使用Maxwell+Python+ClickHouse实现数据展示
原创
使用Maxwell+Python+ClickHouse实现数据展示
原创
保持热爱奔赴山海
发布于 2023-10-11 13:34:01
发布于 2023-10-11 13:34:01
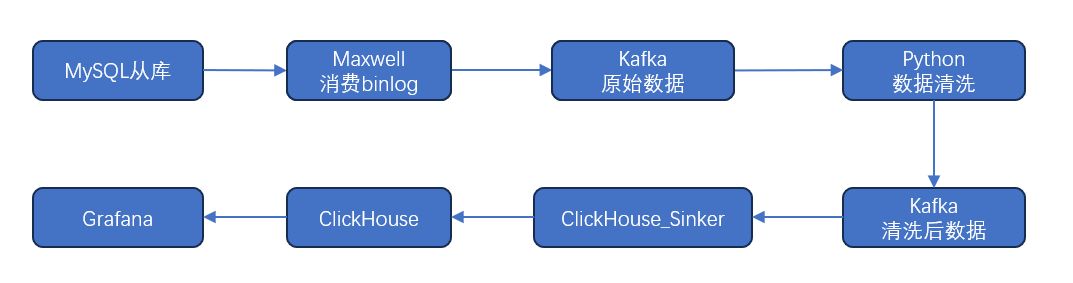
组件:
maxwell
kafka
python_program
clickhouse_sinker 负责消费kafka里清洗后的数据
clickhouse_server 数据持久化
supervisor 守护进程,负责maxwell python_program clickhouse_sinker 的保活
流程:
看板,类似这种:
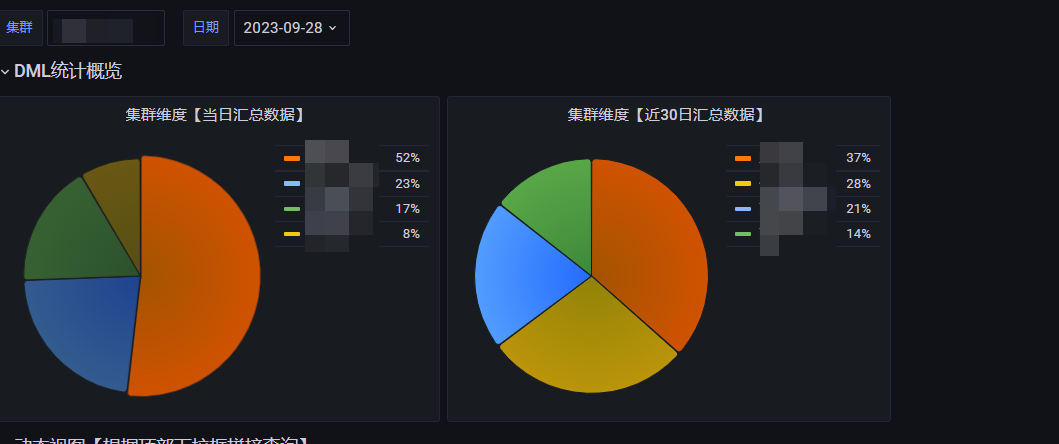
饼图
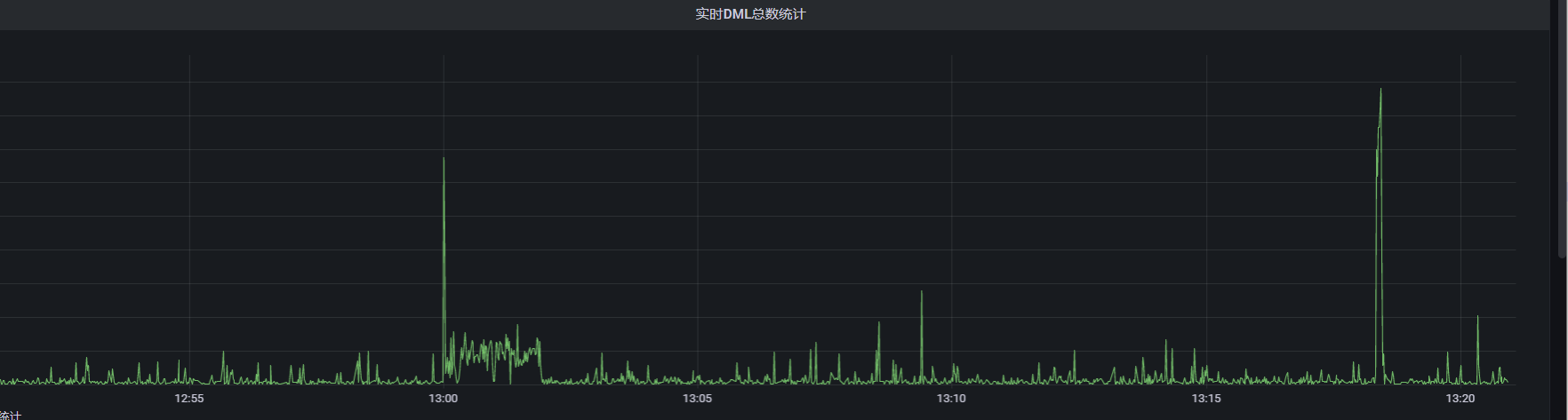
趋势图
相关代码样例:
1、maxwell配置 config.properties
# 日志级别
log_level=info
client_id=12345
replica_server_id=12345
# Maxwell 元数据数据库信息
host=192.168.100.1
port=3306
user=root
password=123456
#producer kafka的配置信息
producer=kafka
kafka.bootstrap.servers=localhost:9092
kafka_topic=binlog_service_A
kafka_partition_hash=murmur3
producer_partition_by=primary_key
#被同步的数据库的信息
replication_host=192.168.100.11
replication_user=dts
replication_password=dts
replication_port=3306
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai
# 配置过滤器,可以配置只同步指定的数据库,指定的表的数据变动。
#filter=exclude: *.*2、python数据清洗程序(配置文件+主程序)
cat configs.py
# -*- coding: utf-8 -*-
# MySQL Settings
MYSQL_SETTINGS = {
"host": "192.168.100.11",
"port": 3306,
"user": "dts",
"passwd": "dts"
}
#
MySQL_CLUSTER_NAME = "服务-A-RDS"
# Kafka Settings
bootstrap_servers = '127.0.0.1:9092'
original_topic = "binlog_service_A"
washed_topic = "binlog_washed"cat main.py
# -*- coding: utf-8 -*-
import json
from kafka import KafkaConsumer, KafkaProducer
import configs
consumer_config = {
'bootstrap_servers': configs.bootstrap_servers,
'group_id': 'my_consumer_group',
'auto_offset_reset': 'latest', # 可选 earliest latest 默认启动后从最新的位置开始消费
'enable_auto_commit': True
}
producer_config = {
'bootstrap_servers': configs.bootstrap_servers
}
# 创建Kafka消费者和生产者
consumer = KafkaConsumer(configs.original_topic, **consumer_config)
producer = KafkaProducer(**producer_config)
# 循环消费消息并处理
for message in consumer:
data = message.value.decode('utf-8')
# print(data)
database = json.loads(data).get('database')
table = json.loads(data).get('table')
type = json.loads(data).get('type')
ts = json.loads(data).get('ts')
xid = json.loads(data).get('xid')
xoffset = json.loads(data).get('xoffset')
result = {}
result['database'] = database
result['table'] = table
result['type'] = type
result['ts'] = ts
result['xid'] = xid
result['xoffset'] = xoffset
result['cluster'] = configs.MySQL_CLUSTER_NAME
res = json.dumps(result, ensure_ascii=False)
new_data = res
print(new_data)
# 发送处理后的消息
producer.send(configs.washed_topic, value=new_data.encode('utf-8'))
# 关闭Kafka消费者和生产者连接
consumer.close()
producer.close()这里的代码是简单版本的。如果数据量大可以使用多线程+kafka多partition的方式提升消费速度。
3、clickhouse_sinker 消费脚本的配置如下:
{
clickhouse: {
hosts: [
[
127.0.0.1
]
]
port: 9000
db: default
username: ""
password: ""
retryTimes: 0
}
kafka: {
brokers: 127.0.0.1:9092
}
task: {
name: binlog_washed
topic: binlog_washed
consumerGroup: clickhouse_sinker
earliest: false
parser: json
autoSchema: true
tableName: binlog_washed
excludeColumns: []
bufferSize: 100000
"dynamicSchema": {
"enable": true,
"maxDims": 1024,
"whiteList": "^[0-9A-Za-z_]+$",
"blackList": "@"
},
}
logLevel: info
}
4、ck_job.py 统计脚本
# -*- encoding: utf-8 -*-
# 相关的定时任务,都放到这里
from datetime import date, timedelta
from clickhouse_driver import Client
from apscheduler.schedulers.background import BlockingScheduler
from apscheduler.triggers.cron import CronTrigger
from apscheduler.executors.pool import ThreadPoolExecutor
def ck_job():
client = Client('localhost')
calc_date = (date.today() - timedelta(days=1)).strftime('%Y-%m-%d')
purge_date = (date.today() - timedelta(days=30)).strftime('%Y-%m-%d')
# 1 根据day统计
insert_sql = """INSERT INTO binlog_washed_by_day SELECT toDate(ts) AS day,type,count(*) AS count,cluster FROM binlog_washed where toDate(ts) = """ + "'" + calc_date + "'" + """
GROUP BY day,type,cluster ORDER BY day ASC,type ASC;"""
res = client.execute(insert_sql)
print(res)
# 2 根据table day统计
insert_sql = """INSERT INTO binlog_washed_by_table SELECT toDate(ts) AS day, database, table, type, count(*) AS count, cluster FROM binlog_washed where toDate(ts) = """ + "'" + calc_date + "'" + """GROUP BY day, database,table,type,cluster ORDER BY day ASC, type ASC"""
res = client.execute(insert_sql)
print(res)
# 3 删早期分区
alter_sql = """ALTER TABLE binlog_washed DROP PARTITION """ + "'" + purge_date + "'"
res = client.execute(alter_sql)
print(res)
client.disconnect()
if __name__ == "__main__":
executors = {"default": ThreadPoolExecutor(1)}
scheduler = BlockingScheduler(executors=executors)
# 每天的03:50:01执行作业
intervalTrigger=CronTrigger(hour=3, minute=50, second=1)
scheduler.add_job(ck_job, intervalTrigger, id="ck_job_id")
scheduler.start()
5、clickhouse建表
-- 明细表
CREATE TABLE default.binlog_washed
(
`ts` DateTime,
`database` String,
`table` String,
`type` String,
`xid` UInt8,
`xoffset` UInt8,
`cluster` String
)
ENGINE = MergeTree
PARTITION BY toDate(ts)
ORDER BY (ts, database, table)
TTL ts + toIntervalMonth(30)
SETTINGS index_granularity = 8192;
-- 统计表
CREATE TABLE default.binlog_washed_by_day
(
`day` Date,
`type` String,
`count` UInt64,
`cluster` String
)
ENGINE = MergeTree
PARTITION BY day
ORDER BY (day, type, cluster)
TTL day + toIntervalMonth(30)
SETTINGS index_granularity = 8192;
CREATE TABLE default.binlog_washed_by_table
(
`day` Date,
`database` String,
`table` String,
`type` String,
`count` UInt64,
`cluster` String
)
ENGINE = MergeTree
PARTITION BY day
ORDER BY (day, database, table, type, cluster)
TTL day + toIntervalMonth(30)
SETTINGS index_granularity = 8192;上述脚本,都通过supervisor去管理,启动后效果类似如下:
# supervisorctl status
ck_jobs RUNNING pid 31499, uptime 19 days, 18:13:12 -- 共用
ck_sinker RUNNING pid 2813, uptime 15 days, 23:03:46 -- 共用
cluster1_maxwell RUNNING pid 8024, uptime 19 days, 2:52:00 -- 每套集群都要启动
cluster1_wash_binlog RUNNING pid 5252, uptime 19 days, 2:54:24 -- 每套集群都要启动
cluster2_maxwell RUNNING pid 31896, uptime 19 days, 2:55:21
cluster2_wash_binlog RUNNING pid 4495, uptime 19 days, 2:56:43原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号