开源软件 FFmpeg 生成模型使用图片数据集
原创
开源软件 FFmpeg 生成模型使用图片数据集
原创
soulteary
发布于 2023-11-14 16:18:49
发布于 2023-11-14 16:18:49
本篇文章聊聊,成就了无数视频软件公司、无数在线视频网站、无数 CDN 云服务厂商的开源软件 ffmpeg。
分享下如何使用它将各种视频或电影文件,转换成上万张图片数据集、壁纸集合,来让下一篇文章中的模型程序“有米下锅”,这个方法特别适合宫崎骏、新海诚这类“壁纸合集”类电影。
写在前面
这篇文章,是作为接下来机器之心举办的分享活动《使用向量数据库快速构建本地轻量图片搜索引擎》而准备的其中一篇素材。因为朋友给我的命题是“图片搜索引擎”,所以想要做这场分享,我们还需要一些有趣的、有意义的图片数据。
其实,在一年前,我曾经分享过一些 有关 Milvus 的实践,其中有一篇内容就是《向量数据库入坑:使用 Docker 和 Milvus 快速构建本地轻量图片搜索引擎》。但是在这一篇文章里,我用的是从搜索引擎搜索出的第一页原神卡通壁纸,数量不多,只有 60 多张壁纸。
为了体现这个图片搜索引擎的性能,这次需要把图片整多些。
而想要获取大量的图片,假如通过编写蜘蛛脚本从网上“漫游式的爬取”内容,一来效率比较低,二来在不引入图片安全审核模型的前提下,很容易引入奇奇怪怪的内容,这不是我想看到的结果,也大概是邀请我分享的朋友害怕出现的结果。
如果采用之前文章中提到的生成式模型来制作数据集,比如“Stable Diffusion”或者“Midjourney”,效率恐怕就更不能保障啦,因为即使我使用出图速度比较快的 4090,等我生成够我想要的图片数量,活动可能也早就结束了。(友情帮忙也得考虑成本,不能折腾训练那种堆卡的事情,给主办方造成困扰,哈哈)
所以,通过 ffmpeg 从海量的电影、电视剧、短视频中抽取图片,形成数据集,作为学习尝试的思路,或许是一个超高性价比的路线。
注意,本篇文章仅讨论如何通过 FFmpeg 创建有价值的、高质量的图片数据集,观影、欣赏你喜欢的作者、演员制作的作品,还是建议在合适的场合,使用合适的方式,比如:带着你的女票一起去电影院里,她看着电影,你看着她。

当然,有可能还有它会看着你
之所以使用视频中的关键帧作为数据集,主要的原因是:这类数据比较有代表性、画面质量相对较高,包含高质量的多种分类的图片。 目前互联网流量中绝大多数是视频,在“哔哩哔哩”或者各种 PT 爱好者网站、以及各种百度云、阿里云盘等资源站点,视频资源的获取难度相对较低,资源相对充分,比如这篇文章我们可以以科幻电影为例,也可以以纪录片为例、或者用连续剧也没啥问题。
在这篇文章中,我选择了今年我最喜欢的一部电影:流浪地球2。(强烈推荐电影博物馆观看,体验非常棒)

流浪地球2
我把这部电影,按照每秒取一副画面,转换成了 10393 张图片,相对于第一次分享使用的 60 张图片,数量级提升了三个等级。其实也不多,在数据库面前,这个数量级还是太小了。

图片、壁纸数据集
当然,你也可以玩把更大的,选择诸如 “哈利波特系列”、“老友记”、“狂飙” 这种可以转换出图片数量更多的电影、电视剧作为目标,轻轻松松搞出十万级、百万级的图片数据集。
或者将新海诚、宫崎骏的画面非常精致的“卡通壁纸”类型的动漫,写个程序,每隔几秒随机换一张图作为壁纸,也十分有乐趣。
言归正传,开始一起了解,如何使用 ffmpeg 来搞定数据集的生成,以及生成过程中的细节。
FFmpeg 的安装
FFmpeg 开源项目
FFmpeg 是全平台的开源软件,所以其实在包括手机上、游戏机中都能够找到它的身影,但是我们今天主要聊的是转换视频为图片数据集,所以就只看主流三大生产力平台就好:
在 Ubuntu 或者 macOS 环境中,我们只需要一条命令,就能够完成 FFmpeg 的安装。
# Ubuntu
apt-get install ffmpeg -y
# macOS
brew install ffmpegWindows 操作系统中,需要下载并使用软件包进行安装,使用官方下载地址就好。
如果你更喜欢使用 Docker,我推荐使用 LinuxServer 组织维护的 FFmpeg Docker镜像,镜像发布页面有提供常见的用法示例,就不过多赘述啦:
docker pull linuxserver/ffmpeg好了,因为是纯 C 编写的程序,安装其实挺简单的,没啥特别的依赖。
基础使用
如果你希望将视频每一秒都转换为图片,图片保持和视频一样的分辨率,可以使用下面的命令:
ffmpeg -i The.Wandering.Earth.Ⅱ.mp4 ball-%3d.png命令开始执行后,就能够看到滚动的日志:
ffmpeg version 6.0 Copyright (c) 2000-2023 the FFmpeg developers
built with Apple clang version 15.0.0 (clang-1500.0.40.1)
configuration: --prefix=/opt/homebrew/Cellar/ffmpeg/6.0_1 --enable-shared --enable-pthreads --enable-version3 --cc=clang --host-cflags= --host-ldflags='-Wl,-ld_classic' --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libaribb24 --enable-libbluray --enable-libdav1d --enable-libjxl --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librist --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libsvtav1 --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libspeex --enable-libsoxr --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack --enable-videotoolbox --enable-audiotoolbox --enable-neon
libavutil 58. 2.100 / 58. 2.100
libavcodec 60. 3.100 / 60. 3.100
libavformat 60. 3.100 / 60. 3.100
libavdevice 60. 1.100 / 60. 1.100
libavfilter 9. 3.100 / 9. 3.100
libswscale 7. 1.100 / 7. 1.100
libswresample 4. 10.100 / 4. 10.100
libpostproc 57. 1.100 / 57. 1.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'The.Wandering.Earth.Ⅱ.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : OurTV Multimedia Platform
Duration: 02:53:11.54, start: 0.000000, bitrate: 6994 kb/s
Stream #0:0[0x1](und): Video: hevc (Main 10) (hev1 / 0x31766568), yuv420p10le(tv, bt2020nc/bt2020/smpte2084), 3840x1608, 6328 kb/s, 120 fps, 120 tbr, 90k tbn (default)
...
...
Stream mapping:
Stream #0:0 -> #0:0 (hevc (native) -> png (native))
Press [q] to stop, [?] for help
Output #0, image2, to 'ball-%3d.png':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : Lavf60.3.100
Stream #0:0(und): Video: png, rgb48be(pc, gbr/bt2020/smpte2084, progressive), 3840x1608, q=2-31, 200 kb/s, 1 fps, 1 tbn (default)
...
frame= 116 fps= 15 q=-0.0 size=N/A time=00:00:00.95 bitrate=N/A speed=0.126x s/s speed=N/A
...随着程序的运行,目标文件夹中,会生成被命名为 ball-001.png、ball-002.png … 等等每一帧图片。
上面的日志会大量的重复,但是在里面会有一些重要的细节,影响着我们这个数据集生成工作的效率,其中之一是:speed 展示状态。
在上面的日志中,speed=0.126x 是指我们的解码和保存图片的性能大概是正常播放速度的一折。也就是说,每一分钟的视频,它需要花费接近两分钟的时间来处理,如果我们处理的视频时间特别久,那么这个“加倍”操作会让我们非常痛苦。
除此之外,还有一个非常关键的隐藏细节:生成结果的硬盘占用空间。
我们都知道,视频文件格式出于“方便数据流通”和“缓解存储压力”的设计考量,类比压缩包文件,有着比较高的压缩率,如果我们将每一帧视频都单独的截取并保存,面对 1 秒内有几十帧的高帧率 4K 或者 8K 电影,图片数据集还没转换完,我们的磁盘可能就用光了,因为每一张图片的尺寸都在 10M 以上,一部 2 个小时整的电影按最低的 25 帧计算,也会出现十八万张图,需要接近 2TB 的存储空间。
如果不是类似郭帆导演的“球系列电影”团队,不需要来回 review 作品的每一帧,那么可能没啥必要这样做,太不经济、太不环保了。
提升转换性能:减少转换图片数量
上面提到了,电影或者各种视频,为了让我们看起来流畅,帧率数值会比较高。但其实一来视频画面变化区别不大,二来存这么多图,存的过程中,CPU 的占用、硬盘的占用实在的颇高,后续处理这些图片也需要消耗更多的时间。
所以,提升转换性能的第一个方案就是,减少不必要的图片数据集的生成。
如果你希望将视频每一秒都转换为图片,图片保持和视频一样的分辨率,可以使用下面的命令:
ffmpeg -i The.Wandering.Earth.Ⅱ.mp4 -r 1 ball-%3d.png命令开始执行后,就能够看到滚动的日志:
ffmpeg version 6.0 Copyright (c) 2000-2023 the FFmpeg developers
built with Apple clang version 15.0.0 (clang-1500.0.40.1)
configuration: --prefix=/opt/homebrew/Cellar/ffmpeg/6.0_1 --enable-shared --enable-pthreads --enable-version3 --cc=clang --host-cflags= --host-ldflags='-Wl,-ld_classic' --enable-ffplay --enable-gnutls --enable-gpl --enable-libaom --enable-libaribb24 --enable-libbluray --enable-libdav1d --enable-libjxl --enable-libmp3lame --enable-libopus --enable-librav1e --enable-librist --enable-librubberband --enable-libsnappy --enable-libsrt --enable-libsvtav1 --enable-libtesseract --enable-libtheora --enable-libvidstab --enable-libvmaf --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx264 --enable-libx265 --enable-libxml2 --enable-libxvid --enable-lzma --enable-libfontconfig --enable-libfreetype --enable-frei0r --enable-libass --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libspeex --enable-libsoxr --enable-libzmq --enable-libzimg --disable-libjack --disable-indev=jack --enable-videotoolbox --enable-audiotoolbox --enable-neon
libavutil 58. 2.100 / 58. 2.100
libavcodec 60. 3.100 / 60. 3.100
libavformat 60. 3.100 / 60. 3.100
libavdevice 60. 1.100 / 60. 1.100
libavfilter 9. 3.100 / 9. 3.100
libswscale 7. 1.100 / 7. 1.100
libswresample 4. 10.100 / 4. 10.100
libpostproc 57. 1.100 / 57. 1.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'The.Wandering.Earth.Ⅱ.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : OurTV Multimedia Platform
Duration: 02:53:11.54, start: 0.000000, bitrate: 6994 kb/s
Stream #0:0[0x1](und): Video: hevc (Main 10) (hev1 / 0x31766568), yuv420p10le(tv, bt2020nc/bt2020/smpte2084), 3840x1608, 6328 kb/s, 120 fps, 120 tbr, 90k tbn (default)
...
...
Stream mapping:
Stream #0:0 -> #0:0 (hevc (native) -> png (native))
Press [q] to stop, [?] for help
Output #0, image2, to 'ball-%3d.png':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : Lavf60.3.100
Stream #0:0(und): Video: png, rgb48be(pc, gbr/bt2020/smpte2084, progressive), 3840x1608, q=2-31, 200 kb/s, 1 fps, 1 tbn (default)
...
frame= 7 fps=0.8 q=-0.0 size=N/A time=00:00:06.00 bitrate=N/A dup=0 drop=868 speed=0.656x =81 speed=N/A
...因为每秒现在只存放一张图片,不需要计算的部分,被直接 drop 丢弃掉,所以能够明显的看到,我们的处理速度有了质变,原来的“一折”的处理速度,提升到了 speed=0.656x,硬盘的压力和后续的处理压力也能够减少许多。
但是,如果我们随便选择一张图片来看,会发现图片的尺寸依旧是惊人的。
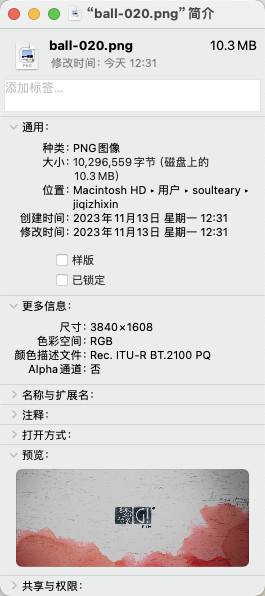
挺大个的一张图,或者应该说每一张图
这个尺寸,对于我们后续的处理程序以及模型程序,在解析图片的时候,会有很多不必要的压力。当然,如果你追求的是超级高清的壁纸数据集,那么这篇文章,已经讲完了你所需要的一切内容啦。接下来你选择你喜欢的视频素材,进行壁纸数据集准备即可。
但是,如果你也和我一样,计划用视频素材来验证一些模型程序,或者实现类似图片搜索引擎的能力验证,还可以选择继续对数据集进行优化。
提升转换性能:减少图片计算尺寸
我们默认转换出的图片分辨率会保持和视频一致,在这篇文章的例子中,我得到的默认尺寸是 3840 × 1608 的图片。
采用小初高学习的“消元大法”,将图片的分辨率选择到一个你觉得合适的水平即可,比如可以选择将画面的长宽都缩减 12 倍:320x240,这样可以更快的让我的模型程序处理这些画面。注意,实际场景里,你应该调整为适合你的图片尺寸。
ffmpeg -i The.Wandering.Earth.Ⅱ.mp4 -r 1 -vf scale=320:240 ball-%3d.png命令非常简单,在输出的文件前加上 -vf scale=分辨率宽:分辨率高 即可。
然后你会发现转换速度也得到了大幅的加强:
frame= 14 fps=1.7 q=-0.0 Lsize=N/A time=00:00:13.00 bitrate=N/A dup=0 drop=1416 speed=1.55x 95 speed=N/A 使用 GPU 进行转换加速
上面的操作,都是在 CPU 环境下进行的,许多的云端媒体相关的服务,也都是使用同样的路子操作的:纯 CPU 计算。
使用 CPU 计算的好处是省钱,相比较 GPU,不论是硬件成本、散热成本,还是电源能耗成本,机房建设要求,门槛都低不少。
但是,倘若,你的笔记本或者你实际有显卡可以使用,那么 FFmpeg 的处理速度将得到更高的提升,当然,如果 CPU 本身能力足够强,使用 GPU 的意义则变成了,为 CPU 减负,让设备能够同时运行更多的任务(比如,我使用的 13900kf + 4090,转换效率来说,CPU 其实更强)。
当然,在使用显卡、加速卡做这类计算时,我们还需要确认我们的 ffmpeg 版本支持这个特性,可以使用 ffmpeg -hwaccels 来看看是否支持硬件解码加速:
# ffmpeg -hwaccels
ffmpeg version 6.0-6ubuntu1 Copyright (c) 2000-2023 the FFmpeg developers
built with gcc 13 (Ubuntu 13.2.0-2ubuntu1)
configuration: --prefix=/usr --extra-version=6ubuntu1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --arch=amd64 --enable-gpl --disable-stripping --enable-gnutls --enable-ladspa --enable-libaom --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libcodec2 --enable-libdav1d --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libglslang --enable-libgme --enable-libgsm --enable-libjack --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librabbitmq --enable-librist --enable-librubberband --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libsrt --enable-libssh --enable-libsvtav1 --enable-libtheora --enable-libtwolame --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzimg --enable-libzmq --enable-libzvbi --enable-lv2 --enable-omx --enable-openal --enable-opencl --enable-opengl --enable-sdl2 --disable-sndio --enable-libjxl --enable-pocketsphinx --enable-librsvg --enable-libvpl --disable-libmfx --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-chromaprint --enable-frei0r --enable-libx264 --enable-libplacebo --enable-librav1e --enable-shared
libavutil 58. 2.100 / 58. 2.100
libavcodec 60. 3.100 / 60. 3.100
libavformat 60. 3.100 / 60. 3.100
libavdevice 60. 1.100 / 60. 1.100
libavfilter 9. 3.100 / 9. 3.100
libswscale 7. 1.100 / 7. 1.100
libswresample 4. 10.100 / 4. 10.100
libpostproc 57. 1.100 / 57. 1.100
Hardware acceleration methods:
vdpau
cuda
vaapi
qsv
drm
opencl
vulkan日志输出的 “Hardware acceleration methods” 列表中,表明了哪些加速方式是可用的。
想要验证硬件加速,其实很简单。不过,我们先执行上面已经使用过的命令,不加任何特殊参数的,最大计算量的命令来收集一个基础的性能状况:
ffmpeg -i The.Wandering.Earth.Ⅱ.mp4 -r 1 -vf scale=320:240 ball-%3d.png处理速度大概是这样:
frame= 17 fps=3.6 q=-0.0 Lsize=N/A time=00:00:16.00 bitrate=N/A dup=0 drop=1836 speed=3.38x此时此刻,CPU 几乎被用满,如果处理的视频分辨率和帧率都再高一些,这台设备应该就不能再做什么其他的事情啦。
接着,我们来使用硬件加速的方式来处理这个视频:
ffmpeg -hwaccel cuda -i The.Wandering.Earth.Ⅱ.mp4 -r 1 -vf scale=320:240 ball-%3d.png在参数上添加 -hwaccel 加速方式 后运行命令,能够看到视频也会使用一个比较快的速度进行处理啦:
frame= 101 fps=3.2 q=-0.0 Lsize=N/A time=00:01:40.00 bitrate=N/A dup=0 drop=11771 speed=3.17x 当然,再次观察系统运行情况,能够看到系统 CPU 运行负载降低了非常多。
最后
好了,本篇的内容就先聊到这里。下一篇内容,我将继续展开向量数据库相关的内容。
—EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上、生活里以及职场中的一些问题,偶尔也在群里不定期的分享一些技术资料。
关于交友的标准,请参考下面的文章:
当然,通过下面这篇文章添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 :D
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年11月14日
统计字数: 11057字
阅读时间: 23分钟阅读
本文链接: https://soulteary.com/2023/11/14/ffmpeg-generates-models-using-image-datasets.html
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号