跟着Nature Communications学数据分析:R语言LEA包做变异位点和环境数据的关联分析

跟着Nature Communications学数据分析:R语言LEA包做变异位点和环境数据的关联分析

用户7010445
发布于 2023-11-20 16:36:33
发布于 2023-11-20 16:36:33
论文
Genomic insights into local adaptation and future climate-induced vulnerability of a keystone forest tree in East Asia
https://www.nature.com/articles/s41467-022-34206-8
论文的代码链接
https://github.com/jingwanglab/Populus_genomic_prediction_climate_vulnerability
还有一篇论文有代码和数据
论文
Genomic signals of local adaptation and hybridization in Asian white birch
https://onlinelibrary.wiley.com/doi/full/10.1111/mec.16788
代码链接https://github.com/GabrieleNocchi/betula_platyphylla_local_adaptation
这个里是有对应的数据的
今天的推文我们学习一下NC这篇论文中 鉴定与环境因素相关的变异位点 (Identification of environment-associated genetic variants)的代码
需要准备两个输入数据
一个是基因型数据,格式如下

image.png
每行是一个样本,每列是一个变异位点
还有一个是环境数据
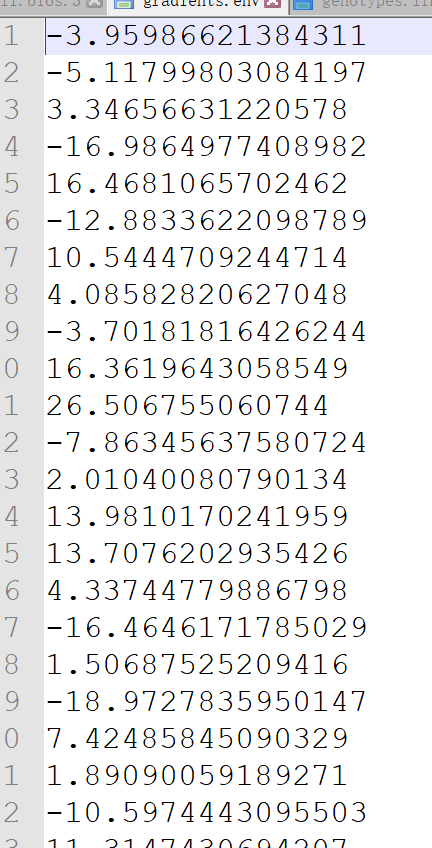
image.png
这两个数据是LEA这个R包自带的示例数据
分析代码
library(LEA)
library(tidyverse)
project <- lfmm(input.file = "genotypes.lfmm",
environment.file = "gradients.env",
CPU=1,
K = 3,
repetitions = 5,
project = "new")
p1 <- lfmm.pvalues(project, K = 3, d = 1, run = 1)
p1$pvalues
p2 <- lfmm.pvalues(project, K = 3, d = 1, run = 2)
p2$pvalues
p3 <- lfmm.pvalues(project, K = 3, d = 1, run = 3)
p3$pvalues
p4 <- lfmm.pvalues(project, K = 3, d = 1, run = 4)
p4$pvalues
p5 <- lfmm.pvalues(project, K = 3, d = 1, run = 5)
p5$pvalues
average.pvalue<-c(p1$pvalues+p2$pvalues+p3$pvalues+p4$pvalues+p5$pvalues)/5
average.pvalue
q_value<-qvalue::qvalue(average.pvalue,fdr.level = 0.05)
q_value$lfdr
q_value$pvalues
average.pvalue
df<-bind_rows(
data.frame(y=q_value$pvalues,group="pvalue"),
data.frame(y=q_value$qvalues,group="qvalue"),
data.frame(y=q_value$lfdr,group="lfdr"),
)
ggplot(data=df,aes(x=group,y=y))+
geom_jitter(aes(color=group),
size=5,
alpha=0.8)+
theme_bw(base_size = 20)+
theme(panel.grid = element_blank())
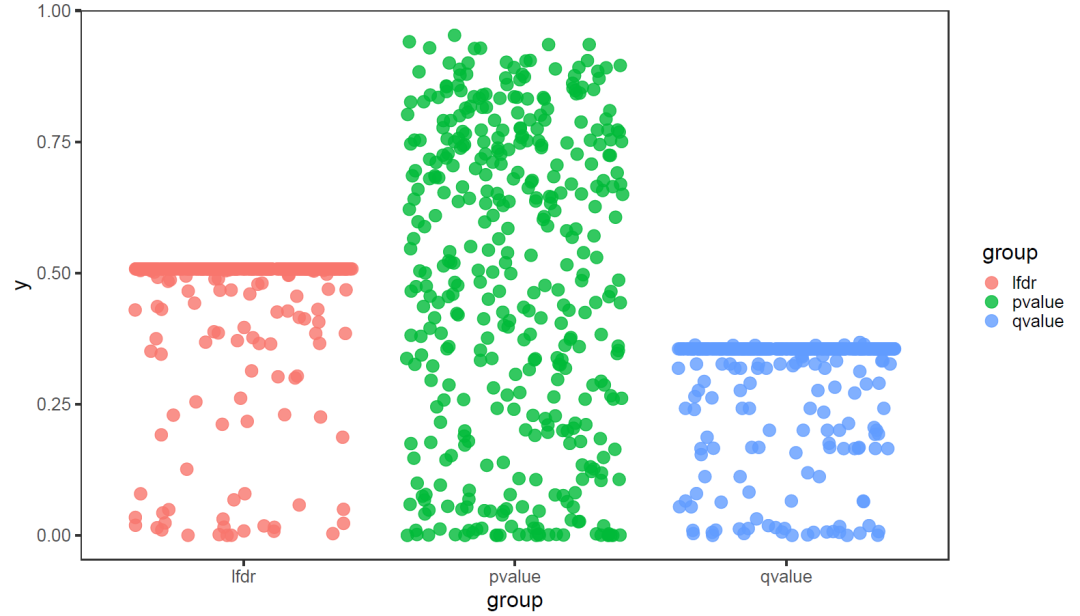
论文中最终设置变异位点和环境数据关联的p值的阈值的时候写了两个方法

image.png
这里
Bonferroni correction, adjusted P=0.05 应该是0.05直接除以位点数
FDR correction, adjusted P = 0.05 这个是什么意思暂时没有看明白
论文中方法部分写的是
P values from all five runs were then averaged for each variant and adjusted formultiple tests using a false discovery rate (FDR) correction of 5% as the significance cutoff
论文里提供的代码写的是
then merge 5-runs results, and calculate the average Pvalue of every site and turn in to q-value in R
代码部分计算qvalue
q_value=qvalue::qvalue(summary$P,fdr.level=0.05)
这里会获得一个qvalue, 只要这个qvalue小于0.05就是显著的吗?这里还是没有搞明白
论文中的figure3a 曼哈顿图展示的还是pvalue的显著性,qvalue的显著性怎么转换到pvalue上呢?
image.png
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-11-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号