SORT新方法AM-SORT | 超越DeepSORT/CO-SORT/CenterTrack等方法,成为跟踪榜首

SORT新方法AM-SORT | 超越DeepSORT/CO-SORT/CenterTrack等方法,成为跟踪榜首

集智书童公众号
发布于 2024-01-29 12:49:31
发布于 2024-01-29 12:49:31

许多基于卡尔曼滤波器的多目标跟踪(MOT)方法假设恒定速度和高斯分布的滤波噪声。这些假设使得基于卡尔曼滤波器跟踪器在线性运动场景中有效。然而,这些线性假设在估计涉及非线性运动和遮挡的场景中未来的物体位置时,成为关键限制。 为了应对这个问题,作者提出了一种基于运动的MOT方法,称为AM-SORT,它是一种适应性运动预测器,可以估计非线性不确定性。AM-SORT是SORT系列跟踪器的创新延伸,它使用 Transformer 架构作为运动预测器,超越了卡尔曼滤波器。作者引入了一种历史轨迹嵌入,使 Transformer 能够从一系列边界框的序列中提取时空特征。 AM-SORT在DanceTrack上的性能与最先进的跟踪器相媲美,IDF1达到56.3,HOTA达到55.6。作者进行了大量的实验来证明作者的方法在预测遮挡下的非线性运动方面的有效性。
1 Introduction
基于运动的多目标跟踪(MOT)方法利用运动预测器提取时空模式,并估计未来帧中的物体运动,以便后续的物体关联。原始的卡尔曼滤波器广泛用作运动预测器,它假设预测和滤波阶段分别具有常速和高斯分布的噪声,分别对应于。常速假设物体速度和方向在短期内保持一致,高斯分布假设估计和检测中的误差方差保持恒定。虽然这些假设通过简化数学建模使卡尔曼滤波器具有高效性,但它们仅适用于特定场景,即物体位移保持线性或始终较小。由于忽略了具有非线性运动和遮挡的场景,卡尔曼滤波器在复杂情况下错误地估算物体位置。
为了克服原卡尔曼滤波器的局限性,提出了替代的估计算法,如扩展卡尔曼滤波器(EKF)和无味卡尔曼滤波器(UKF)。EKF线性化物体运动建模,而UKF通过使用一阶和三阶泰勒级数展开来估计非线性变换。然而,这两种方法仍然依赖于非线性系统的线性近似和假设高斯分布的噪声。另一方面,粒子滤波器通过利用一组离散的粒子来处理非线性和非高斯噪声,避免线性化,但需要消耗昂贵的计算资源。
最近,OC-SORT通过强调观测而不是估计来减少运动预测中的噪声,从而改进了原卡尔曼滤波器。虽然这种方法在遮挡期间可以跟踪具有线性运动的物体,但OC-SORT仍面临非线性运动方面的挑战。当由非线性运动或遮挡引起缺乏观测时,OC-SORT依赖于其基于原卡尔曼滤波器固有线性假设的线性估计。因此,这种基于线性假设的建模在运动预测中累积错误,导致轨迹偏差。
作者认为,卡尔曼滤波器固有的线性假设会导致非线性不确定性下的运动估计不准确和错误的识别匹配。由于这些假设,运动估计中的累积误差限制了基于卡尔曼滤波器的处理非线性不确定性的方法。
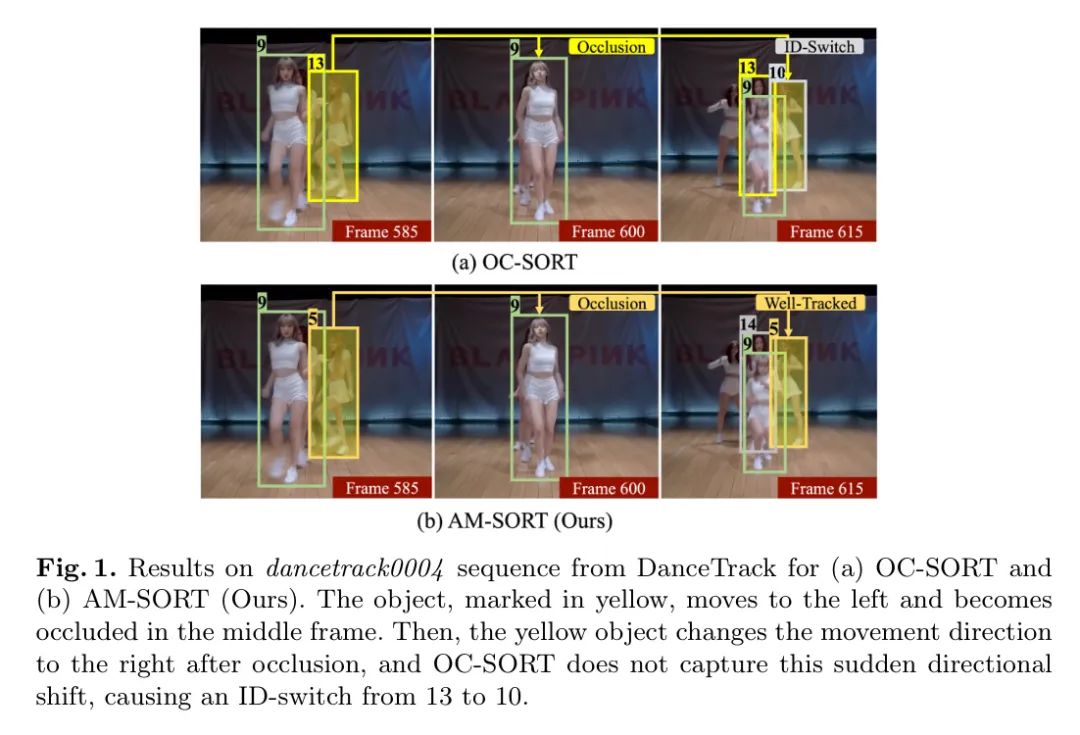
图1显示了在遮挡下的非线性运动场景中的跟踪结果(a)OC-SORT和(b)作者的AM-SORT。如图1(a)所示,当发生遮挡事件后,黄色物体的识别发生了切换。卡尔曼滤波器中的线性运动假设导致运动估计中的方向错误,黄色物体继续向左移动。因此,卡尔曼滤波器依赖于这些具有累积方向错误的线性估计,无法预测方向性的改变。
在本文中,作者提出了一种可适应的运动预测器,该预测器具有历史轨迹嵌入,用于解决卡尔曼滤波器固有线性假设的局限性。适应能力使运动预测器摆脱了线性假设的约束,允许其估计与非线性运动相关的不确定性。
受到 Transformer 架构的启发,这种架构以其在序列数据中捕获复杂依赖性的能力而闻名,作者探索了使用 Transformer 编码器作为可适应的运动预测器的方法。与传统的基于 Transformer 的多目标跟踪(MOT)方法不同,作者利用 Transformer 仅编码运动信息,而不包含目标关联的视觉特征,如图2所示。利用边界框作为输入特征提供了一种有限的物体表示,与外观信息相比,但显著降低了计算复杂性。为了保持与卡尔曼滤波器相当的简单性和资源效率,作者专注于 Transformer 编码器,仅从物体轨迹中学习目标区分特征。
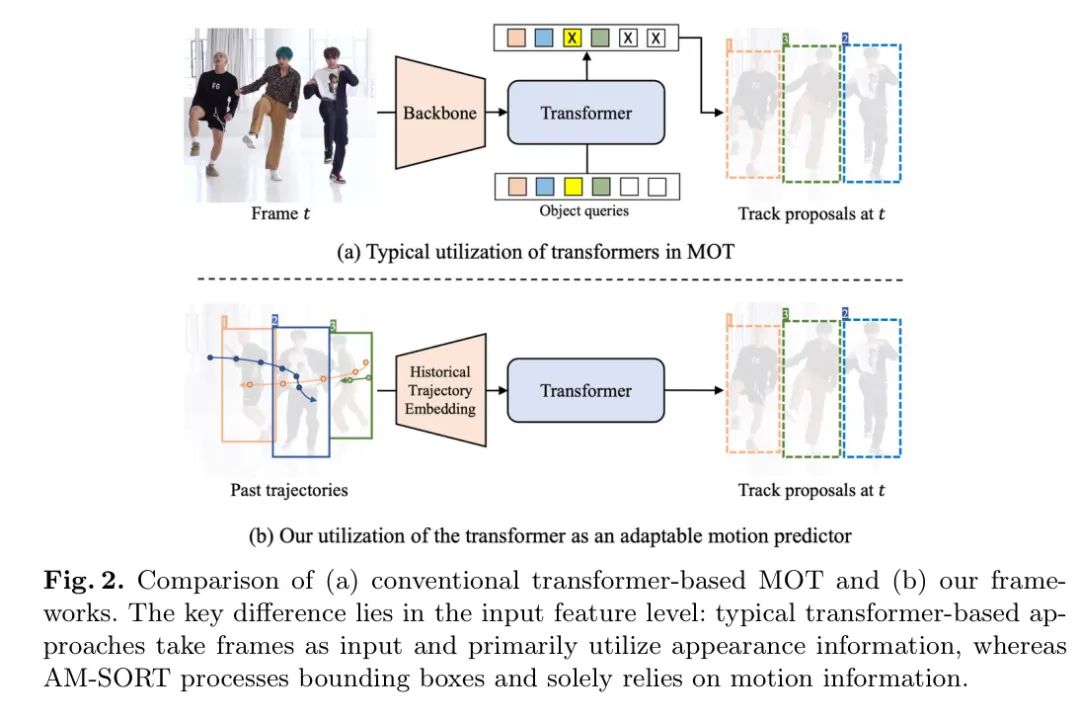
此外,作者的可适应运动预测器可以通过分析和观察比卡尔曼滤波器更长的物体轨迹而获得好处,卡尔曼滤波器仅基于前一时间步的估计来预测物体运动。
为了增强长物体轨迹的表示,作者提出了一种历史轨迹编码,它编码了边界框序列中的时空信息。因此,作者将嵌入的边界框与当前帧的预测标记(预测框)进行拼接。编码器从历史轨迹编码中提取时空特征,使预测标记能够估计当前帧中的边界框。值得注意的是,AM-SORT使用边界框序列作为输入,省略了物体的视觉特征,这使得模型可以在低计算成本下处理。
作者的主要贡献如下:
- 作者提出了一种新颖的SORT系列跟踪器,称为AM-SORT,它具有可适应的运动预测器,可以提供无需线性假设的非线性运动估计。
- 作者引入了历史轨迹嵌入,可以有效地从一系列边界框的序列中捕获运动特征。
- 定性结果表明,AM-SORT准确地预测了物体运动中的非线性变化,展示了与最先进方法竞争的能力。
2 Proposed Method
AM-SORT利用运动线索健壮地跟踪具有非线性运动模式的物体。作者的主要关注点是通过引入基于 Transformer 编码器的可适应运动预测器,实现对非线性不确定性的准确估计,从而超越卡尔曼滤波器。图3显示了AM-SORT的整体流程。具体来说,作者输入单个物体的历史轨迹,其中包含一系列前几帧中的边界框序列。
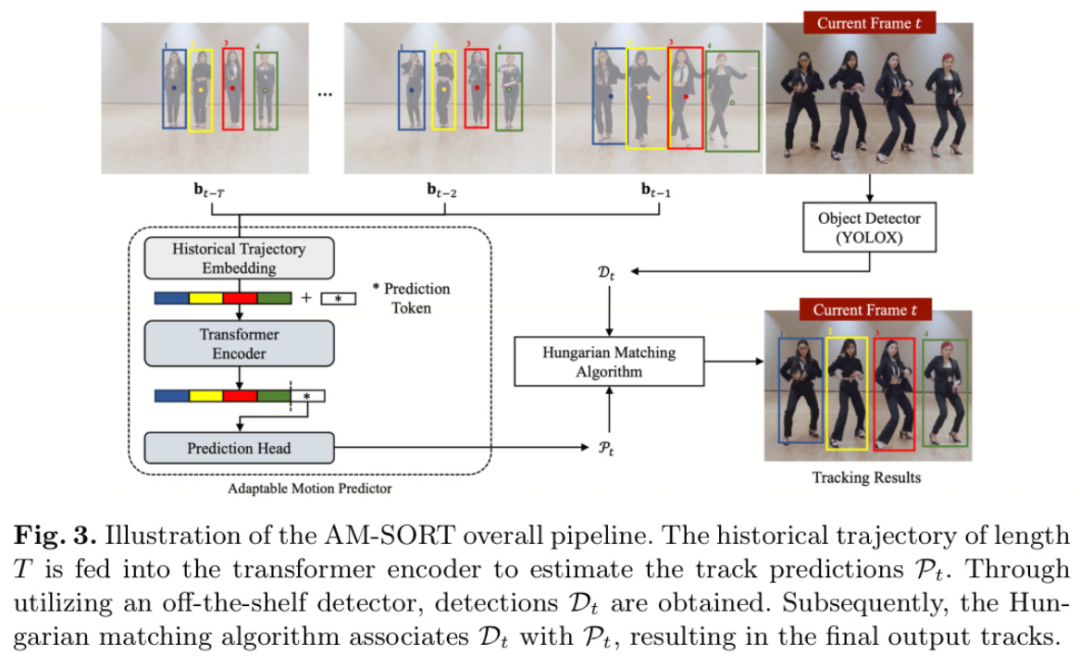
历史轨迹被表示为
,其中
是预定义的历史轨迹长度。边界框被表示为
,其中
是物体在图像平面上的中心坐标,
和
分别表示宽度和高度。
Transformer 编码器产生精炼的预测标记,然后通过预测头将其转换为边界框
。估计的边界框生成一组当前帧的跟踪预测,称为
。接下来,根据匈牙利匹配算法使用互交比(IoU)将
与对应帧的检测
关联。
Historical Trajectory Embedding
历史轨迹嵌入同时编码来自一系列边界框的时空信息,包括三个操作:空间嵌入、预测标记拼接和时间嵌入。图4说明了在作者的运动预测器中历史轨迹嵌入的结构。
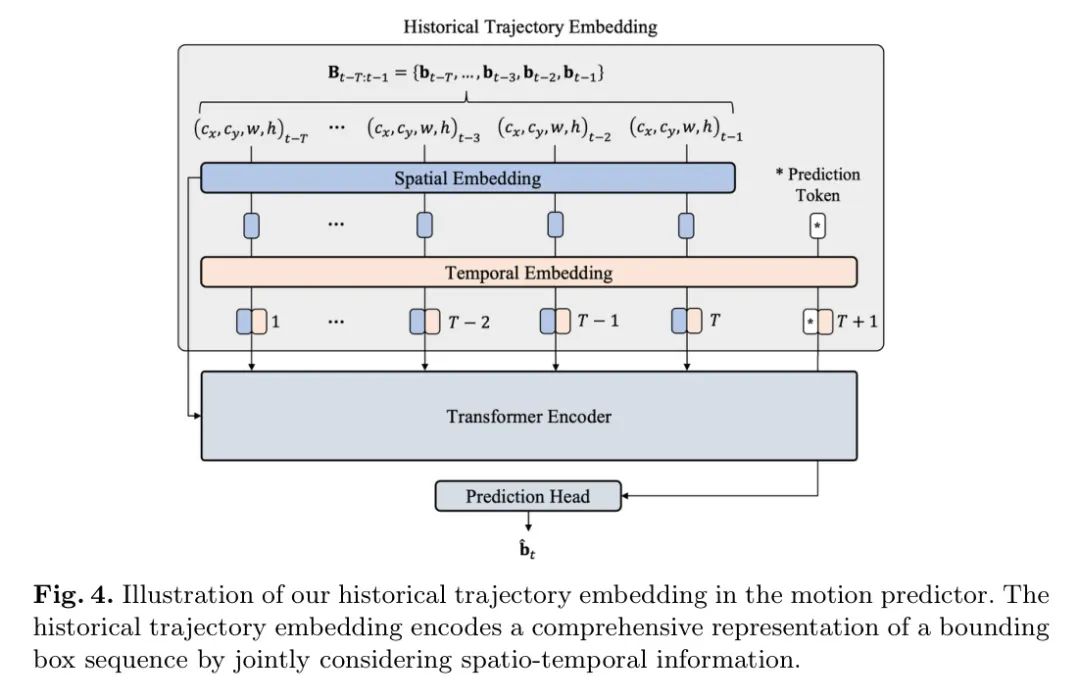
对于空间嵌入,作者使用正弦位置编码将低维边界框转换到高维空间,以便更精细地表示每个边界框,如下所示:
其中,
表示空间嵌入操作,
是嵌入维度,
表示边界框的嵌入。
随后,将整个序列的预测标记与空间嵌入拼接在一起。这个预测标记是一个可学习的嵌入,作为当前帧
中的边界框。数学公式如下:
其中,
表示历史轨迹的空间嵌入,通过将空间嵌入和预测标记
拼接得到。
对于时间嵌入,作者采用与空间嵌入相似的位置编码。相反,作者将自然数编码为每个序列中的空间嵌入的连续编号,从
到
,以逆序编码,即从最后一个元素开始。这确保模型优先考虑历史轨迹嵌入的最后部分,即使对于历史轨迹长度小于
的物体也是如此。因此,历史轨迹嵌入如下所示:
其中,
表示作者的历史轨迹嵌入,
表示时间嵌入,
是从
到
的自然数序列。
值得注意的是,在边界框预测的背景下,物体定位至关重要。因此,在将历史轨迹嵌入传递给每个编码器层之前,作者会在其中增加额外的空间信息。
Adaptable Motion Predictor
作者使用 Transformer 编码器作为可适应的运动预测器,其中包含多头自注意力(MHSA)层和前馈神经网络。MHSA有助于历史轨迹中每个边界框之间的相互作用,提取它们的非线性关系。这个过程通过提供足够的信息来精确地定位当前帧中的物体边界框,公式如下:
其中,
表示 Transformer 编码器操作,
表示精炼的历史轨迹嵌入。预测头只接收预测标记
,它是精炼的历史轨迹嵌入中的最后一个元素,并利用它生成边界框坐标,如下所示:
其中,
表示预测头,
是在当前帧中估计的边界框。预测头由三个线性层组成,每个层后面都有一个ReLU激活函数,最后一个层使用一个Sigmoid激活函数将边界框坐标在
和
之间的范围进行转换。
Training
作者通过将预测的边界框与真实值进行比较来训练可适应的运动预测器。作者提取整个跟踪视频中的所有轨迹,并将它们分割成长度为
的边界框序列。每个轨迹段的首个边界框序列被用作历史轨迹,在帧
中估计
,而该段中的最后一个边界框
被视为真实值。作者采用L1损失函数作为预测损失,以增强对异常值的鲁棒性,例如目标检测和跟踪预测中的错误。
具体而言,将边界框
的估计属性(
)与真实值
的相应属性进行L1损失比较,并计算总预测损失
为平均值:
Masked Tokens.
作者采用Mask标记作为增强策略,以模拟非线性运动和遮挡的影响。作者以概率
在历史轨迹中Mask边界框。然后,用Mask标记替换Mask的边界框,以防止它们的空间信息的编码。这些Mask标记被表示为可学习的嵌入,它们以随机值初始化,并在训练期间优化。通过这种方式,作者增强作者的模型,以获得对缺失轨迹段的清晰理解。作者的Mask标记增强策略可以通过确保复杂的场景下的训练的鲁棒性,有效地执行Mask操作。
此外,作者在推理过程中利用Mask标记来处理历史轨迹嵌入的填充。作者用Mask标记填充历史轨迹嵌入,以保持新生物体(具有过去边界框数量少于
的目标)的恒定长度。
Experiments
Dataset and Evaluation Metric
作者在DanceTrack、MOT17和MOT20上提供了实验结果。DanceTrack主要包含具有相似外观的目标的舞蹈视频。DanceTrack提供了具有非线性目标运动和遮挡的场景,因此对于基于运动跟踪的方法提出了重大的挑战。MOT17和MOT20包含在公共空间中的行人跟踪视频,其中目标运动由慢而平的运动表示,近似为线性。然而,这些数据集仍然具有挑战性,因为场景非常拥挤,物体人口密集。
作者使用了包括HOTA(高阶跟踪精度)、AssA(关联精度)、DetA(检测精度)、IDF1和MOTA(多目标跟踪精度)在内的评估指标。HOTA提供了对检测和关联精度平衡评估,而与MOTA或DetA相比,它更倾向于测量检测。IDF1和AssA用于展示关联性能。
Implementation Details
作者在相应的跟踪数据集上训练作者的可适应运动预测器,而不包括其他数据集的额外样本。为了确保公平的比较,作者使用ByteTrack开发的公开可访问的YOLOX检测器权重,遵循 Baseline ,对目标检测进行训练。 Transformer 编码器包括6层,其中多头自注意力使用8个头。嵌入维度
设置为512。
作者使用Adam优化网络,学习率为0.0001,进行50个周期,并将批量大小设置为512。历史轨迹嵌入长度
预定义为30。Mask概率
选择为0.1。关于
和
选择的分析可以在第4.5节中找到。所有实验均在单个NVIDIA TITAN XP上进行。
Benchmark Results
表1展示了在DanceTrack测试集上的基准结果。AM-SORT在基于外观的跟踪器和混合跟踪器上达到了竞争性性能,并在基于运动的MOT方法中取得了最先进的结果。它获得了56.3的IDF1和55.6的HOTA,超过了 Baseline 。值得注意的是,IDF1上的显著增益为1.7,它衡量了关联性能和再识别精度。
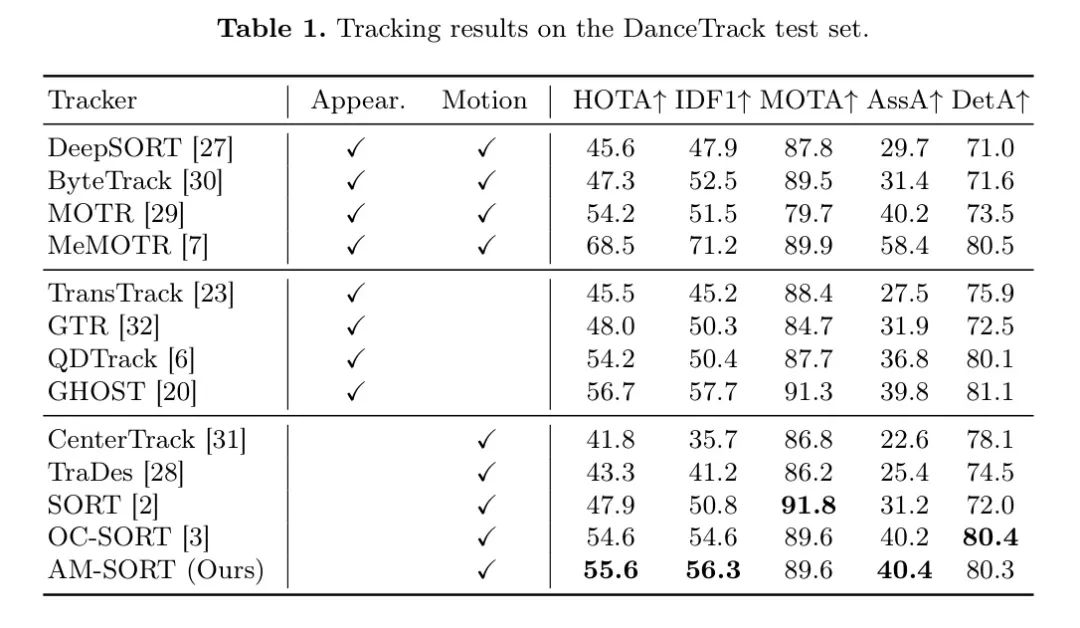
表2展示了在MOT17和MOT20测试集上的跟踪性能,以验证其覆盖线性物体运动的泛化能力。AM-SORT与最先进的MOT方法相比取得了更高的结果。如前所述,MOT17和MOT20旨在跟踪行人,其中运动模式通常为线性,不包含非线性场景。尽管条件不同,但AM-SORT仍表现出一致的改进,尽管它并未解决主要问题。
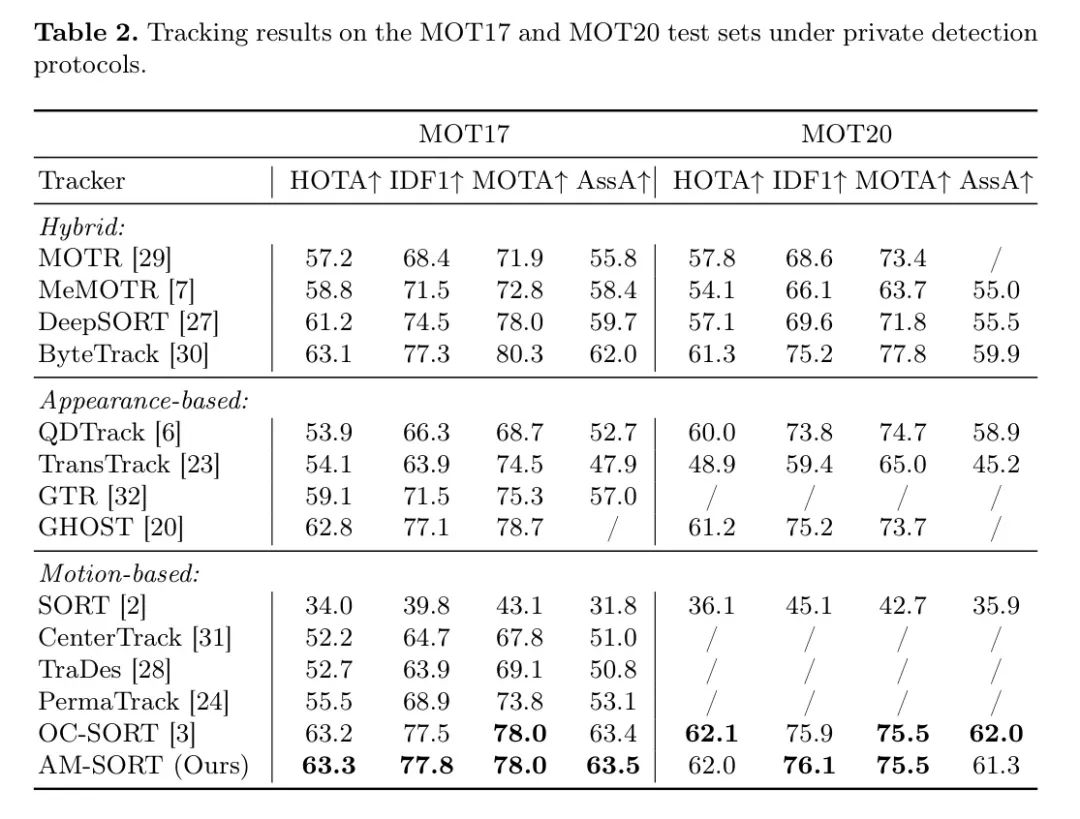
Qualitative Results
图5显示了OC-SORT和AM-SORT的定性比较。这些示例说明了OC-SORT中黄色标记物体的身份切换。在图5的行1中,由于卡尔曼滤波器固有的线性假设,OC-SORT在中间帧中估计了标记物体的细长边界框。它无法预测宽大边界框的突然变化,导致错误匹配。同样,线性假设阻止了在遮挡后捕捉到向右的方向变化,如图5的行2所示。
相比之下,AM-SORT在非线性物体运动和遮挡下能够保持一致的身份。
Ablation Study
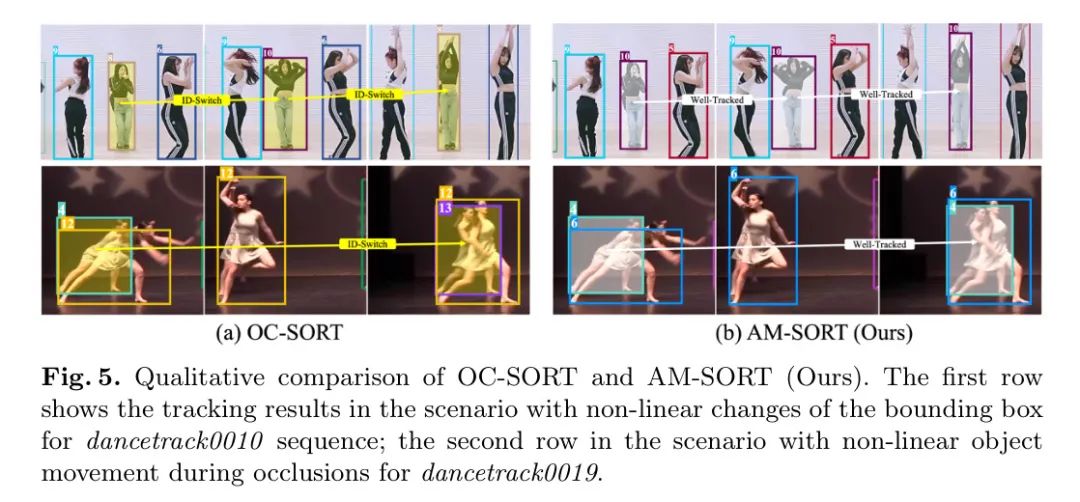
匈牙利匹配算法中的关联成本。在推理阶段,SORT系列跟踪器使用匈牙利匹配算法进行目标关联。为了展示在匈牙利匹配步骤中关联成本的影响,作者在不同的关联成本组合(包括IoU,运动方向差异
和L1距离)下比较OC-SORT和AM-SORT。运动方向差异计算现有轨迹和新观测之间的方向相似度。仅使用IoU的AM-SORT(如表3行1所示)优于仅使用IoU的OC-SORT(如表3行1所示)3.2 IDF1,并相对于OC-SORT的最佳设置(如表3行2所示)增加了0.2 IDF1。
另一方面,运动方向差异降低了作者模型的跟踪性能。原因在于,OC-SORT中包含的运动方向线索用于补偿非线性场景中近似估计的边界框,在AM-SORT中并不适用。作者的可适应运动预测器在预测步骤中已经捕获了非线性方向性的变化,使得基于位置的匹配足够。此外,将位置关联成本(如表3行3所示)、IoU和L1距离结合,相对于OC-SORT的最佳设置,作者的模型获得了额外的2.5 IDF1。
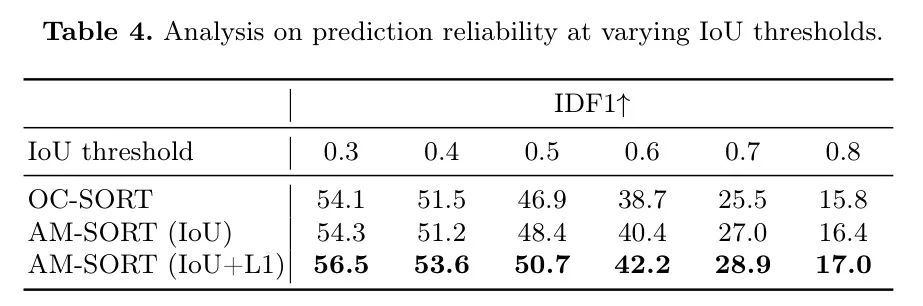
边界框预测的可靠性。为了验证边界框预测的可靠性,作者在逐步增加的IoU阈值下评估OC-SORT和AM-SORT。更高的IoU阈值需要更大的重叠来将检测与预测关联。
表4表明,仅使用IoU的AM-SORT在IoU阈值大于0.4时优于使用最佳IoU设置的OC-SORT,而使用最佳设置的AM-SORT在所有IoU阈值下都表现出优越的性能。更高的IDF1表明,AM-SORT与 GT 具有更多正匹配的轨迹。这表明作者的可适应运动预测器更准确地捕获了物体区域,作为边界框预测更高可靠性的有力证据。
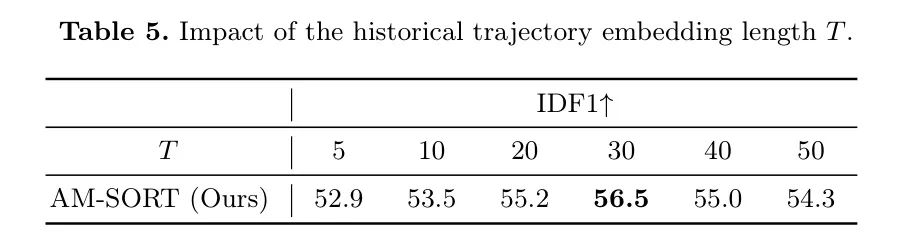
历史轨迹嵌入长度的影响。为了证明跟踪性能如何随历史轨迹嵌入长度变化,作者在不同的
值下评估AM-SORT。表5表明,随着历史轨迹的增加,性能增加,而当
大于30时,性能下降。
作者得出结论,更长的历史轨迹可以提供更全面的空间-时间信息,直到
,而过于老化的历史轨迹框可以提供噪声,从而对整体跟踪性能产生负面影响。因此,作者设置
,该值覆盖了20 FPS视频中1.5秒的物体轨迹。
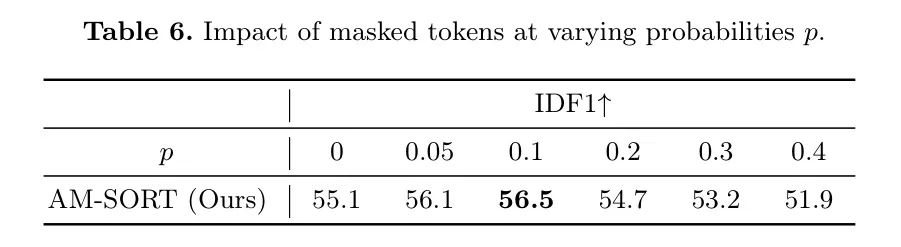
Mask标记的影响。为了证明在训练中利用Mask标记的有效性,作者提供了从
为0到0.4的Mask标记概率的跟踪结果。表6表明,与在
时无Mask标记的训练相比,使用
的Mask标记概率的Mask标记导致IDF1增加了1.4。相反,当
时,性能略有下降。作者建议,使用适中的Mask标记
可以提供对遮挡的强健训练。
5 Conclusion
在本文中,作者提出了一种基于运动的可适应运动预测器AM-SORT,用于有效解决非线性运动和遮挡问题。作者引入历史轨迹编码,用于在边界框序列中编码时空信息,以实现对物体运动轨迹的全面表示。
作者利用 Transformer 在物体轨迹中建模长程依赖性的能力,使作者的运动预测器能够适应复杂运动模式。因此,AM-SORT在与其他最先进方法竞争的同时,也超过了现有的基于运动的方法。
参考
[1].AM-SORT: Adaptable Motion Predictor with Historical Trajectory Embedding for Multi-Object Tracking.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号