CKAD考试实操指南(六)---剖析系统:深入可观察性实践
原创
CKAD考试实操指南(六)---剖析系统:深入可观察性实践
原创
知十
修改于 2023-10-13 08:27:35
修改于 2023-10-13 08:27:35
深入可观察性实践
在这份CKAD考试实操指南中,我将为你详细介绍如何利用CKAD-exercises项目和知十平台进行CKAD考试的准备和复习。通过CKAD-exercises提供的练习题,你可以在知十平台的云原生环境中进行实践和模拟。在这个过程中,你将熟悉Kubernetes的各种操作和场景,并在实践中加深对知识的理解。这种结合实践和理论的学习方式将为你在考试中取得优异成绩提供强有力的支持。
首先,打开浏览器,访问知十平台。在页面右上角点击“登录”,然后使用微信扫码登录即可。

在未登录状态下,每个环境只能体验15分钟,每天有5次机会使用。登录后,每个环境可用时长为1小时,每天登录也有5次的使用机会。
当选择好要进入环境后,通常只需要等待约一分钟左右,就能进入环境中。在等待期间,你可以浏览环境说明文档,了解该环境包含哪些组件及版本。
现在开始第五个主题----可观察性的实操
官网链接及访问路径
这里使用到官网的链接及访问路径如下:
kubernetes.io > Documentation > Reference > Command line tool (kubectl) > kubectl
https://kubernetes.io/docs/reference/kubectl/
kubernetes.io > Documentation > Concepts > Workloads > Pods > Pod Lifecycle
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#container-probes
kubernetes.io > Documentation > Tasks > Configure Pods and Containers > Configure Liveness, Readiness and Startup Probes
题目
存活、就绪、启动探针
1、Create an nginx pod with a liveness probe that just runs the command 'ls'. Save its YAML in pod.yaml. Run it, check its probe status, delete it.
译:创建一个带有存活探针的 nginx pod,该探针只运行命令“ls”。将其 YAML 保存在 pod.yaml 中。运行它,检查其探测状态,将其删除。
# kubectl run nginx: 这部分命令告诉 kubectl 创建一个名为 "nginx" 的资源。在这个上下文中,"nginx" 是资源的名称,可以将其替换为想要的任何其他名称(不能与现有的Pod名称重复)。
# --image=nginx: 这部分指定了要在 Pod 中使用的容器镜像。在这里,使用了名为 "nginx" 的官方镜像作为容器的基础镜像。
# --restart=Never: 这部分指定了 Pod 的重启策略。"Never" 表示如果 Pod 终止,就不要自动重启它。
# --dry-run=client: 这部分告诉 kubectl 在实际创建资源之前模拟操作。它会检查命令是否合法,但不会实际创建 Pod。
# -o yaml: 这部分指定了输出的格式。在这里,它指定将资源定义以 YAML 格式输出。
# > pod.yaml: 这部分将命令的输出重定向到一个名为 "pod.yaml" 的文件中,以便将生成的 Pod 定义保存在这个文件中。
kubectl run nginx --image=nginx --restart=Never --dry-run=client -o yaml > pod.yaml
vi pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
#配置探针部分
livenessProbe: # 存活探针
exec: # 执行命令
command: # 命令定义
- ls # ls 命令
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
#创建pod
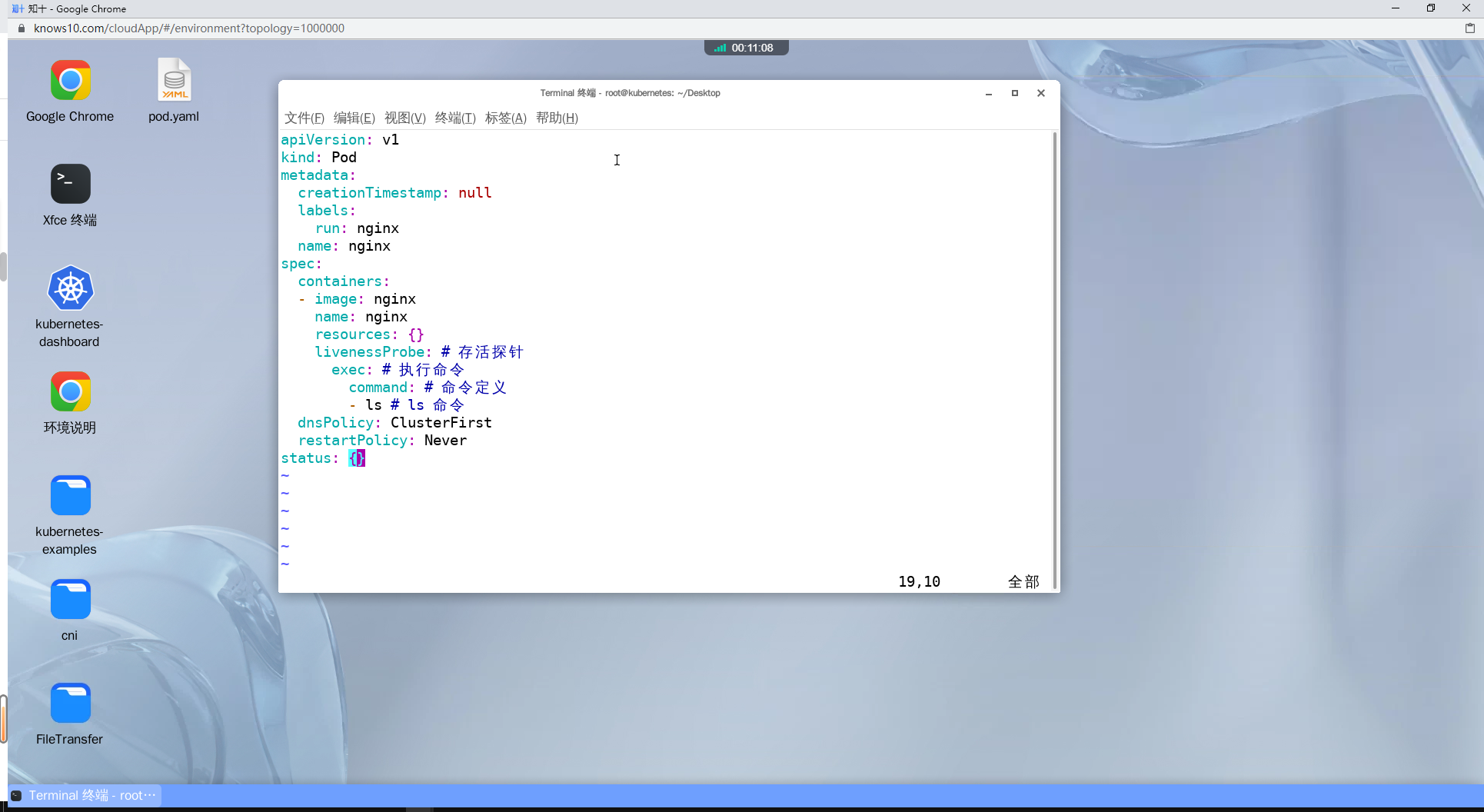
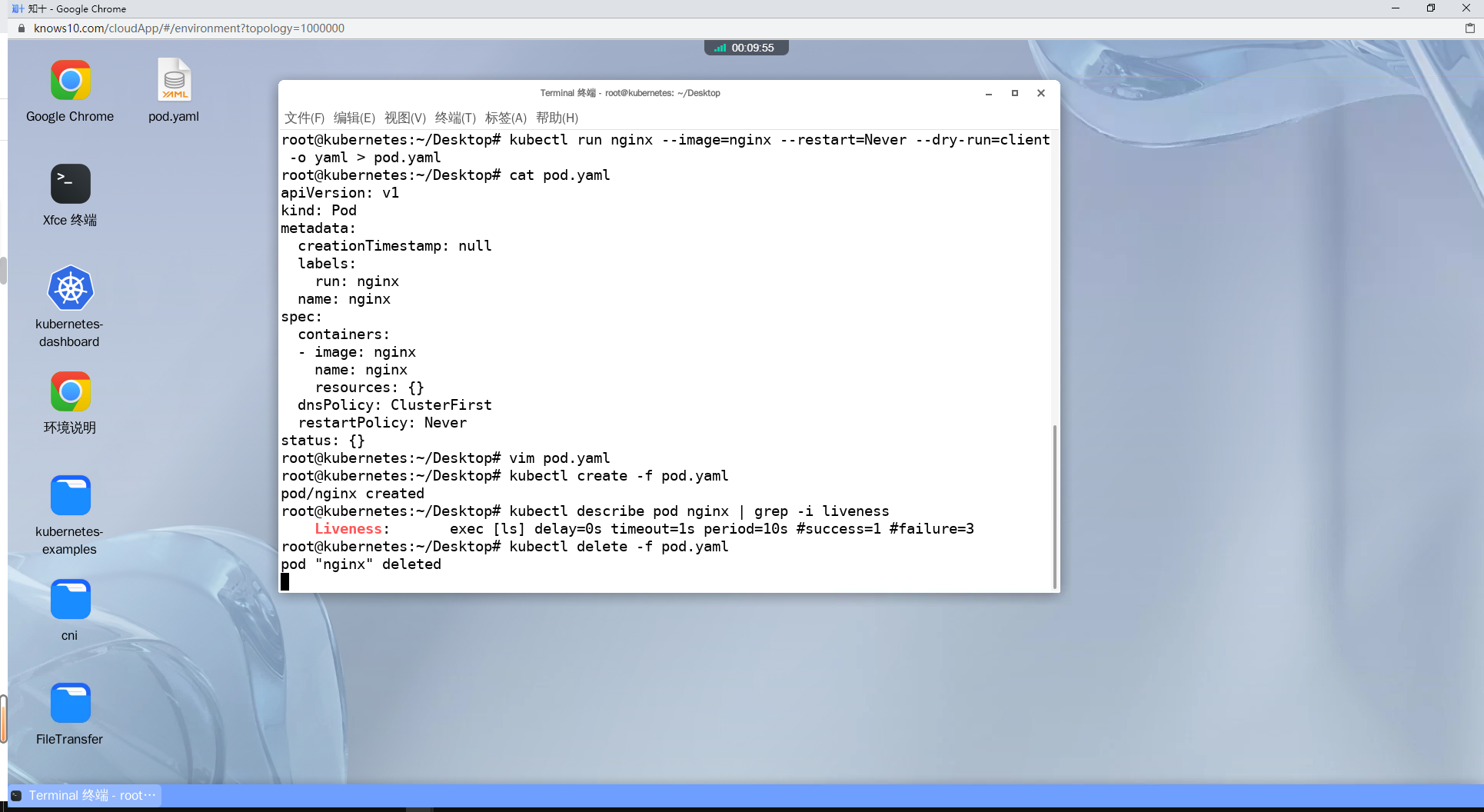
kubectl create -f pod.yaml
#查看pod的存活探针运行的信息
kubectl describe pod nginx | grep -i liveness
#删除pod
kubectl delete -f pod.yaml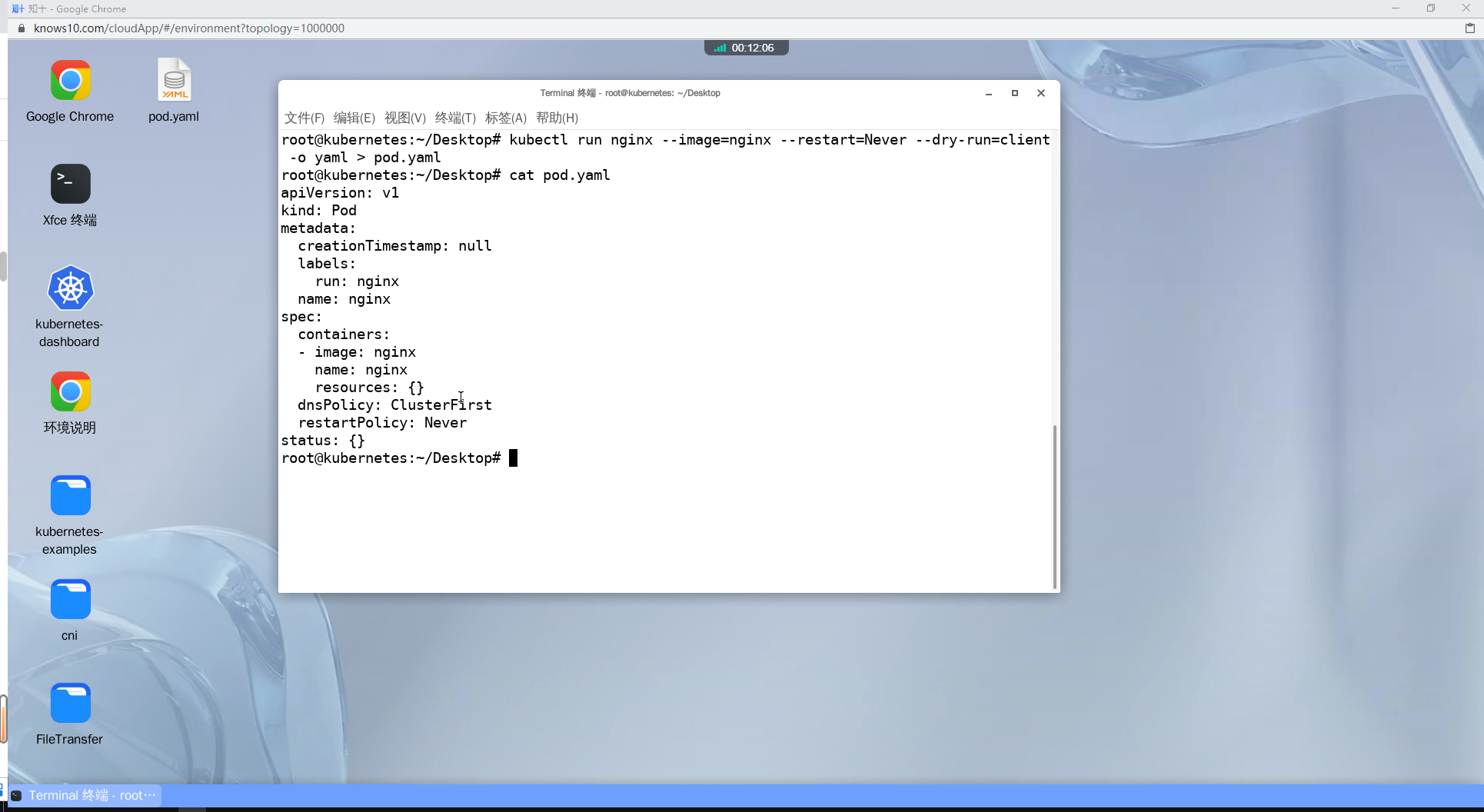
知识点:
- livenessProbe类型及判定探针不健康判定:
- HTTP 探针: 发送 HTTP 请求到容器内指定的端点,检查应用程序是否正常响应。如果返回的 HTTP 状态码表示成功,那么容器被认为是健康的。
- 不健康判定:
- HTTP 请求失败: 如果 HTTP 请求返回的状态码不在成功的范围内(通常是 2xx 系列),就会被认为是不健康的。例如,返回 4xx 或 5xx 的状态码会被解释为应用程序处于不正常状态。
- 连接超时: 如果在预定的超时时间内无法建立 HTTP 连接,探针也会被认为是不健康的。这可能意味着应用程序无法正常响应请求或端口不可达。
- DNS 解析问题: 发送 HTTP 请求时出现 DNS 解析问题,探针会失败,因无法找到目标地址。
- 不健康判定:
- TCP 探针: 尝试与容器内的指定端口建立 TCP 连接。如果连接成功,容器被认为是健康的。
- 不健康判定:
- TCP 连接失败: 如果在预定的超时时间内无法建立 TCP 连接,探针会被认为是不健康的。这可能是由于应用程序未监听指定的端口、端口不可达或防火墙规则等问题。
- 连接超时: 如果在预定的超时时间内无法建立 TCP 连接,探针也会被认为是不健康的。这可能表明应用程序无法正常接受连接。
- 网络问题: 如果在探针尝试建立连接时发生网络故障,如丢包或延迟过高,探针可能会失败。
- 不健康判定:
- Exec 探针: 在容器内运行指定的命令,如果命令成功执行并返回零退出代码,容器被认为是健康的。
- 不健康判定:
- 命令执行失败: 如果在容器内部执行的命令返回非零的退出代码,探针会被认为是不健康的。通常情况下,命令成功执行应该返回零的退出代码,非零的退出代码表示命令执行出现问题。
- 命令超时: 如果执行的命令在预定的超时时间内没有完成,探针会被认为是不健康的。这可能意味着应用程序无法正常处理探针所需的命令。
- 命令不可用: 如果定义的命令在容器内不可用(例如,命令不存在或路径错误),探针会失败。确保命令路径正确且可执行。
- 不健康判定:
- HTTP 探针: 发送 HTTP 请求到容器内指定的端点,检查应用程序是否正常响应。如果返回的 HTTP 状态码表示成功,那么容器被认为是健康的。
- livenessProbe可以设置以下属性来定义探针的行为:
- initialDelaySeconds:容器启动后延迟多少秒开始执行第一次探针检查。
- **periodSeconds**:探针检查之间的时间间隔。- **timeoutSeconds**:探针检查的超时时间。- **successThreshold**:连续多少次成功的探针检查后,容器被认为是健康的。- **failureThreshold**:连续多少次失败的探针检查后,容器被认为是不健康的。- livenessProbe配置示例
- HTTP 探针配置示例:
livenessProbe:
httpGet:
path: /healthz # 替换为应用程序提供的健康检查端点
port: 8080 # 替换为应用程序监听的端口
initialDelaySeconds: 15
periodSeconds: 10- TCP 探针配置示例:
livenessProbe:
tcpSocket:
port: 8080 # 替换为应用程序监听的端口
initialDelaySeconds: 15
periodSeconds: 10- Exec 探针配置示例:
livenessProbe:
exec:
command:
- sh
- -c
- cat /tmp/health.txt # 替换为应用程序检查健康状态的命令
initialDelaySeconds: 15
periodSeconds: 10注意:
- 探针设置合理性: 设置适当的
initialDelaySeconds、periodSeconds、timeoutSeconds、successThreshold和failureThreshold对于确保探针的有效性和准确性非常重要。 - 容器响应时间:
timeoutSeconds应该足够长,以便容器有足够的时间响应探针。过短的超时可能会导致错误的不健康标记。 - 探针命令的正确性: 如果使用 Exec 探针,确保所运行的命令可以正确判断应用程序的健康状态。
- 避免死锁: 如果探针不正确地配置,可能会导致容器被频繁重启,甚至可能陷入无限重启循环。因此,需要仔细测试和调整探针配置。
- 避免资源竞争: 控制好探针执行的频率和容器本身的资源使用,以避免探针本身成为导致容器不健康的原因。
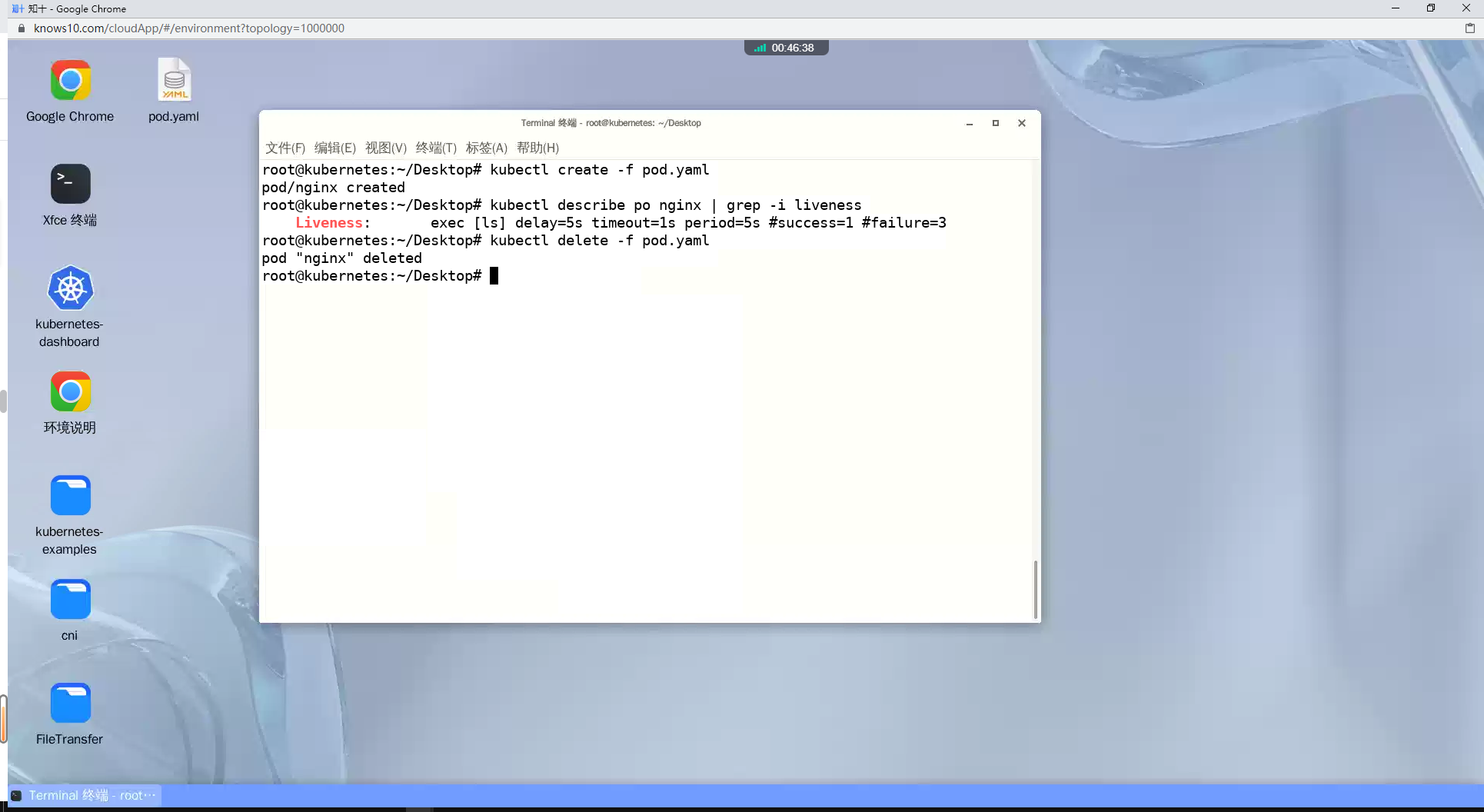
2、Modify the pod.yaml file so that liveness probe starts kicking in after 5 seconds whereas the interval between probes would be 5 seconds. Run it, check the probe, delete it.
译:修改 pod.yaml 文件,使存活探针在 5 秒后开始启动,而探针之间的间隔为 5 秒。运行它,检查探针,删除它。
#查看 Pod 资源的 spec.containers.livenessProbe 字段的说明。
kubectl explain pod.spec.containers.livenessProbe
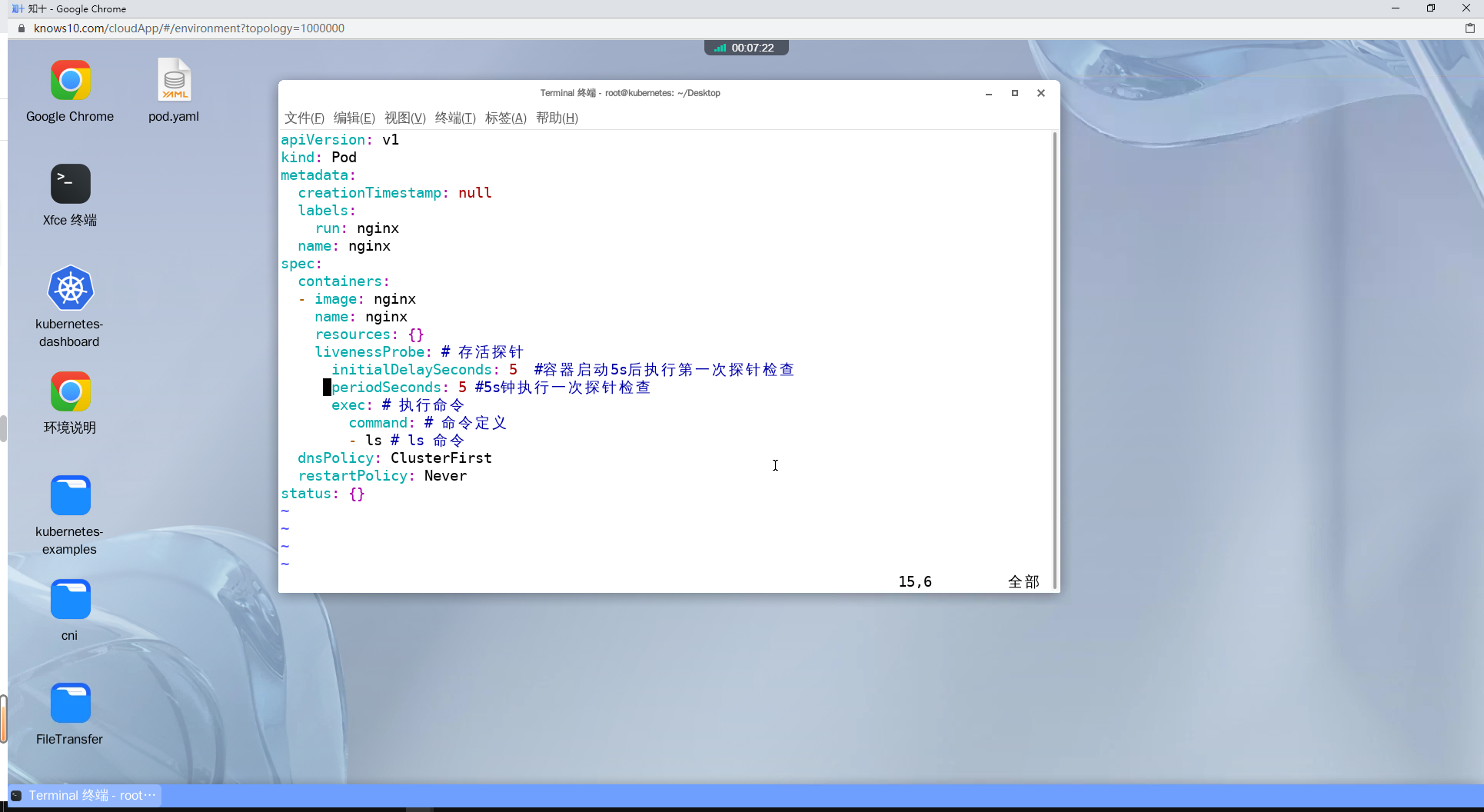
vi pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
livenessProbe:
initialDelaySeconds: 5 #容器启动5s后执行第一次探针检查
periodSeconds: 5 #5s钟执行一次探针检查
exec:
command:
- ls
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
---
kubectl create -f pod.yaml
kubectl describe po nginx | grep -i liveness
kubectl delete -f pod.yaml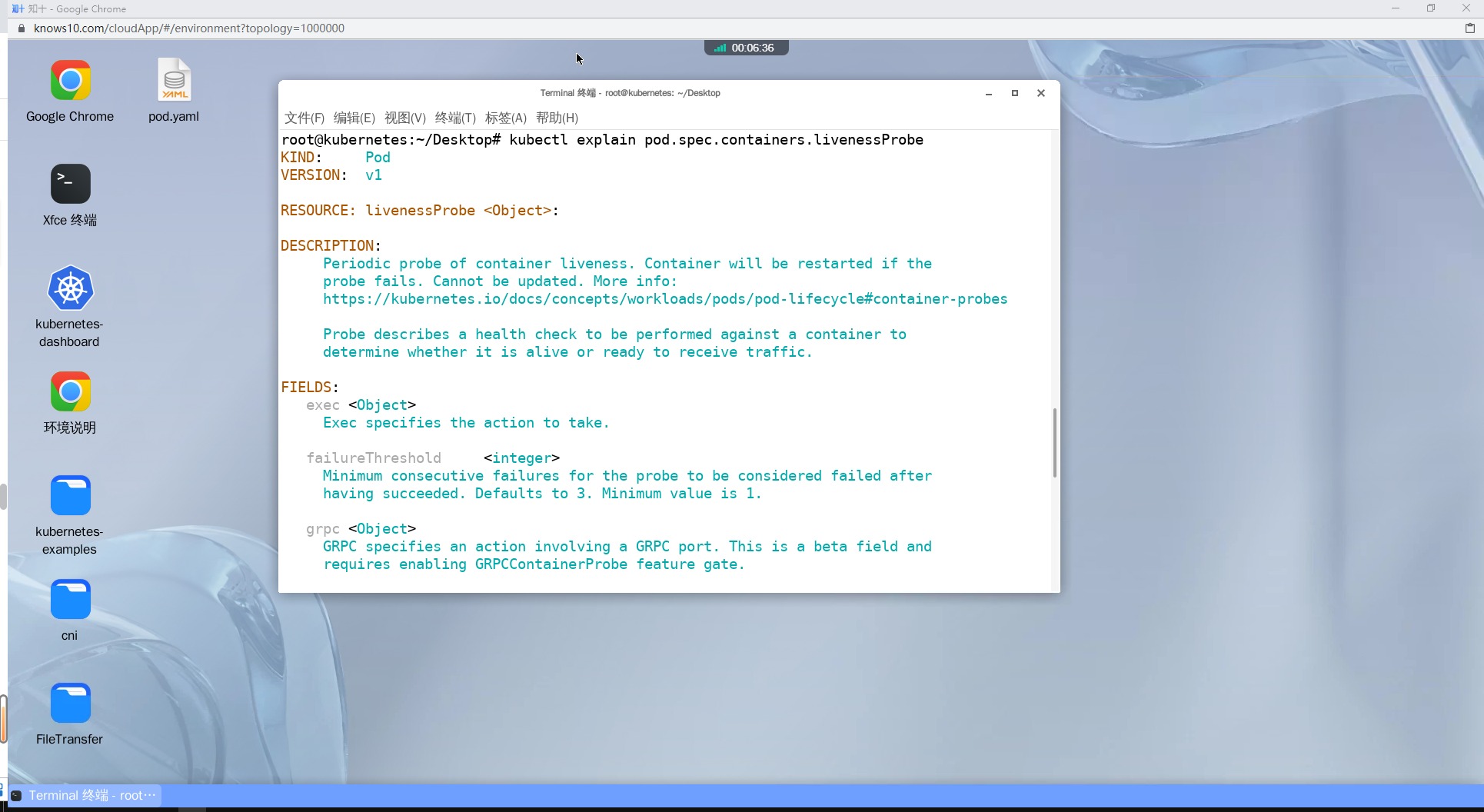
知识点:
- Pod 资源的 spec.containers.livenessProbe 主要字段的说明示例
KIND: Pod
VERSION: v1
RESOURCE: livenessProbe <Object>
DESCRIPTION:
Periodic probe of container liveness. Container will be restarted if the
probe fails. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle#container-probes
Probe describes a health check to be performed against a container to
determine whether it is alive or ready to receive traffic.
FIELDS:
exec <Object>
Exec specifies the action to take.
failureThreshold <integer>
Minimum consecutive failures for the probe to be considered failed after
having succeeded. Defaults to 3. Minimum value is 1.
grpc <Object>
GRPC specifies an action involving a GRPC port. This is a beta field and
requires enabling GRPCContainerProbe feature gate.
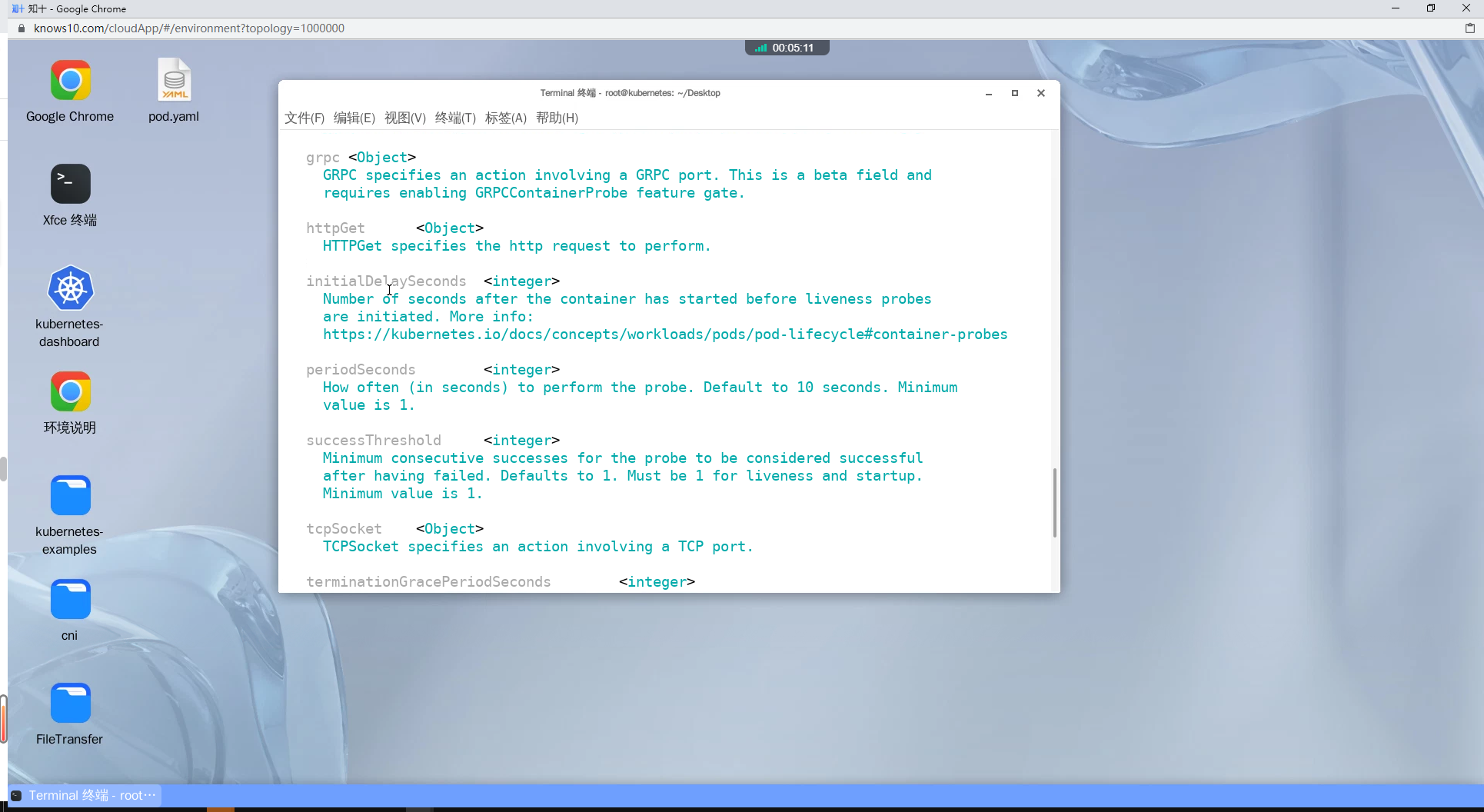
httpGet <Object>
HTTPGet specifies the http request to perform.
initialDelaySeconds <integer>
Number of seconds after the container has started before liveness probes
are initiated. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle#container-probes
periodSeconds <integer>
How often (in seconds) to perform the probe. Default to 10 seconds. Minimum
value is 1.
successThreshold <integer>
Minimum consecutive successes for the probe to be considered successful
after having failed. Defaults to 1. Must be 1 for liveness and startup.
Minimum value is 1.
tcpSocket <Object>
TCPSocket specifies an action involving a TCP port.
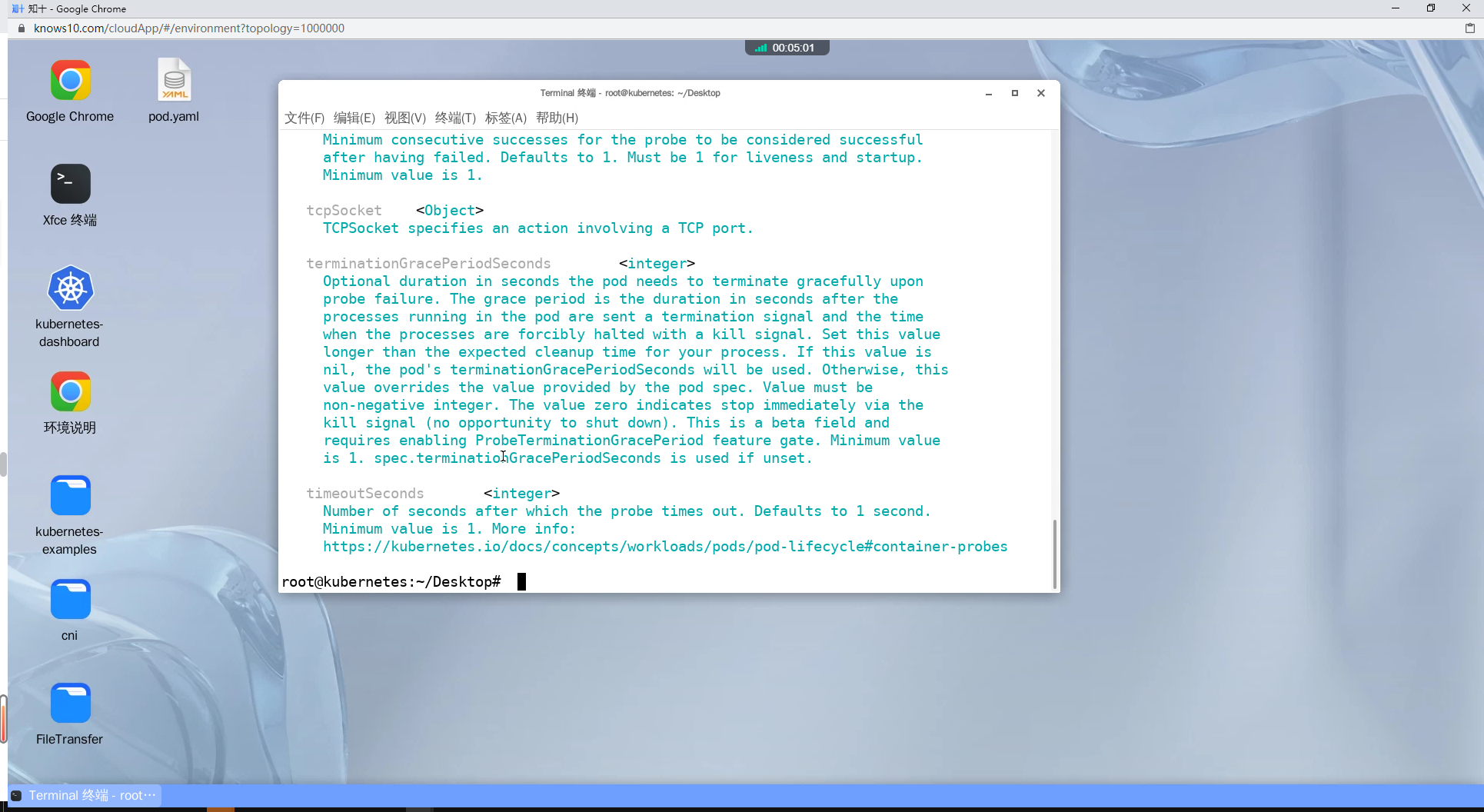
terminationGracePeriodSeconds <integer>
Optional duration in seconds the pod needs to terminate gracefully upon
probe failure. The grace period is the duration in seconds after the
processes running in the pod are sent a termination signal and the time
when the processes are forcibly halted with a kill signal. Set this value
longer than the expected cleanup time for your process. If this value is
nil, the pod's terminationGracePeriodSeconds will be used. Otherwise, this
value overrides the value provided by the pod spec. Value must be
non-negative integer. The value zero indicates stop immediately via the
kill signal (no opportunity to shut down). This is a beta field and
requires enabling ProbeTerminationGracePeriod feature gate. Minimum value
is 1. spec.terminationGracePeriodSeconds is used if unset.
timeoutSeconds <integer>
Number of seconds after which the probe times out. Defaults to 1 second.
Minimum value is 1. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle#container-probes exec: 使用ExecAction定义在容器内部执行的命令来进行存活检测。failureThreshold: 定义连续多少次失败的探针检查后,容器被认为是不健康的。httpGet: 使用HTTPGetAction定义发送 HTTP 请求来进行存活检测。initialDelaySeconds: 定义容器启动后多少秒开始执行第一次探针检查。periodSeconds: 定义多少秒执行一次探针检查。successThreshold: 定义连续多少次成功的探针检查后,容器被认为是健康的。tcpSocket: 使用TCPSocketAction定义与 TCP 端口的连接来进行存活检测。timeoutSeconds: 定义多少秒之后探针超时。
3、Create an nginx pod (that includes port 80) with an HTTP readinessProbe on path '/' on port 80. Again, run it, check the readinessProbe, delete it.
译:创建一个 nginx pod(包括端口 80),在端口 80 上的路径“/”上使用 HTTP 就绪探针 。再次运行它,检查就绪性探测,删除它
# kubectl run nginx: 这部分命令告诉 kubectl 创建一个名为 "nginx" 的资源。在这个上下文中,"nginx" 是资源的名称,可以将其替换为想要的任何其他名称(不能与现有的Pod名称重复)。
# --image=nginx: 这部分指定了要在 Pod 中使用的容器镜像。在这里,使用了名为 "nginx" 的官方镜像作为容器的基础镜像。
# --restart=Never: 这部分指定了 Pod 的重启策略。"Never" 表示如果 Pod 终止,就不要自动重启它。
# --dry-run=client: 这部分告诉 kubectl 在实际创建资源之前模拟操作。它会检查命令是否合法,但不会实际创建 Pod。
# -o yaml: 这部分指定了输出的格式。在这里,它指定将资源定义以 YAML 格式输出。
# --port=80: 这部分指定了容器要监听的端口。在这里,容器将监听端口 80。
# > pod.yaml: 这部分将命令的输出重定向到一个名为 "pod.yaml" 的文件中,以便将生成的 Pod 定义保存在这个文件中。
kubectl run nginx --image=nginx --dry-run=client -o yaml --restart=Never --port=80 > pod.yaml
vi pod.yaml
---
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
ports:
# 注意:就绪探针在容器的整个生命周期内运行。由于nginx暴露了80端口,因此 readiness 不需要 containerPort: 80 来工作。
- containerPort: 80
# 就绪探针配置
readinessProbe:
httpGet:
path: /
port: 80
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
---
# 创建 Pod
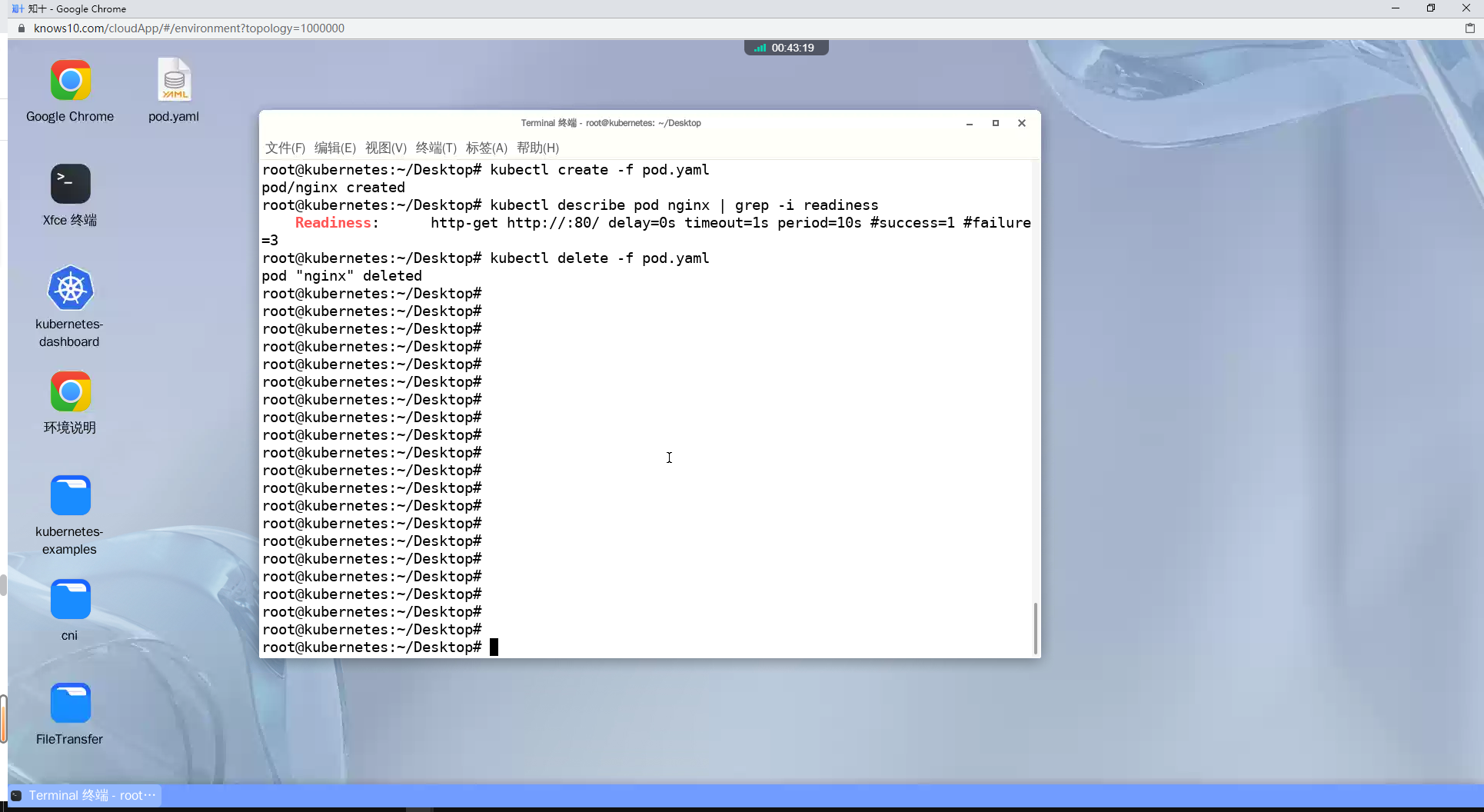
kubectl create -f pod.yaml
# 查看 Pod 的就绪探针
kubectl describe pod nginx | grep -i readiness
# 删除pod
kubectl delete -f pod.yaml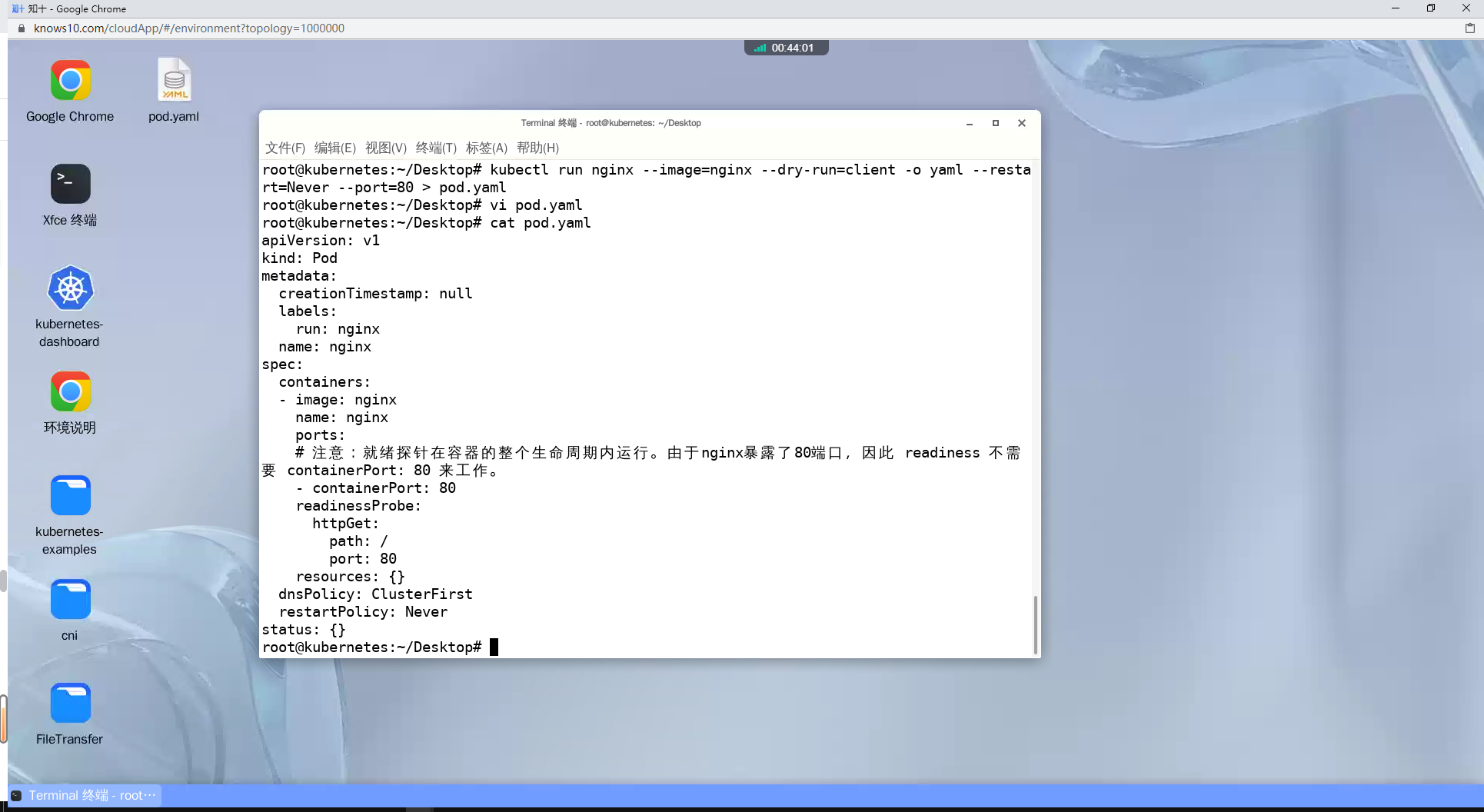
知识点:
- readinessProbe类型及判定探针不健康判定:
- **HTTP 探针:** 发送 HTTP 请求到容器内指定的端点,检查应用程序是否正常响应。如果返回的 HTTP 状态码表示成功,那么容器被认为是健康的。 - 不健康判定:
- **HTTP 请求失败:** 如果 HTTP 请求返回的状态码不在成功的范围内(通常是 2xx 系列),就会被认为是不健康的。例如,返回 4xx 或 5xx 的状态码会被解释为应用程序处于不正常状态。
- **连接超时:** 如果在预定的超时时间内无法建立 HTTP 连接,探针也会被认为是不健康的。这可能意味着应用程序无法正常响应请求或端口不可达。
- **DNS 解析问题:** 发送 HTTP 请求时出现 DNS 解析问题,探针会失败,因无法找到目标地址。
- **TCP 探针:** 尝试与容器内的指定端口建立 TCP 连接。如果连接成功,容器被认为是健康的。 - 不健康判定:
- **TCP 连接失败:** 如果在预定的超时时间内无法建立 TCP 连接,探针会被认为是不健康的。这可能是由于应用程序未监听指定的端口、端口不可达或防火墙规则等问题。
- **连接超时:** 如果在预定的超时时间内无法建立 TCP 连接,探针也会被认为是不健康的。这可能表明应用程序无法正常接受连接。
- **网络问题:** 如果在探针尝试建立连接时发生网络故障,如丢包或延迟过高,探针可能会失败。
- **Exec 探针:** 在容器内运行指定的命令,如果命令成功执行并返回零退出代码,容器被认为是健康的。 - 不健康判定:
- **命令执行失败:** 如果在容器内部执行的命令返回非零的退出代码,探针会被认为是不健康的。通常情况下,命令成功执行应该返回零的退出代码,非零的退出代码表示命令执行出现问题。
- **命令超时:** 如果执行的命令在预定的超时时间内没有完成,探针会被认为是不健康的。这可能意味着应用程序无法正常处理探针所需的命令。
- **命令不可用:** 如果定义的命令在容器内不可用(例如,命令不存在或路径错误),探针会失败。确保命令路径正确且可执行。
- readinessProbe可以设置以下属性来定义探针的行为: - **initialDelaySeconds**:容器启动后延迟多少秒开始执行第一次探针检查。
- **periodSeconds**:探针检查之间的时间间隔。
- **timeoutSeconds**:探针检查的超时时间。
- **successThreshold**:连续多少次成功的探针检查后,容器被认为是健康的。
- **failureThreshold**:连续多少次失败的探针检查后,容器被认为是不健康的。- readinessProbe配置示例
- HTTP 探针配置示例:
readinessProbe:
httpGet:
path: /healthz # 替换为应用程序提供的健康检查端点
port: 8080 # 替换为应用程序监听的端口
initialDelaySeconds: 15
periodSeconds: 10- TCP 探针配置示例:
readinessProbe:
tcpSocket:
port: 8080 # 替换为应用程序监听的端口
initialDelaySeconds: 15
periodSeconds: 10- Exec 探针配置示例:
readinessProbe:
exec:
command:
- sh
- -c
- cat /tmp/health.txt # 替换为应用程序检查健康状态的命令
initialDelaySeconds: 15
periodSeconds: 104、Please list all pods whose liveness probe are failed in the format of / per line.
译:请以每行的格式列出活动探测失败的所有Pod。
#使用如下pod.yaml生成存活探针探测失败的pod
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: nginx
name: nginx
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
livenessProbe:
initialDelaySeconds: 5 #容器启动5s后执行第一次探针检查
periodSeconds: 5 #5s钟执行一次探针检查
exec:
command:
- cat zhishi
dnsPolicy: ClusterFirst
restartPolicy: Never
status: {}
#按命名空间收集失败的Pod事件
# kubectl get events -o json: 这部分命令获取 Kubernetes 集群中的事件,并以 JSON 格式输出。
# jq -r '.items[] | select(.message | contains("failed liveness probe")).involvedObject | .namespace + "/" + .name': 这部分使用 jq 工具来解析 JSON 输出。
# .items[]: 遍历 JSON 中的每个事件。
# select(.message | contains("failed liveness probe")): 选择包含 "failed liveness probe" 的事件。
# .involvedObject: 获取与事件相关联的对象信息。
# .namespace + "/" + .name: 将事件的命名空间和名称组合起来,以输出 namespace/name 格式的字符串。
kubectl get events -o json | jq -r '.items[] | select(.message | type == "string" and contains("Liveness")).involvedObject | .namespace + "/" + .name'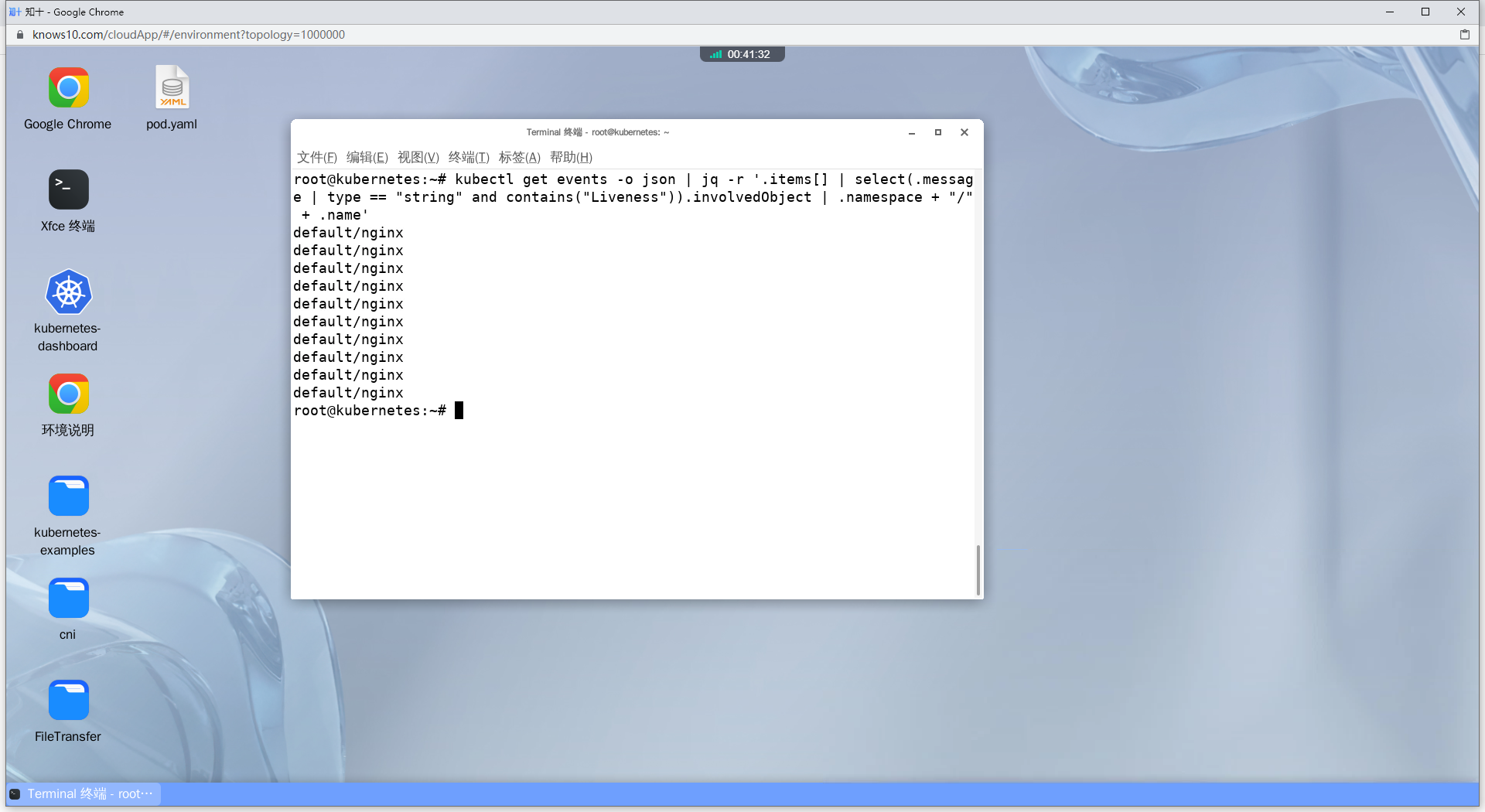
知识点:
- Kubernetes 事件: Kubernetes 事件是对集群中发生的事情的记录,如 Pod 创建、删除、调度、状态变化等。通过
kubectl get events命令可以获取这些事件的信息。- 事件的定义: Kubernetes 事件是对集群中发生的事情的记录,如 Pod 创建、删除、状态变化、健康检查失败等。事件提供了关于集群中活动的重要信息。
- 事件级别: 事件有不同的级别,包括 Normal 和 Warning。Normal 事件表示正常操作或状态,而 Warning 事件表示异常情况或问题。
- 事件源和涉及对象: 事件会指明事件发生的对象(如 Pod、Node 等),以及导致事件的对象(如 Controller、用户等)。
- 事件类型: 事件可以包含不同类型的信息,如创建、修改、删除等。这些类型帮助你理解事件的具体情况。
- 事件消息和时间戳: 事件会包含具体的消息,解释事件的原因和影响。还有一个时间戳,记录事件发生的时间。
- JSON 输出和 jq:
kubectl的输出可以通过-o json参数以 JSON 格式进行输出。jq是一个命令行 JSON 处理工具,它能够以结构化方式解析和查询 JSON 数据。- JSON 查询语法:
jq支持类似于 SQL 的查询语法,用于从 JSON 数据中选择、过滤和操作特定字段和值。 - 基本选择器: 使用点
.表示当前节点,[]表示索引或键值,以选择 JSON 数据的特定部分。
- JSON 查询语法:
# 选择 JSON 对象中的 "name" 属性的值
echo '{"name": "John", "age": 30}' | jq '.name'
# 选择 JSON 数组的第一个元素
echo '[1, 2, 3]' | jq '.[0]'- **条件筛选:** 使用 `select()` 函数和条件表达式,筛选出满足条件的数据项。# 选择数组中大于 2 的元素
echo '[1, 2, 3, 4]' | jq 'map(select(. > 2))'- **对象属性访问:** 使用 `.key` 来访问 JSON 对象中的属性,例如 `.name` 访问对象的 "name" 属性。# 获取 JSON 对象中的 "age" 属性的值
echo '{"name": "Alice", "age": 25}' | jq '.age'- **数组索引:** 使用 `[index]` 访问数组中的特定索引处的值。# 获取数组中索引为 1 的元素
echo '[10, 20, 30]' | jq '.[1]'- **数组迭代:** 使用 `map()` 函数迭代数组,可以对每个数组元素应用相同的操作。# 将数组中的每个元素乘以 2
echo '[1, 2, 3, 4]' | jq 'map(. * 2)'- **数据转换:** `jq` 支持对 JSON 数据进行转换、格式化和重构,例如将 JSON 转换成其他格式。# 将 JSON 格式化为漂亮的格式
echo '{"name": "Bob", "age": 40}' | jq '.'日志
1、Create a busybox pod that runs i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done. Check its logs
译:创建一个busybox的pod,运行命令 i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done.检查它的日志
# kubectl run busybox: 这部分命令告诉 kubectl 创建一个名为 "busybox" 的资源。在这个上下文中,"busybox" 是资源的名称,你可以将其替换为你想要的任何其他名称。
# --image=busybox: 这部分指定了要在 Pod 中使用的容器镜像。在这里,使用了名为 "busybox" 的容器镜像。
# --restart=Never: 这部分指定了 Pod 的重启策略。"Never" 表示如果 Pod 终止,就不要自动重启它。
# -- /bin/sh -c 'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done': 这部分是容器的启动命令。在这里,它是一个无限循环的 Shell 命令,用于输出计数和当前的时间。该命令会在容器内执行。
kubectl run busybox --image=busybox --restart=Never -- /bin/sh -c 'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done'
#查看日志
kubectl logs busybox -f 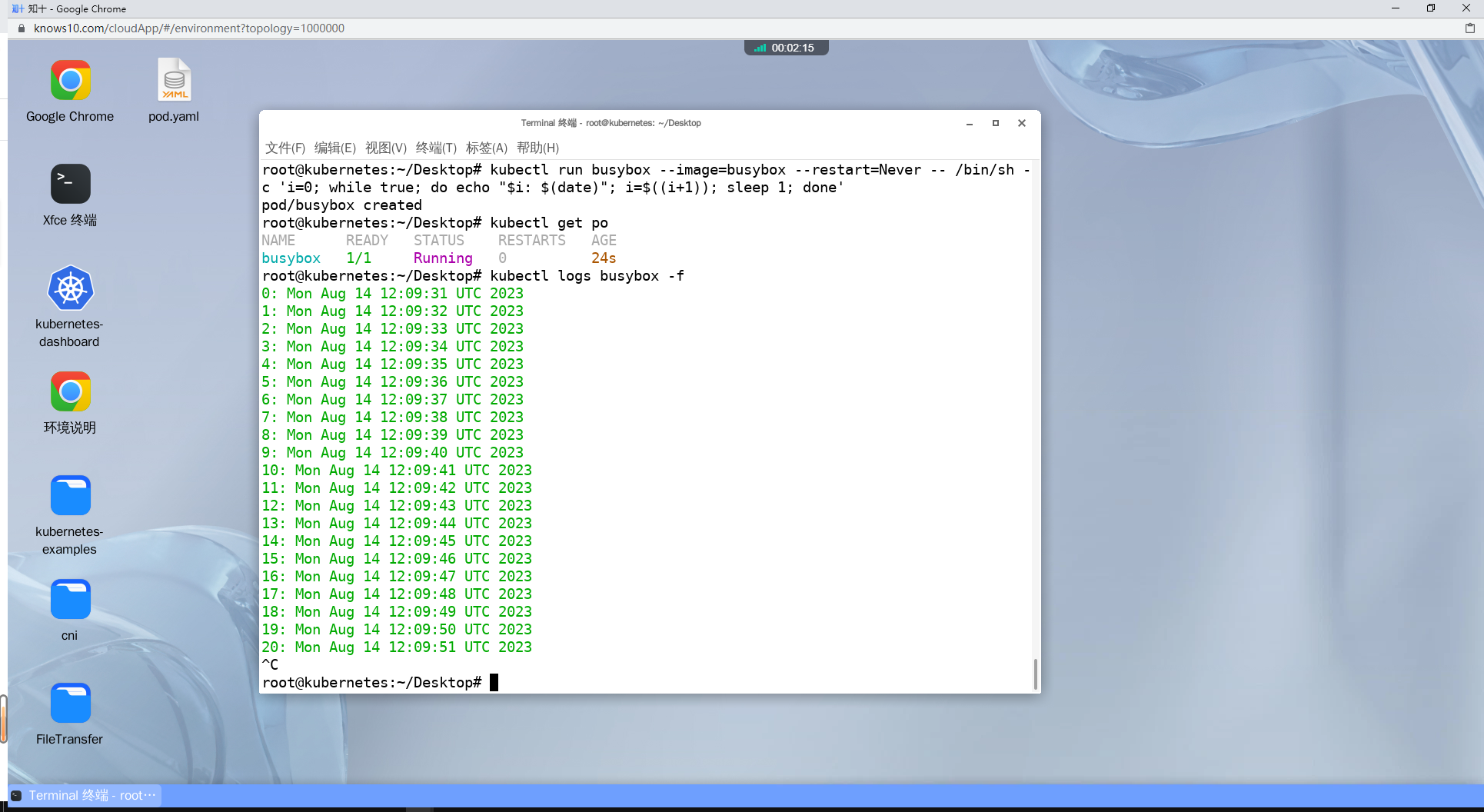
知识点:
- logs用于查看日志
-f: 跟踪日志输出,以实时模式显示并持续刷新日志内容。--all-containers:在多容器的 Pod 中,显示所有容器的日志而不仅仅是第一个容器。--previous:显示之前终止容器的日志,适用于已经终止的容器。--since:指定要显示日志的时间范围,例如--since=1h表示显示最近一小时内的日志。--since-time:指定要显示日志的时间戳,格式为 RFC3339,例如--since-time="2023-07-19T12:00:00Z"。--timestamps或-t:显示日志的时间戳。--tail:从日志的末尾显示指定行数的日志,默认为最近的10行。--limit-bytes:限制日志的大小(字节)。--container或-c:指定要查看日志的容器名称,在多容器的 Pod 中非常有用。--namespace或-n:指定要查看日志的命名空间,如果不指定,默认为 "default" 命名空间。--pod-running-timeout:等待 Pod 运行的最大时间,以秒为单位,默认值为 20 秒。
常用参数为-f和--all-containers,在使用 -f 参数时,可能会不断地输出新的日志内容,因此在某些情况下,您可能需要小心使用,以避免日志输出过多导致终端不可控。如果不带任何参数,默认输出pod中第一个容器截止到执行命令的时间点的日志。
调试
1、Create a busybox pod that runs 'ls /notexist'. Determine if there's an error (of course there is), see it. In the end, delete the pod
译:创建一个运行'ls /notexist'命令的busybox pod。确定是否有错误(当然有),查看它。最后,删除Pod
# kubectl run busybox: 这部分命令告诉 kubectl 创建一个名为 "busybox" 的资源。在这个上下文中,"busybox" 是资源的名称,可以将其替换其他不同的名称。
# --restart=Never: 这部分指定了 Pod 的重启策略。"Never" 表示如果 Pod 终止,就不要自动重启它。
# --image=busybox: 这部分指定了要在 Pod 中使用的容器镜像。在这里,使用了名为 "busybox" 的容器镜像。
# -- /bin/sh -c 'ls /notexist': 这部分是容器的启动命令。在这里,它是一个 Shell 命令,尝试列出 /notexist 目录。由于该目录不存在,命令会失败并输出错误信息。
kubectl run busybox --restart=Never --image=busybox -- /bin/sh -c 'ls /notexist'
# 查看日志
kubectl logs busybox
#查看pod的信息
kubectl describe po busybox
#删除pod
kubectl delete po busybox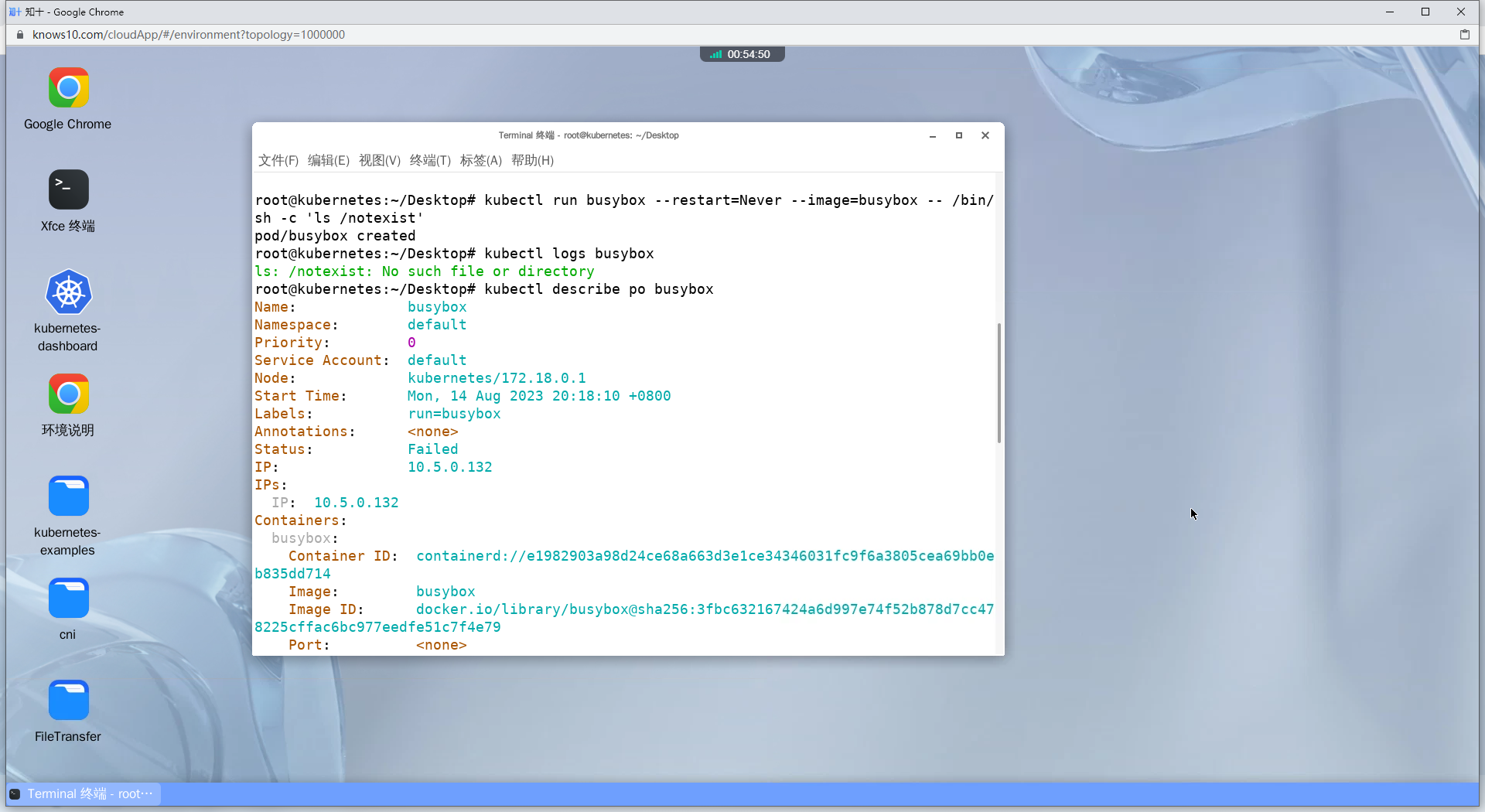
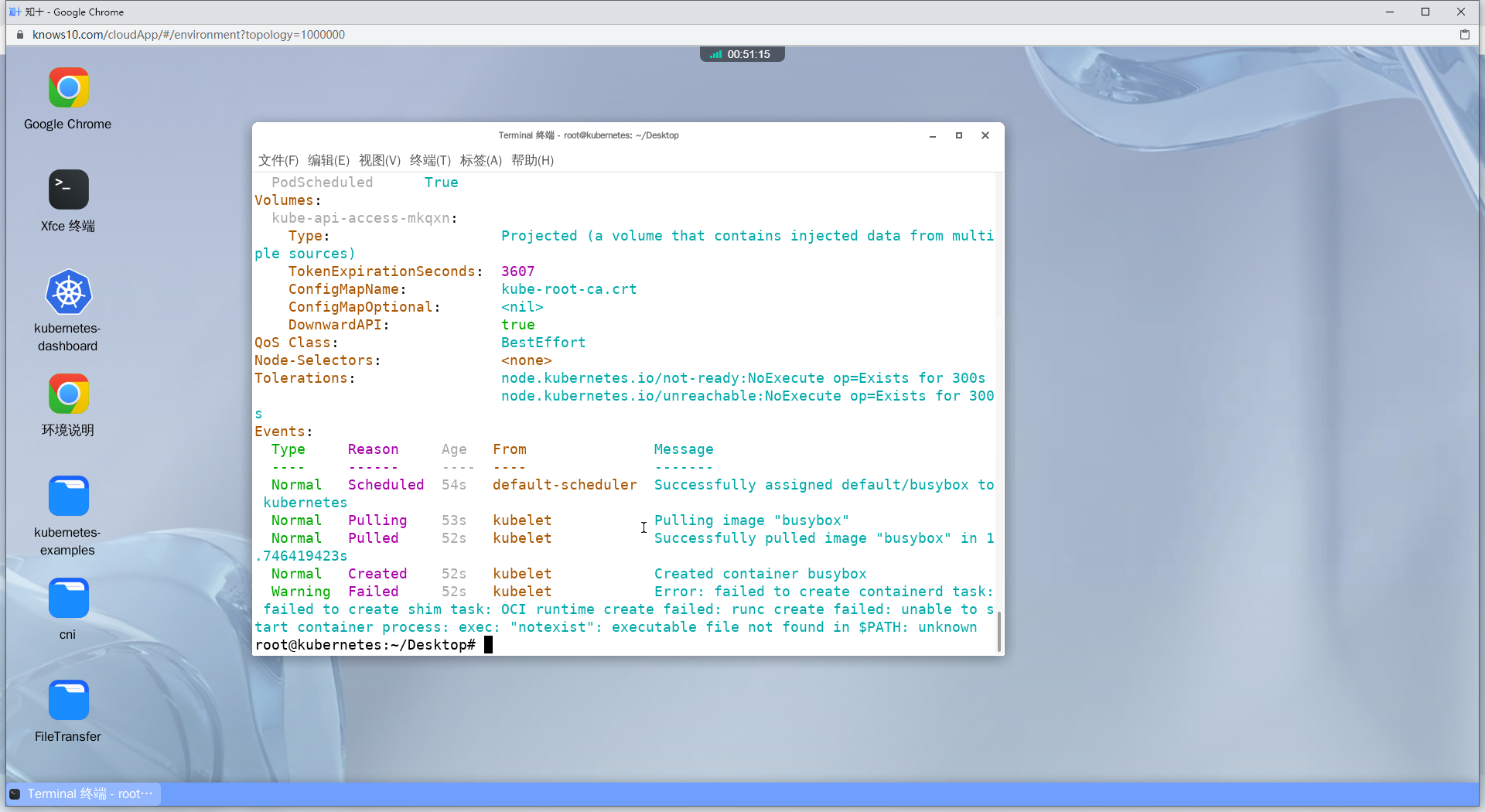
2、Create a busybox pod that runs 'notexist'. Determine if there's an error (of course there is), see it. In the end, delete the pod forcefully with a 0 grace period
译:创建一个运行'notexist'命令的busybox pod。确定是否有错误(当然有),查看它。最后,强制删除Pod,宽限期为0
#创建Pod
kubectl run busybox --restart=Never --image=busybox -- notexist
# 查看日志
kubectl logs busybox
# 查看Pod信息
kubectl describe po busybox
# 获取错误事件
kubectl get events | grep -i error
#删除Pod
# kubectl delete po busybox: 这部分命令告诉 kubectl 删除一个名为 "busybox" 的 Pod。在这个上下文中,"busybox" 是要删除的 Pod 的名称。
# --force: 这部分使用 --force 标志来指示 kubectl 强制执行删除操作,即使存在一些删除条件或终止信号。
# --grace-period=0: 这部分使用 --grace-period 参数来指定删除的优雅期限。通过将值设置为 0,可以使删除操作立即生效,而不等待任何优雅终止。
kubectl delete po busybox --force --grace-period=0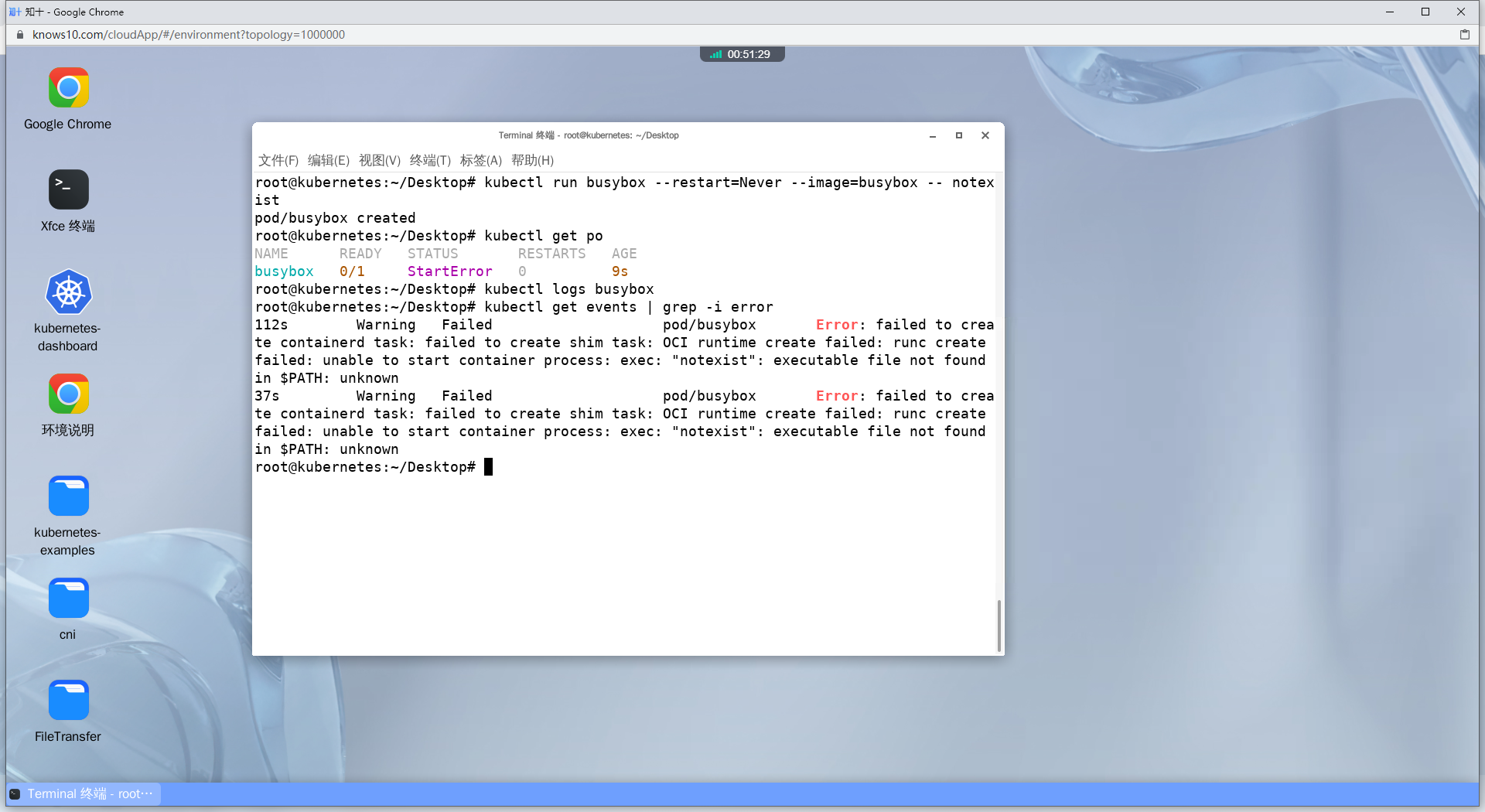
知识点:
delete命令用于删除不同类型的资源。- --all: 删除命令使用
--all标志时,将删除命名空间中的所有资源。例如,kubectl delete all --all -n namespace-name将删除指定命名空间内的所有资源。 - --filename (-f): 使用
-f或--filename标志可以指定一个或多个 YAML 或 JSON 文件,其中包含要删除的资源的定义。例如,kubectl delete -f resource.yaml将删除resource.yaml文件中定义的资源。 - --selector (-l): 使用
-l或--selector标志可以指定一个标签选择器,用于选择要删除的资源。例如,kubectl delete pods -l app=myapp将删除所有标签包含app=myapp的 Pod。 - --grace-period: 使用
--grace-period参数可以设置删除的优雅期限,即容器的优雅终止时间。默认为 30 秒。例如,kubectl delete pod pod-name --grace-period=10将设置 10 秒的优雅期限。 - --force: 使用
--force标志可以强制执行删除操作,即使存在条件或终止信号。例如,kubectl delete pod pod-name --force将强制删除指定的 Pod。 - --grace-period 参数:
--grace-period参数用于设置删除的优雅期限,即容器的优雅终止时间。将其值设置为 0 会导致删除操作立即生效,而不等待任何优雅终止。 - --wait: 使用
--wait标志可以使命令等待资源完全删除后才返回。默认情况下,命令将立即返回。 - --ignore-not-found: 使用
--ignore-not-found标志可以忽略删除不存在的资源时的错误,而不会显示错误消息。 - --timeout: 使用
--timeout参数可以设置等待资源删除完成的超时时间。默认为 0,表示不设置超时。 - --cascade: 使用
--cascade标志可以指定在删除资源时是否级联删除关联资源。例如,kubectl delete deployment deployment-name --cascade=false将删除部署资源但不删除关联的 ReplicaSet。
- --all: 删除命令使用
3、Get CPU/memory utilization for nodes (metrics-server must be running)
译:获取节点的CPU/内存利用率(metrics-server必须正在运行)
kubectl top nodes系列文章
CKAD考试实操指南(一)--- 登顶CKAD:征服考试的完美蓝图
CKAD考试实操指南(二)--- 深入核心:探秘Kubernetes核心实操秘技
CKAD考试实操指南(三)--- 舞动容器:多容器Pod实践指南
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号