假如让你设计文件系统


我是cloud3
本文是图解系列之文件系统

简单来讲文件系统就是用来管理文件和磁盘的,是用户文件和磁盘之间的一个桥梁。
文件系统要管理磁盘就要有管理的规则,所有的管理都要先分组,或者说要条带化,然后按组进行组织管理。

那按照什么粒度划分呢?通常是以4KB为单位的对磁盘进行逻辑上的划分,一个4k称为一个block。文件系统就按照block为最小的管理单位进行磁盘管理。
划分好了最小管理单元后就要对他们进行再分组,哪些block分到一个组里专门干一件事,也有可能一个组里就只有一个block。
这些组分别要做什么呢?想先想到的就是要有一个组用来放文件,那这个组就被称为datablock。
除了存放文件,还要有一个组存放文件的大小、创建时间、文件存放在哪个block中等信息,这些信息被称为meta data,而这个组被称为inodes。
另外还要有一个组来记录磁盘的整体情况,例如磁盘的大小、inodes的大小等,这个组被称为superblock。
磁盘抽象化

于是就有了这么几个组:bootblock,superblock,inodes,datablock。bootblock和引导有关,这里文件系统关系不大,下面首先看看superblock。
超级块
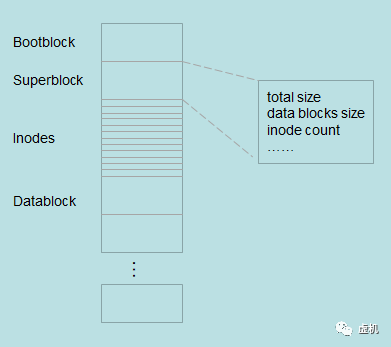
superblock中包含了文件系统的meta data,文件系统中有多少个inodes和data blocks,标明是何种文件系统类型的magic number等都记录在superblock中。
如何找到文件

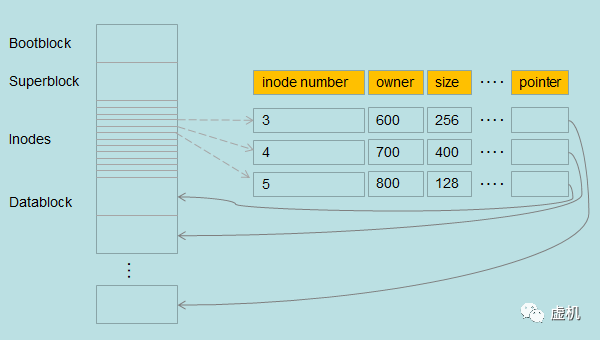
要找到存放在datablock中的文件,就需要有个地方记录文件的位置,这个记录文件位置的东西叫做index node(索引节点),所有的indes node放到一个地方这个地方就是inodes。
所以inodes中就是存放了一条条的数据,每条数据都对应datablock中的一个文件。除了具有指向文件所在block的指针外,还包括文件的mode、size、timestamps等。
如何找到目录
通过index node可以找到文件,同样可以找到目录,index node中如果mode是目录,那么所指向的block中就记录的是一个目录项(目录数据块)。
目录项中就记录了目录中的所有文件名称以及文件所在的index node编号。这样就可以再去通过inodes中的index node去查询文件以及下一级目录了。

总结
现在文件系统的种类繁多,ext3、ext4、xfs等,他们的实现复杂,但是文件系统的原理很简单,就是本文所讲的几个基本元素:文件data,查找文件的inode以及管理整个文件系统的superblock。
现在复杂的文件系统就是在这么一个设计思想上衍生出来的。关于文件系统的设计细节我们后面再具体介绍。
关于文件系统最基本原理就讨论到这里。
我是cloud3
本文是图解系列之文件系统
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2021-09-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号