V8中推测优化(Speculative Optimization)的介绍

V8中推测优化(Speculative Optimization)的介绍

安全锚Anchor
修改于 2023-09-17 14:46:10
修改于 2023-09-17 14:46:10
简介
在详细介绍 TurboFan 的工作原理之前,我先简要介绍一下 V8 工作的high level流程。让我们来看看 V8 工作原理的简化图。
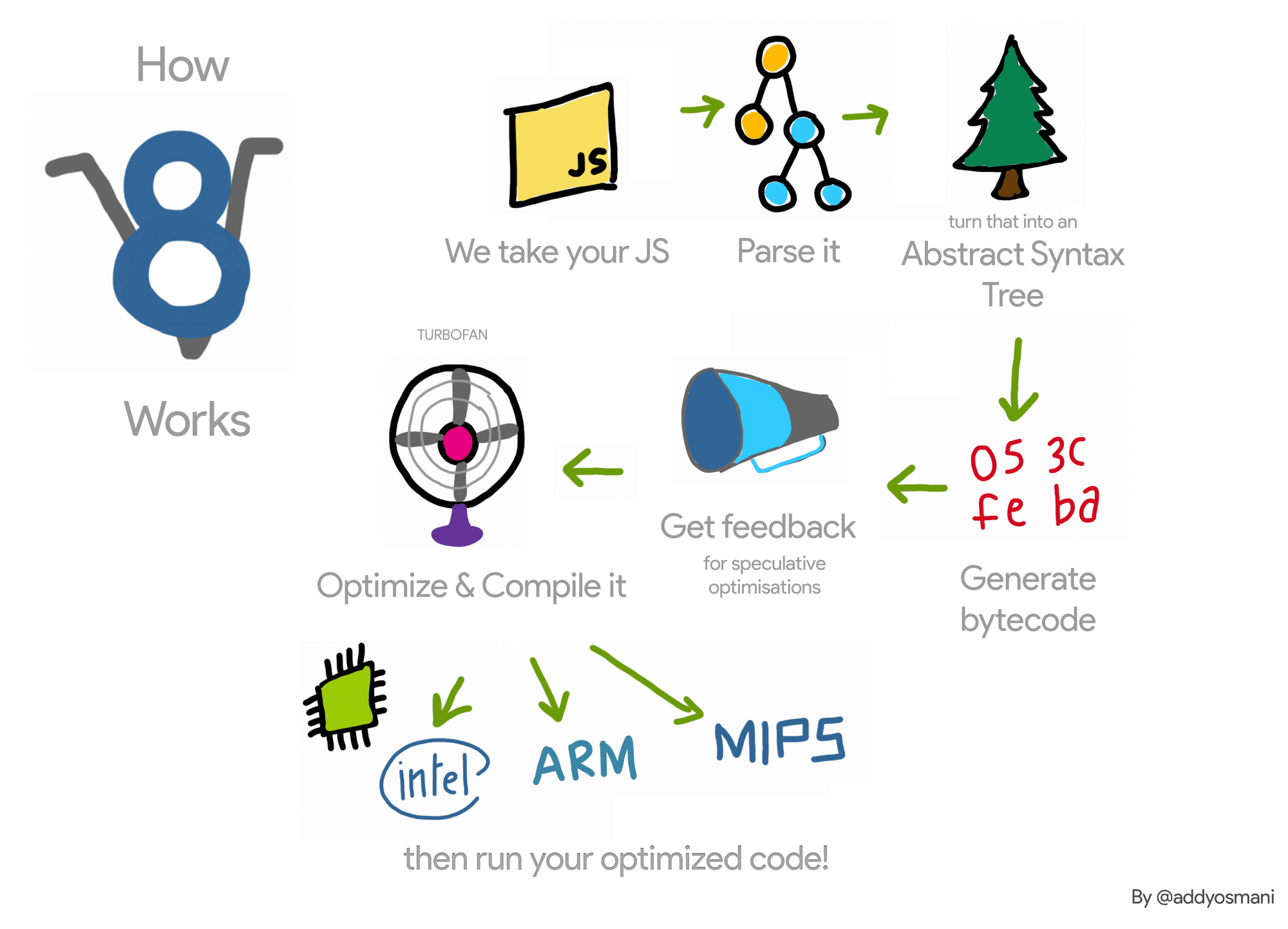
每当 Chrome 浏览器或 Node.js 需要执行某些 JavaScript 代码时,它都会将源代码传递给 V8。V8 会获取 JavaScript 源代码并将其反馈给所谓的 "解析器"(Parser),后者会为源代码创建抽象语法树(AST)表示法。“Parsing JavaScript — better lazy than eager?”的演讲中详细介绍了 V8 是如何工作的。然后,AST 会被传递到最近推出的 Ignition Interpreter,在那里被转化为字节码序列。然后,Ignition 将执行字节码序列。
在执行过程中,Ignition 会收集有关某些操作输入的profiling信息或反馈(feedback)。其中一些反馈信息会被 Ignition 自己用来加快后续字节码的解释。例如,对于像 o.x 这样的属性访问,其中的 o 始终具有相同的形状(即你始终为 o 传递一个值 {x:v},其中 v 是一个字符串),我们会缓存关于如何获取 x 值的信息。这种底层机制被称为内联缓存(IC)。关于属性访问的更多细节可以在“What’s up with monomorphism?”看到。
可能更重要的是,根据您的工作量,TurboFan JavaScript 编译器会利用 Ignition 解释器收集到的反馈信息,通过一种名为 "推测优化 "(Speculative Optimization)的技术生成高度优化的机器代码。在这里,优化编译器会查看过去出现过哪些类型的值,并假定未来我们也会看到相同类型的值。这样,TurboFan 就可以省去很多不需要处理的情况,这对于以最高性能执行 JavaScript 是非常重要的。
基本执行流程
让我们来看看函数 add 以及 V8 如何执行该函数。
function add(x, y) {
return x + y;
}
console.log(add(1, 2));如果在 Chrome DevTools 控制台中运行此程序,你会看到它输出了预期的结果 3:
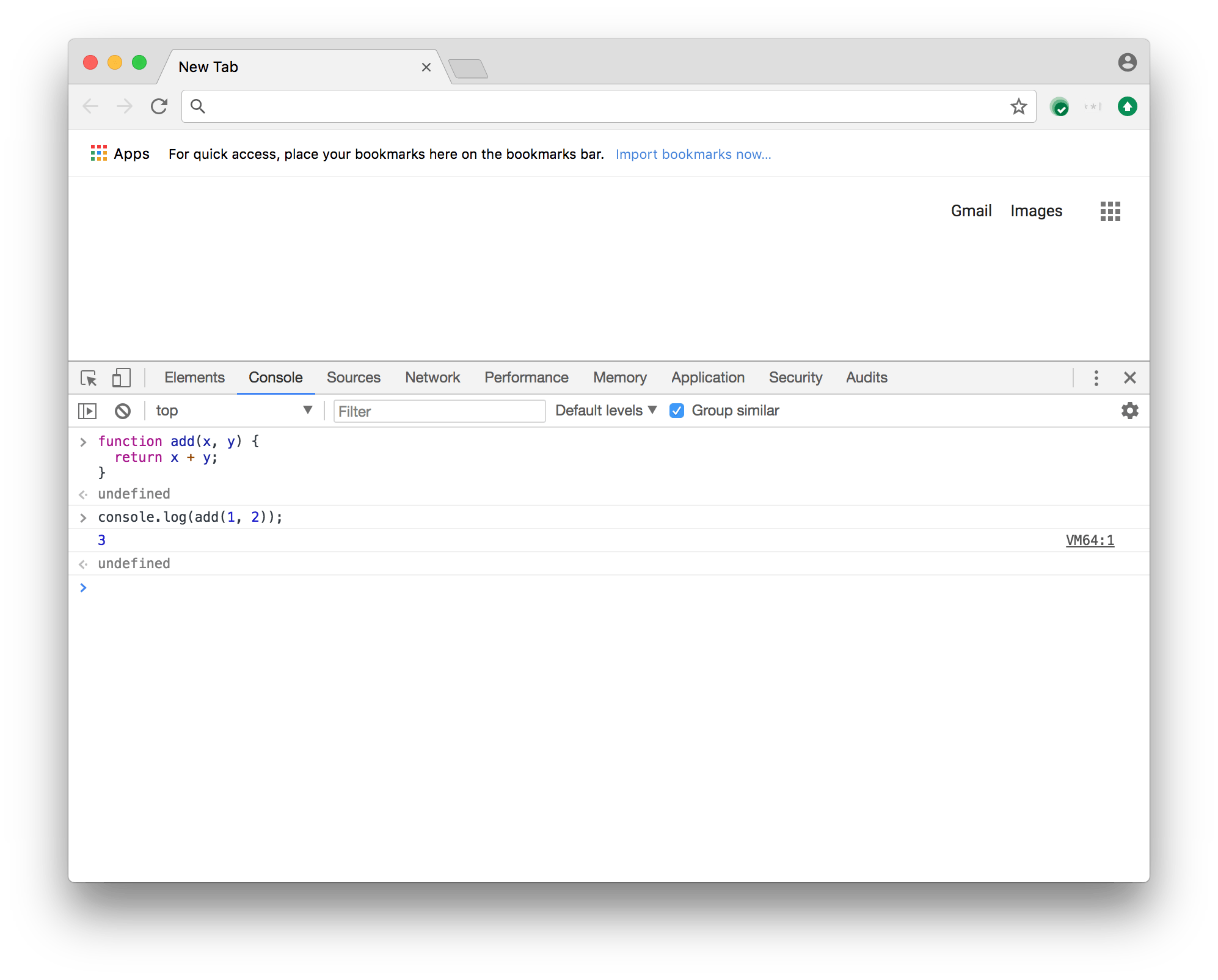
让我们来看看在 V8 的引擎盖下发生了什么,从而得出这些结果。我们将一步一步地完成函数添加。如前所述,我们首先需要解析函数源代码并将其转化为抽象语法树(AST)。这项工作由解析器完成。你可以在 d8 shell 的调试版本中使用 --print-ast 命令行标志查看 V8 内部生成的 AST。
$ out/Debug/d8 --print-ast add.js
…
--- AST ---
FUNC at 12
. KIND 0
. SUSPEND COUNT 0
. NAME "add"
. PARAMS
. . VAR (0x7fbd5e818210) (mode = VAR) "x"
. . VAR (0x7fbd5e818240) (mode = VAR) "y"
. RETURN at 23
. . ADD at 32
. . . VAR PROXY parameter[0] (0x7fbd5e818210) (mode = VAR) "x"
. . . VAR PROXY parameter[1] (0x7fbd5e818240) (mode = VAR) "y"这种格式不太容易理解,所以让我们把它形象化。
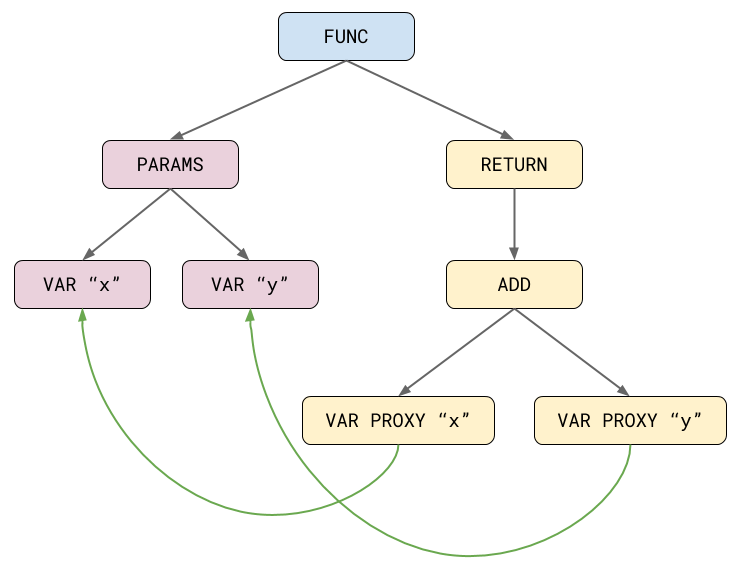
最初,add 的函数字面被解析为树形表示,其中一个子树表示参数声明,另一个子树表示实际的函数体。在解析过程中,我们不可能知道哪些名称对应程序中的哪些变量,这主要是由于 JavaScript 中有趣的 var 挂起规则和 eval,但也有其他原因。因此,解析器最初会为每个名称创建所谓的 VAR PROXY 节点。随后的作用域解析步骤会将这些 VAR PROXY 节点连接到声明的 VAR 节点上,或者将它们标记为全局或动态查找,这取决于解析器是否在周围的某个作用域中看到过 eval 表达式。
这样,我们就得到了一个完整的 AST,其中包含了生成可执行字节码所需的全部信息。然后,AST 将被传递给字节码生成器(BytecodeGenerator),它是 Ignition 解释器中按函数生成字节码的部分。你也可以使用 d8 shell(或 node)中的 --print-bytecode 标志查看 V8 生成的字节码。
$ out/Debug/d8 --print-bytecode add.js
…
[generated bytecode for function: add]
Parameter count 3
Frame size 0
12 E> 0x37738712a02a @ 0 : 94 StackCheck
23 S> 0x37738712a02b @ 1 : 1d 02 Ldar a1
32 E> 0x37738712a02d @ 3 : 29 03 00 Add a0, [0]
36 S> 0x37738712a030 @ 6 : 98 Return
Constant pool (size = 0)
Handler Table (size = 16)这说明为函数 add 生成了一个新的字节码对象,该函数接受三个参数:隐式接收器 this 以及显式形式参数 x 和 y。该函数不需要任何局部变量(帧大小为零),并包含四个字节码序列:
StackCheck
Ldar a1
Add a0, [0]
Return要解释这一点,我们首先需要了解解释器的工作原理。Ignition 使用所谓的寄存器机(与 FullCodegen 编译器中早期 V8 版本使用的堆栈机方法不同)。它将本地状态保存在解释器寄存器中,其中一些寄存器映射到真正的 CPU 寄存器,而另一些寄存器则映射到本地机器堆栈内存中的特定插槽。
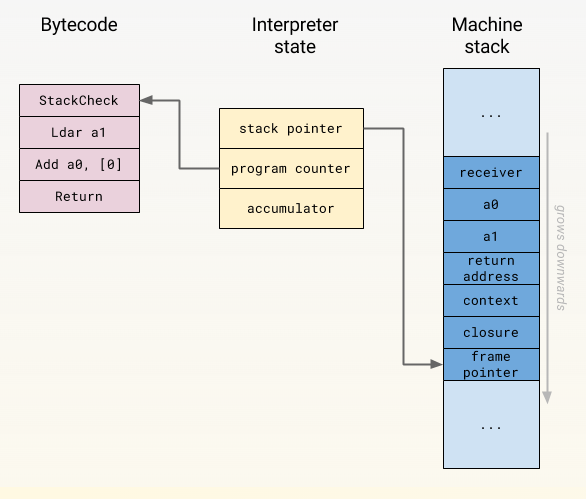
特殊寄存器 a0 和 a1 与机器堆栈上的函数形参相对应(本例中有两个形参)。形式参数是源代码中声明的参数,可能与运行时传递给函数的实际参数不同。每个字节码的最后计算值通常保存在一个称为累加器的特殊寄存器中,当前堆栈帧或激活记录由堆栈指针标识,程序计数器指向字节码中当前执行的指令。让我们来看看本例中各个字节码的作用:
- StackCheck 将堆栈指针与某个已知上限(实际上是下限,因为在 V8 支持的所有架构上,堆栈都是向下增长的)进行比较。如果堆栈增长超过某个阈值,我们就会中止函数的执行,并抛出一个 RangeError(堆栈溢出错误)。
- Ldar a1 将寄存器 a1 的值加载到累加器寄存器中(名字代表LoaD Accumulator Register )
- Add a0, [0] 将 a0 寄存器中的值加载到累加器寄存器中。然后将结果再次放入累加器寄存器。请注意,这里的加法也可以指字符串连接,而且根据操作数的不同,这个操作可以执行任意的 JavaScript。JavaScript 中的 "+"运算符确实很复杂,有很多文章来说明其复杂性。Add 运算符的 [0] 操作数指的是反馈向量槽(feedback vector slot),Ignition 在此存储了我们在函数执行过程中看到的值的剖析信息。我们稍后在研究 TurboFan 如何优化函数时会再讨论这个问题。
- Return 结束当前函数的执行,并将控制权转回调用函数。返回值是累加器寄存器中的当前值。
关于V8中字节码如何工作可以看“Understanding V8’s Bytecode”。
推测优化(Speculative Optimization)
现在,您已经大致了解了 V8 如何在基线情况下执行 JavaScript,是时候开始研究 TurboFan 如何融入其中,以及如何将 JavaScript 代码转化为高度优化的机器代码了。在 JavaScript 中,"+"运算符已经是一个非常复杂的运算,在最终对输入进行数字加法运算之前,它必须进行大量的检查。

如何仅用几条机器指令就能达到峰值性能(可与 Java 或 C++ 代码媲美),并不是一目了然的。这里神奇的关键词是 "推测优化",它利用了对可能输入的假设。例如,当我们知道在 x+y 的情况下,x 和 y 都是数字时,我们就不需要处理其中任何一个是字符串的情况,或者更糟糕的情况--操作数可以是任意的 JavaScript 对象,我们需要先在这些对象上运行抽象操作 ToPrimitive。

知道 x 和 y 都是数字还意味着我们可以排除可观察到的副作用--例如,我们知道它不能关闭计算机或写入文件或导航到不同的页面。此外,我们还知道该操作不会抛出异常。这两点对于优化来说都很重要,因为优化编译器只有在确定表达式不会导致任何可观察到的副作用并且不会引发异常的情况下,才能消除该表达式。
由于 JavaScript 的动态特性,我们通常要到运行时才能知道精确的值类型,也就是说,仅仅通过查看源代码,我们通常不可能知道操作的输入可能是什么值。这就是为什么我们需要根据之前收集到的反馈信息来推测迄今为止我们所看到的值,然后假定我们在未来总是会看到类似的值。这听起来可能有一定的局限性,但对于 JavaScript 这样的动态语言来说,它已经被证明是行之有效的。
function add(x, y) {
return x + y;
}在本例中,我们收集了输入操作数和 + 操作(添加字节码)结果值的信息。当我们使用 TurboFan 对代码进行优化时,到目前为止我们只看到了数字,因此我们会进行检查,以确定 x 和 y 都是数字(在这种情况下,我们知道结果也将是数字)。如果其中任何一项检查失败,我们就会重新解释字节码--这个过程称为去优化(Deoptimization)。因此,TurboFan 不需要担心 + 运算符的所有其他情况,甚至不需要输出机器码来处理这些情况,而可以专注于数字的情况,这可以很好地转换为机器指令。
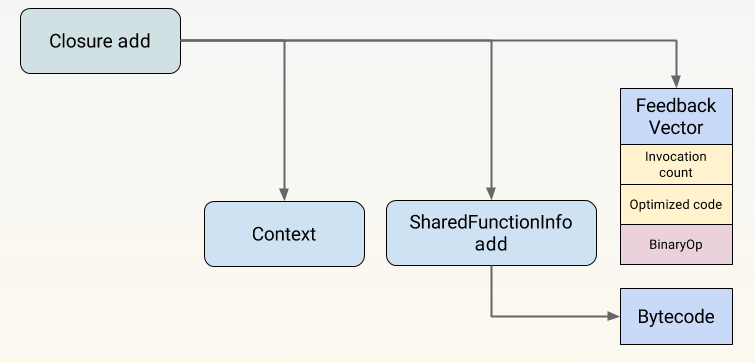
Ignition 收集的反馈信息存储在所谓的反馈向量(以前称为Type Feedback Vector)中。这种特殊的数据结构从闭包链接而来,根据具体的内联缓存(IC),包含用于存储不同类型反馈(即比特集、闭包或隐藏类)的插槽。迈克尔-斯坦顿(Michael Stanton)在“V8 and How It Listens to You”中详细解释了反馈向量的一些概念。闭包还链接到 SharedFunctionInfo,其中包含有关函数的一般信息(如源位置、字节码、严格/松散模式等),同时还链接到上下文,其中包含函数自由变量的值,并提供对全局对象(即 <iframe> 特定数据结构)的访问。
在 add 函数中,反馈向量正好有一个有趣的槽(除了调用计数槽等一般槽之外),这就是二进制操作槽(BinaryOp slot),其中的 +、-、* 等二进制操作可以记录到目前为止所看到的输入和输出的反馈。当使用 --allow-natives-syntax 命令行标志(在 d8 的调试版本中)运行时,你可以使用专门的 %DebugPrint() 本征来查看特定闭包的反馈向量。
function add(x, y) {
return x + y;
}
console.log(add(1, 2));
%DebugPrint(add);在 d8 中使用--allow-natives-syntax,我们可以观察到:
$ out/Debug/d8 --allow-natives-syntax add.js
DebugPrint: 0xb5101ea9d89: [Function] in OldSpace
…
- feedback vector: 0xb5101eaa091: [FeedbackVector] in OldSpace
- length: 1
SharedFunctionInfo: 0xb5101ea99c9 <SharedFunctionInfo add>
Optimized Code: 0
Invocation Count: 1
Profiler Ticks: 0
Slot #0 BinaryOp BinaryOp:SignedSmall
…我们可以看到调用次数为 1,因为我们只运行了一次 add 函数。此外,我们还没有优化过的代码(输出为令人困惑的 0)。但在反馈向量中正好有一个槽,它是一个二进制操作槽,其当前反馈是 SignedSmall。这意味着什么?到目前为止,指向反馈槽 0 的字节码 Add 只看到 SignedSmall 类型的输入,也只产生 SignedSmall 类型的输出。
但这个 SignedSmall 类型是怎么回事呢?JavaScript 中并没有这种类型。这个名字来源于 V8 在表示小有符号整数值时所做的优化,这些值在程序中出现的频率很高,值得特殊处理(其他 JavaScript 引擎也有类似的优化)。
value表示
让我们简要探讨一下 JavaScript 值在 V8 中是如何表示的,以便更好地理解其基本概念。V8 使用一种称为指针标记(Pointer Tagging)的技术来表示一般值。我们处理的大多数值都位于 JavaScript 堆中,必须由垃圾回收器(GC)进行管理。但对于某些值来说,始终在内存中分配它们的成本太高。尤其是那些经常用作数组索引和临时计算结果的小整数值。
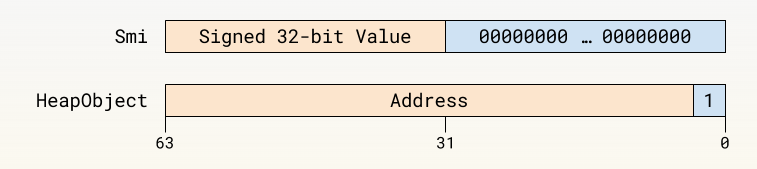
在 V8 中,我们有两种可能的标记表示法: Smi(小整数的缩写)和堆对象(HeapObject),后者指向托管堆中的内存。我们利用了所有已分配对象都按字边界(64 位或 32 位,取决于体系结构)对齐这一事实,这意味着 2 或 3 个最小有效位始终为 0。我们使用最小有效位来区分 HeapObject(位为 1)和 Smi(位为 0)。对于 64 位架构上的 Smi,最小有效位 32 位实际上全部为 0,有符号的 32 位值存储在字的上半部分。这样做的目的是为了使用一条机器指令就能高效访问内存中的 32 位值,而无需加载和移位,同时也是因为在 JavaScript 中,32 位算术运算是位运算的常用方法。
在 32 位架构中,Smi 表示法将最小有效位设置为 0,并将 31 位有符号数值向左移 1,存储在字的上 31 位。
Feedback Lattice
SignedSmall 反馈类型指的是所有具有 Smi 表示的值。对于 Add 操作来说,这意味着到目前为止,它只看到了用 Smi 表示的输入,而且产生的所有输出也都可以用 Smi 表示(即数值没有超出 32 位整数的可能范围)。让我们来看看,如果我们还调用其他不能用 Smi 表示的数字来进行 add 运算,会发生什么情况。
function add(x, y) {
return x + y;
}
console.log(add(1, 2));
console.log(add(1.1, 2.2));
%DebugPrint(add);在 d8 中使用--allow-natives-syntax 再次运行,我们可以观察到:
$ out/Debug/d8 --allow-natives-syntax add.js
DebugPrint: 0xb5101ea9d89: [Function] in OldSpace
…
- feedback vector: 0x3fd6ea9ef9: [FeedbackVector] in OldSpace
- length: 1
SharedFunctionInfo: 0x3fd6ea9989 <SharedFunctionInfo add>
Optimized Code: 0
Invocation Count: 2
Profiler Ticks: 0
Slot #0 BinaryOp BinaryOp:Number
…首先,我们看到调用次数现在是 2,因为我们运行了两次函数。然后,我们看到 BinaryOp 插槽的值变成了 Number,这表明我们已经看到了加法中的任意数字(即非整数值)。对于加法,有一个可能的反馈状态格(lattice),大致如下所示:
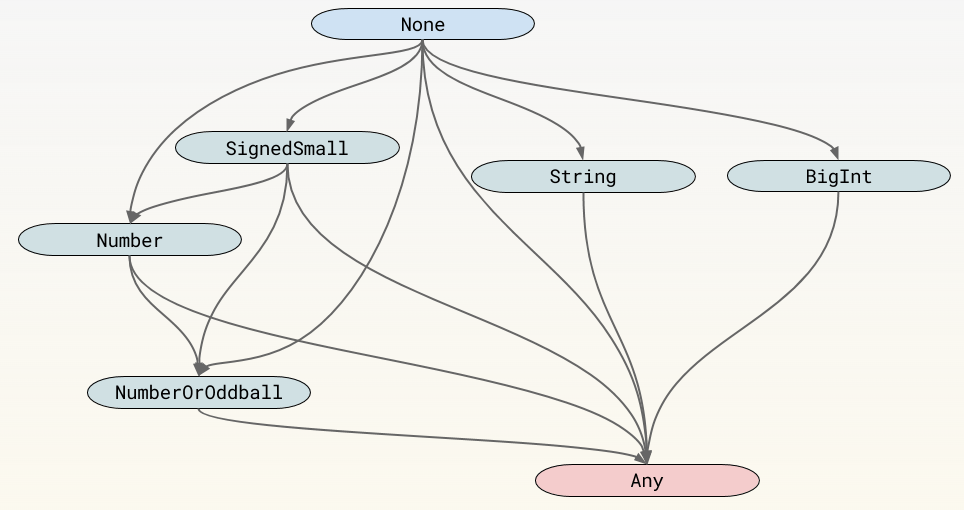
反馈开始时为 "无",表示我们到目前为止什么都没看到,所以我们什么都不知道。Any 状态表示我们看到了不兼容的输入或输出组合。因此,Any 状态表明 Add 被认为是多态的。与此相反,其余的状态表明 Add 是单态的,因为它只看到并产生了在某种程度上相同的值。
- SignedSmall 表示所有值都是小整数(有符号的 32 位或 31 位,取决于体系结构的字大小),并且都用 Smi 表示。
- Number 表示所有值都是常规数(包括 SignedSmall)。
- NumberOrOddball 包括 Number 中的所有值,以及undefined、null、true 和 false。
- String 表示输入都是字符串。
- BigInt 表示两个输入都是 BigInts,详情请参见stage 2 proposal。
需要注意的是,反馈只能在这个网格中进行。我们不可能回到过去。如果我们回到过去,那么就有可能进入所谓的去优化循环,在这个循环中,优化编译器会消耗反馈,并在看到与反馈不一致的值时从优化代码中退出(返回解释器)。下一次函数变热时,我们最终会再次对其进行优化。因此,如果我们没有在网格中取得进展,那么 TurboFan 将再次生成相同的代码,这实际上意味着它将再次在同类输入中退出。这样,引擎就会忙于优化和取消优化代码,而不是高速运行 JavaScript 代码。
优化流程
既然我们已经知道 Ignition 是如何收集 add 函数的反馈信息的,那就让我们看看 TurboFan 是如何利用这些反馈信息来生成最小代码的。我将使用特殊的本征 %OptimizeFunctionOnNextCall() 在非常特定的时间点触发 V8 中函数的优化。我们经常使用这些内在函数来编写测试,以特定的方式对引擎施加压力。
function add(x, y) {
return x + y;
}
add(1, 2); // Warm up with SignedSmall feedback.
%OptimizeFunctionOnNextCall(add);
add(1, 2); // Optimize and run generated code.在这里,我们通过传入两个整数值(其和也符合小整数范围),用 SignedSmall 反馈明确地为 x+y 预热。然后,我们告诉 V8,当下次调用 add 时,它应该(使用 TurboFan)优化函数,最终我们调用 add,触发 TurboFan,然后运行生成的机器代码。
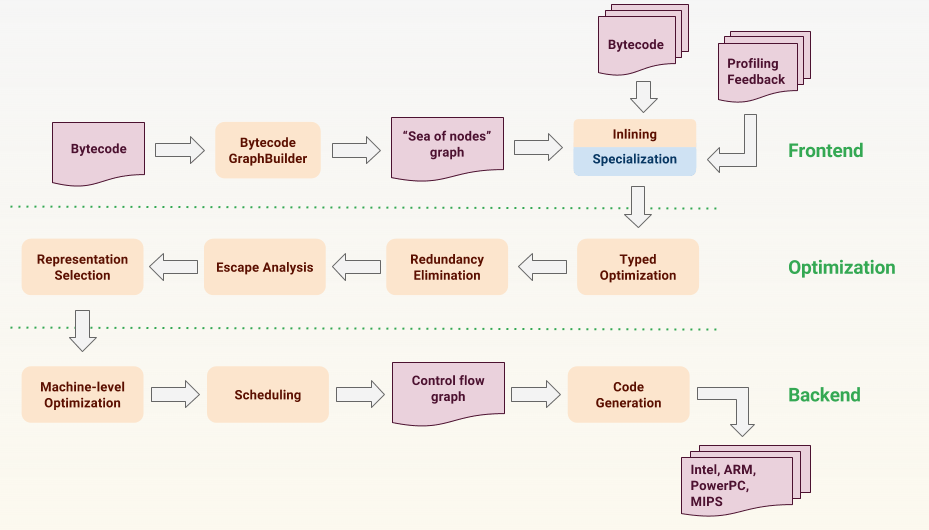
TurboFan 接收之前为 add 生成的字节码,并从 add 的 FeedbackVector 中提取相关反馈。它将其转化为图形表示法,并将图形传递到前端、优化和后端各个阶段。我不会在这里详述传递的细节,这是一篇单独的博文(或一系列单独的博文)的主题。我们将查看生成的机器代码,了解推测优化是如何工作的。你可以通过向 d8 传递 --print-opt-code 标志来查看 TurboFan 生成的代码。

这是 TurboFan 生成的 x64 机器代码,其中有我的注释,并省略了一些无关紧要的技术细节(如去优化器的精确调用顺序)。让我们来看看代码都做了些什么:
# Prologue
leaq rcx,[rip+0x0]
movq rcx,[rcx-0x37]
testb [rcx+0xf],0x1
jnz CompileLazyDeoptimizedCode
push rbp
movq rbp,rsp
push rsi
push rdi
cmpq rsp,[r13+0xdb0]
jna StackCheck 序幕检查代码对象是否仍然有效,或者是否有某些条件发生了变化,需要我们丢弃代码对象。“Internship on Laziness”有相关介绍。一旦知道代码仍然有效,我们就会构建堆栈框架,并检查堆栈上是否有足够的空间来执行代码。
# Check x is a small integer
movq rax,[rbp+0x18]
test al,0x1
jnz Deoptimize
# Check y is a small integer
movq rbx,[rbp+0x10]
testb rbx,0x1
jnz Deoptimize
# Convert y from Smi to Word32
movq rdx,rbx
shrq rdx, 32
# Convert x from Smi to Word32
movq rcx,rax
shrq rcx, 32然后,我们从函数的主体开始。我们从堆栈中加载参数 x 和 y 的值(相对于 rbp 中的帧指针),并检查这两个值是否具有 Smi 表示(因为 + 的反馈信息表明这两个输入到目前为止一直都是 Smi)。这需要测试最小有效位。一旦知道这两个值都是 Smi 表示,我们就需要将它们转换为 32 位表示,方法是将值向右移动 32 位。
如果 x 或 y 不是 Smi,优化代码的执行会立即中止,去优化器会恢复添加前解释器中的函数状态。
题外话:我们也可以在 Smi 表示上执行加法运算;我们之前的优化编译器 Crankshaft 就是这么做的。这样可以省去移位的麻烦,但目前 TurboFan 并没有一个很好的启发式来决定在 Smi 上执行操作是否有利,这并不总是一个理想的选择,而且高度依赖于使用此操作的上下文。
# Add x and y (incl. overflow check)
addl rdx,rcx
jo Deoptimize
# Convert result to Smi
shlq rdx, 32
movq rax,rdx
# Epilogue
movq rsp,rbp
pop rbp
ret 0x18然后,我们继续对输入执行整数加法。我们需要明确测试是否有溢出,因为加法的结果可能超出 32 位整数的范围,在这种情况下,我们需要返回解释器,解释器将学习加法的数字反馈。最后,我们通过将带符号的 32 位数值上移 32 位,将结果转换回 Smi 表示形式,然后返回累加器寄存器 rax 中的数值。
如前所述,对于这种情况来说,这还不是完美的代码,因为在这里,直接在 Smi 表示上执行加法运算比在 Word32 上执行加法运算更有好处,这样可以节省三条移位指令。不过,即使抛开这个小问题不谈,我们也可以看到生成的代码经过了高度优化,并且专门针对剖析反馈。在这里,它甚至没有尝试处理其他数字、字符串、大 ints 或任意 JavaScript 对象,而只是专注于我们目前看到的这类数值。这正是许多 JavaScript 应用程序达到峰值性能的关键因素。
进一步
那么,如果你突然改变主意,想改用数字加法呢?让我们把例子改成这样:
function add(x, y) {
return x + y;
}
add(1, 2); // Warm up with SignedSmall feedback.
%OptimizeFunctionOnNextCall(add);
add(1, 2); // Optimize and run generated code.
add(1.1, 2.2); // Oops?!使用--allow-natives-syntax 和--trace-deopt 运行时,我们观察到以下情况:
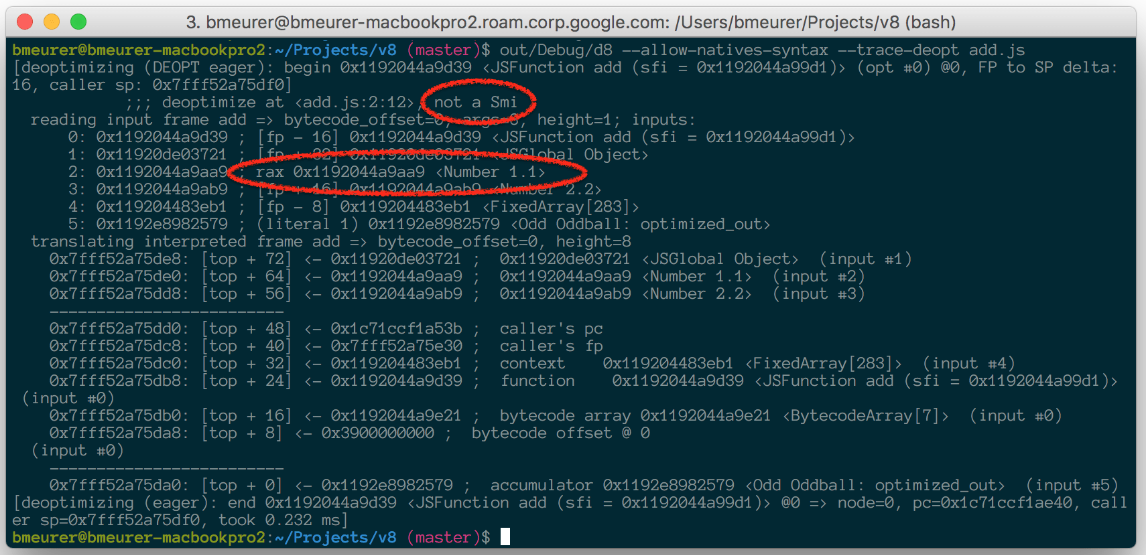
这些输出令人困惑。但让我们提取重要的部分。首先,我们打印出了不得不取消优化的原因,在这种情况下,它不是一个 Smi,这意味着我们在某个地方假定一个值是一个 Smi,但现在我们看到的却是一个 HeapObject。事实上,rax 中的值应该是一个 Smi,但它却变成了数字 1.1。因此,我们对 x 参数的第一次检查失败了,我们需要取消优化,重新解释字节码。不过这将是另一篇文章的主题。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号