iOS MachineLearning 系列(5)—— 视频中的物体运动跟踪

iOS MachineLearning 系列(5)—— 视频中的物体运动跟踪

珲少
发布于 2023-04-27 20:38:49
发布于 2023-04-27 20:38:49
iOS MachineLearning 系列(5)—— 视频中的物体运动追踪
本系列的前面几篇文章中,我们将静态图片分析相关的API做了详尽的介绍。在Vision框架中,还提供了视频中物体追踪的能力。
仔细想来,其实视频的分析和静态图片的分析本质上并无太大的区别,我们可以将视频拆解成图片帧,之后再对图片进行静态分析。将所有图片帧的分析结果反馈到视频上,即实现了对视频的分析能力。
视频中物体运动的跟踪常在一些AR游戏中应用,这些现实增强类的应用常常需要实时追踪显示中的物体。
1 - 先看一个简单的示例
我们以矩形区域追踪为例,与前面文章介绍的静态分析类似,运动追踪实现的核心点也只有三个:
1. 请求操作句柄。
2. 构建请求。
3. 处理分析请求的回调。
首先我们先来构建操作句柄:
lazy var handler = VNSequenceRequestHandler()构建请求:
lazy var request: VNTrackRectangleRequest = {
let req = VNTrackRectangleRequest(rectangleObservation: observation) { result, error in
// 处理结果
if let error {
print(error)
}
// 处理结果
self.handleResult(request: result as! VNTrackRectangleRequest)
}
// 选择快速模式
req.trackingLevel = .fast
return req
}()在构建请求时,需要我们传入一个初始的描述矩形区域的VNRectangleObservation对象,之后的追踪会以参数为对象。VNRectangleObservation的构建示例如下:
// 预检测得到的
var observation = VNRectangleObservation(boundingBox: CGRect(x: 0.3728713095188141, y: 0.833836019039154, width: 0.16493645310401917, height: 0.07572066783905029))需要注意,这里的数据是我使用静态分析预先处理视频首帧得到的,实际应用中,我们也可以先对首帧进行静态分析,找到要追踪的矩形区域。
之外,我们还需要对视频资源进行一些处理,简单来说,即是解析视频帧,之后逐帧进行分析,示例代码如下:
func readVideo() {
// 视频路径
let videoURL = URL(fileURLWithPath: Bundle.main.path(forResource: "video1", ofType: ".mp4")!)
// 读取视频资源
let videoAsset = AVURLAsset(url: videoURL)
// 创建视频资源解析器
let videoProcessor = AVAssetImageGenerator(asset: videoAsset)
videoProcessor.requestedTimeToleranceBefore = CMTime.zero
videoProcessor.requestedTimeToleranceAfter = CMTime.zero
// 获取视频时长
let durationSeconds: Float64 = CMTimeGetSeconds(videoAsset.duration)
// 存储要截取的视频帧时间点
var times = [NSValue]()
// 以每秒60帧为标准,获取总帧数
let totalFrames: Float64 = durationSeconds * 60
// 定义 CMTime 即请求缩略图的时间间隔
for i in 0...Int(totalFrames) {
let timeFrame = CMTimeMake(value: Int64(i), timescale: 60)
let timeValue = NSValue(time: timeFrame)
times.append(timeValue)
}
// 进行图片解析
videoProcessor.generateCGImagesAsynchronously(forTimes: times) { time, cgImage, actualTime, resultCode, error in
if let cgImage = cgImage {
let image = UIImage(cgImage: cgImage)
self.images.append(image)
}
}
}当所有视频帧处理完成后,我们即可以对其进行矩形追踪,示例方法如下:
func start() {
var count = 0
// 这里定时器的作用是逐帧的刷新页面,同时进行追踪
Timer.scheduledTimer(withTimeInterval: 0.03, repeats: true) { t in
if count < self.images.count {
// 设置页面展示的图片
self.imageView.image = self.images[count]
// 将inputObservation设置为上一次的分析结果
self.request.inputObservation = self.observation
// 进行追踪分析
try? self.handler.perform([self.request], on: self.images[count].cgImage!, orientation: .up)
count += 1
} else {
// 当循环结束时,设置isLastFrame表情请求已经到了最后一帧
self.request.isLastFrame = true
// 停止定时器
t.invalidate()
print("end")
}
}
print(images.count)
}需要注意,追踪分析的本质是对矩形区域的前后状态进行比较,将其运行情况进行分析。因此,每次进行分析请求时需要将上一次的结果作为inputObservation进行输入,当视频结束时,设置起isLastFrame来结束分析,释放资源。
最后,分析结果的处理很简单:
func handleResult(request: VNTrackRectangleRequest) {
print(request.results)
for r in request.results ?? [] {
guard let result = r as? VNRectangleObservation else {
return
}
observation = result
var box = result.boundingBox
// 坐标系转换
box.origin.y = 1 - box.origin.y - box.size.height
print("box:", result.boundingBox)
DispatchQueue.main.async {
let size = self.imageView.frame.size
self.boxView.frame = CGRect(x: box.origin.x * size.width, y: box.origin.y * size.height, width: box.size.width * size.width, height: box.size.height * size.height)
}
}
}其中,box是我们定义好的一个UIView蒙层,用来表示追踪的结果,效果如下GIF图所示:
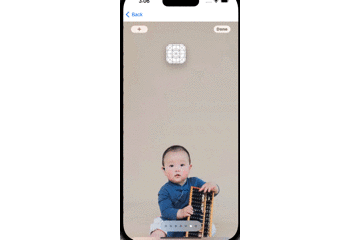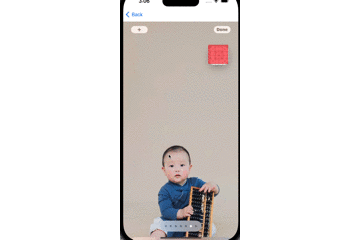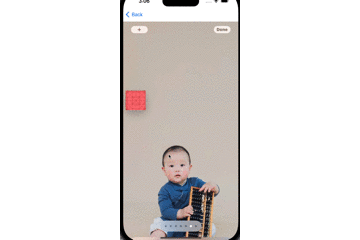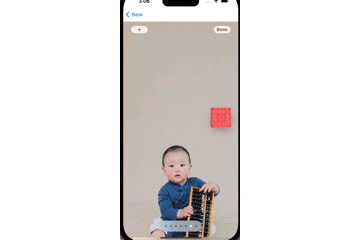
其中,白色的色块是原始视频中的矩形物体,红色的色块是我们的追踪结果。
2 - 几个重要的类
VNSequenceRequestHandle类无需多说了,它的作用就是发起请求,其与VNImageRequestHandler类的最大区别在于VNSequenceRequestHandle在创建对象时无需设置一个图片资源,VNSequenceRequestHandle主要是用来分析一系列图片的,因此其是在请求执行时设置图片资源的。
VNTrackRectangleRequest类用来创建矩形区域追踪请求,继承自VNTrackingRequest类,VNTrackingRequest的定义如下:
open class VNTrackingRequest : VNImageBasedRequest {
// 输入追踪区域的Observation对象 每次根据中要刷新
open var inputObservation: VNDetectedObjectObservation
// 追踪模式
open var trackingLevel: VNRequestTrackingLevel
// 是否是最后一帧,如果设置为true,将停止后续分析
open var isLastFrame: Bool
}其中trackingLevel用了设置追踪的算法模式:
public enum VNRequestTrackingLevel : UInt, @unchecked Sendable {
// 精准优先
case accurate = 0
// 速度优先
case fast = 1
}更多时候,我们要追踪的物体可能不是规则的矩形,也可能是会进行翻转和形变的物体,例如行驶中的汽车,飞行中的球类,奔跑中的人等。对于这类需求,我们需要使用VNTrackObjectRequest来进行追踪,其用法与VNTrackRectangleRequest几乎完全一致,这里就不再赘述,示例代码可以在下面找到:
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-04-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号