玩转Jmeter进行性能测试
原创

一:实施背景
时逢6.18钉钉应用大促,为避免高负载下钉钉微应用的稳定性问题,遂赶工赶时完成钉钉方要求的稳定性压测,以此为楔,深探Jmeter,事后总结,是以成文。不愿窃为私有,分享给诸位QA同学,以期遇坑绕之,少些弯路。
1.1 任务目标
钉钉方对此次压测任务解释如下:
1. 稳定性专项的目的是希望和服务商一起保障服务稳定可用,为用户提供更可靠的服务;主要包括以下内容:
2. 系统架构,包括服务器、数据、容器等
3. 监控配置,报告系统监控(cpu、内存等)和业务监控(QPS、RT等)
4. 首页性能情况
5. 压测情况
6. 降级方案,用于流程突增时,系统及时处理保证服务运行
已上架 | 查看监控线上最高QPS为xxx(可查询近2个月最高QPS等) | 要求压测至少支持:峰值QPS的3~5倍 |
|---|
(1)提供单链路或全链路压测数据及最高支持的QPS上限,各业务场景下列各项值:
a.峰值RT<=100ms
b.峰值错误率(统计非200)<=0.1%
c.峰值总cpu利用率<=70%
d.峰值load1<=cpu总核数-0.5
e.峰值内存利用率<=80%
(2)ISV服务端授权激活场景,服务端响应时间整体小于3s
这样一来,我们的目标很明显,就是验证QPS是日常峰值3~5倍情况下,服务器的资源占用,RT,QPS是否满足要求。
1.2 调研选型
由于时间仓促,我在选型压测工具时只对比了自己比较熟悉的工具Jmeter和LR,而LR只能使用破解版的(HP和微软这些厂商很鸡贼的,你想用破解版的那就用吧,等把你养肥了啃你一口大的,他们的策略也很套路 就是广撒网,总有那么几家会上钩的,对吧),并且钉钉方明确建议使用Jmeter,那就没啥好说的了,直接上Jmeter吧。
二:环境配置&安装目录解释
2.1 Windows环境下安装Jmeter
Step1:配置Java开发环境,话不多说。
Step2:下载Jmeter:https://jmeter.apache.org/download_jmeter.cgi
解压后设置环境变量JMETER_HOME(设置为Jmeter的安装目录)
2.2 Mac下配置Jmeter
Step1:配置Java开发环境。
Step2:下载Jmeter并解压。
Step3:配置bash_profile(切换到当前用户主目录即:cd,然后查看隐藏文件ls –al即可看到这个文件,若无,自己建),加入以下内容。
export JMETER_HOME=/Users/mc/Applications/apache-jmeter PATH=$JMETER_HOME/bin:$PATH:.
export PATH
然后执行,source .bash_profile即可,我们输入jmeter.sh验证下结果如下:
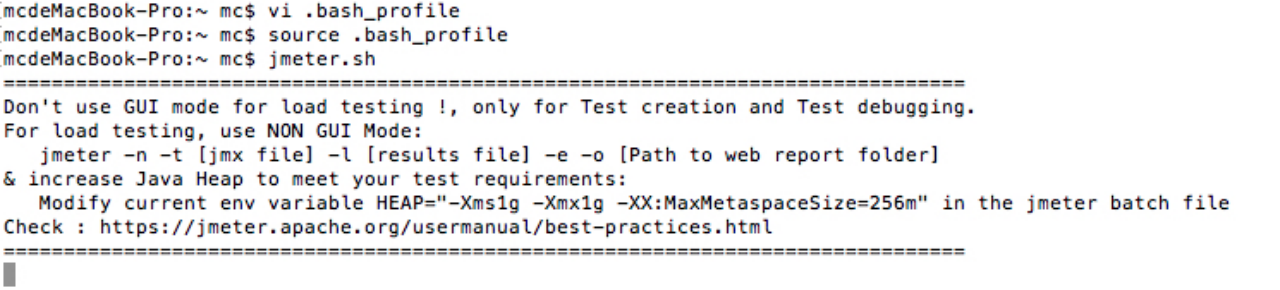

2.3 目录解释

bin:可执行文件目录。以下文件是我们经常会用到的。
jmeter.bat 可以设置jemeter使用的内存(ps:建议配置为负载机物理内存的1/4~1/2)
jmeter.sh:Linux和Mac下启动Jmeter GUI
jmeter-server(.bat):jmeter联系负载设置文件。
jmeter.properties:jmeter的80%以上的配置项均在该文件中配置;一旦该配置文件被改动,只有重启jmeter才生效。
docs:jmeter API文档
extras:Jmeter拓展。
lib: jmeter启动时默认的classpath。使用jmeter进行测试时所有需要import的包和类必须存在该目录下。
lib/ext:存放jmeter的组件/插件,第三方组件和插件也要放置在该目录下。
所有图形化GUI中可见,可使用的部分必须放置在lib/ext目录下。
printable_docs:jmeter官方帮忙文档。
三:Jmeter常用的元件
3.1 测试计划
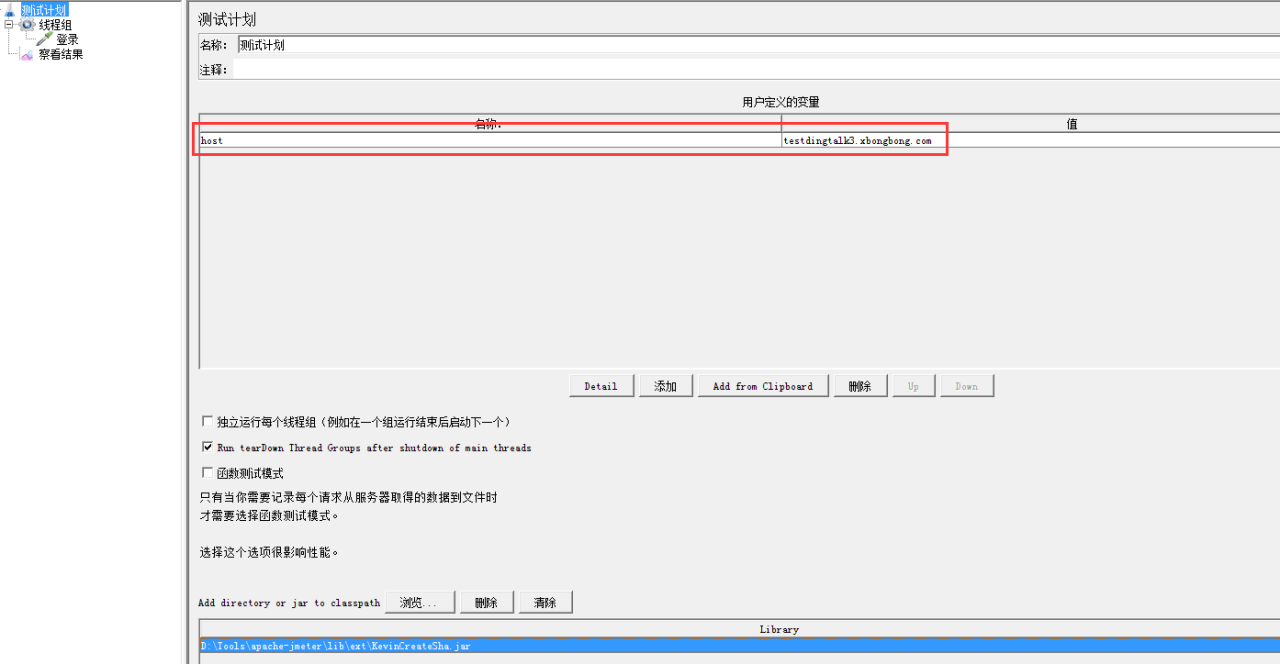
测试计划中可以做以下事情:
1:定义全局变量 2:控制线程组的执行方式 3:引入外部拓展的jar包。
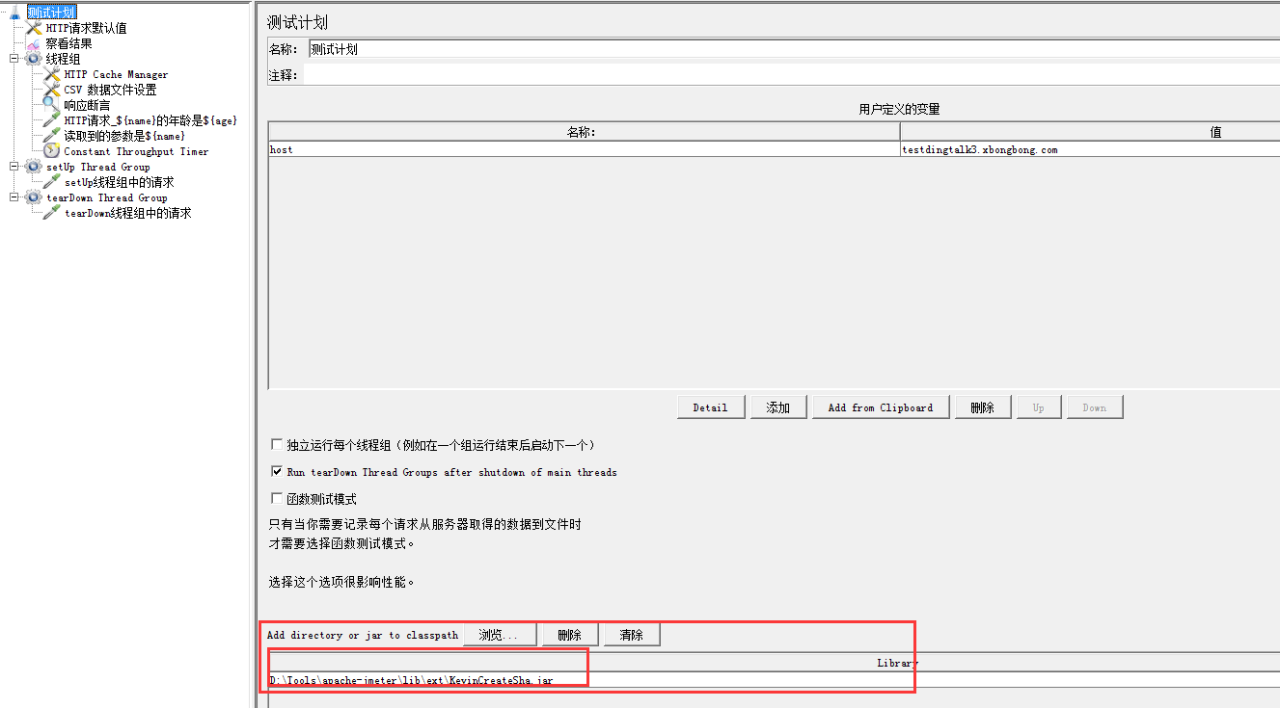
如图:定义全局变量host,后续的请求中可以通过${host}来使用这个变量值。
最下方蓝色框中是需要依赖的外部jar包,这个包是生成sha-256加密字符串用的,后续在bean shell前置处理器那里我会详细说明。
注意:对于<独立运行每个线程组>这个选项,如果一个测试计划中有多个线程组,设置此项可生效,不设置时:每个线程组同时运行。
3.2 线程组
3.2.1 线程组的类别
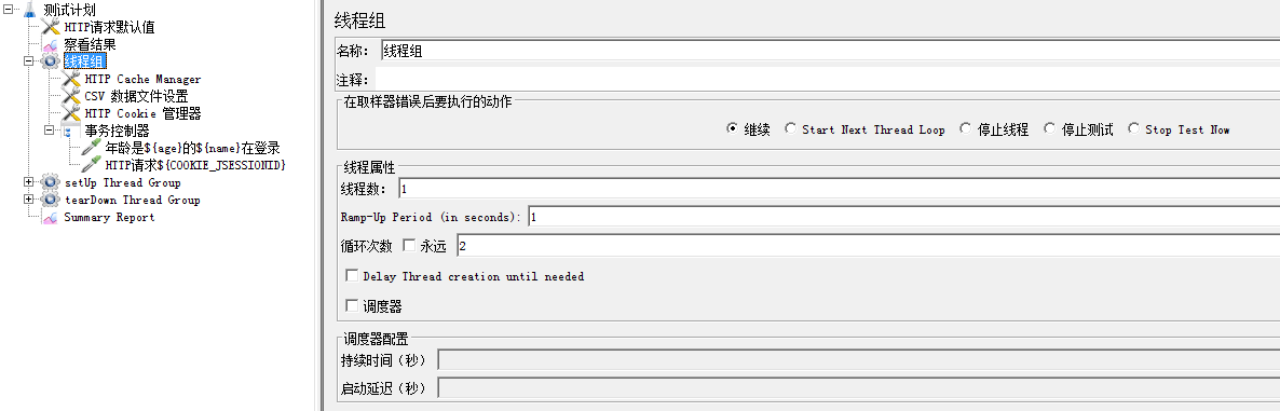
Jmeter中的线程组有3中,分别是:thread group,setup thread group,tearDown thread group。
手动划重点
三种线程组无本质区别,都可以实现多线程的效果。如果在测试计划下只存在一种的话,是没有区别的。区别在于若3中线程组同时存在于一个测试计划下时会存在执行先后的区别:setUp先执行,然后再执行thread group; 最后执行tearDown线程组。
1:线程数=虚拟用户数。
2:Ramp-up Peroid:启动所有线程所需的总时间。
ps:Jmeter中,线程启动的方式采用平均时间计算,线程的最小单位是1;最终效果即:1线程/N秒。N=线程数/Ramp-Up Peroid。
线程组只能指定线程第一次启动时的间隔时间,不能控制之后的循环过程中的线程的间隔。
3:循环次数 每一个线程执行线程组内的组件的次数。
4:Delay Thread creation until needed:
5:调度器:设置线程组计划的启动时间和持续时间。
5.1:调度器是在点击启动后生效。
5.2:启动延迟的优先级别高于启动时间。
5.3:持续时间的优先级高于结束时间。
5.4:线程的停止条件是-->循环次数或持续时间满足设置。
3.2.2 线程组各配置项的意义

1:线程数就是允许当前线程组下脚本的线程数,等效于LR中的Vusers,即:虚拟用户数。
2:Ramp-Up period:在多久时间内启动指定的线程数。
3:循环次数是指虚拟用户循环多少次线程组内的所有请求。
3.3 配置元件
用来配置脚本运行时所需的一些环节值,配置原件是全局的,是在Sampler运行之前编译执行的。
3.3.1 HTTP请求默认值

实际项目中,我们的请求肯定有很多是公用是部分,比如:服务器名称,编码,协议。
我们可以把这部分内容提取出来做封装,当然,Jmeter为我们提供了HTTP请求默认值。
如上图,我将每个请求的协议,服务器名称,编码三项配置在HTTP请求默认值中,后续的HTTP请求就可以不用填写这些内容了。
后续HTTP请求如下:
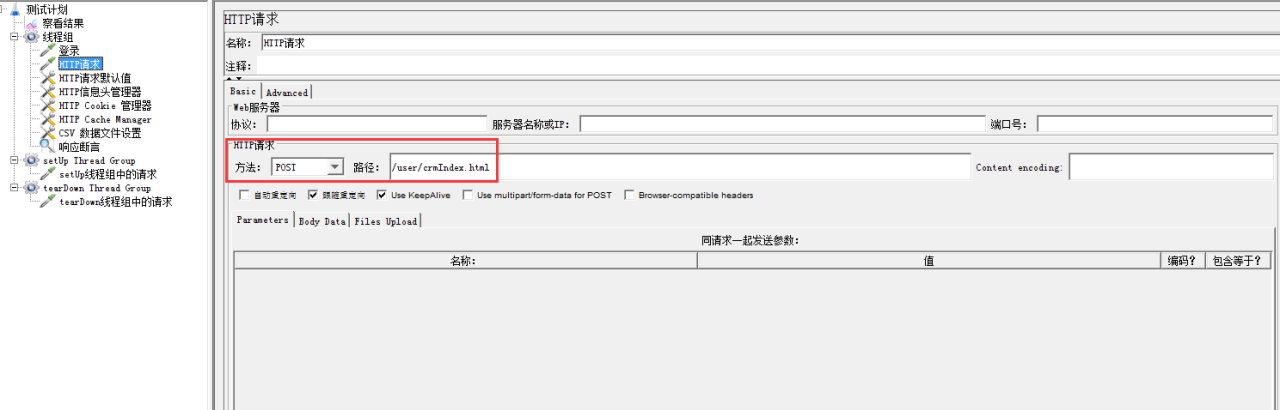
如上图,协议,服务器名称,Content Encoding3项可以为空,因为Jmeter会使用HTTP请求默认值中的配置,如果在HTTP请求中配置了这3项则会覆盖HTTP请求默认值的配置。
3.3.2 HTTP信息头管理器

顾名思义,就是将请求的头部信息集中管理起来。
3.3.3 HTTP Cookie管理器
1. Cookie 管理器就像一个 web 浏览器那样存储并发送 cookie。 如果你有一个 HTTP 请求,其返回结果里包含一个 cookie,那么 Cookie 管理器会自动将该 cookie 保存起来,而且以后所有的对该网站的请求都使用同一个 cookie。每个 JMeter 线程都有自己独立的"cookie 保存区域"。因此,如果你在测试网站的时候使用了 Cookie 管理器来存储 session 信息的话,那么每个 JMeter 线程将会拥有自己独立的 session。**注意这些 cookie 不会显示在 Cookie 管理器里,你可以通过察看结果树来对其进行察看。 2. 接收到的 cookie 数据可以作为 JMeter 线程的参数进行存储 要将 cookie 存储为参数,定义属性"CookieManager.save.cookies=true"。cookie 在被保存之前会在名字上加上 "COOKIE_" 前缀(避免和本地参数重复)。设置好一会名字为 TEST 的 cookie 可以用 ${COOKIE_TEST} 进行引用。如果不希望这个前缀可以对属性 "CookieManager.name.prefix=" 进行定义。 3. 手工添加一个 cookie 到 Cookie 管理器 注意如果你这么干了,这个 cookie 将被所有 JMeter 线程所共享。这种方式用于创建有很长过期日期的 cookie。
3.3.4 HTTP Cache Manager

管理线程组下所有请求的缓存。
3.3.5 CSV数据文件设置

文件名:参数文件的地址,可以是相对路径,也可以是绝对路径。此外,也可以使用Jmeter的用户自定义变量来参数化参数文件的路径。
注意:相对路径的根目录是Jmeter的启动目录(即:%JMETER_HOME%\bin或${JMETER_HOME/bin})。
文件编码:读取参数文件使用的编码格式,此处一定要和参数文件的编码格式一致,强烈建议使用UTF-8格式保存参数文件。
变量名称:定义的参数名称,用逗号隔开,将会与参数文件中的参数对应;如果此处参数个数比参数文件中的参数列多,多余的参数取不到值;反之,参数文件中的部分列将无参数对应。
忽略首行:是否忽略第一行,跟进实际情况定,如果首行是你定义的列名,可以设置为True。
分隔符:用来分割参数文件的分隔符,默认为逗号;如果参数文件中用tab分隔,此处应为”\t”。
是否允许带引号?:如果设置为True,则允许分隔完成的参数里面有分隔符出现。
遇到文件结束符再次循环?:设置为True,则参数文件循环遍历;设置为False,则参数文件遍历完成后不循环(Jmeter在测试执行过程中每次迭代会从参数文件中心取一行数据,从头遍历到尾)。
遇到文件结束符停止线程?:和<遇到文件结束符再次循环>设置为False时复用,设置为True则停止测试;设置为False则不停止。
线程共享模式:
1所有线程:参数文件对所有线程共享,包括同一测试计划中的不同线程组。
2当前线程组:值对当前线程组中的线程共享。
3当前线程:仅当前线程获取参数。


3.4 定时器
运行在作用域内的每一个请求之前,和组件本身的先后次序无关,而且运行次数等于作用域内的请求数量。
3.4.1 固定定时器
固定定时器可以用来模拟用户思考时间。
定时器放在不同的组件下,其作用域不同。如果放置在线程组下,则线程组内每个请求间的间隔都会是这个设置固定定时器延迟时长。
3.4 2 高斯定时器
固定延迟是指设置的固定思考时间,实际线程运行中的思考是时间是以固定延迟为基础浮动一定的偏差,高斯定时器也用来模拟用户思考时间。
3.4.3 Synchronizing Timer
Synchronizing Timer用来模拟集合点
注意:这里的超时设置的是到达集合点的第一个虚拟用户的等待时间。和LR不一样,LR中设置的超时是Vuser之间的等待时间。
3.4.4 Constant Throughput Timer
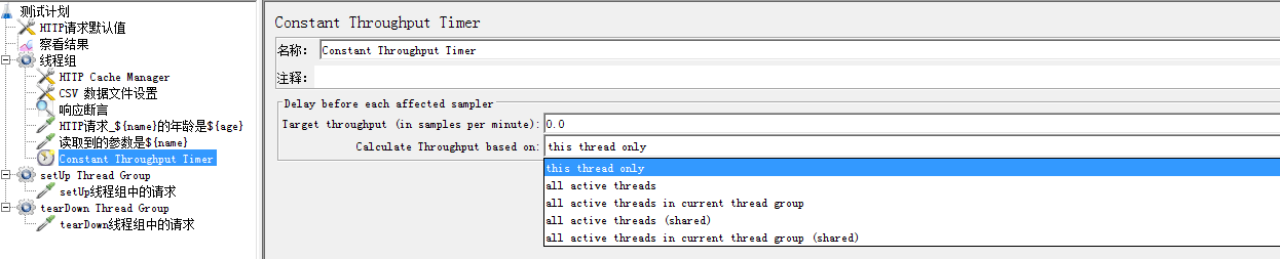
吞吐量定时器,可尽量保持吞吐量在一定范围内。
吞吐量计算模式有5中
1 This thread only:仅针对当前线程,即:线程间互不干扰。
2 All active threads:针对所有线程,把所有线程的吞吐量合在一起作为因子计算。
3 All active threads in current thread group:针对当前线程组中的所有线程。
4 All active threads(shared):线程延迟计算是基于任意一个线程上次运行的时间,也就是随便获取一个线程的运行时间来进行计算。
5 All active threads in current thread group(shared):在当前线程组中任取一个线程的上次运行时间来计算延迟,和4相近。
3.5 前置处理器
运行在作用域内的每一个请求之前,和组件本身的先后次序无关,而且运行次数等于作用域内的请求数量。
3.5.1 BeanShell PreProcessor
这里以实际例子来说明吧,我们这里的每个请求都会将请求的param和accessToken组成的字符串进行sha-256加密,然后作为sign_code成为每个请求中的一部分,所以我们这里使用BeanShell前置处理器先把每个请求的sign_code生成。
Java源码如下:
package SHA;
import java.io.UnsupportedEncodingException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
//类createSha 根据每个请求的报文体和access-token生成sha256字符串
public class createSha {
public static String getInitString(String request_content, String access_token) {
String content = request_content + access_token;
MessageDigest messageDigest;
String encodeStr = "";
try {
messageDigest = MessageDigest.getInstance("SHA-256");
messageDigest.update(content.getBytes("UTF-8"));
encodeStr = byte2Hex(messageDigest.digest());
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return encodeStr.toLowerCase();
}
/*
*将byte转为16进制
*/
private static String byte2Hex(byte[] bytes) {
StringBuffer stringBuffer = new StringBuffer();
String temp = null;
for (int i=0;i<bytes.length;i++) {
temp = Integer.toHexString(bytes[i] & 0xFF);
if(temp.length()==1) {
stringBuffer.append("0");
}
stringBuffer.append(temp);
}
return stringBuffer.toString();
}
}然后将工程导出jar包放置在Jmeter安装目录下的lib/ext目录中。
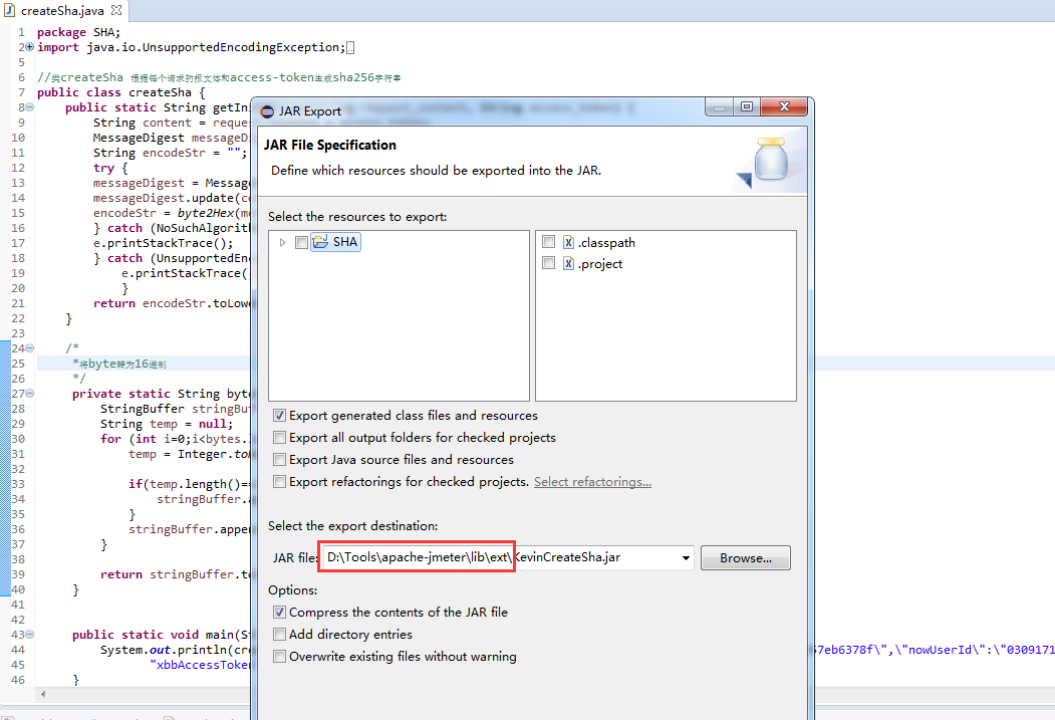
在Jmeter中引用Jar包:
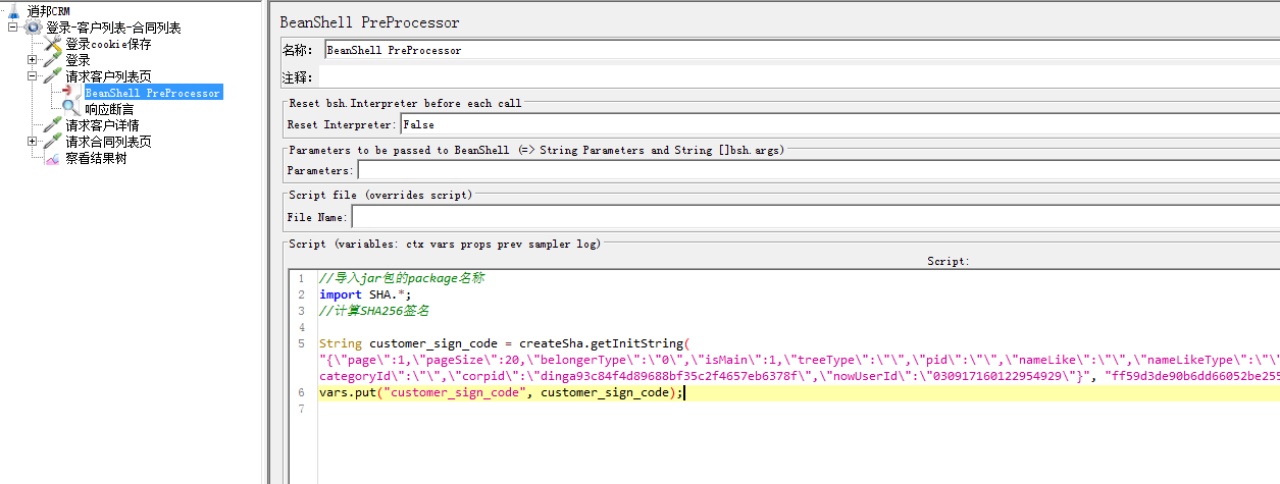
//导入jar包的package名称
import SHA.*;
//计算SHA256签名
String customer_sign_code = createSha.getInitString("{\"page\":1,\"pageSize\":20,\"belongerType\":\"0\",\"isMain\":1,\"treeType\":\"\",\"pid\":\"\",\"nameLike\":\"\",\"nameLikeType\":\"\",\"isArchived\":0,\"child\":\"customer\",\"categoryId\":\"\",\"corpid\":\"dinga93c84f4d89688bf35c2f4657eb6378f\",\"nowUserId\":\"030917160122954929\"}", "ff59d3de90b6dd66052be25524444cb208e652482880040e28fe0eb26334f28b");
vars.put("customer_sign_code", customer_sign_code);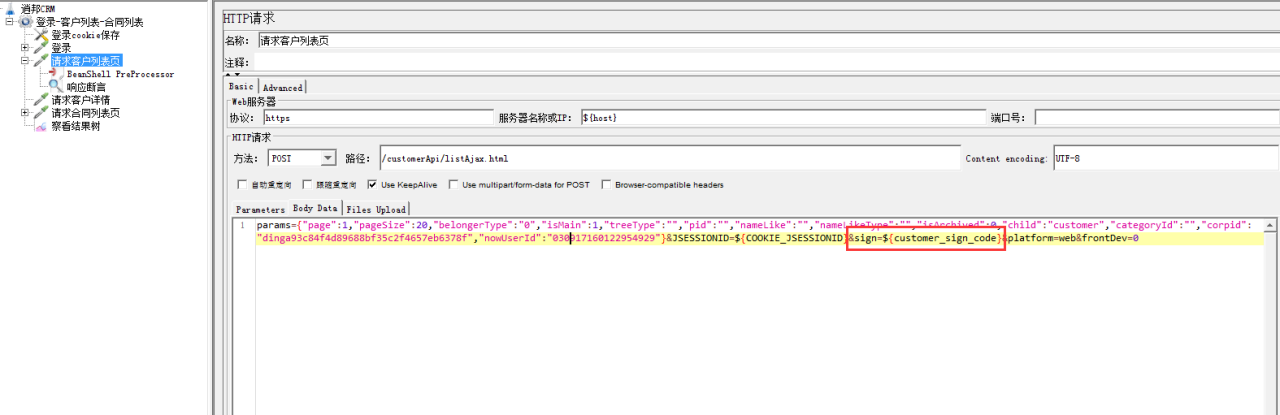
3.6 后置处理器
运行在作用域内的每一个请求之后,和组件本身的先后次序无关,而且运行次数等于作用域内的请求数量。
3.6.1 正则表达式提取器

引用名称:输出的参数名称;参数的值受到正则表达式匹配内容的影响。
正则表达式:自己多多摸索,这是必备技能。
模板:常量最后引用名称就会获取常量的值,位置变了$N$:表示将匹配到的第N个内容的值赋值给引用变量。
匹配数字:正整数:将第N次的模板指定的括号的值传递给变量。数字0:随机将匹配的数据传递给变量。
缺省值:如果正则表达式匹配不到数据,则会使用缺省值,一般留空即可。
3.7 断言
最常用的是<响应断言>
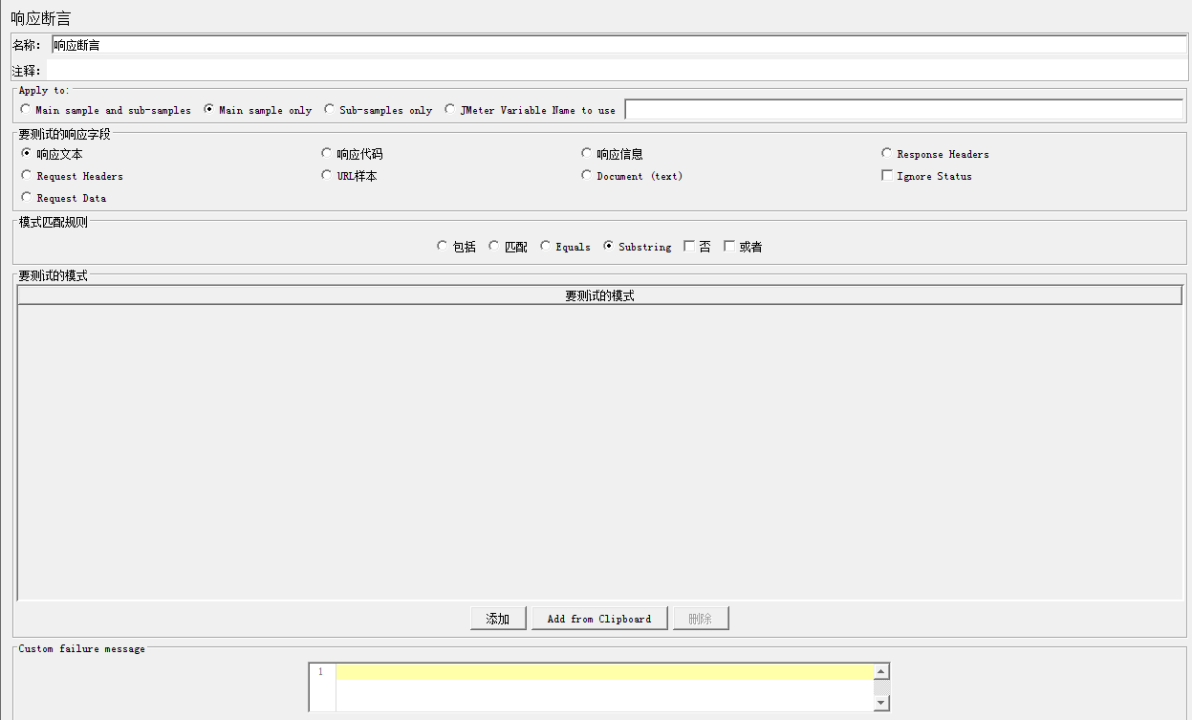
APPly to:适用范围
Main sample and sub-samples:作用于父节点取样器及对应子节点取样器
Main sample only:仅作用于父节点取样器
Sub-samples only:仅作用于子节点取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
要测试的响应字段:要检查的项
响应报文
Documeng(text):测试文件
URL样本
响应代码
响应信息
Response Headers:响应头部
Ignore status:忽略返回的响应报文状态码
模式匹配规则:
包括:返回结果包括你指定的内容
匹配:(好像跟Equals查不多,弄不明白有什么区别)
Equals:返回结果与你指定结果一致
Substring:返回结果是指定结果的字串
否:不进行匹配
要测试的模式:即填写你指定的结果(可填写多个),按钮【添加】、【删除】是进行指定内容的管理
3.8 逻辑控制器
控制Jmeter中各种组件的执行逻辑。
3.8.1 ForEach Controller(循环控制器)
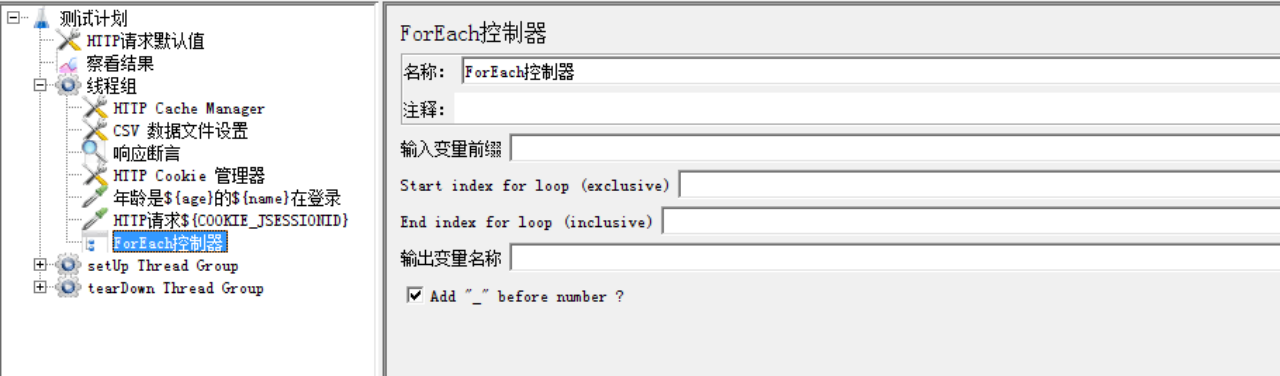
ForEach控制器一般和用户自定义变量一起使用,其在用户自定义变量中读取一系列相关的变量。该控制器下的采样器或控制器都会被执行一次或多次,每次读取不同的变量值。如下图:
参数:
· Input Variable Prefix:输入变量前缀
· Output variable name:输出变量名称
· Start index for loop(exclusive):循环开始的索引(这里如果不填写,默认从1开始,如果没有1开始的变量,执行时会报错)
· End index for loop(inclusive):循环结束的索引
· Add”_”before number:输入变量名称中是否使用“_”进行间隔。
3.8.2 Once Only Controller

作用:在测试计划执行期间,该控制器下的子结点对每个线程只执行一次,登录场景经常会使用到这个控制器。
注意:将Once Only Controller作为Loop Controller的子节点,Once Only Controller在每次循环的第一次迭代时均会被执行
3.8.2 Transaction Controller(事务控制器)

Jmeter中默认每个请求是一个事务;类比LR中每个步骤是一个事务。
如果想把多个请求作为一个事务,使用逻辑控制器-事务控制器元件。
Generate parent sample:生成父取样器。
Include duration of timer and pre-post processor in generated sample:响应时间包含前置处理器(不建议勾选)

3.9 监听器
3.9.1 查看结果树
对每个取样器都作记录其详细的请求内容和服务器返回的响应报文。
3.9.2 Summary Report

Label:取样器/监听器名称
Samples :事务数量
Average:平均一个完成一个事务消耗的时间(平均响应时间)
Median:所有响应时间的中间值,也就是 50% 用户的响应时间,大概是这个意思
Min:最小响应时间
Max:最大响应时间
以上单位都是ms
Std.Dev:偏离量,越小表示越稳定
Error %:错误事务率
Throughtput:每秒事务数,即tps
KB/sec:网络吞吐量
3.9.3 其他监听器插件
请到https://jmeter-plugins.org/查看下载您需要的其他插件。
推荐几个不错的。
Plugins Manager:插件管理器
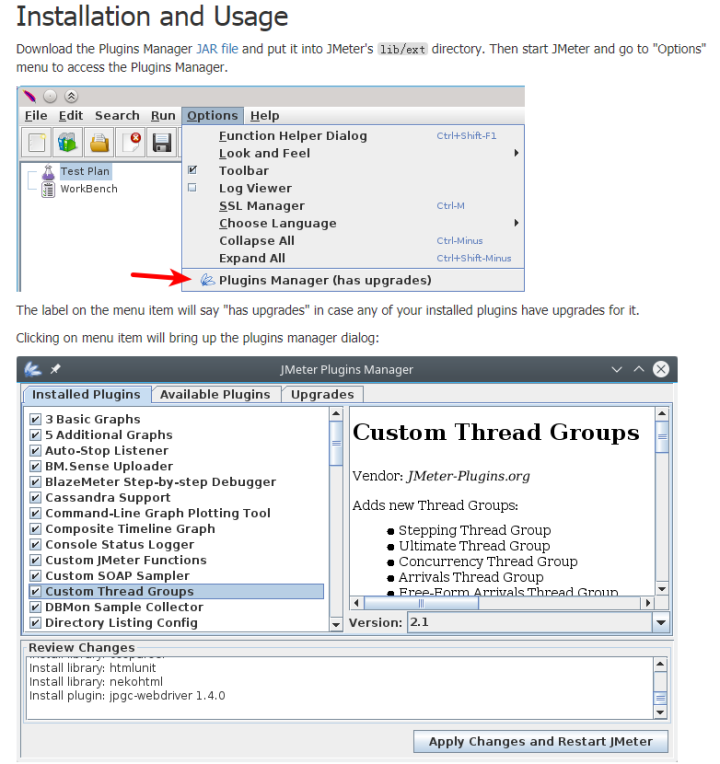
3 Basic Graphs:响应时间vs时间图
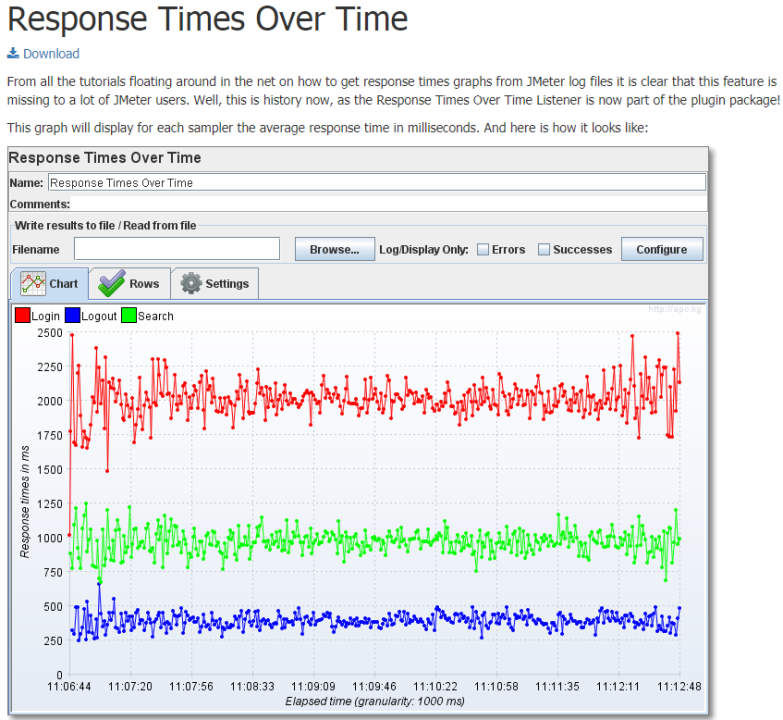
Custom Thread Groups:自定义线程组(下文的浪涌模拟会用到)

四:脚本开发
4.1 使用代理录制
测试计划中添加<非测试元件>-<HTTP代理服务器>
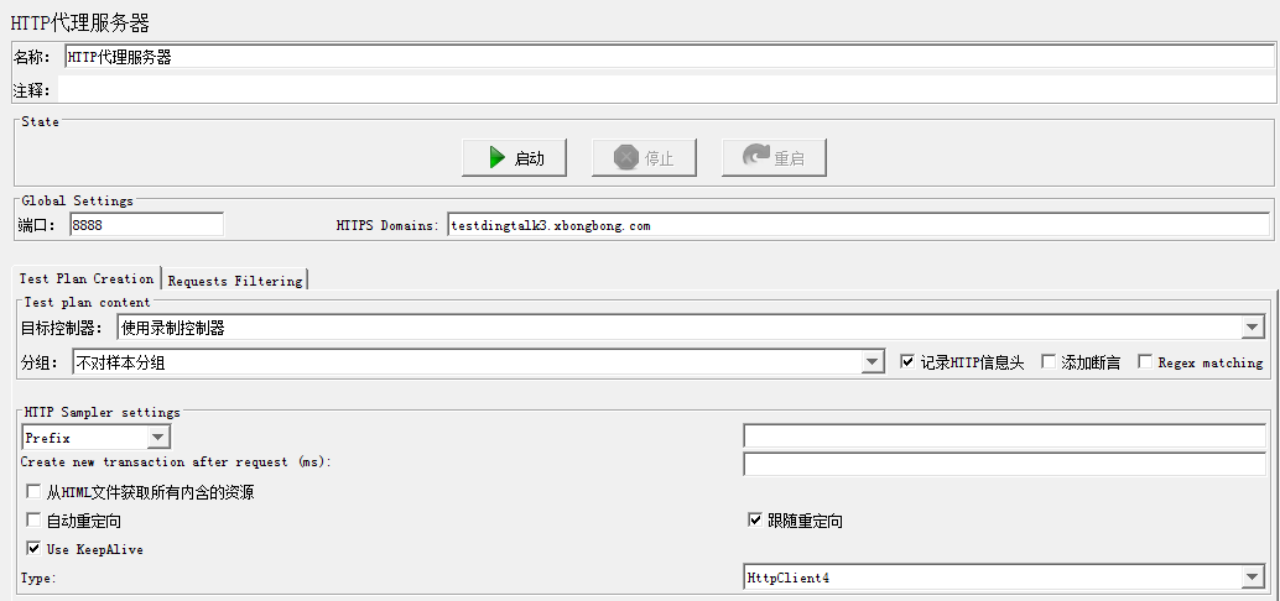
包含模式:只录制所指定的规则请求。
排除模式:不录制所指定的规则请。
重点必考题
Jmeter中的脚本模式是LR中的HTML模式(LR中有URL&HMTL两种模式。) 所以,Jmeter中的静态资源的请求可以手动屏蔽(如果不需要每次都请求静态资源)。切记录制完成后一定要停止代理,还原设置。
4.2 手工开发
4.2.1 抓取报文,手工设置请求
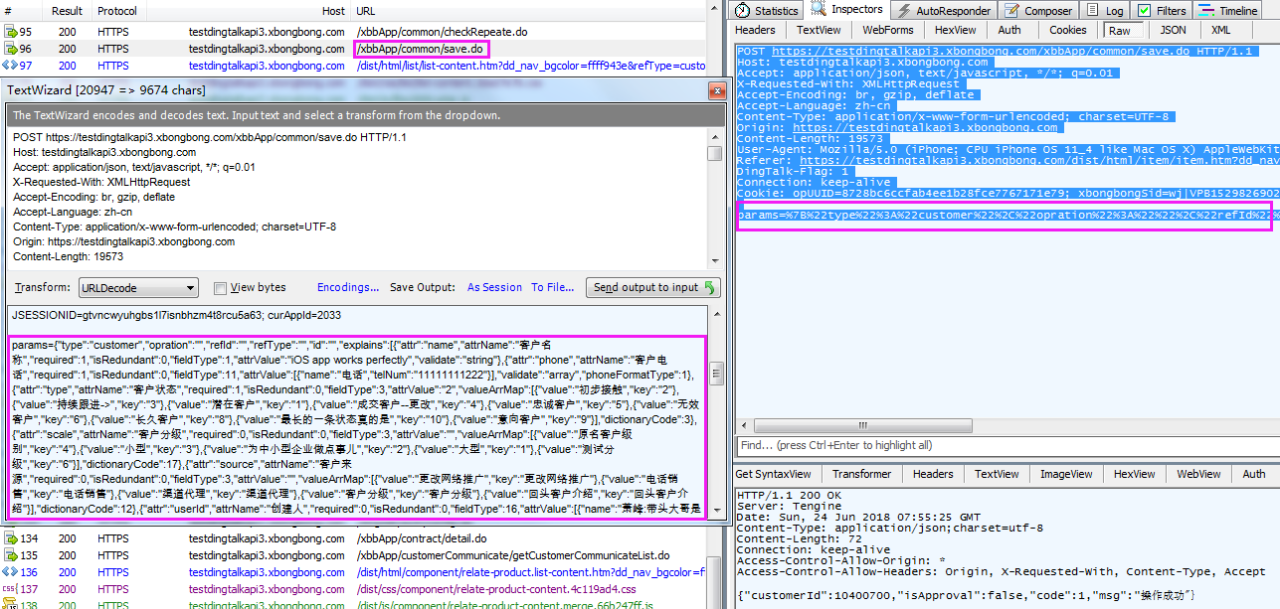
Fiddler抓取报文,然后将请求的body部分写到Jmeter-HTTP请求的Body Data里。

五:场景设计
5.1 参数化
为了实现不同用户的不同请求;即:业务逻辑相同,数据不同。
参数化的实现方式有函数和文件两种方式。
1:使用Jmeter所提供的一些函数来生成参数值。推荐使用函数助手对话框来实现 2:_javascript()函数允许使用js代码来生成一些参数值,但是要求最后一句话是一个变量或变量表达式;这个函数会自动返回最后的变量或者变量表达式的值。
当然也可以使用BeanShell来实现,举例如下:
文件方式实现过程中,参数文件类型可以是.csv或者.txt类型。通过函数或者配置元件-CSV Data Set Config组件实现读取。
两点注意事项
Jmeter中:对变量,参数,函数的使用都是遵循相同的调用格式:${变量名},${参数名},${函数名(形参...)}。
在Jmeter组件中,所有鼠标点击可以输入的地方都可以做参数调用,实现参数化。
5.2 关联设置
关联最终要做的操作本质是:先存后用(先保存服务器响应的一些特殊作用的值,在后续的请求中使用保存的服务器动态响应的值。)
LR中的关联通过函数web_reg_sava_param一系列注册函数(带reg)实现数据保存;Jmeter中通过后置处理器-正则表达式提取器实现。
5.3 检查点
通过断言来实现
5.4 事务
Jmeter中默认每个请求是一个事务;类比LR中每个步骤是一个事务。
如果想把多个请求作为一个事务,使用逻辑控制器-事务控制器元件。
5.5 思考时间
一般使用时间定时器;如:固定/高斯随机定时器。
5.6 集合点
使用定时器-Synchronizing Timer来实现。
注意:这里的超时设置的是到达集合点的第一个虚拟用户的等待时间。和LR不一样,LR中设置的超时是Vuser之间的等待时间。
5.7浪涌模拟
使用Jmeter的第三方插件Custom Thread Groups
有以下几种线程组(模式)可以选择。
1:Stepping Thread Group (deprecated)

2:Arrivals Thread Group
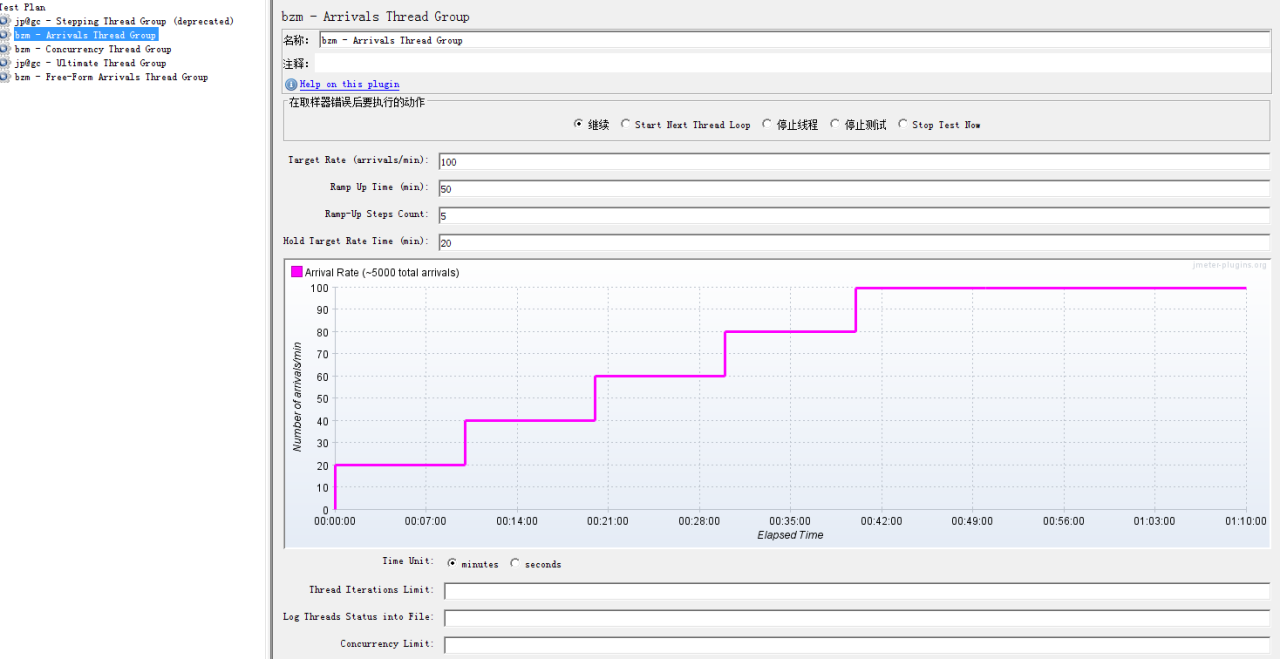
3:Concurrency Thread Group
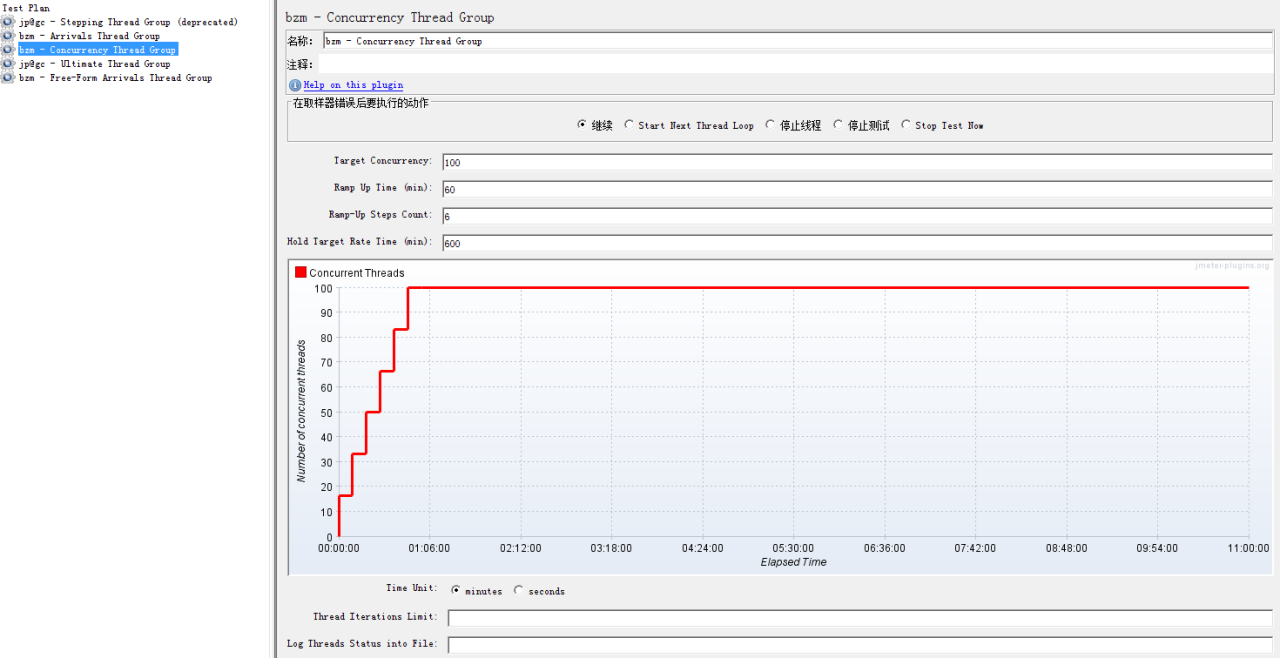
4:Ultimate Thread Group

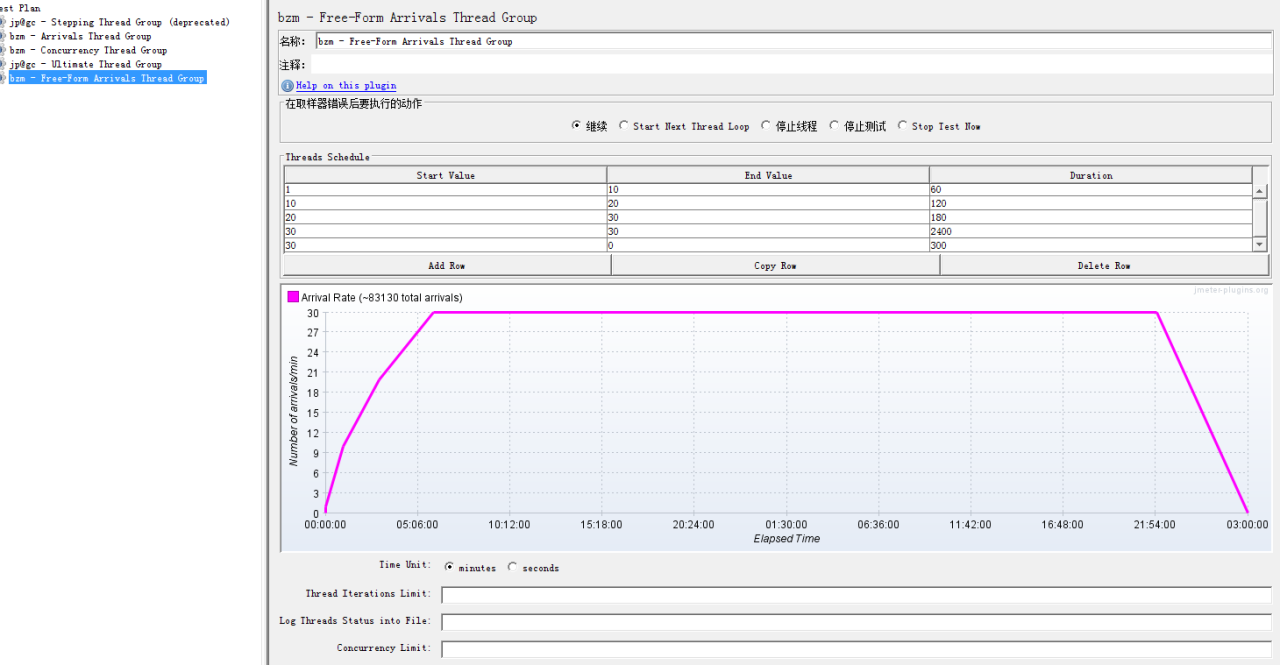
5:Free-Form Arrivals Thread Group
六:实施压测
6.1 命令行执行
-h 帮助 -> 打印出有用的信息并退出
-n 非 GUI 模式 -> 在非 GUI 模式下运行 JMeter
-t 测试文件 -> 要运行的 JMeter 测试脚本文件
-l 日志文件 -> 记录结果的文件
-r 远程执行 -> 在Jmter.properties文件中指定的所有远程服务器
-H 代理主机 -> 设置 JMeter 使用的代理主机
-P 代理端口 -> 设置 JMeter 使用的代理主机的端口号
示例如下:
例1:测试计划与结果,都在%JMeter_Home%\bin 目录
> jmeter -n -t test1.jmx -l result.jtl
例2:指定日志路径的:
> jmeter -n -t test1.jmx -l report\01-result.csv -j report\01-log.log
例3:默认分布式执行:
> jmeter -n -t test1.jmx -r -l report\01-result.csv -j report\01-log.log
例4:指定IP分布式执行:
> jmeter -n -t test1.jmx -R 192.168.10.25:1036 -l report\01-result.csv -j report\01-log.log
例5:生成测试报表
> jmeter -n -t 【Jmx脚本位置】-l 【中间文件result.jtl位置】-e -o 【报告指定文件夹】
> jmeter -n -t test1.jmx -l report\01-result.jtl -e -o tableresult
注意:
1)-e -o之前,需要修改jmeter.properties,否则会报错;
2)-l 与-o 目录不一样,最后生成两个文件夹下。
3)命令中不写位置的话中间文件默认生成在bin下,下次执行不能覆盖,需要先删除result.jtl;报告指定文件夹同理,需要保证文件夹为空
6.2 联机压测
Step1:在负载机上启动jmeter-server.bat
注意事项:jmeter-server通过默认的1099端口进行监听和通信,如果1099端口被占用,需要修改控制机上Jmeter的配置文件jmeter.properties中的server_port属性。
Step2:在控制机上添加负载机。
修改控制机上的Jmeter的配置文件jmeter.properties中的remote_hosts属性(
形式如下:192.168.10.6:1099,192.168.10.168:1099),多台负载机用逗号隔开。
Step3:重启控制机Jmeter,点击远程启动/远程全部启动。
注意事项:
1:联机负载时,脚本的允许环境是负载机的环境,控制机和负载机上Jmeter版本,允许环境,环境变量,jar包,参数文件必须一致
2:如果控制机和负载机的OS相同,脚本中对文件的使用可以通过绝对路径实现,如果OS不同,只能使用相对路径。
3:Jmeter联机负载时,线程组的计划分别,同时在不同的负载机上执行,所以对服务器而言:总压力=线程组设定的压力x负载机数量。Jmeter的联机负载和LR有很大不同,Jmeter的联机负载会使负载翻倍,而LR的联机负载不会改变控制机上设定的负载。
4:和LR一样,报告文件在控制机上查看。
七:压测报告
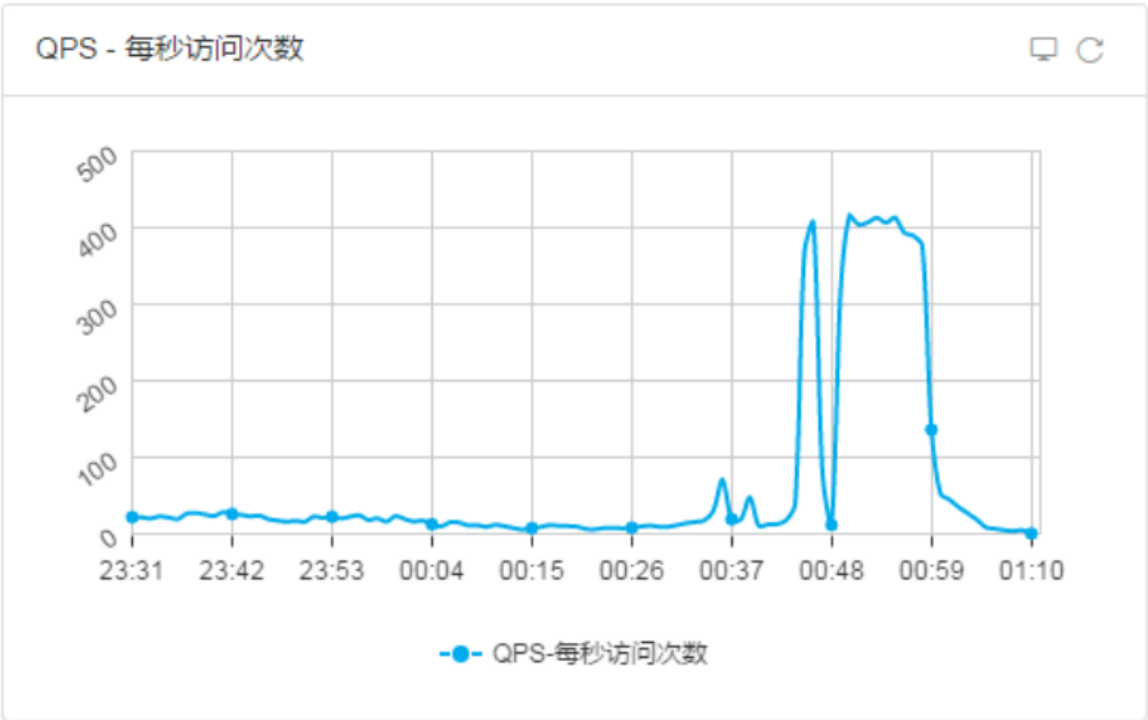
压测过程中我们对服务器进行了监控,重点关注的性能指标如下:
1:QPS-每秒访问次数
2:RT-平均响应时间

3:错误请求数

4:CPU使用率

5:内存使用率
首页请求;客户列表;客户详情页;合同订单列表;合同订单详情页。
通过标准 | 是否符合标准 | 压测值 |
|---|---|---|
预估线上峰值QPS值*3<实际压测值 | 是 | 410 |
峰值RT<=2000ms | 是 | 1.5s |
峰值错误率(统计非200)<=0.1% | 是 | 0.01% |
峰值总cpu利用率<=70% | 是 | 65% |
峰值load1<=cpu总核数-0.5 | 是 | 3 |
峰值内存利用率<=80% | 是 | 75% |
测试结论:
App项目日常QPS 为60,压测(2018-5-31 0:45到0:59)QPS在400左右,RT曲线和错误率曲线在QPS峰值410时出现失败事务(事务失败率0.01%),其他时间段并没有出现明显异常。系统可满足业务需求。
Jmeter的强大之处远远不止文章中提到的这些,很多时候我们完全可以继承AbstractJavaSamplerClient自行开发脚本。
此外,开发能力强的同学,可以对Jmeter进行二次开发或者封装已扩展Jmeter的插件或优化使用体验,当然,刚接触到Jmeter皮毛的我就不抛砖引玉了,希望真正熟悉Jmeter的同学可以作更优秀的分享~ 期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号