拟某款抽卡FPS手游封测调研报告
原创
拟某款抽卡FPS手游封测调研报告
原创
用户11196524
发布于 2024-10-18 18:45:31
发布于 2024-10-18 18:45:31
数据准备
背景:6月份整个月的数据,其中更新日期为 2024-06-14
6月份封测包括两张表:
表一:usr_info_list 包括用户的基本信息
表二: detail_usr_comsume_list 详细消费信息表:
数据由python生成的tsv数据提供:
- 表一 usr_info_list :
包括用户名uid、 手机号phone 、所在城市city、 性别gender、 年龄age、 游戏内的等级levels、 月度消费usr_amount 、以及用户最常用的3种社区forums
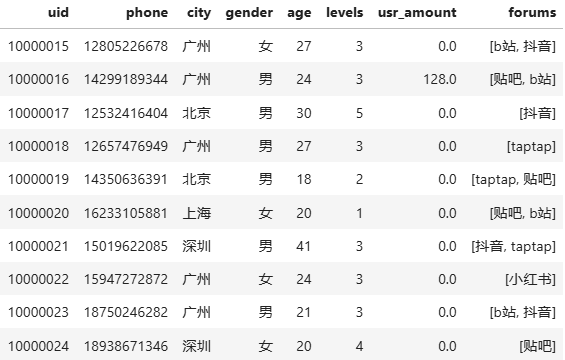
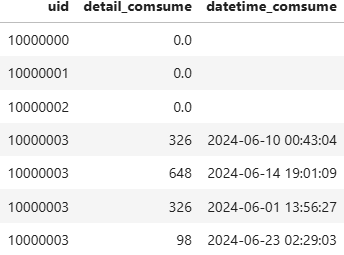
- 表二、 detail_usr_comsume_list :
用户uid、单笔消费金额detail_comsume 、发生消费的时间datetime_comsume
建表部分
使用以下语句将表一和表二生成数据库表
create table if not exists usr_info_list(
uid string,
phone string,
city string,
gender string,
age int,
levels int,
usr_amount float,
forums string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
with serdeproperties(
"input.regex" = "([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t([^\\t]*)\\t\\[([^\\t]*)\\]"
);
create table if not exists detail_usr_comsume_list(
uid string,
consume float,
usr_datetime string
)row format delimited
fields terminated by '\t';
load data inpath "hdfs://node_main:8020/user/tmp/proj4/usr_info_list.tsv" into table usr_info_list;
load data inpath "hdfs://node_main:8020/user/tmp/proj4/detail_usr_comsume_list.tsv" into table detail_usr_comsume_list;数据查询前的配置调优工作
1、确认hadoop与hive环境中堆栈的大小是否合适
hadoop-env.sh
export HADOOP_HEAPSIZE_MAX=6144
export HADOOP_HEAPSIZE_MIN=4096hive-env.sh
export HIVE_HEAPSIZE=20482、需要设置hiveserver2的高可用性与内存配置
hive-site.xml
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>3、开启动态插入与查询优化相关的配置
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.groupby.skewindata=true;
set hive.stats.column.autogather=false; HIVE分析部分
计算流水信息
create table general_tb as
select *,(usr_cnt-pay_cnt) as not_pay_cnt
from(
select sum(usr_amount) as GMV,
avg(usr_amount) avg_amount,
count(uid) usr_cnt,
sum(if(age>17,1,0)) as adult_cnt,
count(if(usr_amount>0,1,NULL)) as pay_cnt
from usr_info_list
)t;按日期时间分层
-- 费总额
create table comsume_per_date as
select usr_date,
if(dayofweek(usr_date)=1,7,dayofweek(usr_date)-1)as week_day,
sum(consume) as day_consume
from(
select uid,consume,date(usr_datetime) as usr_date
from detail_usr_comsume_list
where consume >0
)t
group by usr_date
order by usr_date asc;-- 计算每小时的总消费额,平均消费额
create table comsume_per_hour as
select hour(usr_datetime) as hour,count(*) as cnt,
round(avg(consume),1) as avg_consume,
sum(consume) as sum_consume
from detail_usr_comsume_list
where consume>0
group by hour(usr_datetime);powerBI新建度量值
更新日 = CALCULATE(sum(comsume_per_date[day_consume]),FILTER(comsume_per_date, comsume_per_date[usr_date] in {DATE(2024,06,14),DATE(2024,06,15),DATE(2024,06,16)}))
更新日之外 = CALCULATE(sum(comsume_per_date[day_consume]),FILTER(comsume_per_date,not comsume_per_date[usr_date] in {DATE(2024,06,14),DATE(2024,06,15),DATE(2024,06,16)}))
工作日消费 = CALCULATE([更新日之外],'comsume_per_date'[week_day] in {4,3,2,1})
周末消费 = CALCULATE([更新日之外],'comsume_per_date'[week_day] in {5,6,7})
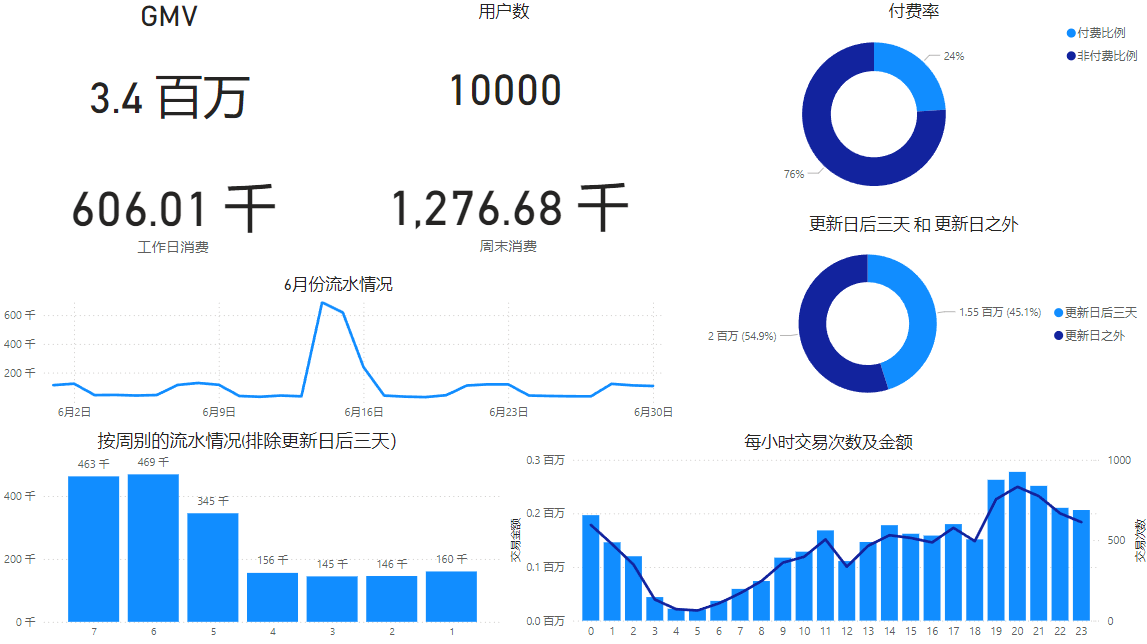
add_rate = [周末消费]/[工作日消费]通过ODBC连接HIVE数据库,输出总体概况面板
活动策划部门
- 游戏产能投放建议
- 6月份流水集中在六月中旬已知活动更新日期为6月14日,其余时间规律性波动且平稳。版本更新后三天的流水占一个月总流水的47% ,可以此估算当月总体情况。可以考虑变更更新策略:适当增加新活动,加快更新频率保持每月较高的流水。
- 周末的付费水平超出工作日的2倍,活动预热可以放在工作日初周末前,保证周末有充足的玩家上线。
- 用户在晚上7点开始到11点的交易额达到高峰,建议版本宣发时间调整至周末,并且在晚上7点前完成游戏的更新维护工作。考虑到可能出现的BUG,建议预留时间。
外部拉新部分:
按照性别分组
-- 男性和女性玩家的平均消费额和总消费额
create table gender_info as
select gender,count(*),
round(avg(usr_amount),1) as avg_amount,
round(sum(usr_amount),1 )as sum_amount
from usr_info_list
group by gender;按照年龄段分组
-- 按照年龄段分类,计算所定义的年龄段tag的数量,人均消费和总消费
create table if not exists ages_info as
select age_tag,count(uid) as usr_cnt,
round(avg(usr_amount),1) as avg_amount_per_tag,
sum(usr_amount) as sum_amount_per_tag
from(
select
case when age < 16 then '少年' when age between 16 and 21 then '青少年'
when age between 22 and 35 then '年轻工薪青年'
when age between 36 and 50 then '中年'
else '老年' end as age_tag,usr_amount,uid
from usr_info_list
)t
group by age_tag;按照城市分组
-- 按年龄分组后计算男性和女性玩家的数量以及总消费、平均消费
select city,count(uid) as city_cnt,sum(usr_amount) as city_amount
from usr_info_list
group by city按照社区分组
-- 拆开原有的社区列,每种社区单独计算
-- 计算每个社区的如人均年龄、等级、总消费、平均消费以及男女占比
create table forums_info as
select parts,
sum(if(gender='男',1,0)) as male,sum(if(gender='女',1,0)) as female,
count(city) city_cnt,
round(avg(age),1) as avg_age,
round(avg(levels),1) as avg_level,
round(avg(usr_amount),1) as avg_amount,
round(sum(usr_amount),1 )as sum_amount
from usr_info_list lateral view explode(split(forums," ")) fm as parts
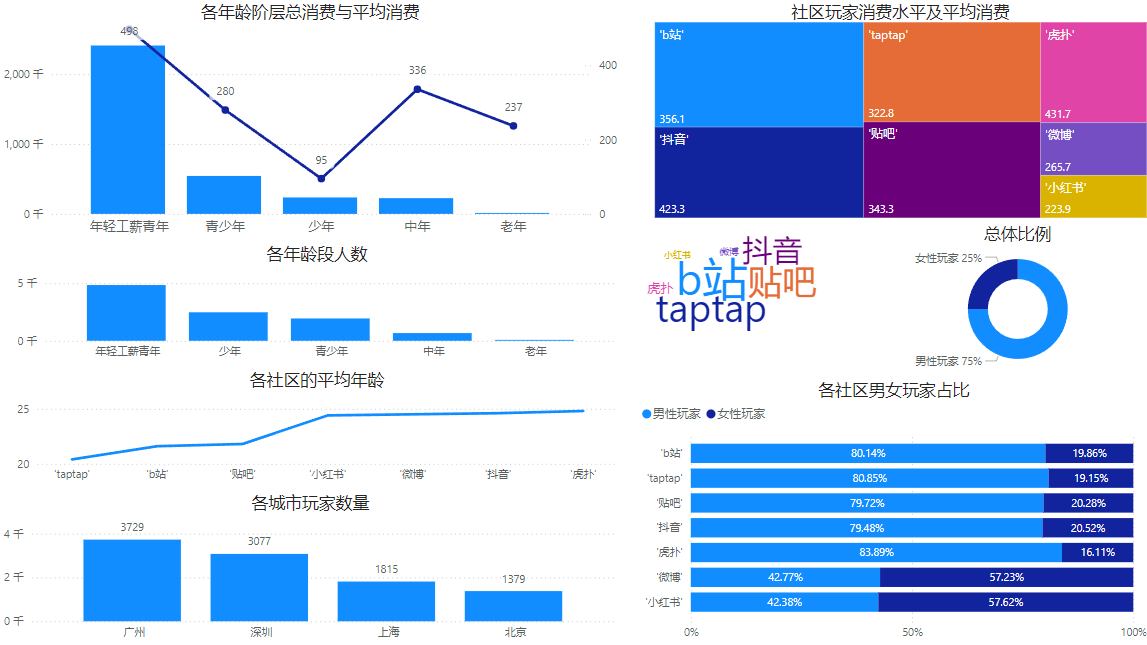
group by parts;输出到powerBI:
市场宣传部门
【各年龄阶层总消费与平均消费]】中,总消费和平均消费最高的是年龄在22~35的工薪青年
【各年龄段人数中】中,来看也是35岁以下的年轻人为主体
【各社区年龄段】中, B站,taptap、贴吧、抖音流媒体居多,其中B站,taptap、贴吧的使用人群更年轻
【社区玩家消费水平及平均消费】中,也是以B站,taptap、贴吧、抖音的指标为优
最后根据【各社区男女占比】与【总体比例】可知,玩家的主体为男玩家
结合上述内容,最典型的玩家特诊为年龄在22~35岁活跃在B站,taptap、贴吧的男性工薪青年,如果进一步扩展年龄,可以把目标放在16~21青少年,这部分人群数量更多,人均消费高,消费欲望较强,并且年龄与工薪青年在社区上有更多的共同点
另外,玩家数量集中在广东、深圳,按照城市体量来说上海和北京仍有挖掘空间,可加大宣传投入
内部转化部分:
按等级分层
-- 按照游戏等级计算总消费和平均消费
create table level_info as
select levels,count(*)as lv_cnt,
round(avg(usr_amount),1) as avg_amount,
sum(usr_amount) as sum_amount
from usr_info_list
group by levels;进一步的人群分析
根据各自指标中间的25%~75%均值作为判断高低的指标
R(Recency)
select avg(R) as avg_R
from(
select *,row_number() over (partition by R) as rank_R
from(
select uid,datediff('2024-07-01',max(usr_datetime)) as R
from detail_usr_comsume_list
where consume>0
group by uid
)t
)tt
where rank_R between 600 and 1800;F(Frequency)
with tb1 as(
select uid,count(usr_datetime) cum_cnt
from detail_usr_comsume_list
where consume>0
group by uid
),
tb2 as(
select uid
from(
select uid,cnt_rank
from (
select uid, row_number() over (order by cum_cnt) as cnt_rank
from tb1
)t
where cnt_rank between 600 and 1800
)tt
)
select avg(cum_cnt) as avg_F
from tb1
where uid in (select uid from tb2);M(Monetary)
with tb1 as(
select uid,sum(consume) cum_sum
from detail_usr_comsume_list
where consume>0
group by uid
),
tb2 as(
select uid
from(
select uid,cum_rank
from (
select uid, row_number() over (order by cum_sum) as cum_rank
from tb1
)t
where cum_rank between 600 and 1800
)tt
)
select avg(cum_sum) as avg_M
from tb1
where uid in (select uid from tb2);生成用户tag表格
create table pay_usr_tag as
with tb as (
select uid ,
datediff('2024-07-01',max(usr_datetime)) as R,
count(usr_datetime) as F,
sum(consume) as M
from detail_usr_comsume_list
where consume>0
group by uid
)
select *,case
when R < 16 and F >2 and M>=682 then '重要价值用户'
when R < 16 and F <=2 and M>=682 then '重要发展用户'
when R >=16 and F >2 and M>=682 then '重要保持用户'
when R >=16 and F <=2 and M>=682 then '重要挽留用户'
when R < 16 and F >2 and M<682 then '一般价值用户'
when R < 16 and F <=2 and M<682 then '一般发展用户'
when R >=16 and F >2 and M<682 then '一般保持用户'
when R >=16 and F <=2 and M<682 then '一般挽留用户'end as usr_tag
from tb;create table usr_tag_info as
select usr_tag,count(*) as cnt,sum(M) as sum_amount
from pay_usr_tag
group by usr_tag;
create table point_usr_info as
with tb1 as
(
select uid
from pay_usr_tag
where usr_tag='重要价值用户'
)
select parts,
round(avg(usr_amount),1) as avg_amount,
round(sum(usr_amount),1 )as sum_amount
from usr_info_list lateral view explode(split(forums," ")) fm as parts
where usr_info_list.uid in (select tb1.uid from tb1)
group by parts;计算度量值
重要价值用户消费占比 = CALCULATE(SUM(usr_tag_info[sum_amount]),usr_tag_info,usr_tag_info[usr_tag]="重要价值用户")/sum('usr_info_list_pt'[usr_amount])
前三占比 = CALCULATE(sum(usr_tag_info[cnt]),usr_tag_info[usr_tag] in{"重要价值用户","一般挽留用户","一般发展用户"})/sum(usr_tag_info[cnt]) 输出到powerBI:
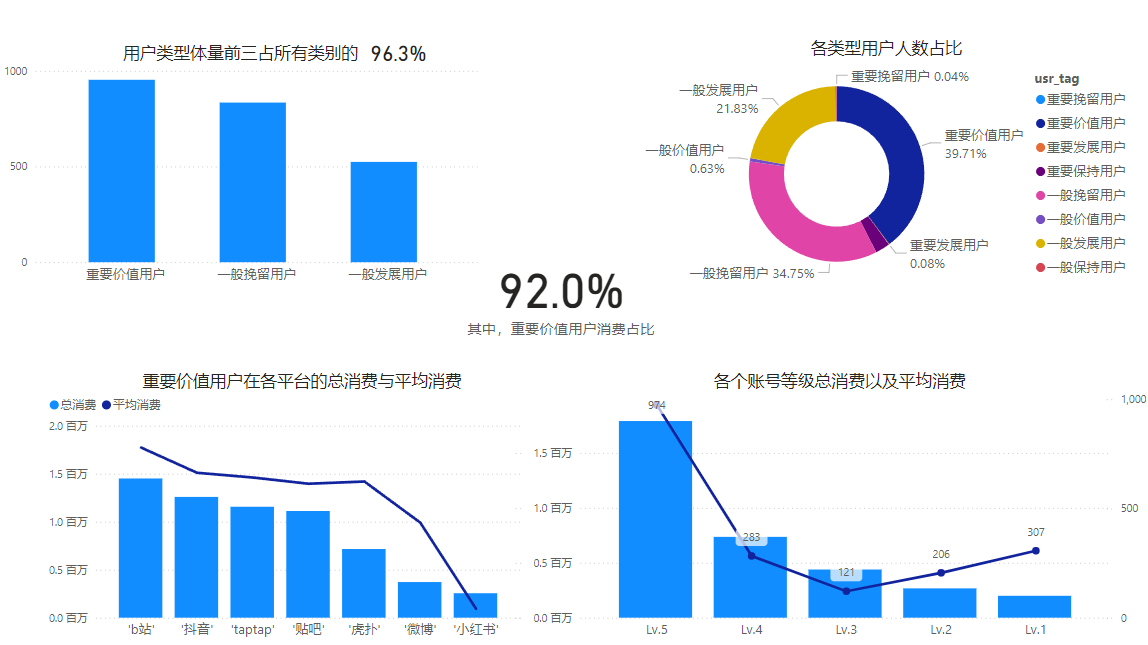
游戏运营部门
根据RFM构成圆环图。可以看到体量前三的用户占总体的96%分别是:重要价值用户、一般挽留用户、一般发展用户。
其中 重要价值用户一类占比40%但消费占总体的90%,与优质渠道(b站,抖音,taptap,贴吧)吸引过来的人群特征相符,新增的用户保持以往的运营方式即可,证明现今的付费内容对高频大额消费的玩家是合适的
一般挽留用户与重要价值用户体量相当,一般发展用户也占了较大比例。用户转换上还有很大的挖掘空间,对这两类人群有以下优先级:
- 虽然一般挽留用户的人数更多,但是考虑转换成本问题,可以优先从一般发展用户入手,增加消费频次F,使其转换为一般价值用户,后期逐渐诱导提高消费金额。例如新增内购,如皮肤,特效等。
- 一般挽留用户,RFM值都比较低,可以先刺激近期进行一次消费,使其转换为一般发展用户,后期逐渐诱导增加消费频次。首购优惠,更新月卡礼包等,引导首次消费和定期消费
根据【账号各等级总消费及平均消费】。在游戏内的游戏等级的表现来看:玩家等级越高在消费能力越强,人均消费即消费欲望方面在图上呈现两边高中间低的情况,LV1的消费欲望仅次于最高的LV5,可能是中间的体验过程由问题导致消费较少,建议在玩期中期插入玩家体验的调查问卷。
(以上数据特征由python权值设置后自动生成,生成代码后续更新)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号