"技术扶贫"大佬 Anthony Fu 最新文章


技术扶贫源自:
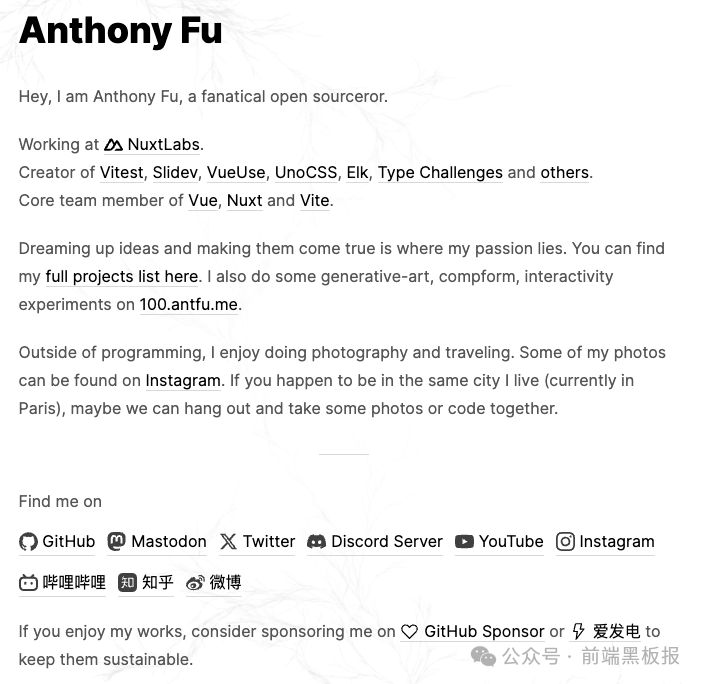
Anthony Fu 确实厉害,下面是他的自我介绍:
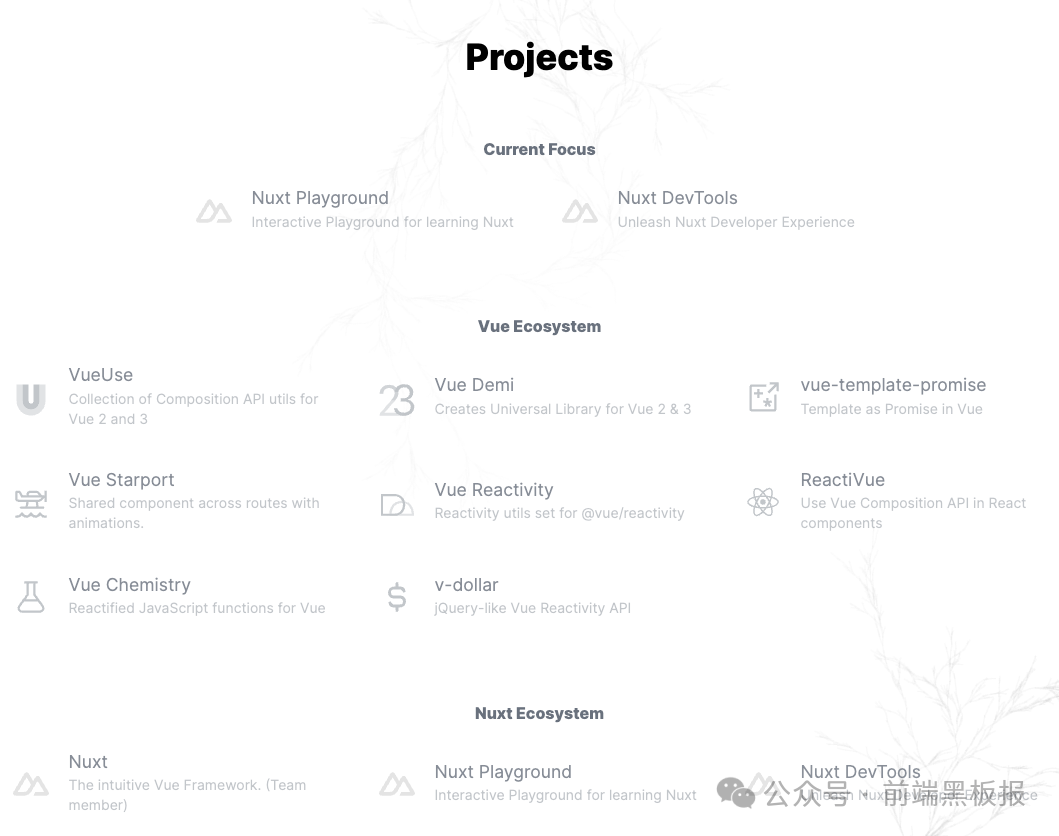
是一位名副其实的狂热开发者,为社区做了很多贡献。看了一下他的 projects (有些是自己的,有些是参与的。),多到恐怖(截取一部分):
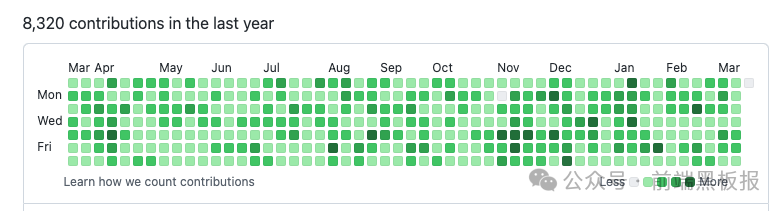
下面是他的 github 提交记录:
最近他写了一篇文章,估计是感觉自己遇到瓶颈了:
这次的情况有点不同,这并不是我没有动力,而是我有太多想做的事情,但我的能力有限。
下面是全文机翻(推荐读原文:https://antfu.me/posts/mental-health-oss):
简而言之:我很好,哪儿也不去。有压力,但仍在努力提高。谢谢你,别担心!
这是我开始做开源的第四年,坦白地说,我开始越来越频繁地感到事情超出了我的能力范围,我仍然不确定我是否经历过真正的倦怠,但我确实经历过我的生产力和动力周期性的起伏。
这篇文章不是指南,甚至不是抱怨,更像是我的个人日记,我只是把它当作我自己的记录,我只是觉得如果我能和你分享这些,可能会很有趣。
如果你已经经历过倦怠或感觉接近倦怠,我建议你休息一下,和别人谈谈,如果需要的话寻求专业帮助。这里还有一篇不错的文章《维护开源维护者的平衡》,你可以参考。
所以,让我告诉你们一些我最近一直在思考的东西
毫无准备的
在某种程度上,开源对我来说仍然非常新,即使是今天。
自从我开始学习编程并了解开源以来,我一直梦想成为一名全职开源开发者。当我在大学时,我渴望得到开源社区的认可,努力“找出”一些我可以完成的有影响力的工作。突然之间,你会到达一个关键点,你的项目可能会出乎意料地起飞,或者你被邀请加入一个大项目——在某个时刻,你会开始感到所有这些兴奋,以及突然而来的责任。几天后,当最初的兴奋开始消退时,你开始意识到它也意味着这么多的责任和其他你从未想过的事情。尽管我在大学期间一直努力进入开源,但当我最终踏入它时,我意识到我是多么的没有准备。
开源的一个有趣之处在于,你可能从来没有准备好。你可能会遇到棘手的技术问题,或者必须跟上新技术,但还有一堆除了编码之外的事情你必须处理。你必须成为你的客户支持,回答问题;成为一个设计师,一个作家准备好的文档;一个项目经理保持项目在轨道上;一个团队领导者招募新的贡献者并保持团队的积极性;营销你的产品;在会议上发言;等等......。这些都是作为一个开源开发者的“副作用”,许多东西都是捆绑在一起的,不仅仅是代码。
对我来说,这是一个很大的挑战。我很内向,我不擅长聊天或交谈。我在学校的英语考试成绩很糟糕,而且在英语口语方面一点也不自信。即使只是在同学面前,我也会怯场。我想我也不喜欢团队管理,尽管我从未领导过一个团队——有这么多事情要害怕。
它不会给你时间准备好(或者另一方面,如果不迈出第一步,你可能永远不会准备好),随着项目的增长,随着你责任的增加,你将被迫学习和适应。当它自然地成长为一个团队时,你必须学会沟通,学会领导。当有人邀请你做播客或演讲时,他们不会等你3年练习语言或演讲技巧——你要么错过机会,要么战胜自己的恐惧并去做。因为我如此热爱开源,我必须征服他们和自己。
可能看起来有些难以承受。但如果你接受这些挑战,并一个一个地克服它们,渐渐地,你可能会发现它们很有趣,也很有益。最后,我很感激所有这些机会,它们把我推出我的舒适区,迫使我提高。在开源的这四年里,尽管在许多事情上我仍然不完美,但我的英语讲得更加自信了。我在许多会议上发表演讲,其中一些甚至有数千名与会者。在每次演讲前我仍然会超级紧张,但至少我不再害怕演讲了。
还有很多挑战和惊喜等着我,我既害怕又兴奋地想知道接下来会发生什么。
“预期”
人类适应,这驱使我们生存和不断进步,但也使我们很难保持满意。
当我开始我的第一个开源项目时,我非常兴奋。我会不断刷新页面,急切地等待新的议题、新的请求和新的评论出现。每一个星星都会让我感到高兴,我会尽可能地帮助每一个问题。我设定了里程碑,比如100颗星星、500颗星星,并在达到它们时庆祝。我仍然记得当我告诉我的朋友我的项目上有几百颗星星,我正在对世界产生一些影响时我是多么自豪。
一旦你达到这些目标,事情开始变得“平常”。然后你就会开始期待更多,设定更高的目标。在某种程度上,我开始不再关心那些星星或下载量的数字。这并不一定是件坏事,因为它们不是我应该关注的参数,但有时我怀念过去的日子,那时我可以从那些简单的事情中获得快乐。
后来我发现,人生中的很多经历都与我们的期望值有直接关系。刚开始的时候,我们期望值很低,而且相对容易实现。随着我们不断前进,站到更高的位置,我们开始期望更多,而且不是线性增长的。当你有1000颗星星的时候,再多得到100颗听起来并不像你一无所有的时候那么令人印象深刻。当你有1000颗星星的时候,你会寻找另外1000颗,而只有100颗已经不能满足你了。这对我来说很奇怪,我不喜欢自己的这种“人性”。
我发现降低期望值并对自己所拥有的一切心存感激是保持快乐的好方法。当你开始意识到你不能一直达到自己的里程碑时,最好的方法就是停止追求更高的目标,休息一下,欣赏周围的风景——也许你已经达到足够高的高度了。自从我开始“不过于在意得失”,我发现自己更乐于尝试不同的想法,即使它们可能不会成功——因为我对它们没有很高的期望,对我来说没有“失败”的概念。如果其中一些后来被证明是好主意,那将是一个不错的“意外惊喜”。
如果你感兴趣,我解释了关于牦牛剃毛的帖子中关于我的想法发现过程。
“自我期望”
期望不仅适用于我们正在做的事情,也适用于我自己。当我太过关心一个项目时,我经常发现我对自己作为一个友好的维护者的角色期望过高。当我看到人们批评我的项目时,当某个bug给人们带来麻烦时,或者当我没有及时回复问题时,我会感觉很糟糕。这种感觉在流行的项目中变得更加强烈,因为你知道有很多人依赖它。这些自我期望让我承受了相当大的压力。
正如我在另一篇文章中提到的,开源项目中维护者和用户的比例往往是不平衡的,很难找到一个新的合作者或团队成员,但由于开源本身就是免费的,所以基本上没有增长更多用户的门槛。
我认为对于维护者来说,很难转变思维,认为他们没有义务为别人解决问题,因为开源软件通常是按原样提供的。特别是对于关心用户和社区的维护者来说,当我们收到新的问题时,很难忽视。但从另一个角度来看,一个人的时间和精力是有限的。当工作量超出一个人的能力时,最好设置优先级,专注于最重要的事情。
我希望在我开始维护高流量的开源项目时有人能告诉我这一点(你在网上有这样的好资源)——我花了很长时间才意识到我不需要完美,按照自己的节奏做事是可以的。与其被动地接收通知,我最好关闭推送通知,并在我准备好的时候主动检查问题和拉取请求。
如果你对这个方法感兴趣,我曾经谈过我如何管理 GitHub 通知。
降低对自己的期望——没有人是完美的,也没有人是机器。不要让它们成为你的负担。更重要的是保持健康和可持续的步伐,保持自己的快乐和动力,从长远来看会有更积极的影响。
当你的梦想成为你的工作
生活在自己的梦想中是一件很棒的事情,老实说,这是一种特权。但同时,老实说,拥有一个梦想和生活在梦想中是完全不同的。梦想总是理想化的,排除了所有无聊的细节。我的梦想是成为一名全职开源开发人员。是的,这听起来很棒,可以独立,做你喜欢的事情,有一个灵活的或根本没有时间表,在任何地方工作,造福世界等等。但在现实中,事情并不是那么简单。
这和“把爱好当成工作”很相似,它确实有很多好处,比如你会更快乐、更有效率,但它也带来了义务和责任。当爱好变成工作时,你失去了选择何时做什么的自由。以前,你会把业余爱好作为工作后的放松,但现在当你想用业余爱好放松时,它们变成了工作。
我很幸运,软件开发是一个大领域,有很多不同的事情可以做。除了“主要”的开源项目维护,我有时会做一些小项目(生成艺术、稳定扩散、一些小实验等),以提神醒脑(作为主要项目的一种“放松”)。我也喜欢玩独立游戏,虽然我一直在考虑认真开发一些游戏——但那是另一个故事了——至少现在我仍然有一些方法来逃避,当我真的想远离代码时。
我可能太喜欢编程了,所以我对这个没有强烈的感受。在我看来,“工作”和“娱乐”之间的界限相当模糊。有时候,一个有趣的项目可以成为人们依赖的严肃的东西。
速度、范围和质量
这实际上是驱使我写这篇博客的主题。
让我们从速度、范围和质量的“铁三角”开始。
速度-范围-质量的铁三角:
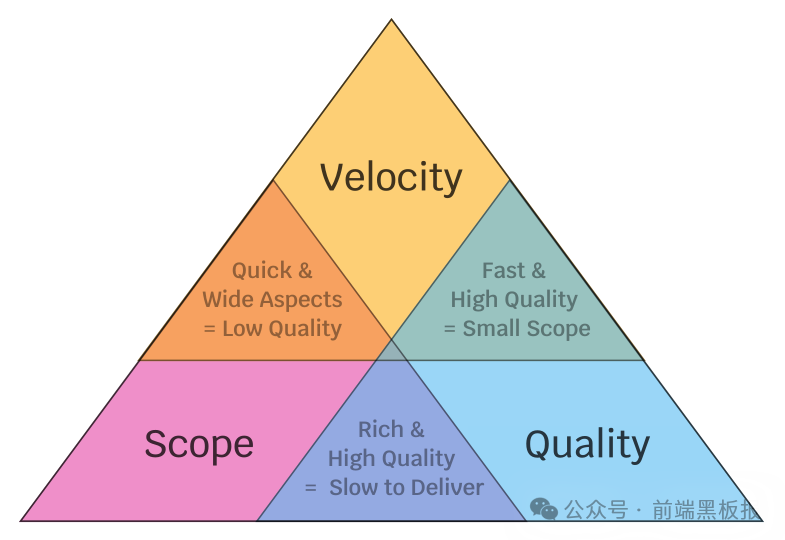
通常,人们会说,在这三个因素中,你只能选择两个。如果你想更快地交付一个项目,你可能必须牺牲质量或有一个更小的特性范围。如果你想有一个高质量和功能丰富的产品,你可能必须牺牲速度来慢慢地交付好东西,等等。
对我个人来说,拥有高质量的开源软件是一个不可改变的标准,我永远不会妥协。
同时,保持一定的速度和势头对我来说也很重要。我的大部分动力都是由我完成某件事后的成就感驱动的。当我能够创建迭代然后交付的反馈循环时,我可能会处于一个很好的流状态。
所以,我通常会选择质量和速度。在一开始,我的项目范围很明确,也很小。我设法保持高质量,快速交付,并迅速得到社区的反馈。当时,我能够保持高效率和动力,继续在这些项目上工作。
范围
我“偶然”能够在相当长的时间内保持这种势头和速度。我开始与i18n Ally和VueUse一起进入开源领域,从那时起我加入了Vue和Vite团队,然后仅在2021年,我就提出了Slidev(2021年4月)、UnoCSS(2021年10月)和Vitest(2021年12月)——一切都进展得太顺利了,以至于我几乎没有意识到拥有更大范围的能力是有一定限制的。从那以后,我一直以这种“速度”无知地继续做这件事。我非常幸运地遇到了令人惊叹的团队和社区,并从他们那里得到了帮助:
- • 非常棒的Nuxt团队,支持无止境
- • sheremet-va AriPerkkio和Vitest团队照顾Vitest
- • chu121su12 zyyv 和 UnoCSS 团队对 UnoCSS 进行了大量优化
- • Alfred-Skyblue Tahul 和VueUse团队为VueUse
- • sxzz 管理 Unplugin
- • KermanX tonai 在 Slidev 上推出了许多功能
- • arashsheyda 在 Nuxt DevTools 上提供了许多帮助
- • shuuji3 Shinigami92为Elk做出的贡献
- • patak-dev sapphi-red bluwy 继续推动Vite与出色的社区前进
- • userquin 用于维护 Vite PWA 并帮助几乎所有地方的一切
- • yyx990803,我从他那里学到了很多关于OSS和决策制定的知识。
- • 还有许多为开源做出贡献或通过赞助提供财务支持的人!
很遗憾我不能把它们全部列出来,而且其中许多实际上是跨项目的重叠。我想说的是,我不是独自工作,我不能独自做所有这些。我从社区和团队那里得到了很多帮助,才有了所有这些项目。我真的很感激。在质量和速度之上,似乎我还在广泛的项目上工作——看起来好像打破了铁三角规则——但实际上,幕后的优秀社区是使其成为可能的“魔法”。
能力
维护多个高流量开源项目的工作量是巨大的。如果没有社区的帮助,我早就达到了我的极限。虽然社区帮了我很多,但它仍然需要大量的精力来沟通、协调,以及持续的上下文切换。随着时间的推移,我积累了很多我必须自己做的事情,很多我想尝试的想法,以及很多我想改进的事情。
我想让这些项目继续下去,继续前进;我想写更多的博客文章来分享我的想法;我想做更多的演讲,去旅行和见面;我想做更多的直播,因为我知道很多人都在等待;我必须清理这件事,去做那个发布;我还想学法语;花更多的时间和我的家人在一起——我的意思是,这可能只是生活。人们有自己的担忧和责任,我并不比别人更特别或更忙。
"但不知何故,似乎有某种东西,
我可能不愿意承认我可能的倦怠。不是因为我害怕它,而是因为我不想放弃和被动地处理它。我知道当我需要休息时,我需要休息,但称自己“倦怠”和放弃是一种逃避责任的“捷径”。我想找出“根本原因”,并试图改善情况,而不是仅仅“解决”它。正如我们之前所谈到的,“期望”的转变,以及对我的“准备不足”和“自我期望”的重新评估,是我解决因为不同原因而接近倦怠的时刻的办法。通过调整自己和采取措施,我通常能够在大约一周内从低点恢复过来,并继续前进。
这次的情况有点不同,这并不是我没有动力,而是我有太多想做的事情,但我的能力有限。我开始思考,也许是因为我期望自己保持相同的速度来完成所有事情,我担心自己做得不够多,做得不够快。获得快速的反馈是令人敬畏的,而且相当有效率,但我可能变得有些不耐烦,因为我太习惯于快速了。结合起来,它们使我在做一些需要中长期努力的事情时很容易感到沮丧。
例如,写作。我不擅长写作,而且我真的不喜欢写作。文档、博客文章、教程和演讲——都需要大量的时间,而且,我必须做的事情。当我在写作或中途放弃时,我很容易分心和失去注意力。所以我在Twitter上问了这个问题,并从社区中得到了很多很好的建议(查看评论,你可能会发现一些对你有用的东西)。我开始试着放松下来,慢慢地做,试着改变我的思想,不要期待立即的结果,而是享受这个过程。你正在阅读的这个博客花了我大约一周的时间来写(这对我来说是相当长的一段时间),分成多个部分。我感觉这也帮助我重新思考和重组我的想法和感受,实际上,把它们写下来让我对我的焦虑感觉好多了。
所以,我或许应该重新评估一下自己的能力和期望,我必须理解和接受我不能一直保持同样的速度,我不必太过于强迫自己,慢一点,多关注细节,也许我会在过程中找到不一样的快乐和满足。
坦白地说,我甚至不确定我在这篇博客中想要表达什么——也许只是简单地与你分享我的想法和感受。现在,我仍然感到相当大的压力。我仍然在适应,并试图找到一个更好的方法来处理它。在这一周的写作和与朋友交谈中,我感觉好多了,我相信我会度过这一切。这可能就像我们生活中的许多其他事情一样;我们并不总是有完美的解决方案,但我们必须继续前进,找到我们的出路。
保持良好的心理健康是每个开源维护者保持可持续性的重要任务之一,我认为在整个旅程中不会有“答案”或“解决方案”来应对高低起伏,这更像是一个不断学习和适应的过程,以找到适合我们每个人的方法。
我希望收到你的来信
感谢你一直读到最后,看完我这篇乱七八糟又冗长的想法!
我知道我的观点一定很偏颇。如果它曾经触发了你任何的想法或感觉,我很好奇想听听你的想法或你的方法。你可以在这条推文或mastodon下留下一些评论,或者如果你喜欢私人对话,可以发邮件到hi@antfu.me[1]。期待你的回复!
谢谢
最后,我要感谢我的女朋友Ines,她从一开始就一直支持我,帮助我度过那些艰难的时刻,没有她的大力支持,我可能就不会走到今天。
此外,感谢patak-dev和posva围绕这个主题进行的深入对话,他们真的帮了我很多,并提供了巨大的支持。
还有你!还有伟大的开源社区!我非常感激我从你们那里得到的所有帮助和支持。
下次见,保重!
(侵删,文章权利归原作者所有。)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号