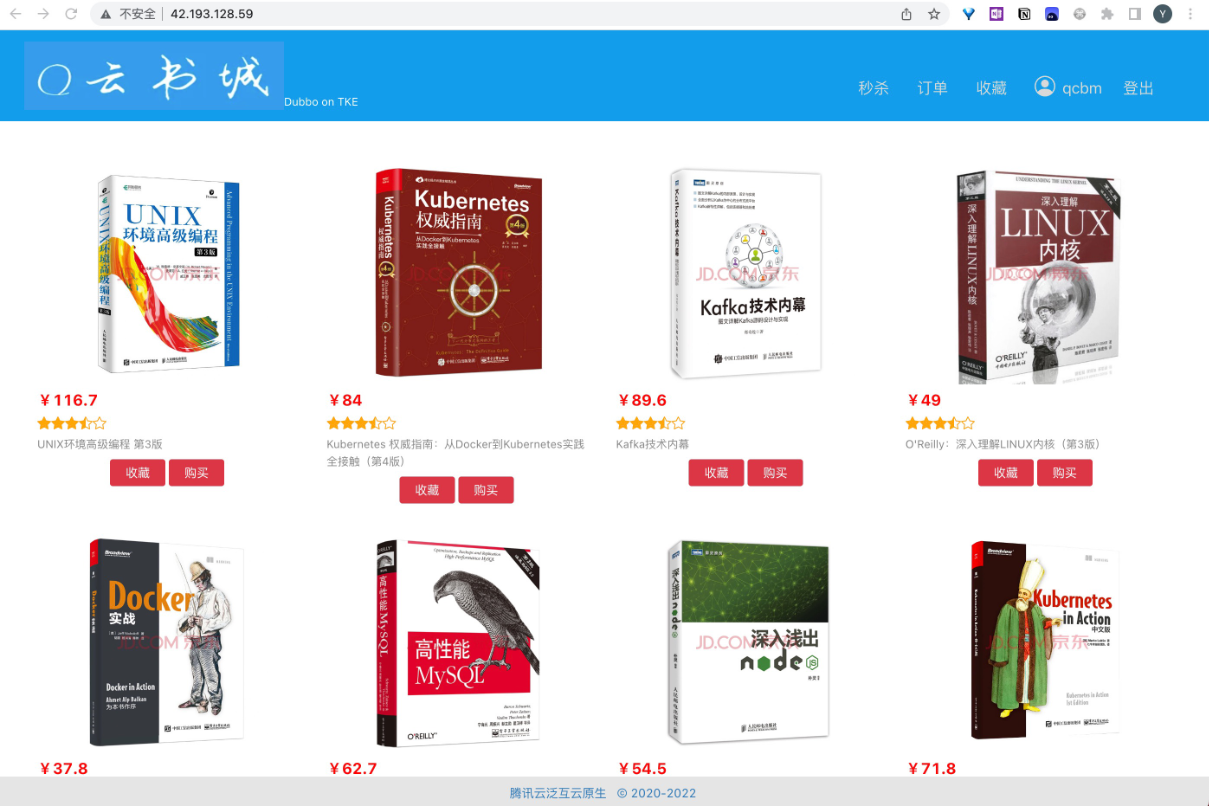
QCBM入口页面
同城双活改造
基础资源的部署,可能对ChatGPT来说有些简单,接下来,给他一些挑战,给我们提供一个应用层的跨区高可用方案。
为了实现同城双活,我们已经做了如下动作:数据层的MySQL、Redis和Nacos,开通多可用区版本;在申请Ingress时,加入了多可用区部署annotation。现在只剩下应用层还是单可用区部署。
我们希望只用一套TKE集群实现同城双活,最大程度的节约成本。理论上,将node开在不同的可用区,deployment多副本pod分散到不同可用区的node上,一旦出现单区故障,业务仍然可以提供连续性保证
之前在网上看过podantiaffinity的用法,但只是收藏,忘了阅读。不知道ChatGPT能不能基于这个方法,帮我完成应用层的改造工作。
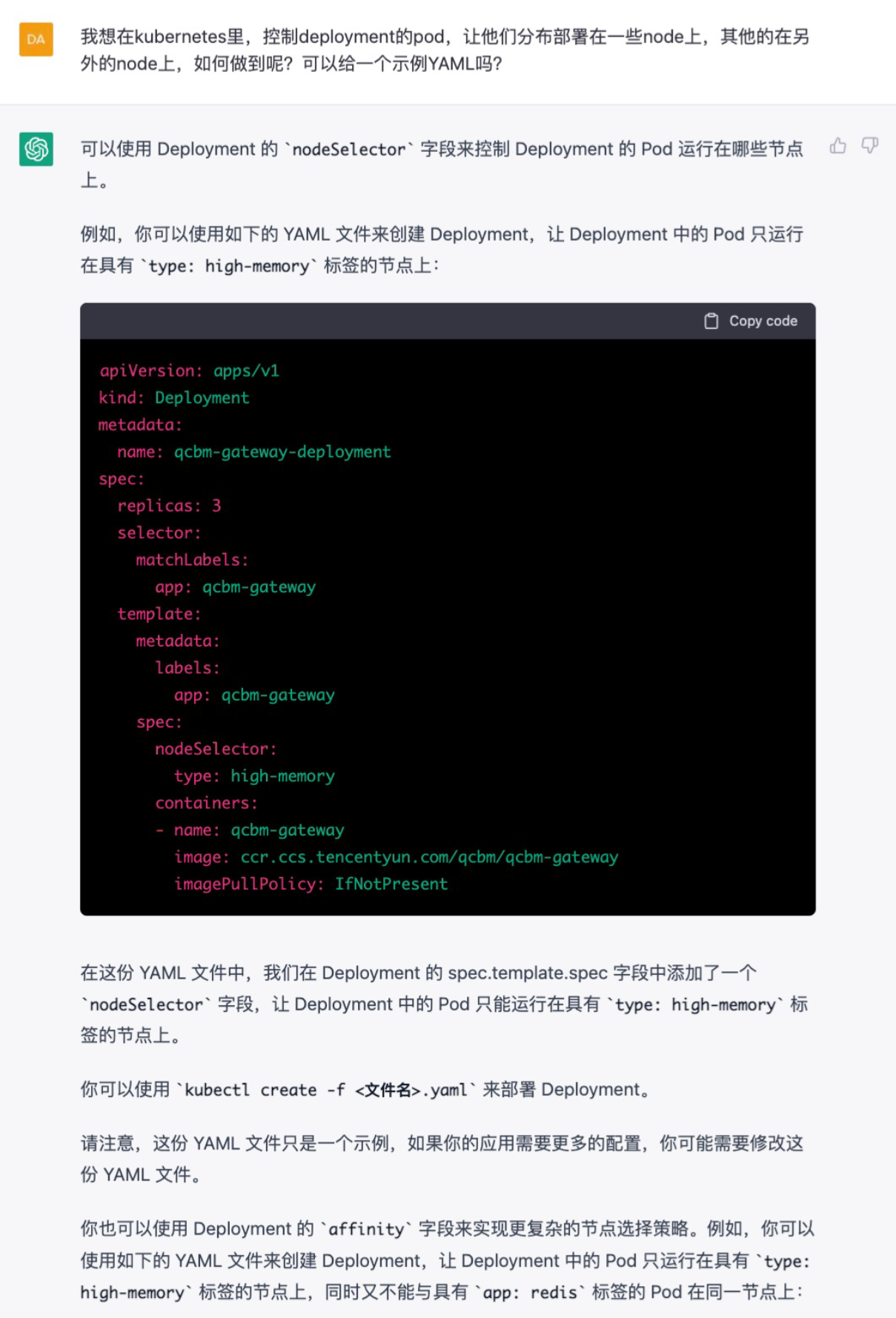
ChatGPT:控制Pod运行节点
ChatGPT给了我们两个备选项:nodeSelector肯定不行,因为他会把所有pod都调度到同一个node上,这不符合我们打散pod的要求。podantiaffinity的方案和我们的预期一致,来详细看看这一部分是如何实现的。
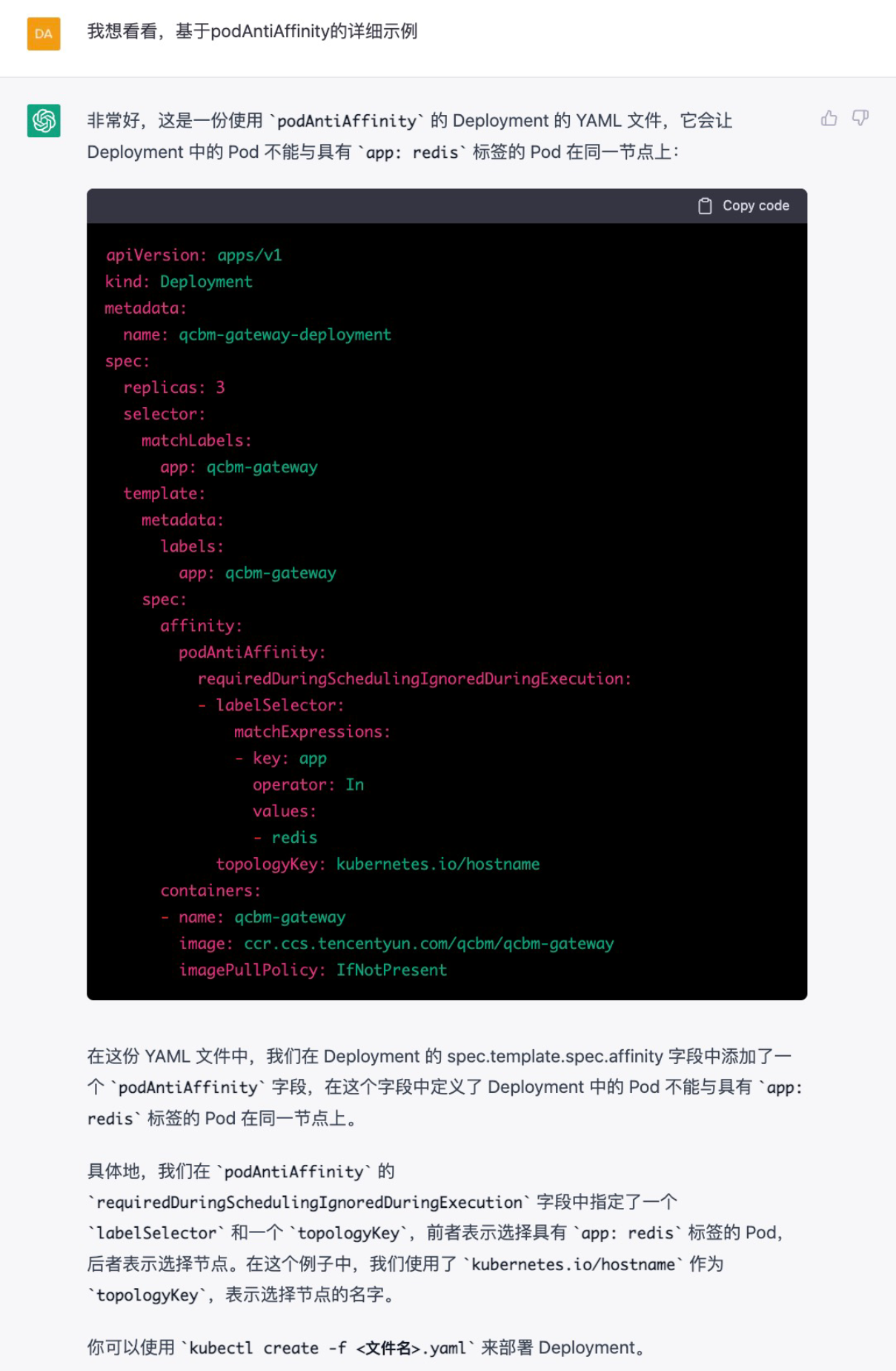
ChatGPT:Affinity-hostname
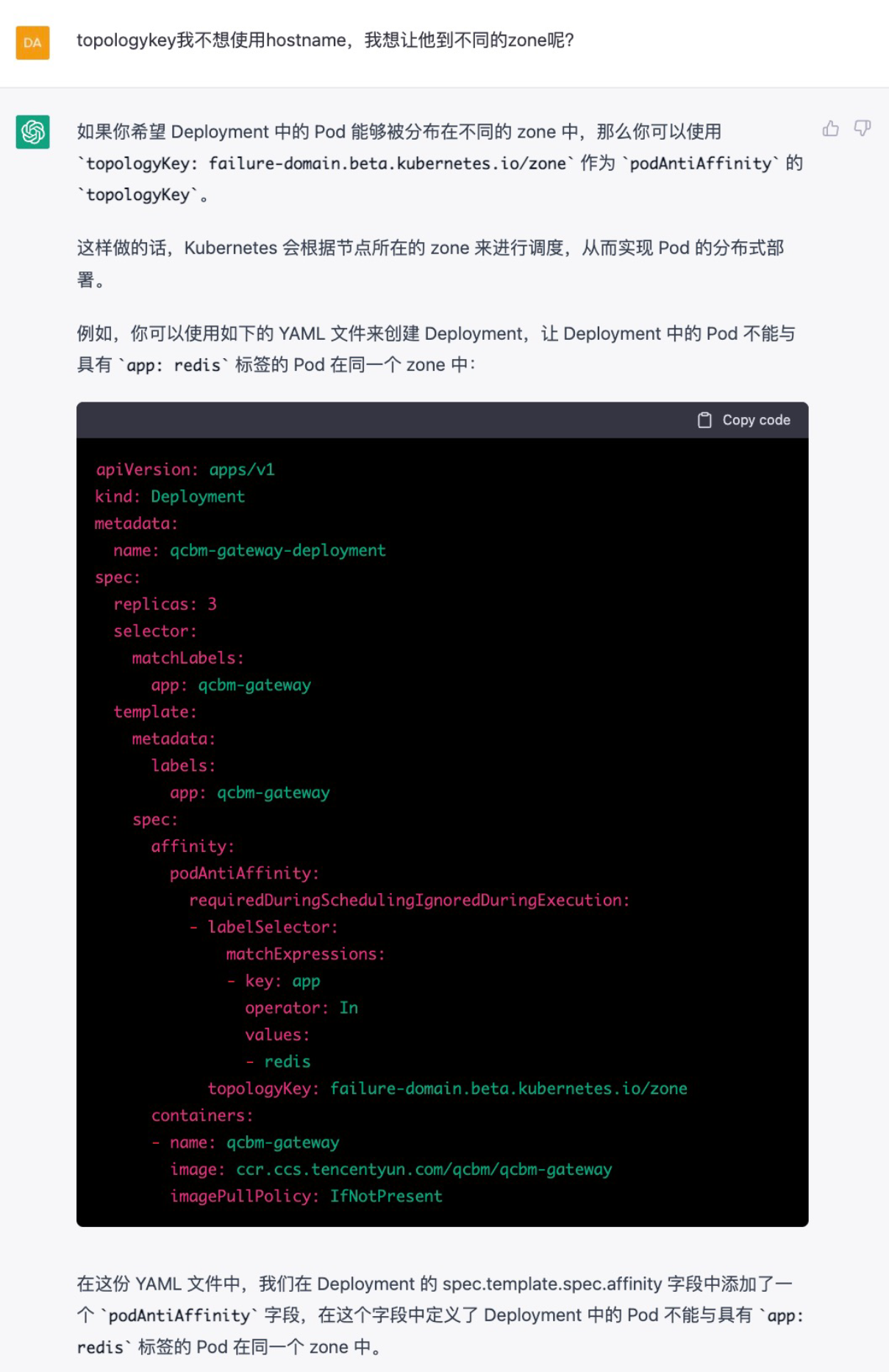
ChatGPT:Affinity-zone
看起来可以满足我的需求,决定按照这个方式尝试一下。考虑到ChatGPT的资源来自2019年前的资料,且语句中涉及到beta字眼。查询K8S官网,发现failure-domain.beta.kubernetes.io/zone已经被deprecated,建议使用最新的topology.kubernetes.io/zone。
另外,我们的deployment可能存在多个副本,但只想开通两个可用区的node资源。所以把requiredDuringSchedulingIgnoredDuringExecution修改为preferredDuringSchedulingIgnoredDuringExecution,避免大于2个副本的depolyment无法被调度。
加上官网的示例,我们对ChatGPT的答案进行一些修改,得到了正确的affinity语句:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- user-service
topologyKey: topology.kubernetes.io/zone
weight: 100因为是云原生部署,腾讯云TKE集群会每个node节点自动打上topology.kubernetes.io/zone的标签,所以无需再额外操作node资源文件了。
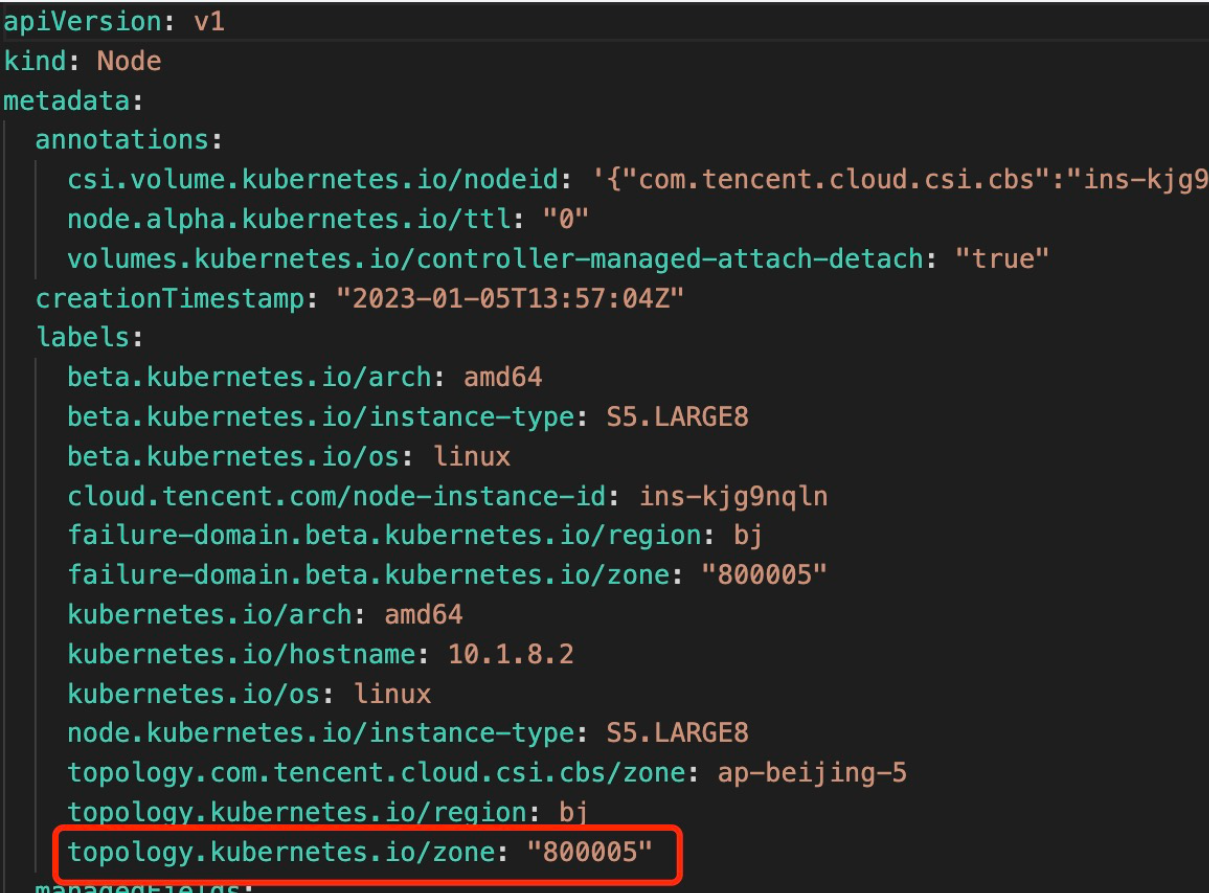
腾讯云TKE Node Labels
接下来开始实操,首先在TKE集群里添加一个不同可用区的Node节点。
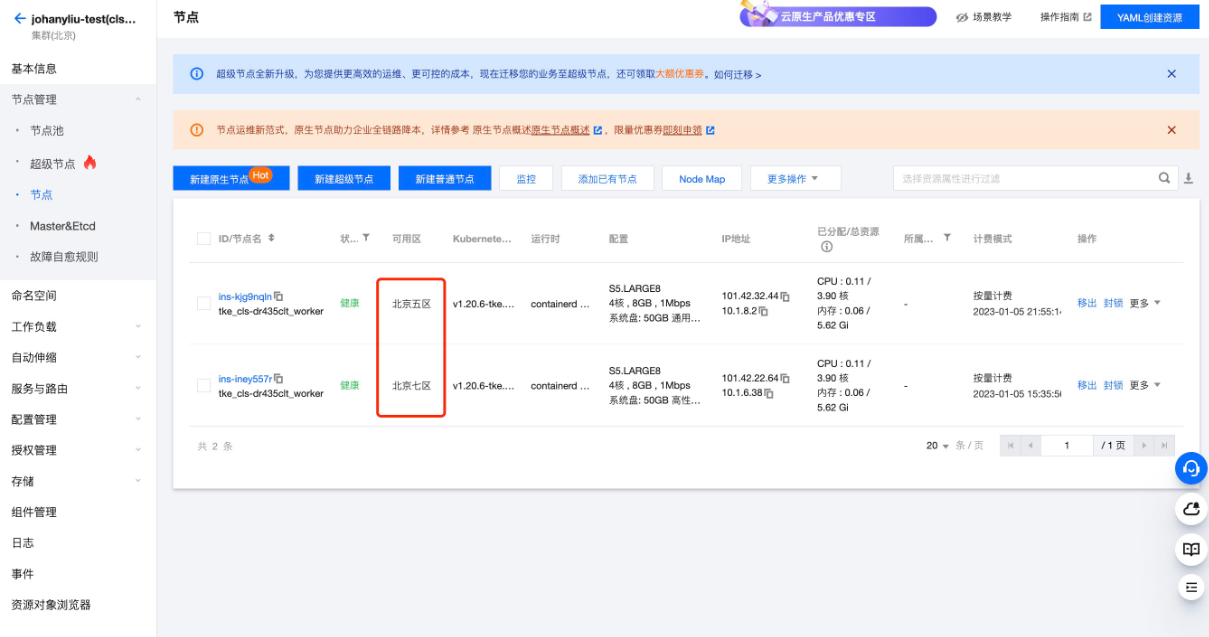
多可用区Node
先从user-service开始修改,在template.spec里加上affinity语句。提交后deployment下面的4个pod,被均匀的分配到不同节点上,使得user-service deployment具备了跨区可用特性,这正是预期的效果。
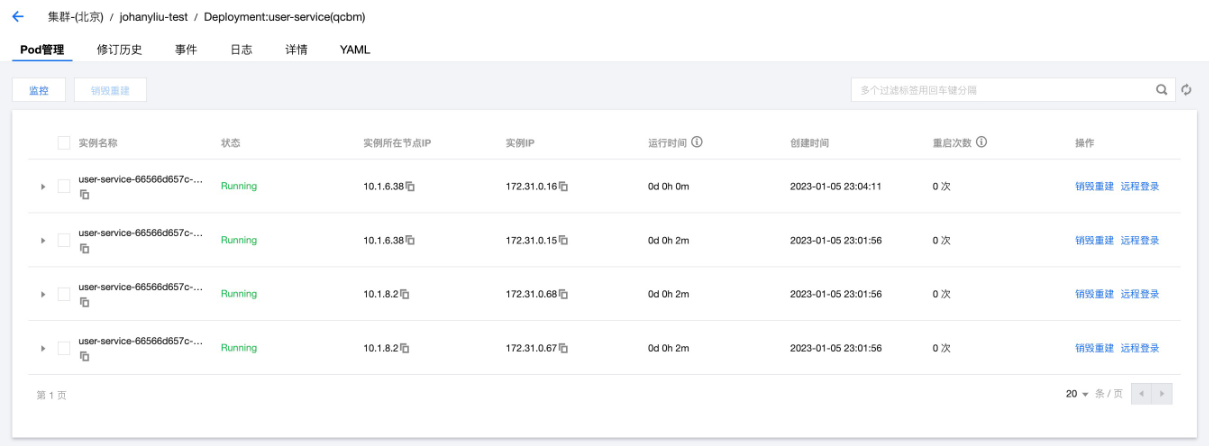
Deployment跨可用区部署Pod
将所有已部署的Deployment进行修改,完成架构中应用层的跨区高可用改造。
当然,这种部署模式会依赖Kubernetes调度器的优选算法,我们需要保证跨区的node具有相对均匀的资源,这样preferredDuringSchedulingIgnoredDuringExecution模式才能实现预期的效果。
结语
今天在ChatGPT的帮助下,我们不光完成了容器的部署,还实现了应用层的高可用改造。从接入层、应用层到数据层,快速地搭建出云上同城双活架构,从而避免单可用区故障,可能导致的访问中断。Excellent!
ChatGPT 表现出来的能力确实令人震惊,希望他能够学习到更多腾讯云云原生产品的最佳实践,让每一位用户轻松玩转云原生。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号