技术专题:API资产识别大揭秘(二)
原创

在上一期中,我们介绍了API资产的识别技术,探讨了API资产的定义以及各类风格API的识别技术。在本期中,我们将继续介绍API资产识别中的API聚合技术。
一、相关介绍
作为API资产梳理中的关键环节,API聚合的目的是从流量数据中识别出各种API,并通过分析将流量中API进行归一化处理。

*API资产聚合其实类似于生活中的物品聚类。在API资产梳理过程中,将通信流量当中属于同一个的API接口用通用模式来表示。
举个例子:
在API通信流量当中,我们识别了多个Restful API:
http://www.test.com/v1/app/1001很明显,这其实是属于同一个API接口,该API聚合后的效果应该为:
http://www.test.com/v1/app/{id}在实际企业API资产梳理工作中,API通信流量通常非常巨大。当我们在流量中识别到了10亿次API请求时,我们就必须考虑这到底是存在10亿个API资产,还是只有10个API资产。因此,API资产分析的聚合成为企业理清API资产真实数量的关键。
二、API聚合技术
整体思路:基于统计算法,将通信流量中API初步归类,一般来说按照同一个业务系统进行分类,然后将其所有的 API 无论是 URL 的部分还是 Body 的部分,全部抽象成一个数据结构,通过统计的方法去缩小API聚合范围,最后通过一定的算法把通用的模式识别出来,再用这些通用的模式去打标签,这种增量的流量逐渐的能够收敛掉,接近到真实 API 的资产数量程度。
下面来看看统计部分的算法。
1. 字典树算法
Trie,又称字典树、单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
举个例子:关键字集合为:{“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”} 使用Trie树表示如下图所示:
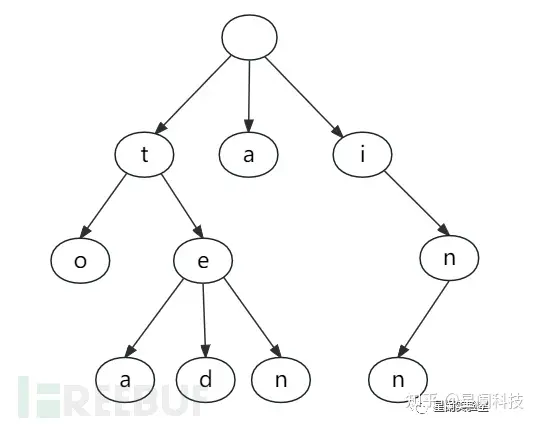
在API聚合逻辑中,我们还需要对Trie算法进行变形,将/作为节点分割符,将API的URL部分变成树状结构。
比如:
http://example.com/cat/sports解析结果如下图:
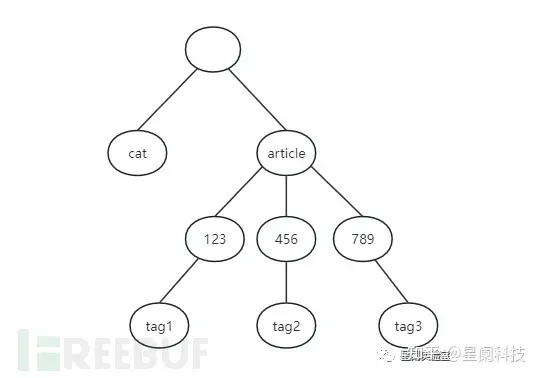
基于树状结构,我们将统计确定API聚合范围的相关维度,比如:
- 尾结点到跟节点的距离,表示API中URL的长度
- 拥有相同节点的树状结构,表示API中URL相同路径
- 同一深度的节点可变性
通过以上统计数据,我们将API聚合的范围进一步缩小:这些API属于同一业务系统、路径长度相同、拥有相同路径节点,并且存在可变路径。
2. 字符串相似判定
当我们运用前面提及的Tire算法进一步缩小API聚合的范围后发现,后续的工作主要是对于那些可变路径的相似度的计算,也就是这些在同一位置的可变路径是不是属于同一类,如果是就可以把它们进行聚合处理。
下面我们将介绍几种关于字符串相似度计算的基本原理:
余弦相似性
余弦相似性通过测量两个向量的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1;并且其最小值是-1。定义如下:
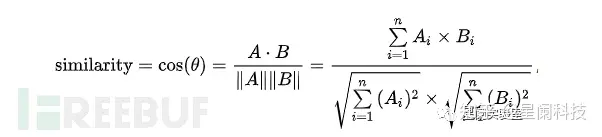
编辑距离
编辑距离是针对二个字符串(例如英文字)的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。
汉明距离
汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。汉明距离是编辑距离中的一个特殊情况,仅用来计算两个等长字符串中不一致的字符个数。
Sorensen Dice 相似度系数
Dice相似度系数是用于度量两个集合的相似性,因为可以把字符串理解为一种集合,因此Dice距离也会用于度量字符串的相似性。
Jaccard 相似度
定义公式如下,简单来说就是集合的交集与集合的并集的比例。
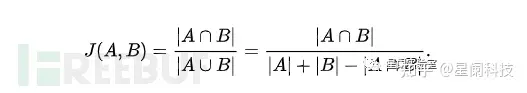
当然,上述都是计算字符串的相似性的理论方案,在一定程度上这些方法是有效的,但结合不同的训练样本和业务实际,计算API中URL相似度的方法也各有不同。
Simhash算法
Simhash是google于2007年发布的一篇论文《Detecting Near-duplicates for web crawling》中提出的算法,最初主要用于解决亿万级别的网页去重任务。
SimHash本身属于一种局部敏感hash,其主要思想是降维,将高维的特征向量转化成一个f位的指纹,通过算出两个指纹的海明距离来确定两篇文章的相似度。当然,利用Simhash算法,我们也可以用于两个字符串的相似度的计算,下面是SimHash算法的流程:
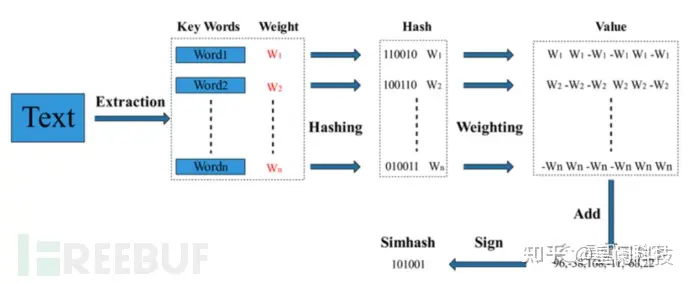
而传统的Hash算法只负责将原始内容尽量均匀随机地映射为一个签名值,原理上仅相当于伪随机数产生算法。即便是两个原始内容只相差一个字节,所产生的签名也很可能差别很大,所以传统的Hash是无法在签名的维度上来衡量原内容的相似度。
3. 聚合效果
那通过上述API聚合技术的介绍,我们聚合后最终能够达到什么样的效果呢?
我们以测试网站的API为例:
从流量中获取到该网站存在以下API(通过处理,图中显示API的URL路径部分)
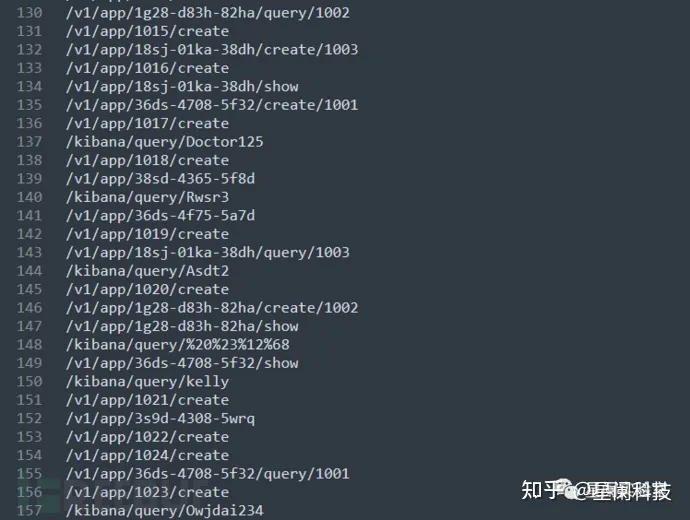
通过统计算法处理之后,我们将得到路径相同、URL长度相同、拥有相同路径节点等条件的API聚合范围。
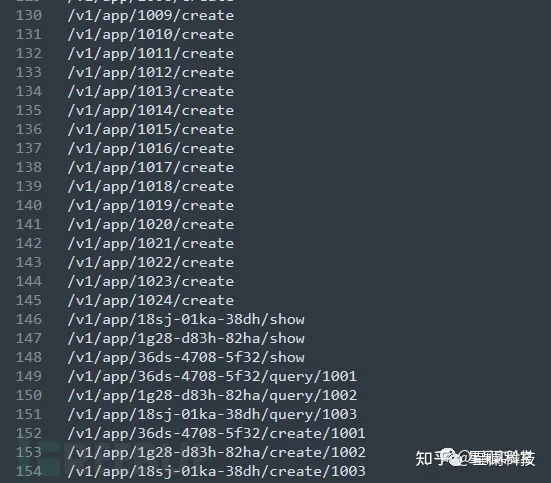
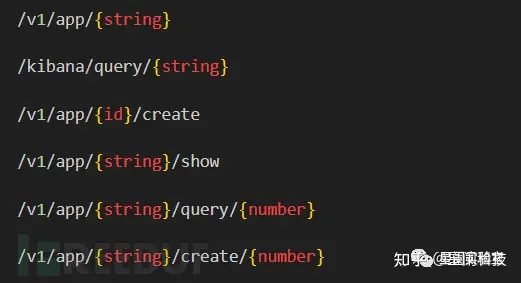
根据统计后的聚合范围,我们对满足条件的API中的可变路径部分进行相似度计算并聚合,最终结果如下所示:
小结
本次主要旨在揭示基于统计算法的API资产分析和聚合技术。通过将通信流量中的API进行初步分类,并将所有API的URL部分抽象为一个数据结构。通过统计方法缩小API聚合范围,然后利用相关算法计算和聚合满足条件的API中可变路径部分的相似度。最后,对聚合的通用模式进行识别,并对后续增量的流量进行收敛,以此帮助企业梳理出接近真实API的资产及其数量。
关于Portal Lab
星阑科技 Portal Lab 致力于前沿安全技术研究及能力工具化。主要研究方向为数据流动安全、API 安全、应用安全、攻防对抗等领域。实验室成员研究成果曾发表于BlackHat、HITB、BlueHat、KCon、XCon等国内外知名安全会议,并多次发布开源安全工具。未来,Portal Lab将继续以开放创新的态度积极投入各类安全技术研究,持续为安全社区及企业级客户提供高质量技术输出。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号