scrapy异步下载图片
原创
scrapy异步下载图片
原创
用户6841540
发布于 2024-08-07 08:55:37
发布于 2024-08-07 08:55:37
scrapy异步下载图片
通过 from scrapy.pipelines.images import ImagesPipeline管道下载,可以考虑自己重写,从而修改默认的方式
爬虫文件
"""scrapy异步下载图片"""
import scrapy
from selenium.webdriver import Chrome
from ..items import ServantPicItem
import pandas as pd
import numpy as np
from scrapy.pipelines.images import ImagesPipeline
class ServantSpider(scrapy.Spider):
name_list = []
img_list = []
name = 'servant'
start_urls = ['https://fgo.wiki/w/%E8%8B%B1%E7%81%B5%E5%9B%BE%E9%89%B4']
def parse(self, response):
item = ServantPicItem()
# 读取本地csv文件
data = pd.read_csv("link.csv",usecols=["图片名称"])
data_array1 = np.array(data.stack()) # 首先将pandas读取的数据转化为array
self.name_list = data_array1.tolist()
data = pd.read_csv("link.csv",usecols=["图片链接"])
data_array2 = np.array(data.stack()) # 首先将pandas读取的数据转化为array
self.img_list = data_array2.tolist() # 然后转化为list形式
# item['name'] = self.name_list
item['image_urls'] = self.img_list # 必须是img_urls,这是图片下载文件中有的
yield item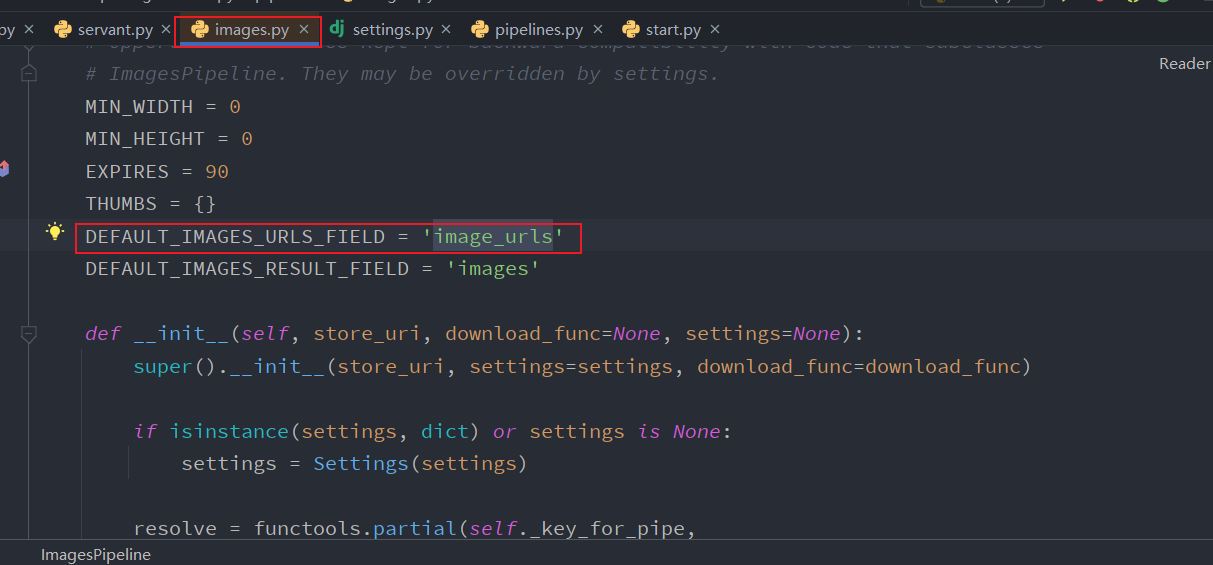
setting.py文件
IMAGES_STORE = 'FGO' # 没有会自动创建
ITEM_PIPELINES = {
# 'servant_pic.pipelines.ServantPicPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 300,
}管道文件不需要更改。
items.py文件
import scrapy
class ServantPicItem(scrapy.Item):
image_urls = scrapy.Field()结果
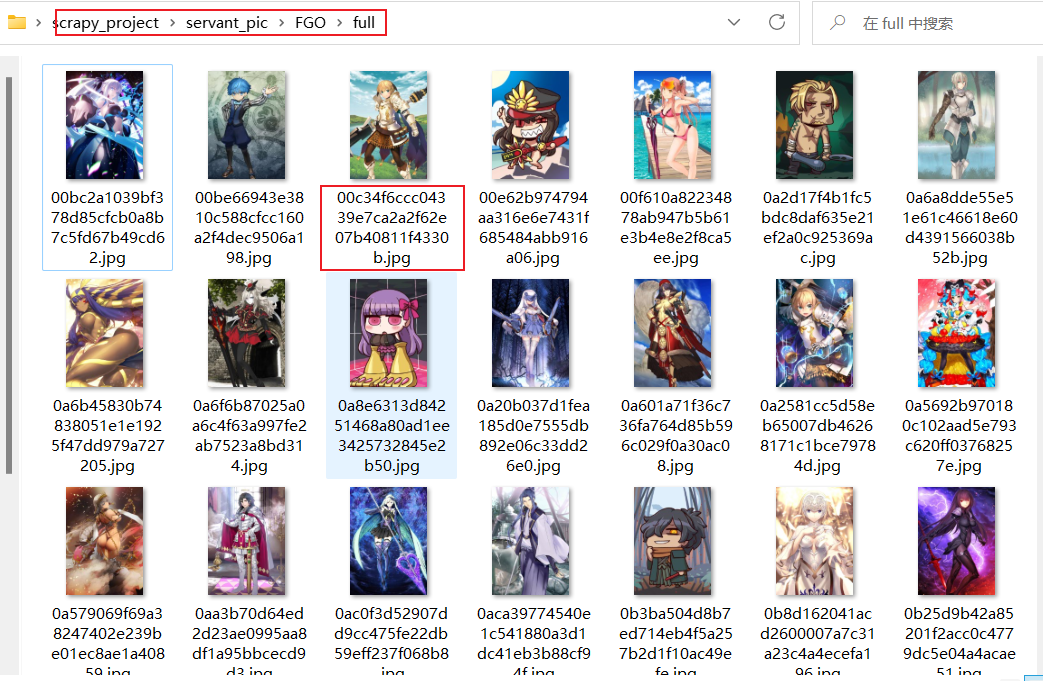
运行后会在本地工程下兴建一个FGO文件夹,子文件夹full,
full中为下载图片,命名为以图片URL的SHA1值进行保存的
通过 from scrapy.pipelines.images import ImagesPipeline管道下载,可以考虑自己重写,从而修改默认的方式
爬虫文件
"""scrapy异步下载图片"""
import scrapy
from selenium.webdriver import Chrome
from ..items import ServantPicItem
import pandas as pd
import numpy as np
from scrapy.pipelines.images import ImagesPipeline
class ServantSpider(scrapy.Spider):
name_list = []
img_list = []
name = 'servant'
start_urls = ['https://fgo.wiki/w/%E8%8B%B1%E7%81%B5%E5%9B%BE%E9%89%B4']
def parse(self, response):
item = ServantPicItem()
# 读取本地csv文件
data = pd.read_csv("link.csv",usecols=["图片名称"])
data_array1 = np.array(data.stack()) # 首先将pandas读取的数据转化为array
self.name_list = data_array1.tolist()
data = pd.read_csv("link.csv",usecols=["图片链接"])
data_array2 = np.array(data.stack()) # 首先将pandas读取的数据转化为array
self.img_list = data_array2.tolist() # 然后转化为list形式
# item['name'] = self.name_list
item['image_urls'] = self.img_list # 必须是img_urls,这是图片下载文件中有的
yield itemsetting.py文件
IMAGES_STORE = 'FGO' # 没有会自动创建
ITEM_PIPELINES = {
# 'servant_pic.pipelines.ServantPicPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 300,
}管道文件不需要更改。
items.py文件
import scrapy
class ServantPicItem(scrapy.Item):
image_urls = scrapy.Field()结果
运行后会在本地工程下兴建一个FGO文件夹,子文件夹full,
full中为下载图片,命名为以图片URL的SHA1值进行保存的
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号