Elasticsearch快照(snapshot)备份原理及分析
原创
Elasticsearch快照(snapshot)备份原理及分析
原创
空洞的盒子
发布于 2024-08-02 14:52:04
发布于 2024-08-02 14:52:04
什么是Elasticsearch的Snapshot backup
Snapshot是Elasticsearch提供的一种将集群数据备份至远程存储库的功能。例如将数据备份至S3,HDFS,共享文件系统等。
使用场景
1. 数据备份和恢复
• 快照功能提供了数据的备份和恢复能力,确保数据不会因意外故障而丢失。
2. 集群迁移
• 可以使用快照功能将数据从一个Elasticsearch集群迁移到另一个集群。
3. 数据归档
• 将历史数据快照到存储库中,从而释放在线集群的存储空间。
Repository
- 存储库是用来保存快照的存储位置。Elasticsearch支持多种类型的存储库,如共享文件系统(fs)、Amazon S3、HDFS、Azure Blob存储等。
- 存储库需要在创建快照之前进行注册。
Snapshot
- 快照是指定时间点上Elasticsearch集群或索引的备份。快照包含索引的所有分片数据。
- 快照是增量的,只有自上次快照以来发生更改的数据会被保存。
快照操作步骤
创建仓库
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups",
"compress": true
}
}创建快照
PUT /_snapshot/my_backup/snapshot_1
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false
}参数说明:
• indices:要备份的索引列表。
• ignore_unavailable:如果索引不可用是否忽略。
• include_global_state:是否包括集群的全局状态。
恢复快照
POST /_snapshot/my_backup/snapshot_1/_restore
{
"indices": "index_1,index_2",
"ignore_unavailable": true,
"include_global_state": false,
"rename_pattern": "index_(.+)",
"rename_replacement": "restored_index_$1"
}参数说明:
• indices:要恢复的索引列表。
• ignore_unavailable:如果索引不可用是否忽略。
• include_global_state:是否包括集群的全局状态。
• rename_pattern 和 rename_replacement:用于重命名恢复的索引。
查看快照
#查看仓库下全部快照
GET /_snapshot/my_backup/_all
#查看具体某一快照
GET /_snapshot/my_backup/snapshot1
#查看快照状态
GET /_snapshot/my_backup/snapshot1/_status删除快照
DELETE /_snapshot/my_backup/snapshot_1- 可以删除某个快照以释放远程存储仓库所在存储介质的存储空间。
操作注意事项
1. 存储库类型和配置
• 存储库类型和配置应根据实际需求和环境选择,例如使用S3存储库需要配置访问凭证和存储桶。
2. 快照性能
• 创建和恢复快照时会消耗集群资源,应在非高峰期执行这些操作以避免对线上服务的影响。
3. 快照一致性
• 创建快照时Elasticsearch确保数据的一致性,即使在快照过程中有数据写入操作,也不会影响快照的一致性。
4. 安全性
• 确保存储库的访问权限和快照操作的权限配置合理,防止未经授权的操作。
备份原理与源码解析
备份原理
当发起备份快照请求至快照备份完成大致分为以下几个阶段:
请求解析阶段
- 获取快照备份请求,解析快照备份语句,创建快照备份请求。
- 备份请求创建后,Elasticsearch首先会对repository进行合规检查,状态检查。
- 解析请求中的indices表达式,加载请求中指定的各类参数,加载插件状态;
请求构造阶段
- 构造snapshot request,将通过客户端提交的备份请求解析为用于在Elasticsearch中执行的请求语句。
- 初始化备份请求,主要进行快照ID的生成,监听器的注册,repository元数据的加载等。
请求准备阶段
- 首先对snapshot request中的快照进行验证,判断是否已经存在或已经有同名snapshot处于流程中的状态。
- 开始执行snapshot backup任务,需要对repository metadata进行校验,判断snapshot name在repository中的可用性。校验任务并发数是否超过参数值限制。
- 获取snapshot中涉及到的indices列表,准备相关shard metadata与shard data。
- 创建快照条目集合,开始维护快照状态。
请求执行阶段
- 获取已经校验完成的index shard ID。
- 检查获取的index shard是否为primary shard。这是因为快照仅作用于primary shard。
- 检查index shard当前的状态,是否允许进行snapshot操作。当需要备份的shard处于relocating或recovering状态时进行backup操作时会发生冲突。
- 获取snapshot中包含的indices的shard的底层segment文件和metadata文件。以Stream的方式将数据文件写入至远程repository。
- 在snapshot backup Task执行期间,ActionListener会对备份请求的状态进行持续的监听。
请求完成阶段
- 当有index shard备份完成后,快照进程会调用方法像集群中的master node 同步已经完成的shard信息,并发送完成的状态。同时向master node同步分片所在节点的shard备份状态。
- 向shard所在节点更新特定快照的备份状态。
- 接收ActionListener返回的回调信息并进行处理。
- 当快照中所有的shard全部备份完成,状态全部更新完成后,snapshot backup进程会释放所占用的shard资源。TransportService threadpool也将结束对于snapshot相关thread的维护工作。
Snapshot backup Task在Elasticsearch中的执行逻辑细则如下图所示:
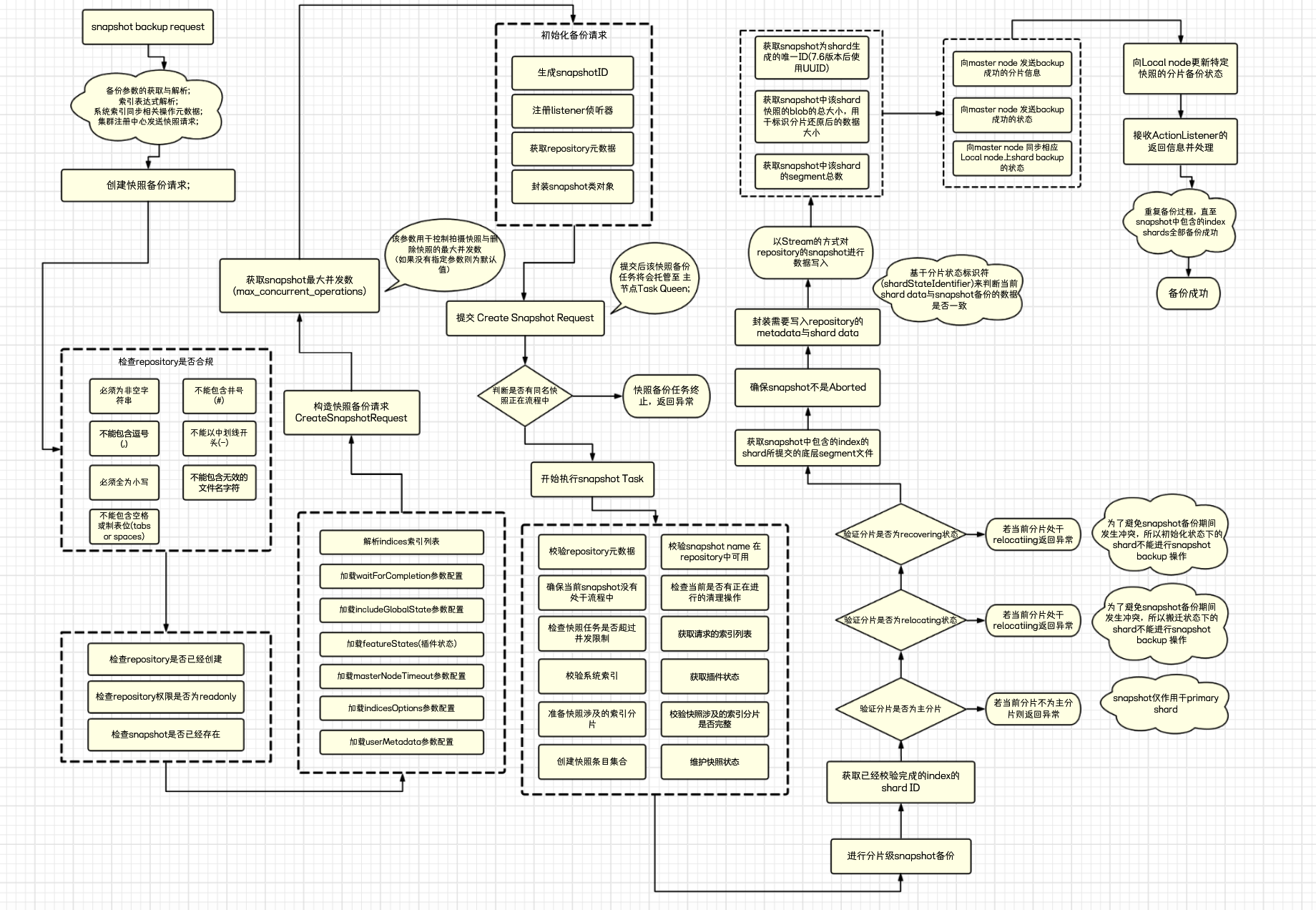
Snapshot备份原理流程图
主要源码分析
1.CreateSnapshotRequest.java
主要用于创建快照请求,约束了repository唯一参数,以及命名规范。
public CreateSnapshotRequest(String repository, String snapshot) {
this.snapshot = snapshot;
this.repository = repository;
}
public CreateSnapshotRequest(StreamInput in) throws IOException {
super(in);
snapshot = in.readString();
repository = in.readString();
indices = in.readStringArray();
indicesOptions = IndicesOptions.readIndicesOptions(in);
if (in.getTransportVersion().before(SETTINGS_IN_REQUEST_VERSION)) {
readSettingsFromStream(in);
}
featureStates = in.readStringArray();
includeGlobalState = in.readBoolean();
waitForCompletion = in.readBoolean();
partial = in.readBoolean();
userMetadata = in.readMap();
}
@Override
public void writeTo(StreamOutput out) throws IOException {
super.writeTo(out);
out.writeString(snapshot);
out.writeString(repository);
out.writeStringArray(indices);
indicesOptions.writeIndicesOptions(out);
if (out.getTransportVersion().before(SETTINGS_IN_REQUEST_VERSION)) {
Settings.EMPTY.writeTo(out);
}
out.writeStringArray(featureStates);
out.writeBoolean(includeGlobalState);
out.writeBoolean(waitForCompletion);
out.writeBoolean(partial);
out.writeGenericMap(userMetadata);
}
@Override
public ActionRequestValidationException validate() {
ActionRequestValidationException validationException = null;
if (snapshot == null) {
validationException = addValidationError("snapshot is missing", validationException);
}
if (repository == null) {
validationException = addValidationError("repository is missing", validationException);
}
if (indices == null) {
validationException = addValidationError("indices is null", validationException);
} else {
for (String index : indices) {
if (index == null) {
validationException = addValidationError("index is null", validationException);
break;
}
}
}
if (indicesOptions == null) {
validationException = addValidationError("indicesOptions is null", validationException);
}
if (featureStates == null) {
validationException = addValidationError("featureStates is null", validationException);
}
final int metadataSize = metadataSize(userMetadata);
if (metadataSize > MAXIMUM_METADATA_BYTES) {
validationException = addValidationError(
"metadata must be smaller than 1024 bytes, but was [" + metadataSize + "]",
validationException
);
}
return validationException;
}
@Override
public String toString() {
return "CreateSnapshotRequest{"
+ "snapshot='"
+ snapshot
+ '\''
+ ", repository='"
+ repository
+ '\''
+ ", indices="
+ (indices == null ? null : Arrays.asList(indices))
+ ", indicesOptions="
+ indicesOptions
+ ", featureStates="
+ Arrays.asList(featureStates)
+ ", partial="
+ partial
+ ", includeGlobalState="
+ includeGlobalState
+ ", waitForCompletion="
+ waitForCompletion
+ ", masterNodeTimeout="
+ masterNodeTimeout
+ ", metadata="
+ userMetadata
+ '}';
}CreateSnapshotRequest类继承自MasterNodeRequest类,同时在继承时将CreateSnapshotRequest作为泛型参数传入。表名创建快照请求需要主节点进行处理。调用父类 MasterNodeRequest 的构造方法,从输入流中读取和初始化父类的字段。通过调用父类的writeTo()方法将快照请求中的字段写入至输出流。同时通过validate()方法来对snapshot,repository,indices,indicesOptions,featureStates,metadataSize进行相关的校验。通过toString()方法完成request的构建。
字段说明:
snapshot: 从输入流中读取快照的名称。repository: 从输入流中读取存储库的名称。indices: 从输入流中读取索引数组。indicesOptions: 从输入流中读取索引选项。if (in.getTransportVersion().before(SETTINGS_IN_REQUEST_VERSION)) { readSettingsFromStream(in); }:如果传输版本在特定版本之前,从输入流中读取设置。featureStates: 从输入流中读取特性状态数组。includeGlobalState: 从输入流中读取是否包括全局状态的布尔值。waitForCompletion: 从输入流中读取是否等待完成的布尔值。partial: 从输入流中读取是否部分快照的布尔值。userMetadata: 从输入流中读取用户元数据。
2.SnapshotsService.java
这个类主要负责创建快照的相关服务。这个Service贯穿于创建快照,删除快照在主节点上执行的所有步骤。
public static final Setting<Integer> MAX_CONCURRENT_SNAPSHOT_OPERATIONS_SETTING = Setting.intSetting(
"snapshot.max_concurrent_operations",
1000,
1,
Setting.Property.NodeScope,
Setting.Property.Dynamic
);
private volatile int maxConcurrentOperations;在这个类中,首先我们可以看到在开头就创建了名为MAX_CONCURRENT_SNAPSHOT_OPERATIONS_SETTING的静态常量,范围是从1~1000。默认值是1000。这个参数就是我们用于控制同时执行快照任务的最大并发数限制。如果我们在快照语句冲没有指定该参数值时,那么快照在构造执行时就会加载该参数的默认值。
public SnapshotsService(
Settings settings,
ClusterService clusterService,
IndexNameExpressionResolver indexNameExpressionResolver,
RepositoriesService repositoriesService,
TransportService transportService,
ActionFilters actionFilters,
SystemIndices systemIndices
) {
this.clusterService = clusterService;
this.indexNameExpressionResolver = indexNameExpressionResolver;
this.repositoriesService = repositoriesService;
this.threadPool = transportService.getThreadPool();
this.transportService = transportService;
// The constructor of UpdateSnapshotStatusAction will register itself to the TransportService.
this.updateSnapshotStatusHandler = new UpdateSnapshotStatusAction(
transportService,
clusterService,
threadPool,
actionFilters,
indexNameExpressionResolver
);
if (DiscoveryNode.isMasterNode(settings)) {
// addLowPriorityApplier to make sure that Repository will be created before snapshot
clusterService.addLowPriorityApplier(this);
maxConcurrentOperations = MAX_CONCURRENT_SNAPSHOT_OPERATIONS_SETTING.get(settings);
clusterService.getClusterSettings()
.addSettingsUpdateConsumer(MAX_CONCURRENT_SNAPSHOT_OPERATIONS_SETTING, i -> maxConcurrentOperations = i);
}
this.systemIndices = systemIndices;
this.masterServiceTaskQueue = clusterService.createTaskQueue("snapshots-service", Priority.NORMAL, new SnapshotTaskExecutor());
}
在该构造函数中初始化了部分快照创建,备份,删除过程中涉及到的关键参数。
参数解析
• Settings settings: 配置项,包含集群配置的相关设置。
• ClusterService clusterService: 集群服务,提供集群状态和集群级别的操作。
• IndexNameExpressionResolver indexNameExpressionResolver: 索引名称表达式解析器,用于解析索引名称表达式。
• RepositoriesService repositoriesService: 仓库服务,管理快照仓库的创建和访问。
• TransportService transportService: 传输服务,负责节点间通信。
• ActionFilters actionFilters: 动作过滤器,处理操作请求的过滤逻辑。
• SystemIndices systemIndices: 系统索引,管理系统级索引。
public void createSnapshot(final CreateSnapshotRequest request, final ActionListener<Snapshot> listener) {
final String repositoryName = request.repository();
final String snapshotName = IndexNameExpressionResolver.resolveDateMathExpression(request.snapshot());
validate(repositoryName, snapshotName);
// TODO: create snapshot UUID in CreateSnapshotRequest and make this operation idempotent to cleanly deal with transport layer
// retries
final SnapshotId snapshotId = new SnapshotId(snapshotName, UUIDs.randomBase64UUID()); // new UUID for the snapshot
Repository repository = repositoriesService.repository(request.repository());
if (repository.isReadOnly()) {
listener.onFailure(new RepositoryException(repository.getMetadata().name(), "cannot create snapshot in a readonly repository"));
return;
}
submitCreateSnapshotRequest(request, listener, repository, new Snapshot(repositoryName, snapshotId), repository.getMetadata());
}
通过createSnapshot()方法用于实现对快照流程的初始化。在该方法中我们可以看到对于repositoryName,snapshotName的获取与解析,对于快照仓库的权限判断,如果仓库权限为ReadOnly则直接返回。全部检验完成后则调用submitCreateSnapshotRequest()方法提交快照请求。
private void submitCreateSnapshotRequest(
CreateSnapshotRequest request,
ActionListener<Snapshot> listener,
Repository repository,
Snapshot snapshot,
RepositoryMetadata initialRepositoryMetadata
) {
repository.getRepositoryData(
listener.delegateFailure(
(l, repositoryData) -> masterServiceTaskQueue.submitTask(
"create_snapshot [" + snapshot.getSnapshotId().getName() + ']',
new CreateSnapshotTask(repository, repositoryData, l, snapshot, request, initialRepositoryMetadata),
request.masterNodeTimeout()
)
)
);
}submitCreateSnapshotRequest()方法的主要用途是提交创建快照的请求。在正确获取到全部参数后会生成一个全新的快照备份SnapshotTask。
主要包含以下几个关键步骤:
1. 获取仓库数据: 它首先通过调用 repository.getRepositoryData 来获取快照仓库的数据。
2. 处理失败情况: 它使用 listener.delegateFailure 方法来处理任何可能的失败情况。
3. 提交快照任务: 如果成功获取到仓库数据,它会将创建快照的任务提交到 masterServiceTaskQueue。
参数解析
• CreateSnapshotRequest request: 创建快照的请求对象,包含了快照操作所需的所有参数。
• ActionListener listener: 操作完成后的回调监听器,用于处理成功或失败的情况。
• Repository repository: 进行快照操作的目标仓库。
• Snapshot snapshot: 要创建的快照对象。
• RepositoryMetadata initialRepositoryMetadata: 初始仓库元数据。
在快照任务提交之后,我们就需要对快照请求进行解析与执行。这里我们继续往下看。
private class SnapshotTaskExecutor implements ClusterStateTaskExecutor<SnapshotTask> {
@Override
public ClusterState execute(BatchExecutionContext<SnapshotTask> batchExecutionContext) throws Exception {
final ClusterState state = batchExecutionContext.initialState();
final SnapshotShardsUpdateContext shardsUpdateContext = new SnapshotShardsUpdateContext(batchExecutionContext);
final SnapshotsInProgress initialSnapshots = state.custom(SnapshotsInProgress.TYPE, SnapshotsInProgress.EMPTY);
SnapshotsInProgress snapshotsInProgress = shardsUpdateContext.computeUpdatedState();
for (final var taskContext : batchExecutionContext.taskContexts()) {
if (taskContext.getTask()instanceof CreateSnapshotTask task) {
try {
final var repoMeta = state.metadata()
.custom(RepositoriesMetadata.TYPE, RepositoriesMetadata.EMPTY)
.repository(task.snapshot.getRepository());
if (Objects.equals(task.initialRepositoryMetadata, repoMeta)) {
snapshotsInProgress = createSnapshot(task, taskContext, state, snapshotsInProgress);
} else {
// repository data changed in between starting the task and executing this cluster state update so try again
taskContext.success(
() -> submitCreateSnapshotRequest(
task.createSnapshotRequest,
task.listener,
task.repository,
task.snapshot,
repoMeta
)
);
}
} catch (Exception e) {
taskContext.onFailure(e);
}
}
}
shardsUpdateContext.completeWithUpdatedState(snapshotsInProgress);
if (snapshotsInProgress == initialSnapshots) {
return state;
}
return ClusterState.builder(state).putCustom(SnapshotsInProgress.TYPE, snapshotsInProgress).build();
}
private SnapshotsInProgress createSnapshot(
CreateSnapshotTask createSnapshotTask,
TaskContext<SnapshotTask> taskContext,
ClusterState currentState,
SnapshotsInProgress snapshotsInProgress
) {
final RepositoryData repositoryData = createSnapshotTask.repositoryData;
final Snapshot snapshot = createSnapshotTask.snapshot;
final String repositoryName = snapshot.getRepository();
final String snapshotName = snapshot.getSnapshotId().getName();
ensureRepositoryExists(repositoryName, currentState);
final Repository repository = createSnapshotTask.repository;
ensureSnapshotNameAvailableInRepo(repositoryData, snapshotName, repository);
ensureSnapshotNameNotRunning(snapshotsInProgress, repositoryName, snapshotName);
validate(repositoryName, snapshotName, currentState);
final SnapshotDeletionsInProgress deletionsInProgress = currentState.custom(
SnapshotDeletionsInProgress.TYPE,
SnapshotDeletionsInProgress.EMPTY
);
ensureNoCleanupInProgress(currentState, repositoryName, snapshotName, "create snapshot");
ensureBelowConcurrencyLimit(repositoryName, snapshotName, snapshotsInProgress, deletionsInProgress);
final CreateSnapshotRequest request = createSnapshotTask.createSnapshotRequest;
// Store newSnapshot here to be processed in clusterStateProcessed
Map<Boolean, List<String>> requestedIndices = Arrays.stream(
indexNameExpressionResolver.concreteIndexNames(currentState, request)
).collect(Collectors.partitioningBy(systemIndices::isSystemIndex));
List<String> requestedSystemIndices = requestedIndices.get(true);
//对于系统索引的验证
if (requestedSystemIndices.isEmpty() == false) {
Set<String> explicitlyRequestedSystemIndices = new HashSet<>(requestedSystemIndices);
explicitlyRequestedSystemIndices.retainAll(Arrays.asList(request.indices()));
if (explicitlyRequestedSystemIndices.isEmpty() == false) {
throw new IllegalArgumentException(
format(
"the [indices] parameter includes system indices %s; to include or exclude system indices from a "
+ "snapshot, use the [include_global_state] or [feature_states] parameters",
explicitlyRequestedSystemIndices
)
);
}
}
List<String> indices = requestedIndices.get(false);
final List<String> requestedStates = Arrays.asList(request.featureStates());
final Set<String> featureStatesSet;
//请求状态的验证
if (request.includeGlobalState() || requestedStates.isEmpty() == false) {
if (request.includeGlobalState() && requestedStates.isEmpty()) {
// If we're including global state and feature states aren't specified, include all of them
featureStatesSet = systemIndices.getFeatureNames();
} else if (requestedStates.size() == 1 && NO_FEATURE_STATES_VALUE.equalsIgnoreCase(requestedStates.get(0))) {
// If there's exactly one value and it's "none", include no states
featureStatesSet = Collections.emptySet();
} else {
// Otherwise, check for "none" then use the list of requested states
if (requestedStates.contains(NO_FEATURE_STATES_VALUE)) {
throw new IllegalArgumentException(
"the feature_states value ["
+ SnapshotsService.NO_FEATURE_STATES_VALUE
+ "] indicates that no feature states should be snapshotted, "
+ "but other feature states were requested: "
+ requestedStates
);
}
featureStatesSet = new HashSet<>(requestedStates);
featureStatesSet.retainAll(systemIndices.getFeatureNames());
}
} else {
featureStatesSet = Collections.emptySet();
}
final Set<SnapshotFeatureInfo> featureStates = new HashSet<>();
final Set<String> systemDataStreamNames = new HashSet<>();
final Set<String> indexNames = new HashSet<>(indices);
for (String featureName : featureStatesSet) {
SystemIndices.Feature feature = systemIndices.getFeature(featureName);
Set<String> featureSystemIndices = feature.getIndexDescriptors()
.stream()
.flatMap(descriptor -> descriptor.getMatchingIndices(currentState.metadata()).stream())
.collect(Collectors.toSet());
Set<String> featureAssociatedIndices = feature.getAssociatedIndexDescriptors()
.stream()
.flatMap(descriptor -> descriptor.getMatchingIndices(currentState.metadata()).stream())
.collect(Collectors.toSet());
Set<String> featureSystemDataStreams = new HashSet<>();
Set<String> featureDataStreamBackingIndices = new HashSet<>();
for (SystemDataStreamDescriptor sdd : feature.getDataStreamDescriptors()) {
List<String> backingIndexNames = sdd.getBackingIndexNames(currentState.metadata());
if (backingIndexNames.size() > 0) {
featureDataStreamBackingIndices.addAll(backingIndexNames);
featureSystemDataStreams.add(sdd.getDataStreamName());
}
}
if (featureSystemIndices.size() > 0 || featureAssociatedIndices.size() > 0 || featureDataStreamBackingIndices.size() > 0) {
featureStates.add(new SnapshotFeatureInfo(featureName, List.copyOf(featureSystemIndices)));
indexNames.addAll(featureSystemIndices);
indexNames.addAll(featureAssociatedIndices);
indexNames.addAll(featureDataStreamBackingIndices);
systemDataStreamNames.addAll(featureSystemDataStreams);
}
indices = List.copyOf(indexNames);
}
logger.trace("[{}][{}] creating snapshot for indices [{}]", repositoryName, snapshotName, indices);
final Map<String, IndexId> allIndices = new HashMap<>();
for (SnapshotsInProgress.Entry runningSnapshot : snapshotsInProgress.forRepo(repositoryName)) {
allIndices.putAll(runningSnapshot.indices());
}
final Map<String, IndexId> indexIds = repositoryData.resolveNewIndices(indices, allIndices);
final Version version = minCompatibleVersion(currentState.nodes().getMinNodeVersion(), repositoryData, null);
ImmutableOpenMap<ShardId, ShardSnapshotStatus> shards = shards(
snapshotsInProgress,
deletionsInProgress,
currentState,
indexIds.values(),
useShardGenerations(version),
repositoryData,
repositoryName
);
if (request.partial() == false) {
Set<String> missing = new HashSet<>();
//分片相关信息的验证
for (Map.Entry<ShardId, ShardSnapshotStatus> entry : shards.entrySet()) {
if (entry.getValue().state() == ShardState.MISSING) {
missing.add(entry.getKey().getIndex().getName());
}
}
if (missing.isEmpty() == false) {
throw new SnapshotException(snapshot, "Indices don't have primary shards " + missing);
}
}
// 生成新的快照条目
final var newEntry = SnapshotsInProgress.startedEntry(
snapshot,
request.includeGlobalState(),
request.partial(),
indexIds,
CollectionUtils.concatLists(
indexNameExpressionResolver.dataStreamNames(currentState, request.indicesOptions(), request.indices()),
systemDataStreamNames
),
threadPool.absoluteTimeInMillis(),
repositoryData.getGenId(),
shards,
request.userMetadata(),
version,
List.copyOf(featureStates)
);
// 更新任务上下文并返回新的快照进度
final var res = snapshotsInProgress.withAddedEntry(newEntry);
taskContext.success(() -> {
logger.info("snapshot [{}] started", snapshot);
createSnapshotTask.listener.onResponse(snapshot);
if (newEntry.state().completed()) {
endSnapshot(newEntry, currentState.metadata(), createSnapshotTask.repositoryData);
}
});
return res;
}
}此时Elasticsearch在这里创建了一个名为SnapshotTaskExecutor的内部类,实现了ClusterStateTaskExecutor<SnapshotTask> 接口,用于执行快照任务。
在这个内部类中public ClusterState execute(BatchExecutionContext<SnapshotTask> batchExecutionContext)方法负责处理提交的快照任务,并根据任务的类型执行相应的操作。
主要包含以下步骤:
1. 初始化集群状态:获取初始的集群状态。
2. 创建快照更新上下文:用于更新快照的状态。
3. 获取当前进行中的快照:从集群状态中获取当前进行中的快照信息。
4. 处理任务:遍历任务上下文,检查任务类型是否为 CreateSnapshotTask,并执行相应的操作。
• 如果仓库元数据没有改变,则调用 createSnapshot 方法创建快照。
• 如果仓库元数据改变,则重新提交创建快照请求。
5. 更新快照状态:更新快照状态,如果没有变化,返回初始集群状态,否则返回更新后的集群状态。
private SnapshotsInProgress createSnapshot(CreateSnapshotTask createSnapshotTask,TaskContext<SnapshotTask> taskContext,ClusterState currentState,SnapshotsInProgress snapshotsInProgress) 方法负责具体创建快照的步骤。
在该方法中对于快照仓库,快照,索引,插件状态均进行了详细的验证。主要包含以下几个步骤
1. 各种快照相关数据验证:确保仓库存在、快照名称可用、没有清理进行中等。
2. 处理请求的索引和特性状态:根据请求处理需要快照的索引和特性状态。
3. 创建新快照条目:生成新的快照条目。
4. 更新任务上下文:更新任务上下文,并在快照开始时调用监听器的响应方法。
5. 返回新的快照进度:返回更新后的快照进度。
3.SnapshotShardsService.java
SnapshotShardsService.java主要运行于数据节点,并控制这些节点运行的分片快照,负责管理这些分片级快照,包括启动,停止等动作。
public SnapshotShardsService(
Settings settings,
ClusterService clusterService,
RepositoriesService repositoriesService,
TransportService transportService,
IndicesService indicesService
) {
this.indicesService = indicesService;
this.repositoriesService = repositoriesService;
this.transportService = transportService;
this.clusterService = clusterService;
this.threadPool = transportService.getThreadPool();
this.remoteFailedRequestDeduplicator = new ResultDeduplicator<>(threadPool.getThreadContext());
if (DiscoveryNode.canContainData(settings)) {
// this is only useful on the nodes that can hold data
clusterService.addListener(this);
}
}首先在构造函数中初始化了indices,repository,cluster,threadPool相关属性。同时需要注意clusterService.addListener(this);只在保存数据的节点上产生作用。
private void snapshot(
final ShardId shardId,
final Snapshot snapshot,
final IndexId indexId,
final IndexShardSnapshotStatus snapshotStatus,
Version version,
final long entryStartTime,
ActionListener<ShardSnapshotResult> resultListener
) {
ActionListener.run(resultListener, listener -> {
snapshotStatus.ensureNotAborted();
final IndexShard indexShard = indicesService.indexServiceSafe(shardId.getIndex()).getShard(shardId.id());
if (indexShard.routingEntry().primary() == false) {
throw new IndexShardSnapshotFailedException(shardId, "snapshot should be performed only on primary");
}
if (indexShard.routingEntry().relocating()) {
// do not snapshot when in the process of relocation of primaries so we won't get conflicts
throw new IndexShardSnapshotFailedException(shardId, "cannot snapshot while relocating");
}
final IndexShardState indexShardState = indexShard.state();
if (indexShardState == IndexShardState.CREATED || indexShardState == IndexShardState.RECOVERING) {
// shard has just been created, or still recovering
throw new IndexShardSnapshotFailedException(shardId, "shard didn't fully recover yet");
}
final Repository repository = repositoriesService.repository(snapshot.getRepository());
Engine.IndexCommitRef snapshotRef = null;
try {
snapshotRef = indexShard.acquireIndexCommitForSnapshot();
snapshotStatus.ensureNotAborted();
repository.snapshotShard(
new SnapshotShardContext(
indexShard.store(),
indexShard.mapperService(),
snapshot.getSnapshotId(),
indexId,
snapshotRef,
getShardStateId(indexShard, snapshotRef.getIndexCommit()),
snapshotStatus,
version,
entryStartTime,
listener
)
);
} catch (Exception e) {
IOUtils.close(snapshotRef);
throw e;
}
});
}snapshot()主要负责创建分片快照。在该方法中我们可以看到在获取索引信息与分片id后,方法对当前分片是否为主分片,是否处于搬迁状态,是否处于初始化状态,均进行了严格校验。较晚完成后,才会创建分片快照。快照创建完成后调用IndexShard.java中的acquireIndexCommitForSnapshot()方法对索引文件进行提交。我们在后续将对该方法进行分析。
在这里我们只看到了对于分片的校验,如果在分片校验之前索引出现某些问题,那这里的逻辑则会出现漏洞,所以我们发现,在给对象indexShard获取索引与分片的相关信息时调用了indexServiceSafe()方法,或许可以为我们答疑解惑。
final IndexShard indexShard = indicesService.indexServiceSafe(shardId.getIndex()).getShard(shardId.id());public IndexService indexServiceSafe(Index index) {
IndexService indexService = indices.get(index.getUUID());
if (indexService == null) {
throw new IndexNotFoundException(index);
}
assert indexService.indexUUID().equals(index.getUUID())
: "uuid mismatch local: " + indexService.indexUUID() + " incoming: " + index.getUUID();
return indexService;
}在indexServiceSafe(Index index)方法中我们可以看到,已经对传入的索引进行了是否存在的检查。避免了再创建分片快照时出现由于索引问题而导致的创建异常。
在创建分片快照时,为了保证我们创建的分片快照是与当前Elasticsearch集群中存储的shard信息一致,这里我们通过getShardStateId(IndexShard indexShard,IndexCommit snapshotIndexCommit)进行一致性校验。
@Nullable
public static String getShardStateId(IndexShard indexShard, IndexCommit snapshotIndexCommit) throws IOException {
final Map<String, String> userCommitData = snapshotIndexCommit.getUserData();
final SequenceNumbers.CommitInfo seqNumInfo = SequenceNumbers.loadSeqNoInfoFromLuceneCommit(userCommitData.entrySet());
final long maxSeqNo = seqNumInfo.maxSeqNo;
if (maxSeqNo != seqNumInfo.localCheckpoint || maxSeqNo != indexShard.getLastSyncedGlobalCheckpoint()) {
return null;
}
return userCommitData.get(Engine.HISTORY_UUID_KEY)
+ "-"
+ userCommitData.getOrDefault(Engine.FORCE_MERGE_UUID_KEY, "na")
+ "-"
+ maxSeqNo;
}在getShardStateId()方法中,会基于shard当前状态为其生成一个标识符,这个标识符可用于检测分片的内容在两个快照之间是否已更改。如果分片的全局检查点和本地检查点相等,则假定分片的内容未更改,其最大序列号未更改,并且其 history- 和 force-merge-uuid 未更改。如果分片的全局和本地检查点不同,则该方法返回 {@code null},因为在这种情况下不能使用安全的唯一分片状态 ID,因为主故障转移可能会导致后续快照上同一序列号的不同分片内容。
/** Notify the master node that the given shard has been successfully snapshotted **/
private void notifySuccessfulSnapshotShard(final Snapshot snapshot, final ShardId shardId, ShardSnapshotResult shardSnapshotResult) {
assert shardSnapshotResult != null;
assert shardSnapshotResult.getGeneration() != null;
sendSnapshotShardUpdate(snapshot, shardId, ShardSnapshotStatus.success(clusterService.localNode().getId(), shardSnapshotResult));
}
/** Notify the master node that the given shard failed to be snapshotted **/
private void notifyFailedSnapshotShard(
final Snapshot snapshot,
final ShardId shardId,
final String failure,
final ShardGeneration generation
) {
sendSnapshotShardUpdate(
snapshot,
shardId,
new ShardSnapshotStatus(clusterService.localNode().getId(), ShardState.FAILED, failure, generation)
);
}在分片级快照备份完成后,我们还需要向主节点同步shard snapshot相关的信息与请求的状态,此时我们需要根据快照的状态 调用不同的回调方法来向主节点和数据节点同步分片信息,快照状态。然后才会进行相关资源的释放;如果备份成功则调用notifySuccessfulSnapshotShard(),如果失败则需要调用notifyFailedSnapshotShard()。不管是哪一个方法,都需要在回调时传递snapshot,shardId,ShardSnapshotStatus,ShardGeneration这四个必要参数。
private void sendSnapshotShardUpdate(final Snapshot snapshot, final ShardId shardId, final ShardSnapshotStatus status) {
remoteFailedRequestDeduplicator.executeOnce(
new UpdateIndexShardSnapshotStatusRequest(snapshot, shardId, status),
new ActionListener<>() {
@Override
public void onResponse(Void aVoid) {
logger.trace("[{}][{}] updated snapshot state to [{}]", shardId, snapshot, status);
}
@Override
public void onFailure(Exception e) {
logger.warn(() -> format("[%s][%s] failed to update snapshot state to [%s]", shardId, snapshot, status), e);
}
},
(req, reqListener) -> transportService.sendRequest(
transportService.getLocalNode(),
SnapshotsService.UPDATE_SNAPSHOT_STATUS_ACTION_NAME,
req,
new ActionListenerResponseHandler<>(reqListener.map(res -> null), in -> ActionResponse.Empty.INSTANCE)
)
);
}该方法则负责向主节点更新快照的状态。
4.IndexShard.java
public Engine.IndexCommitRef acquireIndexCommitForSnapshot() throws EngineException {
final IndexShardState state = this.state; // one time volatile read
if (state == IndexShardState.STARTED) {
// unlike acquireLastIndexCommit(), there's no need to acquire a snapshot on a shard that is shutting down
return getEngine().acquireIndexCommitForSnapshot();
} else {
throw new IllegalIndexShardStateException(shardId, state, "snapshot is not allowed");
}
}这个方法用于在快照过程中获取当前索引分片的索引提交(Index Commit)引用,以确保快照操作能够在一致的视图上执行。该方法在获取索引提交引用时会检查索引分片的状态,只有在分片处于启动状态时才允许获取索引提交引用。通过检查分片的状态,确保只有在分片启动且没有关闭的情况下,才允许获取索引提交引用。如果分片不处于启动状态,则抛出异常,防止不合法的快照操作。在该方法的返回中getEngine().acquireIndexCommitForSnapshot();调用引擎的 acquireIndexCommitForSnapshot 方法获取当前索引分片的索引提交引用。这确保了获取的提交是一个一致的视图,可以用于快照操作。
通过分析该方法的逻辑,我们可以发现:
1. 读取分片状态:
• final IndexShardState state = this.state;:一次性读取分片的当前状态。这里 this.state 是一个 volatile 变量,因此读取是线程安全的。
2. 检查分片状态:
• if (state == IndexShardState.STARTED):检查分片的状态是否为 STARTED(已启动)。只有当分片处于启动状态时,才允许获取索引提交引用。
3. 获取索引提交引用:
• return getEngine().acquireIndexCommitForSnapshot();:调用引擎的 acquireIndexCommitForSnapshot 方法获取当前索引分片的索引提交引用。这确保了获取的提交是一个一致的视图,可以用于快照操作。
4. 异常处理:
• else 分支:如果分片的状态不是 STARTED,则抛出 IllegalIndexShardStateException 异常,表明在当前状态下不允许进行快照操作。
getEngine().acquireIndexCommitForSnapshot()这里获取的索引提交则是依赖Lucene中的IndexCommit.java
5.IndexCommit.java
IndexCommit.java 是底层Lucene包中的一个抽象类,代表了索引的一个提交点(commit point)。它在索引管理过程中起着关键作用,尤其是在处理索引提交、删除和快照等操作时。
public abstract class IndexCommit implements Comparable<IndexCommit> {
/** 获取提交点关联的段文件. */
public abstract String getSegmentsFileName();
/** 返回该提交点引用的所有关联文件. */
public abstract Collection<String> getFileNames() throws IOException;
/** 返回索引的目录. */
public abstract Directory getDirectory();
/**
* 删除提交点,仅适用于在上下文中引用的提交点。
* 调用该方法后会通知调用者删除该提交点。具体删除的策略则是由IndexDeleationPolicy所决定。
* 这只能由其IndexDeleationPolicy策略下的onInit()或者onCommit()方法调用;
*/
public abstract void delete();
/**
* 如果调用删除,则返回true。默认由IndexWriter进行调用。
*/
public abstract boolean isDeleted();
/** 返回引用的segment数量。 */
public abstract int getSegmentCount();
/**唯一提交方法,通常为隐式调用*/
protected IndexCommit() {}
/** 用于判断两次IndexCommit提交内容,目录是否相等。 */
@Override
public boolean equals(Object other) {
if (other instanceof IndexCommit) {
IndexCommit otherCommit = (IndexCommit) other;
return otherCommit.getDirectory() == getDirectory()
&& otherCommit.getGeneration() == getGeneration();
} else {
return false;
}
}
@Override
public int hashCode() {
return getDirectory().hashCode() + Long.valueOf(getGeneration()).hashCode();
}
/** 返回当前提交生成的segment */
public abstract long getGeneration();
/**
* 返回已经传递给IndexWriter的userData。
*/
public abstract Map<String, String> getUserData() throws IOException;
@Override
public int compareTo(IndexCommit commit) {
if (getDirectory() != commit.getDirectory()) {
throw new UnsupportedOperationException(
"cannot compare IndexCommits from different Directory instances");
}
long gen = getGeneration();
long comgen = commit.getGeneration();
return Long.compare(gen, comgen);
}
/**
* 从NRT或非NRT中获取提交点初始化
*/
StandardDirectoryReader getReader() {
return null;
}
}该抽象类主要提供以下功能:
1. 管理和引用索引提交点:
• 提供接口以获取特定提交点的段文件、索引文件和目录。
2. 提交点的删除和检查:
• 允许通过 delete 方法标记提交点删除,通过 isDeleted 方法检查删除状态。
3. 提交点比较:
• 通过 compareTo 方法比较两个提交点的代,确保操作的正确顺序。
4. 用户数据管理:
• 支持存储和检索与提交点关联的用户数据。
5. 确保一致性:
• 提供了 equals 和 hashCode 方法以确保提交点的一致性和唯一性。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号