CrowdStrike故障导致全球宕机事件始末
原创CrowdStrike故障导致全球宕机事件始末
原创
引言
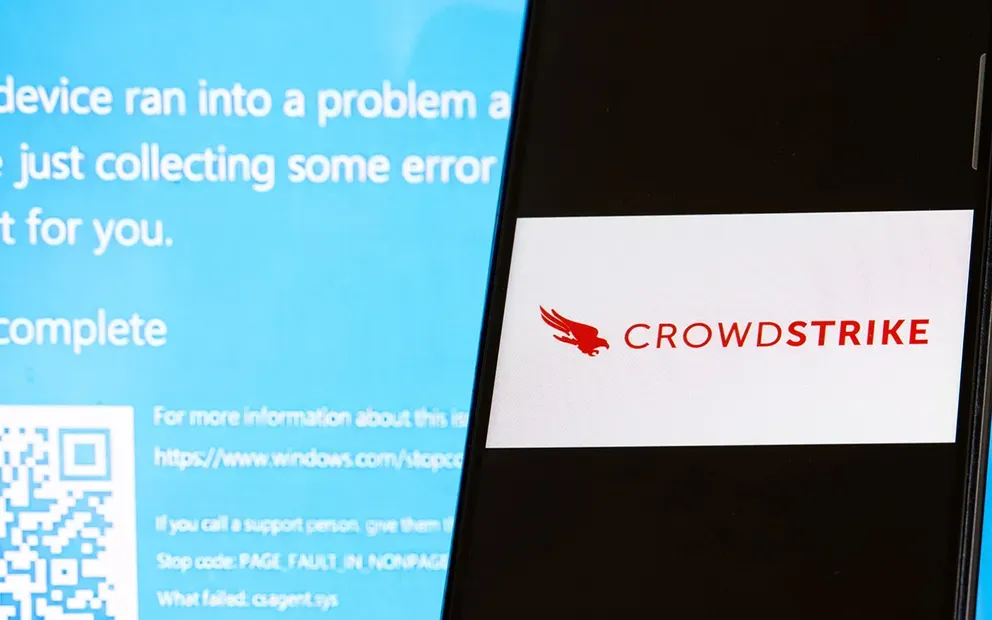
在网络安全领域,CrowdStrike作为全球领军安全公司之一,提供了先进的终端保护和威胁情报服务。然而,2024年7月的一场全球宕机事件揭示了即便是顶尖网络安全公司也会面临的技术和管理挑战。这场事件不仅对众多企业和组织造成了巨大影响,同时也暴露了复杂网络系统中的潜在脆弱性。本文将详细介绍此次故障事件的发生、技术细节分析及其带来的损失和启示。
事件背景
CrowdStrike简介
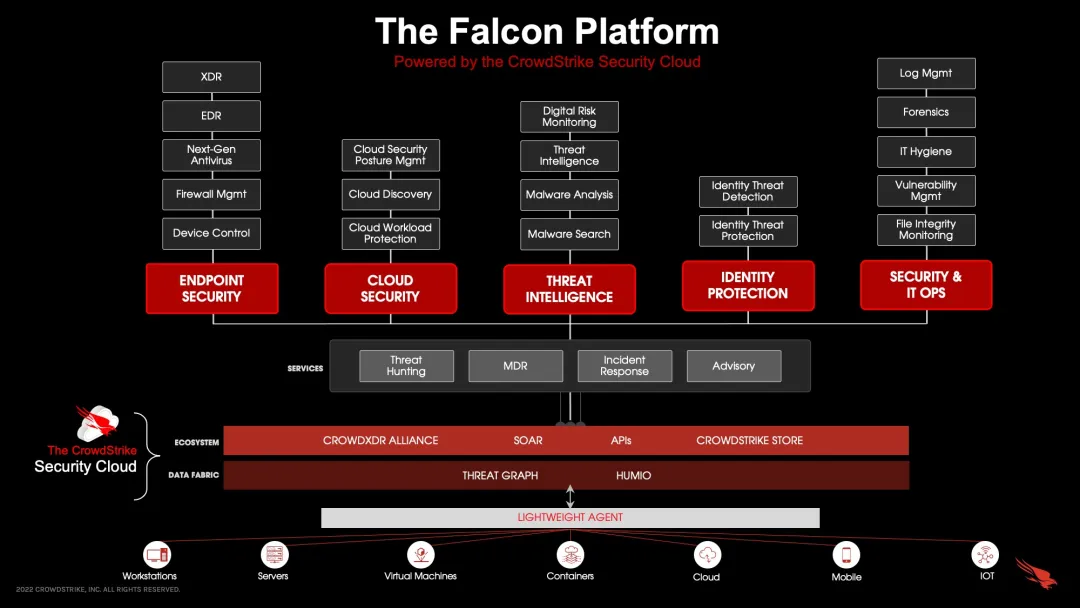
CrowdStrike成立于2011年,总部位于美国加利福尼亚州,其主要产品是基于云的终端保护平台——Falcon平台,通过实时威胁检测和响应服务,为政府机构、大型企业和中小型公司提供保护。
CrowdStrike的成功源于其创新的技术和对网络安全威胁的快速响应能力。Falcon平台利用机器学习和行为分析技术,能够实时检测和阻止各种复杂的网络攻击。正因如此,CrowdStrike的客户遍布全球,包括许多关键基础设施部门和大型企业。
事件背景
CrowdStrike提供一系列安全软件保护计算机免于网络攻击。旗下漏洞扫描器“猎鹰传感器”(Falcon Sensor)产品在个人电脑操作系统的内核层面安装端点侦测与响应Sensor,以检测和预防威胁。CrowdStrike会定期向客户分发补丁,使他们的计算机能够应对新的威胁。
- 2009年,微软与欧盟达成协议,要求微软必须向第三方安全软件开发商开放相关应用程序接口(API)。因此,包括CrowdStrike在内的安全软件均拥有系统内核级别的访问权限。
- 2024年7月18日,即在此次问题更新前,Microsoft Azure云服务发生异常,导致美国中部部分Azure用户无法访问其云存储及Microsoft 365服务。微软表示,两起事件并无关系,但对这些受影响公司的客户来说,问题却更加复杂。
- 2024年7月19日早上4时09分,部署在Azure的Windows虚拟机开始重启及崩溃,6时48分,Google计算引擎报告此问题。7时15分,Google宣布CrowdStrike更新存在问题。
- CrowdStrike首席执行官乔治·库尔茨确定此事由CrowdStrike的异常驱动更新造成,而非网络攻击。
此次事件引发了广泛关注,因为CrowdStrike的Falcon平台广泛应用于全球各地的关键基础设施和企业网络安全防护。许多企业依赖Falcon平台来检测和防御高级持续性威胁(APT),因此这次宕机事件对全球网络安全形势产生了深远影响。
技术分析
事件起因
根据CrowdStrike的自己发布的根因分析,此次事件的直接起因是一项Sensor配置更新的逻辑错误。简单来说,此次故障是由于在更新过程中,Falcon Sensor未能正确处理额外的输入值。这一错误使得系统在尝试访问超出预期范围的内存时发生崩溃。
Sensor的“内容解释器”模块在处理输入数据数组时,尝试访问第21个输入值,导致了内存越界读取。由于Falcon平台的Sensor运行在Windows内核模式下,具有高权限访问,可以访问和控制系统的所有资源,这一错误导致了系统级别的崩溃,最终引发了全球范围的宕机事件 。
故障处理
在发现问题后,CrowdStrike立即采取了修复措施,包括停止发布新的配置更新,并回滚了有问题的更新文件。此外,公司还启动了独立的第三方软件安全审查,评估Falcon平台的安全性和质量保证流程 。公司承诺将通过这一事件汲取教训,改进内部流程,防止类似事件再次发生 。
CrowdStrike的修复措施包括以下几个方面:
- 停止有问题的更新:立即停止发布和分发有问题的配置更新,防止更多系统受到影响。
- 回滚更新:对已经受到影响的系统进行回滚,恢复到更新前的状态。
- 独立审查:引入第三方软件安全公司对Falcon平台的代码和更新流程进行独立审查,确保不存在其他潜在漏洞和问题。
- 改进测试流程:加强内部测试和质量保证流程,确保每一次更新都经过严格的测试和验证,避免类似错误的发生。
影响与损失
业务影响
此次事件对全球多个行业产生了重大影响。尤其是航空业,Delta航空公司因系统崩溃取消了超过5000次航班,预计损失达5亿美元,此外,许多政府机构和大型企业也遭受了不同程度的业务中断,导致数据丢失和运营停滞,微软通报称,全球共有850万台设备受到影响。
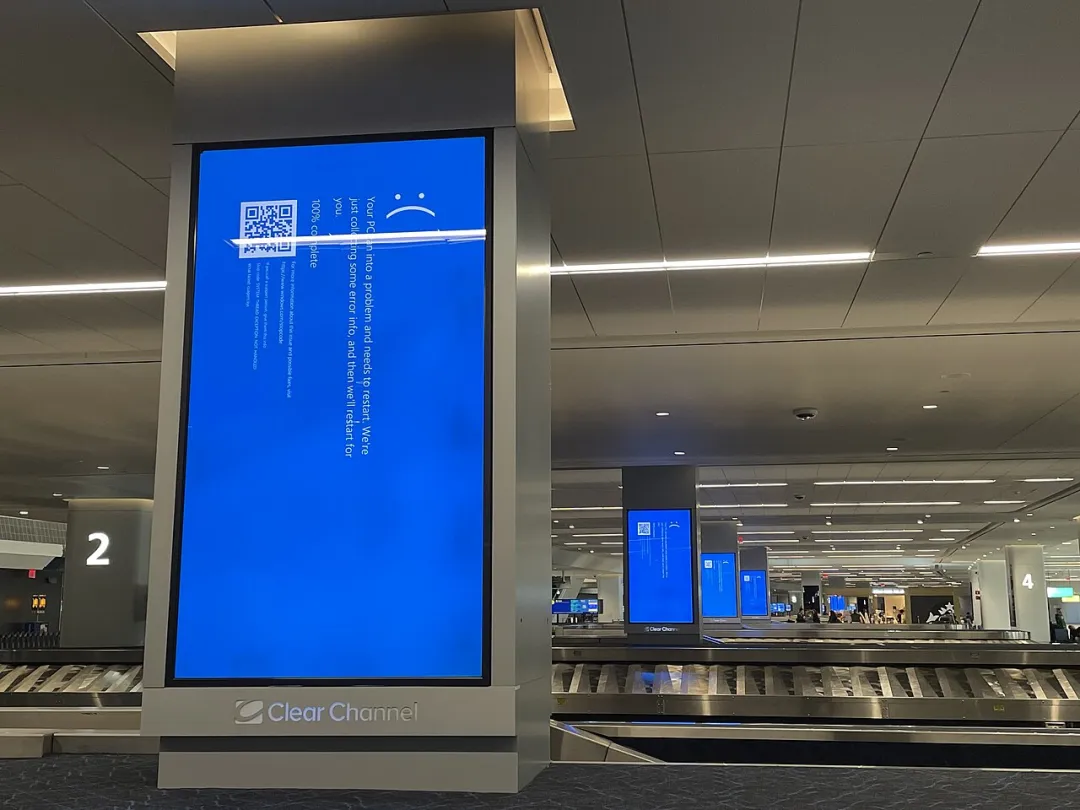
在宕机事件发生后,许多依赖CrowdStrike保护的企业和组织无法正常运行其关键业务系统。这不仅导致了直接的经济损失,还影响了客户信任和企业声誉。一些金融机构由于无法访问关键数据和系统,面临着交易中断和客户资金管理的问题。
经济损失
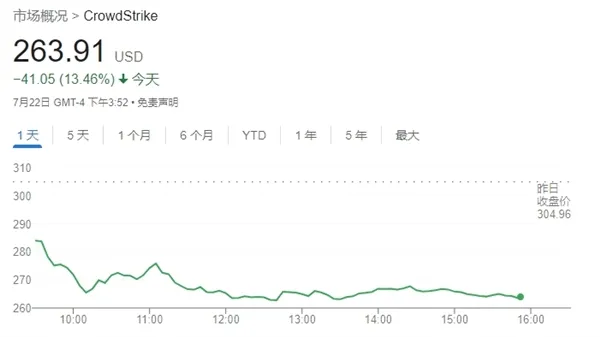
事件发生后,CrowdStrike的股票价格大幅下跌,在事件发生后的12天内(9个交易日),CrowdStrike股价大跌32%,市值蒸发超250亿美元,股东们称,CrowdStrike对其技术的保证存在重大虚假和误导性声明,公司的市场信誉受到了严重打击。受影响的企业和机构也面临着高额的损失,包括业务中断、客户流失和潜在的法律诉讼费用。
除了直接的业务中断损失外,企业还面临着修复系统和恢复数据的高昂成本。许多企业不得不紧急启动灾难恢复计划,调动大量人力和资源进行系统修复和数据恢复。这些额外的成本进一步加重了企业的经济负担。
此外,由于事件导致的广泛影响,许多企业可能会面临客户和合作伙伴的赔偿要求。例如,航空公司因航班取消和延误导致的乘客赔偿和退款成本将是巨大的。类似地,金融机构可能会因交易中断和客户资金管理问题面临客户的索赔和法律诉讼。
启示与反思
质量保证的重要性
此次事件暴露了在软件更新和配置管理过程中,质量保证和测试环节的关键性。为了避免类似事件的再次发生,企业必须加强对关键更新的测试流程,确保每一次发布的更新都经过严格的质量审查和验证。
软件质量保证(QA)是确保软件产品满足预期要求和标准的关键过程。在开发和发布软件更新时,必须进行全面的测试和验证,包括功能测试、性能测试和安全测试。通过严格的QA流程,可以发现和修复潜在的缺陷和漏洞,防止它们在生产环境中引发严重问题。
加强安全审查
此外,CrowdStrike在事件后采取了引入第三方安全审查的措施,这也是其他企业可以借鉴的做法。通过独立的安全审查,可以更早地发现潜在的安全漏洞和系统缺陷,从而降低系统崩溃的风险。
第三方安全审查提供了一个独立的视角,可以帮助企业识别和解决自身可能忽略的问题。安全审查通常包括代码审查、漏洞扫描和渗透测试等多个环节,旨在全面评估系统的安全性和可靠性。通过定期进行独立审查,企业可以持续改进其安全防护能力,降低遭受攻击和故障的风险。
系统弹性与恢复能力
最后,此次事件也提醒我们,企业在设计和维护关键系统时,必须考虑到系统的弹性和快速恢复能力。建立完备的应急响应计划,确保在发生意外故障时能够快速恢复和恢复业务,是每一个企业应当重视的工作。
系统弹性是指系统在遭受攻击或故障时,仍能保持正常运行或迅速恢复的能力。为了提高系统弹性,企业可以采取以下措施:
- 冗余设计:在关键系统中引入冗余设计,确保在某个组件故障时,其他组件能够继续正常工作。
- 灾难恢复计划:制定详细的灾难恢复计划,涵盖从故障检测到系统恢复的每一个步骤,确保在发生故障时能够迅速采取行动。
- 定期演练:定期进行应急响应演练,测试和优化灾难恢复计划,提高团队在实际故障中的应对能力。
- 数据备份:实施定期的数据备份策略,确保在数据丢失时能够迅速恢复到最新的状态。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
腾讯云开发者
