如何使用Redis数据类型进行亿级别统计数据
原创

前言
在开发中我们Redis数据类型用到最多的是Set命令,但是不仅于此,还有很多数据类型,这些可用户我们很多统计需求的场景,看看这些场景你遇到过,或者再次遇到的时候会做如何进行方案选择,一起看看!
📚 全文字数 : 8k+
⏳ 阅读时长 : 12min
📢 关键词 : Redis统计模式、list、bitmap、hyperLogLog
Redis常见统计模式
Redis集合类型(List、Set、Hash、Sorted Set)常见的四种统计模式,包括聚合统计、排序统计、二值状态统计和基数统计。

聚合统计
聚合统计就是指统计多个集合元素的聚合结果,比如下面集合统计方式:
1:统计多个集合的共有元素(交集统计) 2:把两个集合相比,统计其中一个集合独有的元素(差集统计) 3:统计多个集合的所有元素(并集统计)
聚合统计方式下Set类型支持集合内的增删改查操作,并且支持多个集合间的交集、并集、差集操作
Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
这个时候我们可以有两种方式来【避免阻塞主库实例】:
- 从主从集群中选择一个从库,让它专门负责聚合计算
- 把数据读取到客户端,在客户端来完成聚合统计
排序统计
List 和 Sorted Set 类型属于有序集合,两种类型的区别如下:
1:List 是按照元素进入 List 的顺序进行排序的 2:Sorted Set 可以根据元素的权重来排序,自己来决定每个元素的权重值 List顺序排序会带来什么问题呢?
List 是通过元素在 List 中的位置来排序的,当有一个新元素插入时,先插入的元素在 List 中的位置都后移了一位,也就是说先插入的元素在第 1 位的元素现在排在了第 2 位。所以,对比新元素插入前后,List 相同位置上的元素就会发生变化,用 LRANGE 读取时,就会读到旧元素。
而 Sorted Set 就不存在这个问题,因为它是根据元素的实际权重来排序和获取数据
二值统计
二值状态就是指集合元素的取值就只有 0 和 1 两种,简单理解为成立或者不成立,比如我们每天上班打开,要么打卡了,要么没打卡,这也是很典型的二值状态。
这种统计场景我们会选择Bitmap,用户一天的打卡状态用1 个 bit 位就能表示 0或1,一年下来也只是365个bit位,特别是在记录海量数据时Bitmap 能够有效地节省内存空间。
基数统计
基数统计就是指统计一个集合中不重复的元素个数,比如统计UV。
Redis 的集合类型中,Set 类型默认支持去重,你也可以用Hash类型,当数据很多时,Set类型和Hash 类型也会消耗很大的内存空间
HyperLogLog 是一种不精确的去重基数方案!
用 Redis 提供的 HyperLogLog,HyperLogLog 是一种用于统计基数的数据集合类型,它的最大优势就在于,当集合元素数量非常多时,它计算基数所需的空间总是固定的,而且还很小。
每个 HyperLogLog 只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。
HyperLogLog是有误差的,因为它的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是 0.81%。这也就意味着,你使用 HyperLogLog 统计的 UV 是 100 万,但实际的 UV 可能是 101 万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用 Set 或 Hash 类型
小小总结一下在使用Redis进行统计的时候常用Set、Sorted Set、Hash、List、Bitmap、HyperLogLog 这些类型,这些类型能够支持的统计模式和情况如下:
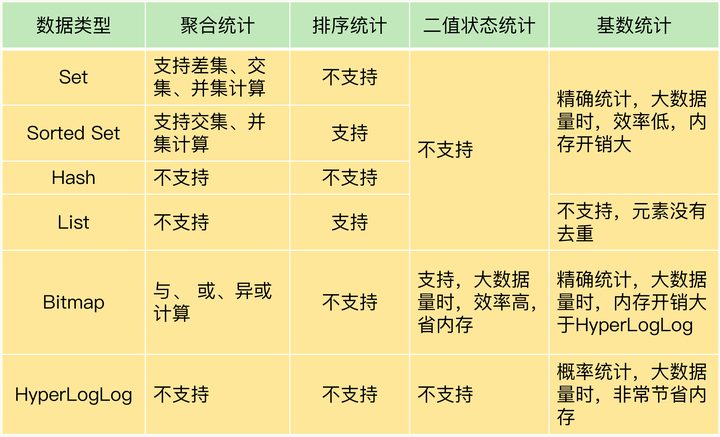
聚合统计
Redis的Set类型支持聚合操作类型的统计

Set 类型的底层数据结构是由 整数集合(intset)和哈希表(hashtable)实现的,当set保存的数据都为整数且元素个数不超过512个时,使用整数集合(intset),否则使用哈希表(hashtable)
Set命令的常用操作如下:

场景再现
作为开发人员,我们往往关注了很多技术公众号,而计算共同关注的好友就可以使用Set类型来进行交集运算得到结果。
我们把公众号ID作为key,关注公众号的用户userid作为value的值
比如: 小许code的公众号ID 为 gz:65,关注小许code的用户userid有 1、3、5、7、9 大佬刘的公众号ID 为 gz:67,关注大佬刘的用户userid有 3、7、9、10、11
交集
我们来模拟一下并集统计案例,看看如何操作,先把set集合的key和value值进行添加
127.0.0.1:6379> SADD gz:65 1 3 5 7 9
127.0.0.1:6379> SADD gz:67 3 7 9 10 11SINTER命令统计两个公众号的共同好友只需要两个 Set 集合的交集,如下命令:
127.0.0.1:6379> SINTER gz:65 gz:67
输出结果:
1) "3"
2) "7"
3) "9"不过也可以SINTERSTORE,它将结果保存到目标集合,并返回结果结果集的成员个数,而不是跟SINTER一样简单地返回结果集,可以看到关注了两个公众号的共同的好友有3个。
127.0.0.1:6379> SINTERSTORE gz:65:67 gz:65 gz:67
输出结果
(integer) 3差集
差集是一种集合运算,记A,B是两个集合,则所有属于A且不属于B的元素构成的集合
比如关注了 "大佬刘"公众号的朋友,有多少没有关注"小许code"呢,如果也都关注了小许code,要是能成功吸粉就好了,哈哈
执行如下指令就可以将结果结算出来
127.0.0.1:6379> SDIFF gz:67 gz:65
输出结果:
1) "10"
2) "11"不过SDIFFSTORE可以将结果集输出到另一个集合中,并返回有多少关注了大佬刘的人没关注小许code,这就是差集计算了。
127.0.0.1:6379> SDIFFSTORE diff:67:65 gz:67 gz:65
输出结果:
(integer) 2并集
两个集合所有元素构成的集合,叫做A和B的并集
比如关注了"大佬刘"和"小许code"公众号的粉丝一共有多少人,这就是计算两者的并集
我们使用SUNION命令来统计,具体如下
127.0.0.1:6379> SUNION gz:65 gz:67
1) "1"
2) "3"
3) "5"
4) "7"
5) "9"
6) "10"
7) "11"不过SUNIONSTORE可以将结果集输出到另一个集合中
127.0.0.1:6379> SUNIONSTORE union:65:67 gz:65 gz:67
(integer) 7好吧,其实两个公众号,去掉公共关注者的情况,实际只有7个自然人关注了这两个公众号,太难了,我要涨粉!
排序统计
堆排序的业务场景可就多了,比如你公众号发表文章的点赞、收藏、浏览、热榜列表等等。
在Redis中具排序功能的是Sorted Set和List
- List:按照元素插入 List 的顺序排序,使用场景通常可以作为 消息队列、最新列表;
- Sorted Set:根据元素的 score 权重排序,可以自己决定每个元素的权重值,使用场景(排行榜,按收藏、点赞数排序)
list排序方案

比如:小许发布的一片文章引起了小轰动,不少朋友进行了评论,那么可以 List插入顺序排序来实现评论列表,最新评论在前头
我们模拟一些数据,假设key是文章前缀+ID,并且已经评论了6条,后续增加一条新评论id就插入到List头部
127.0.0.1:6379> LPUSH article:100 1 2 3 4 5 6
(integer) 6比如评论分页每页显示5条, 我们可以LRANGE key star stop 获取列表指定区间内的元素
127.0.0.1:6379> LRANGE article:100 0 4
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"好了这里已经获取到了5条最新的评论了,这种方式实现了类似分页的功能,但是这种是存在问题的,可能导致列表元素重复或漏掉
List的问题元素重复是如何发生的?
同样使用上面的 article:100这个key进行案例说明,在我们获取第二页的数据时,正常来说是返回一条记录,也就是id为1的评论。
但是,在暂时第二页前,新产生了两条id为7、8的评论插入到了List头部,进行第二页查询就出现了下面问题了
127.0.0.1:6379> LRANGE article:100 5 9
1) "3"
2) "2"
3) "1"怎么又出现了id为3和2的评论啊,不对啊,没错这种情况下就是会出现这种情况,我们捋一捋过程
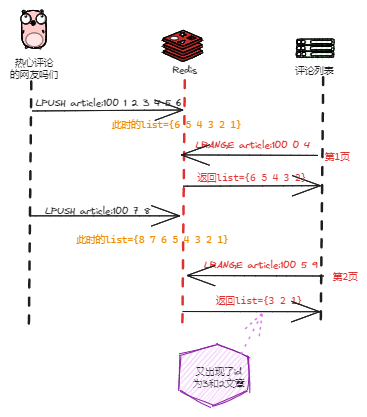
小总结:只有不需要分页(比如每次都只取列表的前 5 个元素)或者更新频率非常低的列表用 List 类型实现也是可以的
Sorted Set排序方案
相对于List,Sorted Set优势在于无论以怎样的方式插入集合都会根据权重进行排序,非常适用于各种排序统计逻辑

比如:小许发布的文章中想按收藏数排序选出最热门的5篇文章,那么就可以将收藏数的值设置score,新增收藏数,就讲score的值再增加1
// 这里拿两篇文章来举例咯,分别是50、60个收藏,不然命令比较长
127.0.0.1:6379> ZADD likeTopList 50 article:1 60 article:2
(integer) 2每次收藏增加就可以用ZINCRBY命令将sorce+1
127.0.0.1:6379> ZINCRBY likeTopList 1 article:1
"51"而ZRANGEBYSCORE命名就可以返回有序集合中指定分数区间的元素,分数由低到高,比如下面命令
127.0.0.1:6379> ZRANGEBYSCORE likeTopList 50 60 WITHSCORES
1) "article:1"
2) "51"
3) "article:2"
4) "60"可通过 ZREVRANGE key start stop [WITHSCORES]指令,获取集合中score最大的值是多少
127.0.0.1:6379> ZREVRANGE likeTopList 0 0 WITHSCORES
1) "article:2"
2) "60"我们可以看出即使集合中的元素更新频繁,也能够用Sorted Set类型的相关命令去方便有效的进行获取数据排序,相对于List而言,是更适合最新列表,排行榜等场景的使用。
二值统计
二值指的是值只有两种状态,也就是集合中的元素的值只有0和1两种,最简单的实现方式我们可以用Redis的String类型,比如标记用户的上下线状态
set userId 1 //上线
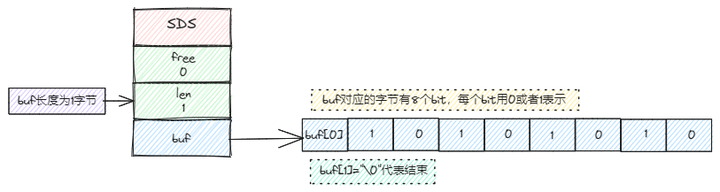
set userId 0 //下线这种实现看起来可以,但是万一有百万用户,这样记录上下线状态就太消耗内存了,string类型底层的sds结构体属性如下:
- buf:字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个'\0',这就会额外占用 1 个字节的开销
- len:占 4 个字节,表示 buf 的已用长度,不包括'\0'
- alloc:也占 4 个字节,表示 buf 的实际分配长度,不包括'\0'
因此,二值统计用在大量数据时string类型是不合适的
Bitmap(位图)结构是什么,如何解决这个问题的?
BitMap (位图)的底层数据结构使用的是String类型的的 SDS 数据结构来保存。因为一个字节8个bit位,为了有效的将字节的8个bit都利用到位,使用数组模式存。因此string类型最大存512M内容,所以位图的存储上限是2^32,可以存将近43亿的值,太能存了!
8 bit = 1byte
1024 byte = 1kb
1024 kb = 1Mb
Bitmap存储量计算方式: 8 * 1024 * 1024 * 512 = 2^32 (42.9亿),
并且每个bit都使用二值状态表示,要么0,要么1,每个字节有8个bit,如下图:
介绍完Bitmap我们来看下该如何用在我们的需求上,1表示用户上线 0表示下线,我们先看下Bitmap常用命令
SETBIT命令设置或者清空key在offset处的bit值(0或1),GETBIT来获取值
//设置用户id为1001的状态为上线
127.0.0.1:6379> SETBIT loginStatus 1001 1
(integer) 0
//获取用户1001的登录状态
127.0.0.1:6379> GETBIT loginStatus 1001
(integer) 1
127.0.0.1:6379> SETBIT loginStatus 1001 0
(integer) 1
//设置用户id为1001的状态为下线
127.0.0.1:6379> GETBIT loginStatus 1001
(integer) 0这个登录上下线的案例比较简单,我们每天上班都要打卡吧,然后每个月还得汇总我们的打卡记录看我们是否满勤,按一个月31天算,每个人的考勤只需要31个bit就搞定了。
我们key设置为 uid:dateSign:1001:202309 (用户ID为1001在9月份的打卡记录),这里简单举个栗子
//2023年9月21号打卡
127.0.0.1:6379> SETBIT uid:dateSign:1001:202309 21 1
(integer) 0
//2023年9月22号打卡
127.0.0.1:6379> SETBIT uid:dateSign:1001:202309 22 1
(integer) 0
////2023年9月23号未打卡
127.0.0.1:6379> SETBIT uid:dateSign:1001:202309 23 0
(integer) 0
...如果统计本月用户1001的打开记录,就可以用 BITCOUNT 指令 (用于统计给定的 bit 数组中值为1 的 bit 位的数量)
127.0.0.1:6379> BITCOUNT uid:dateSign:1001:202309
(integer) 2这个BITCOUNT指令还是很给力的,一下子就出了结果
BITPOS 返回数据表示 Bitmap 中第一个值为 0或1 的 offset 位置,比如这个月第一次打卡日期,如下命令,你看是21号,赞!
127.0.0.1:6379> BITPOS uid:dateSign:1001:202309 1
(integer) 21基数统计
基数就是不会重复的数字,对于基数统计就是统计元素中不会重复的元素,常见于网站的PV、UV统计。
关于基数统计其实方案有很多,如Set、HyperLogLog,甚至可以使用Hash
Set实现
Set集合本来就是可以去重的,所以在计算时只要将用户id设置到集合中即可,因此能保证不会重复去记录同一个用户ID
比如:我们来统计一个网站有多少用户访问了,一天内访问多次也只能算作是一次,那么通过Set集合就可以这么实现。
// value为用户ID, key为页面+日期
127.0.0.1:6379> SADD page1:0921 1001
(integer) 1
127.0.0.1:6379> SADD page1:0921 1002
(integer) 1
127.0.0.1:6379> SADD page1:0921 1001
(integer) 0
127.0.0.1:6379> SADD page1:0921 1001
(integer) 0通过 SCARD 命名就可以,返回集合的元素个数,也就是用户数,SMEMBERS 返回的是返回的是集合内具体的元素
127.0.0.1:6379> SCARD page1:0921
(integer) 2
127.0.0.1:6379> SMEMBERS page1:0921
1) "1001"
2) "1002"Hash实现
Hash类型的实现方式是利用了Hash中的属性不能重复的特性来处理,实现起来我们把页面+日期作为key,然后Hash中的field和value分别设置为用户id和1,具体如下:
127.0.0.1:6379> HSET page2:20230921 1001 1
(integer) 1
127.0.0.1:6379> HSET page2:20230921 1002 1
(integer) 1
127.0.0.1:6379> HSET page2:20230921 1001 1
(integer) 0
//利用HLEN统计访问数 uv
127.0.0.1:6379> HLEN page2:20230921
(integer) 2HyperLogLog实现
Set和Hash的问题在于如果页面用户访问持续增长,集合的内存消耗也将大幅度提升会出现bigkey的情况,这样就不利于统计了。
Redis 提供的 HyperLogLog 高级数据结构,是一种用于基数统计的数据集合类型,即使数据量很大,计算基数需要的空间也是固定的,比方说
最多只需要花费 12KB 内存就可以计算 2 的 64 次方个元素的基数。
我们看看怎么使用
// PFADD命令往key:page3:20230921添加记录
127.0.0.1:6379> PFADD page3:20230921 1001 1002 1003 1004
(integer) 1
127.0.0.1:6379> PFADD page3:20230921 1002 1003 1005 1006 1007
(integer) 1PFCOUNT 命令获取页面uv值,这里两次添加的值当中 1002、1003是重复的,所以得出的结果是 7
127.0.0.1:6379> PFCOUNT page3:20230921
(integer) 7这里都是计算单个页面的值,假如需要统计多个页面一起的uv值的话,我们就可以用 PFMERGE 命令来整合多个HyperLogLog 合并在一起形成一个新的 HyperLogLog 值。
127.0.0.1:6379> PFADD page4:20230921 1002 1003 1005 1006 1007 1008 1009
(integer) 1
127.0.0.1:6379> PFMERGE commonPageUv page4:20230921 page3:20230921
OK
127.0.0.1:6379> PFCOUNT commonPageUv
(integer) 9这里我们新统计了page4的浏览,然后讲page3和page4的结果进行整合到commonPageUv这个HyperLogLog中,最后统计的结果是9,没错。
至于缺点我们在文章开头也讲了,存在一定误差,使用之前要知道这点!
总结
关于 Redis统计场景的方案和方法就介绍到这里了,根据需求和实际情况去选择,希望对你在处理开发问题的时候有帮助!
👨👩 朋友,希望本文对你有帮助~🌐
欢迎点赞 👍、收藏 💙、关注 💡 三连支持一下~🎈
我是小许,下期见~🙇💻
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号