国产大模型如何追上OpenAI
原创

目前看,算力其实不是一个比较大的瓶颈,数据的有效性才是大模型能力提升的关键。
比如最近的deepseek V3一发布,大家就发现其实能够用很低的成本就能够训练出一个媲美GPT
-4o的模型。DeepSeek V3的训练总共才用了不到280万个GPU小时,而Llama 3 405B却用了3080万GPU小时。用训练一个模型所花费的钱来说,训练一个DeepSeek V3只需要花费557.6万美元,相比之下,一个简单的7B Llama 3模型则需要花费76万美元。
目前看,算力其实不是一个比较大的瓶颈,数据的有效性才是大模型能力提升的关键。
比如最近的deepseek V3一发布,大家就发现其实能够用很低的成本就能够训练出一个媲美GPT
-4o的模型。DeepSeek V3的训练总共才用了不到280万个GPU小时,而Llama 3 405B却用了3080万GPU小时。用训练一个模型所花费的钱来说,训练一个DeepSeek V3只需要花费557.6万美元,相比之下,一个简单的7B Llama 3模型则需要花费76万美元。
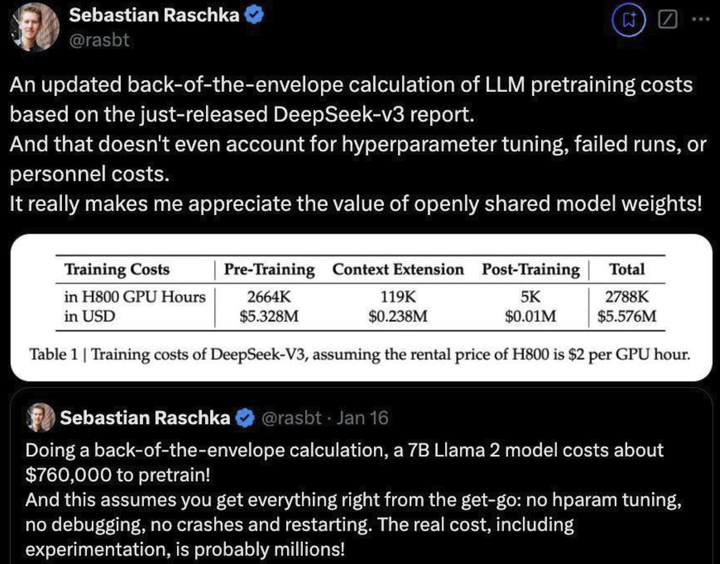
从论文中的公布细节可以得到它的训练成本估算:
- 以 H800 GPU 小时为单位。H800 GPU 的租赁价格假定为每小时 2 美元。
- 训练分为三个阶段:预训练、上下文扩展和后期训练:
- 预训练:使用了 2664K(266.4 万)GPU 小时,成本约为 532.8 万美元。
- 上下文扩展:使用了 119K(11.9 万)GPU 小时,成本约为 23.8 万美元。
- 后期训练:使用了 5K GPU 小时,成本约为 1,000 美元。
- 总成本:2788K(278.8 万)GPU 小时,总费用为 557.6 万美元。
比起动辄几百亿人民币都训练不出来一个好用的大模型,DeepSeek V3的训练简直颠覆了大家的想象。这里训练这么省钱当然主要是因为该模型原生就是FP8,还有在模型架构上做了一些优化导致模型训练成本很低。
为什么会这么省钱?
DeepSeek V3除了使用了FP8之外,还有一些其他的模型细节。比如它继续采用了多头潜在注意力(MLA)来实现高效推理。它在传统多头注意力机制(Multi-Head Attention)的基础上,引入了潜在特征(Latent Features)概念,进一步提高了对复杂关系的建模能力。
也就是先把token的特征压缩成一个小维度的latent vector,然后再通过一些简单的变换把它扩展到各个头需要的Key和Value空间。对于一些重要的信息,比如旋转位置编码RoPE,会进行单独处理,这样网络仍然可以保留时间和位置的信息。
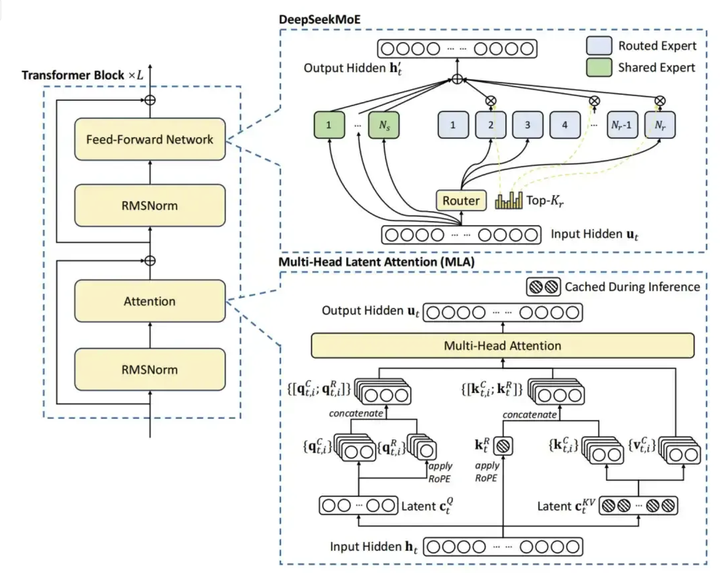
在MOE架构中,引入了路由专家 (Routed Experts) 和共享专家 (Shared Experts) 。主要是用来激活那些参数需要被更新。
路由专家中主要是用来选择参数进行激活。对于每个输入的token,只有一部分路由专家会被选中来参与计算。这个选择过程是由一个门控机制决定的,比如DeepSeekMoE中用的那种根据亲和度分数来选的Top-K方式。
而共享专家始终参与所有输入的处理。无论输入是什么,所有共享专家都会贡献它们的力量。
还用到了一个MTP(多个tokens预测)技术,MTP的核心理念在于训练时,模型不仅要预测下一个token(就像传统语言模型那样),还要同时预测序列后面的几个token。这样一来,模型就能获得更丰富的训练信息,有助于它更深入地理解上下文以及长距离的依赖关系。
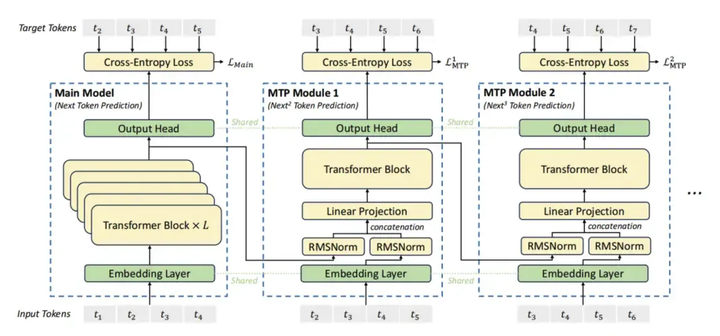
通过上面几个简单的trick,就可以很好的训练出一个质量不出的大模型出来,并且能够和GPT-4o和Claude 3.5相媲美。这个工作给很多公司提供了新的思路。其高效的训练方法和较低的计算成本,可以给其他没有资源的公司借鉴一下,也验证了大规模的GPU集群不是训练大模型的必要条件。
数据集才是关键?
之前就曾经有爆料称,OpenAI的下一代大模型效果不及预期。其下一代模型“猎户座”(Orion),对比于GPT-4来说提升效果不明显,同时还存在GPT-4上的一些明显错误。这可能就说明,为什么迟迟不出来GPT-5了,因为提升幅度有限,所以把GPT-5改名成立了Orion

目前最主流的说法认为,大模型的scaling raw正在慢慢失效,也就是目前的大模型尽管有着大量的数据集进行训练,但是其能力却没有大规模的提升,体现出了Scaling raw在慢慢失效。
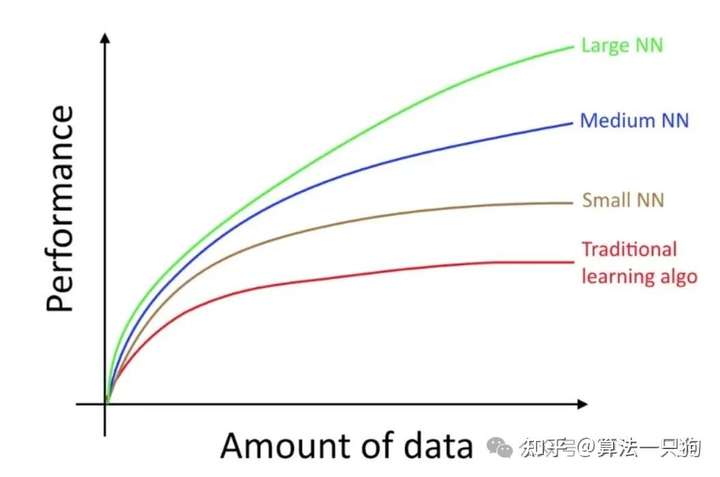
为什么会导致性能提升有效呢?主要是现在大模型所需要的大规模数据集已经耗尽了,高质量的数据集其实没有多少。
OpenAI就为此创建了一个“基础团队”,主要研究怎么合成高质量的数据,提供给大模型进行学习。而如果能够源源不断的提供给大模型一个高质量的数据集,那么确实有可能会进一步提升
要生成高质量的数据,目前常用的方法是通过一个在相关内容上进行过预训练的大语言模型生成合成数据。具体来说,生成过程通常是基于少量的真实数据,编写一组特定的 prompt,再经由生成模型生成具有针对性和高质量的合成数据。
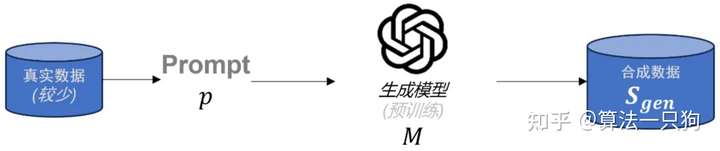
但是这种生成数据的方法会有两个明显的问题。
- 一个是信息增益有限:合成数据的有效性在于其为模型提供了新的信息。如果合成数据与原始数据过于相似,信息增益有限,模型的泛化能力提升也会受限。
- 另一个是数据质量控制困难:合成数据的质量直接影响模型的性能。生成高质量的合成数据需要精确的建模和丰富的先验知识,确保合成数据在多样性和真实性上与真实数据相匹配。
所以目前怎么大规模合成高质量的数据,使得scaling raw持续发挥作用,是OpenAI需要急切解决的问题。
写在最后
其实国内的大模型能够追上来,算力落后不是一个关键,更为关键的原因在于能否获取到有用的数据集,来进一步提升模型的效果。往往一个质量较高的数据集对于模型的提升作用更大,这也就为什么OpenAI也一直尝试合成高质量的数据,毕竟目前人类的数据其实已经用透了,想要再一次提升大模型的效果,只能另辟蹊径,搞出一个更纯的数据集出来才行。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号