DIY 3 种分库分表分片算法,自己写的轮子才吊!
原创

大家好,我是小富~
前言
本文是《ShardingSphere5.x分库分表原理与实战》系列的第六篇,书接上文实现三种自定义分片算法。通过自定义算法,可以根据特定业务需求定制分片策略,以满足不同场景下的性能、扩展性或数据处理需求。同时,可以优化分片算法以提升系统性能,规避数据倾斜等问题。
在这里,自定义分片算法的类型(Type)统一为CLASS_BASED,包含两个属性:strategy 表示分片策略类型,目前支持三种:STANDARD、COMPLEX、HINT;algorithmClassName 表示自定义分片算法的实现类路径。此外,还可以向算法类内传入自定义属性。
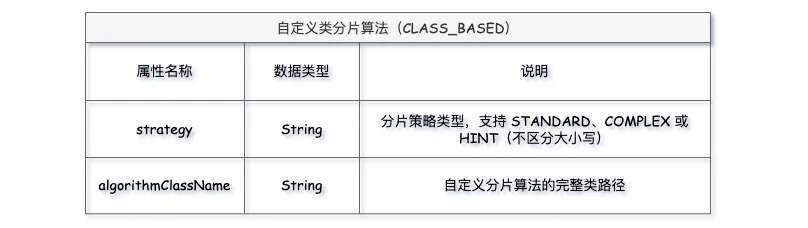
自定义 STANDARD 算法
要实现自定义 STANDARD 标准算法,需要实现StandardShardingAlgorithm<T>接口( T 代表接收的分片健值类型),并重写接口中的四个方法。其中,有两个 doSharding() 方法为处理分片的核心逻辑;getProps() 方法用于获取分片算法的配置信息;init() 方法则用于初始化分片算法的配置信息,支持动态修改。
5.X 以后的版本,实现自定义标准算法的精准分片和范围分片,不在需要实现多个接口。只用实现 StandardShardingAlgorithm 标准算法接口,重写两个 doSharding() 方法。 doSharding(availableTargetNames,rangeShardingValue) 处理含有 >、<、between and 等操作符的 SQL,doSharding(availableTargetNames,preciseShardingValue) 处理含有 = 、in 等操作符的 SQL。
精准分片
精准分片用于SQL中包含 in、= 等操作符的场景,支持单一分片健。
重写方法 doSharding(Collection availableTargetNames, PreciseShardingValue preciseShardingValue),该方法返回单一的分片数据源或分片表数据。有两个参数:一个是可用目标分库、分表的集合,另一个是精准分片属性对象。

PreciseShardingValue 对象属性数据格式如下:
{
"columnName": "order_id", // 分片健
"dataNodeInfo": {
"paddingChar": "0",
"prefix": "db", // 数据节点信息前缀,例如:分库时为db,分表时为分片表t_order_
"suffixMinLength": 1
},
"logicTableName": "t_order", // 逻辑表
"value": 1 // 分片健值
}范围分片
范围分片用于 SQL中包含 >、< 等范围操作符的场景,支持单一分片健。
重写方法 doSharding(Collection availableTargetNames, RangeShardingValue rangeShardingValue),该方法可以返回多个分片数据源或分片表数据。有两个参数:一个是可用目标分库、分表的集合,另一个是精准分片属性对象。

RangeShardingValue 对象属性数据格式如下:
{
"columnName": "order_id", // 分片健
"dataNodeInfo": {
"paddingChar": "0",
"prefix": "db", // 数据节点前缀,分库时为数据源,分表时为分片表t_order_
"suffixMinLength": 1
},
"logicTableName": "t_order", // 逻辑表
"valueRange": [0,∞] // 分片健值的范围数据
}精准分片算法的 doSharding() 执行流程:从PreciseShardingValue.getValue()中获取分片键值,然后经过计算得出相应编号,最终在availableTargetNames可用目标分库、分片表集合中选择以一个符合的返回。
范围分片算法的 doSharding() 执行流程:从RangeShardingValue.getValueRange()方法获取分片键的数值范围,然后经过计算得出相应编号,最终在availableTargetNames可用目标分库、分片表集合中选择多个符合的返回。
下面是具体实现分片的逻辑:
/**
* 自定义标准分片算法
*
* @author 公众号:程序员小富
* @date 2024/03/22 11:02
*/
@Slf4j
public class OrderStandardCustomAlgorithm implements StandardShardingAlgorithm<Long> {
/**
* 精准分片进入 sql中有 = 和 in 等操作符会执行
*
* @param availableTargetNames 所有分片表的集合
* @param shardingValue 分片健的值,SQL中解析出来的分片值
*/
@Override
public String doSharding(Collection<String> availableTargetNames,
PreciseShardingValue<Long> shardingValue) {
/**
* 分库策略使用时:availableTargetNames 参数数据为分片库的集合 ["db0","db1"]
* 分表策略使用时:availableTargetNames 参数数据为分片库的集合 ["t_order_0","t_order_1","t_order_2"]
*/
log.info("进入精准分片 precise availableTargetNames:{}", JSON.toJSONString(availableTargetNames));
/**
* 分库策略使用时: shardingValue 参数数据:{"columnName":"order_id","dataNodeInfo":{"paddingChar":"0","prefix":"db","suffixMinLength":1},"logicTableName":"t_order","value":1}
* 分表策略使用时: shardingValue 参数数据:{"columnName":"order_id","dataNodeInfo":{"paddingChar":"0","prefix":"t_order_","suffixMinLength":1},"logicTableName":"t_order","value":1}
*/
log.info("进入精准分片 preciseShardingValue:{}", JSON.toJSONString(shardingValue));
int tableSize = availableTargetNames.size();
// 真实表的前缀
String tablePrefix = shardingValue.getDataNodeInfo().getPrefix();
// 分片健的值
long orderId = shardingValue.getValue();
// 对分片健取模后确定位置
long mod = orderId % tableSize;
return tablePrefix + mod;
}
/**
* 范围分片进入 sql中有 between 和 < > 等操作符会执行
*
* @param availableTargetNames 所有分片表的集合
* @param shardingValue 分片健的值,SQL中解析出来的分片值
* @return
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames,
RangeShardingValue<Long> shardingValue) {
/**
* 分库策略使用时:availableTargetNames 参数数据为分片库的集合 ["db0","db1"]
* 分表策略使用时:availableTargetNames 参数数据为分片库的集合 ["t_order_0","t_order_1","t_order_2"]
*/
log.info("进入范围分片:range availableTargetNames:{}", JSON.toJSONString(availableTargetNames));
/**
* 分库策略使用时 shardingValue 参数数据:{"columnName":"order_id","dataNodeInfo":{"paddingChar":"0","prefix":"db","suffixMinLength":1},"logicTableName":"t_order","valueRange":{"empty":false}}
* 分表策略使用时 shardingValue 参数数据:{"columnName":"order_id","dataNodeInfo":{"paddingChar":"0","prefix":"t_order_","suffixMinLength":1},"logicTableName":"t_order","valueRange":{"empty":false}}
*/
log.info("进入范围分片:rangeShardingValue:{}", JSON.toJSONString(shardingValue));
// 分片健值的下边界
Range<Long> valueRange = shardingValue.getValueRange();
Long lower = valueRange.lowerEndpoint();
// 分片健值的上边界
Long upper = valueRange.upperEndpoint();
// 真实表的前缀
String tablePrefix = shardingValue.getDataNodeInfo().getPrefix();
if (lower != null && upper != null) {
// 分片健的值
long orderId = upper - lower;
// 对分片健取模后确定位置
long mod = orderId % availableTargetNames.size();
return Arrays.asList(tablePrefix + mod);
}
//
return Collections.singletonList("t_order_0");
}
@Override
public Properties getProps() {
return null;
}
/**
* 初始化配置
*
* @param properties
*/
@Override
public void init(Properties properties) {
Object prop = properties.get("prop");
log.info("配置信息:{}", JSON.toJSONString(prop));
}
}配置算法
在实现了自定义分片算法的两个 doSharding() 核心逻辑之后,接着配置并使用定义的算法。配置属性包括strategy分片策略类型设置成standard,algorithmClassName自定义标准算法的实现类全路径。需要注意的是:策略和算法类型必须保持一致,否则会导致错误。
spring:
shardingsphere:
rules:
sharding:
# 分片算法定义
sharding-algorithms:
t_order_database_mod:
type: MOD
props:
sharding-count: 2 # 指定分片数量
# 12、自定义 STANDARD 标准算法
t_order_standard_custom_algorithm:
type: CLASS_BASED
props:
# 分片策略
strategy: standard
# 分片算法类
algorithmClassName: com.shardingsphere_101.algorithm.OrderStandardCustomAlgorithm
# 自定义属性
prop:
aaaaaa: 123456
bbbbbb: 654321
tables:
# 逻辑表名称
t_order:
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: t_order_database_mod
# 分表策略
table-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: t_order_standard_custom_algorithm测试算法
在插入测试数据时,默认会自动进入精确分片的 doSharding() 方法内,看到该方法会获取分片键的数值,根据我们的计算规则确定返回一个目标分片表用于路由。
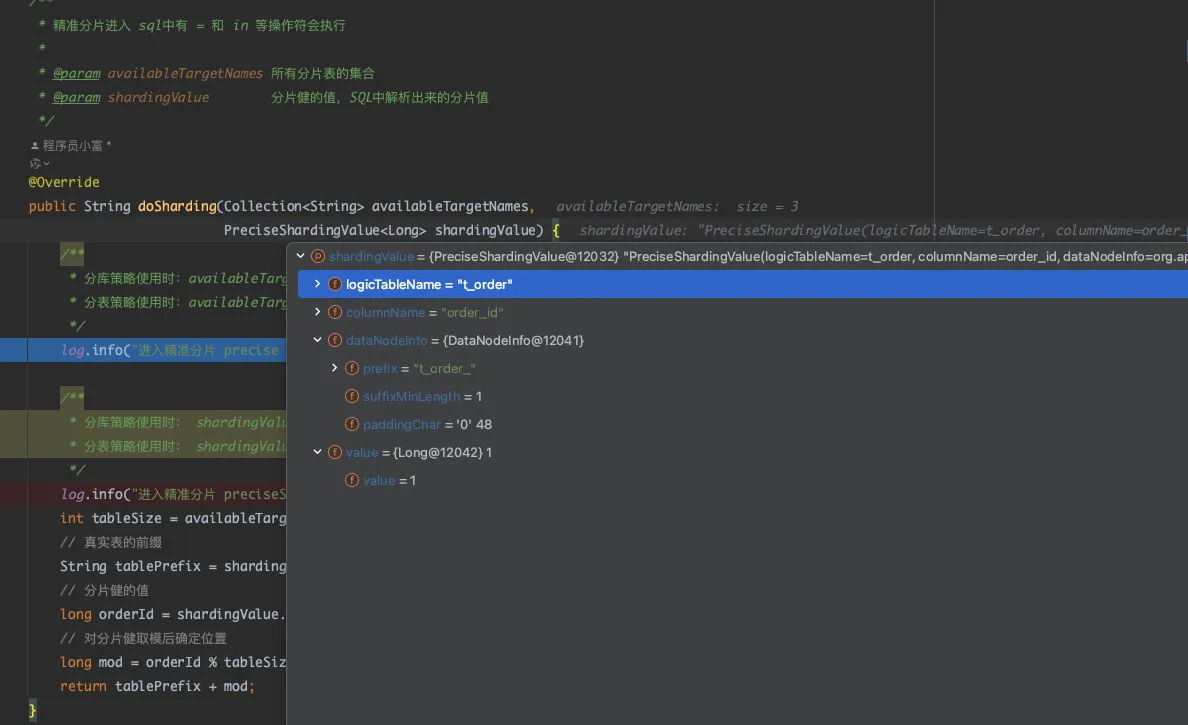
接着执行一个范围查询的 SQL,此时将进入范围分片的 doSharding() 方法。通过观察 shardingValue.getValueRange() 方法中分片键的数值范围,可以发现这些数值范围是从SQL查询中解析得到的。
select * from t_order where order_id > 1 and order_id < 10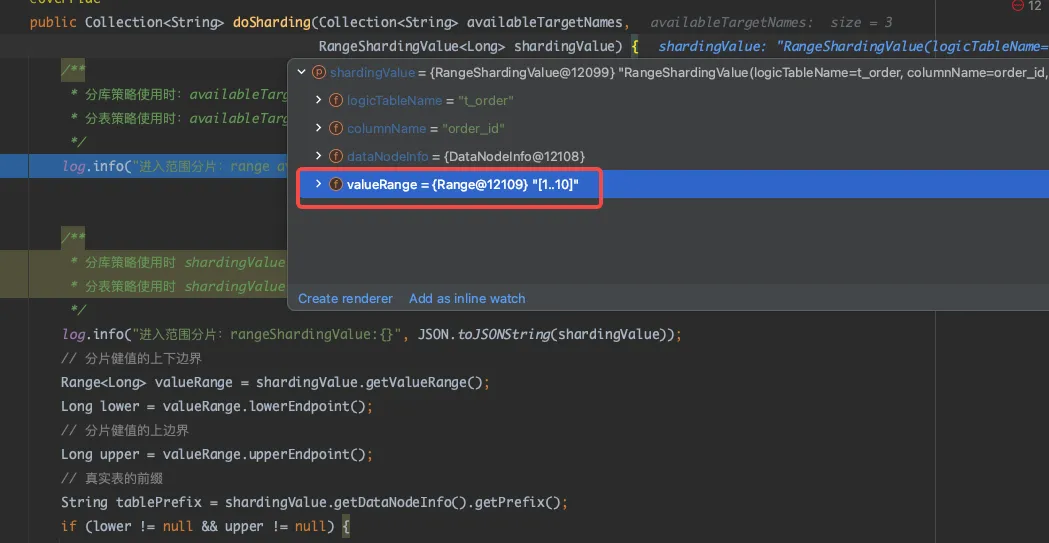
自定义 COMPLEX 算法
复合分片算法支持包含 >,>=, <=,<,=,IN 和 BETWEEN AND 等操作符的SQL,支持多分片健。
自定义COMPLEX复合分片算法,需要我们实现 ComplexKeysShardingAlgorithm<T> 接口(其中 T 代表接收的分片键值类型),并重写该接口内部的 3 个方法。其中,主要关注用于处理核心分片逻辑的 doSharding()方法,可以返回多个分片数据源或分片表数据;其他两个配置方法与上述类似,这里不再赘述。
重写复合分片方法 doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValues) 实现定制的多分片健逻辑,该方法有两个参数:一个是可用目标分库、分表的集合;另一个是多分片健属性对象。

logicTableName为逻辑表名,columnNameAndShardingValuesMap用于存储多个分片键和对应的键值,columnNameAndRangeValuesMap用于存储多个分片键和对应的键值范围。
ComplexKeysShardingValue数据结构如下:
public final class ComplexKeysShardingValue<T extends Comparable<?>> implements ShardingValue {
// 逻辑表
private final String logicTableName;
// 多分片健及其数值
private final Map<String, Collection<T>> columnNameAndShardingValuesMap;
// 多分片健及其范围数值
private final Map<String, Range<T>> columnNameAndRangeValuesMap;
}核心流程:通过循环 Map 得到多个分片健值进行计算,从 availableTargetNames 可用目标分库、分片表集合中选择多个符合条件的返回。
/**
* 自定义复合分片算法
*
* @author 公众号:程序员小富
* @date 2024/03/22 11:02
*/
@Slf4j
public class OrderComplexCustomAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
/**
* 复合分片算法进入,支持>,>=, <=,<,=,IN 和 BETWEEN AND 等操作符
*
* @param availableTargetNames 所有分片表的集合
* @param complexKeysShardingValue 多个分片健的值,并SQL中解析出来的分片值
*/
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames,
ComplexKeysShardingValue<Long> complexKeysShardingValue) {
/**
* 分库策略使用时:availableTargetNames 参数数据为分片库的集合 ["db0","db1"]
* 分表策略使用时:availableTargetNames 参数数据为分片库的集合 ["t_order_0","t_order_1","t_order_2"]
*/
log.info("进入复合分片:complex availableTargetNames:{}", JSON.toJSONString(availableTargetNames));
// 多分片健和其对应的分片健范围值
Map<String, Range<Long>> columnNameAndRangeValuesMap = complexKeysShardingValue.getColumnNameAndRangeValuesMap();
log.info("进入复合分片:columnNameAndRangeValuesMap:{}", JSON.toJSONString(columnNameAndRangeValuesMap));
columnNameAndRangeValuesMap.forEach((columnName, range) -> {
// 分片健
log.info("进入复合分片:columnName:{}", columnName);
// 分片健范围值
log.info("进入复合分片:range:{}", JSON.toJSONString(range));
});
// 多分片健和其对应的分片健值
Map<String, Collection<Long>> columnNameAndShardingValuesMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap();
log.info("进入复合分片:columnNameAndShardingValuesMap:{}", JSON.toJSONString(columnNameAndShardingValuesMap));
columnNameAndShardingValuesMap.forEach((columnName, shardingValues) -> {
// 分片健
log.info("进入复合分片:columnName:{}", columnName);
// 分片健值
log.info("进入复合分片:shardingValues:{}", JSON.toJSONString(shardingValues));
});
return null;
}
}配置算法
处理完复合分片算法的doSharding()核心逻辑,接着配置使用定义的算法,配置属性包括strategy分片策略类型设置成complex,algorithmClassName自定义算法的实现类全路径。
需要注意:配置分片键时,一定要使用 sharding-columns 表示复数形式,很容易出错。
spring:
shardingsphere:
rules:
sharding:
sharding-algorithms:
t_order_database_mod:
type: MOD
props:
sharding-count: 2 # 指定分片数量
# 13、自定义 complex 标准算法
t_order_complex_custom_algorithm:
type: CLASS_BASED
props:
# 分片策略
strategy: complex
# 分片算法类
algorithmClassName: com.shardingsphere_101.algorithm.OrderComplexCustomAlgorithm
# 自定义属性
aaaaaa: aaaaaa
tables:
# 逻辑表名称
t_order:
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
standard:
sharding-column: order_id
sharding-algorithm-name: t_order_database_mod
# 分表策略
table-strategy:
complex:
sharding-columns: order_id , user_id
sharding-algorithm-name: t_order_complex_custom_algorithm测试算法
插入测试数据,debug 进入 doSharding() 方法,看到columnNameAndShardingValuesMap内获取到了 user_id
、order_id 两个分片键及健值。
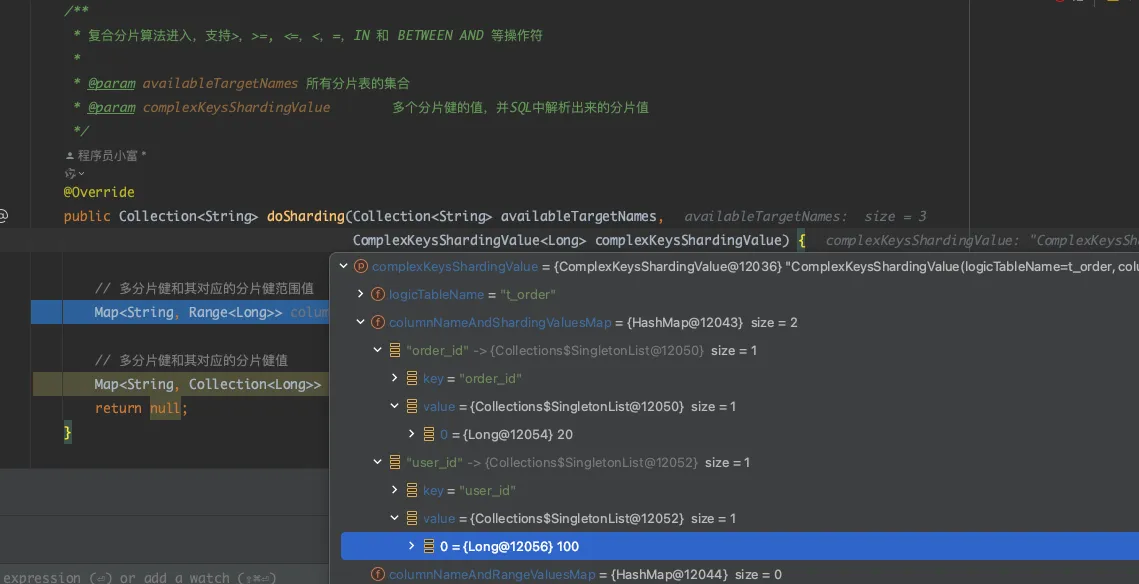
当执行范围查询的SQL,columnNameAndRangeValuesMap属性内获取到了 user_id、order_id 两个分片键及健值范围,通过range.upperEndpoint()、lowerEndpoint()得到上下界值。
select * from t_order where order_id > 1 and user_id > 1;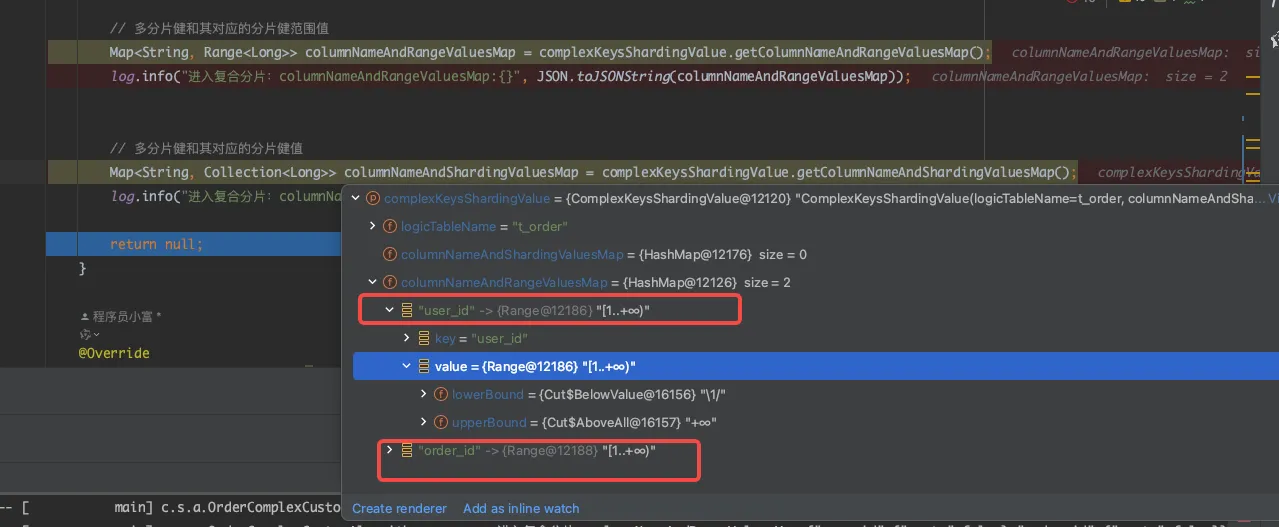
自定义 HINT 算法
要实现自定义HINT强制路由分片算法,需要实现 HintShardingAlgorithm<T> 接口( T 代表接收的分片键值类型)。在实现过程中,需要重写接口中的3个方法。其中,核心的分片逻辑在 doSharding() 方法中处理,可以支持返回多个分片数据源或分片表数据。另外,其他两个prop配置方法的使用方式与上述相同,这里不赘述。
重写 HINT 核心分片方法 doSharding(Collection availableTargetNames, HintShardingValue shardingValue),以实现我们的定制逻辑。该方法接受两个参数:一个是可用目标分库、分表的集合,另一个是 Hint 分片属性对象。

方法内执行流程:我们首先获取 HintManager API 设置的分库或分表的分片值,经过计算后得到合适的分片数据源或分片表集合,然后直接路由到目标位置,无需再关注SQL本身的条件信息。
/**
* 自定义强制路由分片算法
*
* @author 公众号:程序员小富
* @date 2024/03/22 11:02
*/
@Slf4j
public class OrderHintCustomAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, HintShardingValue<Long> hintShardingValue) {
/**
* 获取到设置的分表或者分库的分片值
* 指定分表时的分片值 hintManager.addTableShardingValue("t_order",2L);
* 指定分库时的分片值 hintManager.addDatabaseShardingValue("t_order", 100L);
*/
Collection<Long> values = hintShardingValue.getValues();
Collection<String> result = new ArrayList<>();
// 从所有分片表中得到合适的分片表
for (String each : availableTargetNames) {
for (Long value : values) {
Long mod = value % availableTargetNames.size();
if (each.endsWith(String.valueOf(mod))) {
result.add(each);
}
}
}
return result;
}
}配置算法
配置自定义Hint算法,配置属性包括strategy分片策略类型设置成hint,algorithmClassName自定义Hint算法的实现类全路径。使用该算法时无需指定分片健!
spring:
shardingsphere:
# 具体规则配置
rules:
sharding:
# 分片算法定义
sharding-algorithms:
t_order_database_mod:
type: MOD
props:
sharding-count: 2 # 指定分片数量
# 14、自定义 hint 标准算法
t_order_hint_custom_algorithm:
type: CLASS_BASED
props:
# 分片策略
strategy: hint
# 分片算法类
algorithmClassName: com.shardingsphere_101.algorithm.OrderHintCustomAlgorithm
# 自定义属性
bbbbbb: bbbbbb
tables:
# 逻辑表名称
t_order:
# 数据节点:数据库.分片表
actual-data-nodes: db$->{0..1}.t_order_${0..2}
# 分库策略
database-strategy:
hint:
sharding-algorithm-name: t_order_database_mod
# 分表策略
table-strategy:
hint:
sharding-algorithm-name: t_order_hint_custom_algorithm测试算法
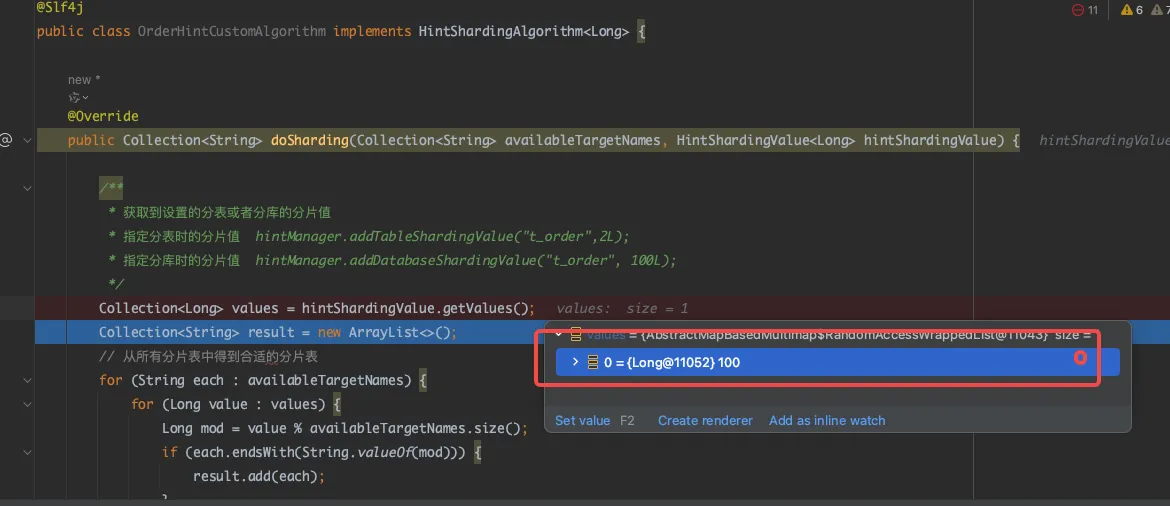
在执行SQL操作之前,使用 HintManager API 的 addDatabaseShardingValue和 addTableShardingValue方法来指定分库或分表的分片值,这样算法内通过 HintShardingValue 可以获取到分片值。注意:如果在执行 SQL 时没有使用 HintManager 指定分片值,那么执行SQL将会执行全库表路由。
@DisplayName("Hint 自动义分片算法-范围查询")
@Test
public void queryHintTableTest() {
HintManager hintManager = HintManager.getInstance();
// 指定分表时的分片值
hintManager.addTableShardingValue("t_order",2L);
// 指定分库时的分片值
hintManager.addDatabaseShardingValue("t_order", 100L);
QueryWrapper<OrderPo> queryWrapper = new QueryWrapper<OrderPo>()
.eq("user_id", 20).eq("order_id", 10);
List<OrderPo> orderPos = orderMapper.selectList(queryWrapper);
log.info("查询结果:{}", JSON.toJSONString(orderPos));
}
到这关于 shardingsphere-jdbc 的 3种自定义分片算法实现就全部结束了。
总结
本文介绍了 STANDARD、COMPLEX 和 HINT 三种自定义分片算法的实现,和使用过程中一些要注意的事项。ShardingSphere 内置的十几种算法,其实已经可以满足我们绝大部分的业务场景,不过,如果考虑到后续的性能优化和扩展性,定制分片算法是个不错的选择。
全部demo案例 GitHub 地址:https://github.com/chengxy-nds/Springboot-Notebook/tree/master/shardingsphere101/shardingsphere-algorithms
我是小富~ 下期见
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号