Meta AI研究员、英伟达工程师称赞的数据分析工具DataLab是什么

Meta AI研究员、英伟达工程师称赞的数据分析工具DataLab是什么

腾讯大数据
发布于 2025-02-05 11:02:55
发布于 2025-02-05 11:02:55
近日,腾讯大数据发布在arXiv的一篇学术论文《DataLab: A Unified Platform for LLM-Powered Business Intelligence》引起了各界同仁的广泛关注,前Meta AI研究员在推特和领英上分享该论文,同时又有领域大V相继转载,使得DataLab被推到了大数据领域的风口浪尖。

此次分享带动了外网AI研究员对于此文章的热烈讨论,评论区不乏有称赞"系统架构图很酷,agent通信机制设计的不错"的英伟达工程师,以及称赞"DataLab看起来比DataBricks Mosaic AI更优秀"的用户

我们回归到DataLab,它是腾讯大数据自研的,以大语言模型驱动的大数据智能体为基础,连接Python、SQL、Pyspark等多种常用的数据分析语言的智能数分与数科工具,同时后续本文将针对DataLab的技术方案进行概览性介绍。
01 什么是AI驱动的智能分析
商业智能分析通常涉及数据准备、数据分析、数据可视化等多个环节,需要数据工程师、数据科学家、数据分析师等各种角色借助不同数据工具(例如代码开发工具、可视化创作工具等)来合作完成。
最近,大模型智能体(LLM-based Agents)依靠其强大的自然语言推理和外部工具调用能力,已能自动化完成许多BI任务,极大降低了用户负担和准入门槛。然而,现有相关工作大多局限于单个任务(例如NL2SQL, NL2VIS等),未将BI流程作为整体来考虑,这种分离增加了沟通成本、决策延迟和潜在错误。为了实现完整的BI流程,企业内不同角色需要通过定期会议、Wiki文档等方式进行反复对齐,整合不同数据工具上的工作流,因此效率往往较低。
为了应对这一问题,腾讯大数据研发团队参考国内外公司成熟的相关解决方案(例如Databricks, Hex等),并结合公司内的自有技术积淀和应用实践,提出DataLab——一个一站式数分与数科工具,通过大模型多智能体框架来统一BI流程,满足不同数据角色的各种任务需求。
02 DataLab的整体架构
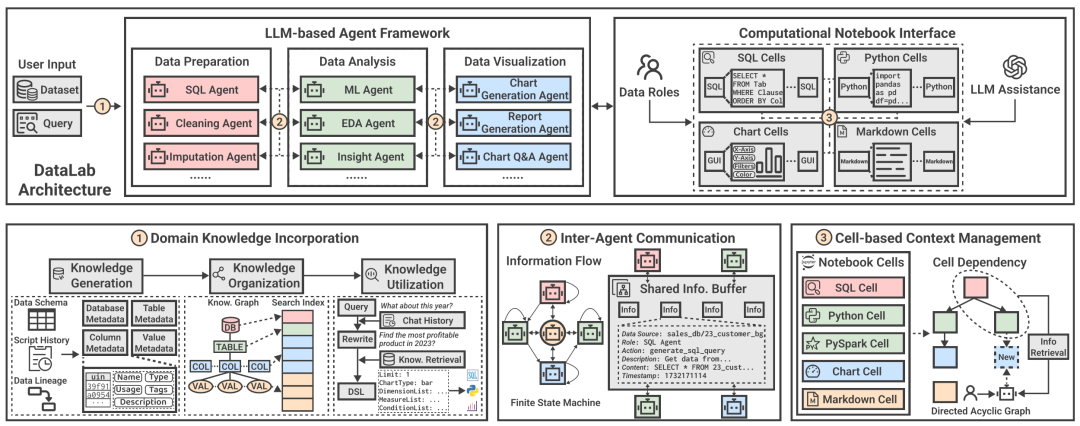
[DataLab整体架构图]
DataLab通过协调多个能够调用各种数据工具(Data Function Calling)的智能体,从而完成各种数据分析任务。研发团队将整个AI辅助分析的环节拆分为数据准备->数据分析->数据可视三步:
● 在数据准备环节,设计知识组织智能体,基于非结构化的元数据、数据血缘、查询SQL数据,构建领域知识图谱。
● 在数据分析环节,构建SQL/Python/Pyspark代码沙盒环境,直接连通底层Hive数据库,从而进行快速、高效、安全、隐私保护的代码执行。
● 在数据可视环节,基于指标维度分析的常用BI DSL协议,结合图表渲染工具(ECharts, VegaLite),构建自然语言交互的实时可视化智能体。
三个环节的技术细节如下:
领域知识注入模块
为了让大语言模型模型学到指标、维度、业务黑话、计算公式等大数据特殊领域知识,设计知识生成、知识组织和知识利用三个环节。
知识生成:以数据表Schema,它所关联的脚本历史流水(例如用于数据处理的SQL和Python脚本),以及该表的血缘信息作为输入。其中,数据表Schema提供表名、列名及其类型;脚本历史流水由领域专家创建,在公司内定期执行,可以深刻反映数据表的语义信息和常见用法;血缘信息包含整个公司内相关上下游数据表的元数据,可以作为知识生成的补充来源。
知识组织:借助大模型以Map-Reduce的方式自动生成数据库级/表级/列级的知识,并以结构化形式存储在知识图谱中。
知识利用:基于知识图谱设计RAG方案,通过粗排、精排、维度码值匹配等环节,召回与用户的自然语言问题相关的知识,并基于知识将用户问题改写为一个以JSON结构表达的BI DSL实例,从而应对用户输入的歧义、模糊、指代问题。
智能体构造
研发团队将大数据智能体分为三类:工具调用智能体(Function Call),角色扮演智能体(Role Play),以及代理规划智能体(Proxy Planner)。其中,每个BI智能体被表示为一个有向无环图,通过低代码的方式进行构建。
角色扮演智能体主要用于问题改写、意图分发、参数提取等固定输出格式的模块。
工具调用智能体基于改写后的用户问题,调用合适的数据工具(代码生成、代码执行、图表绘制、时序分析、异常检测),完成用户意图。
代理规划智能体将复杂的用户请求拆解为若干子任务,自动分配给相应的智能体,并监控任务的整个过程,防止循环调用、错误复述、链路遗忘等问题。
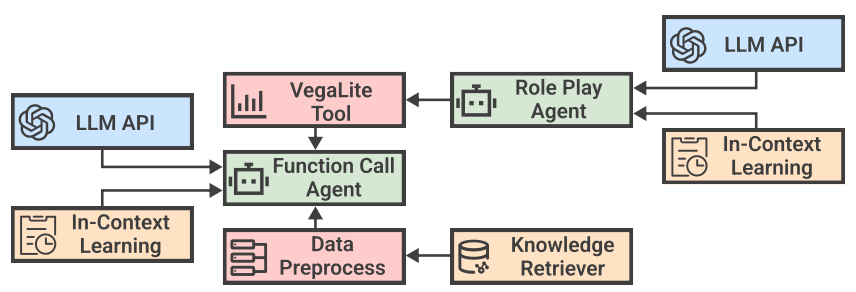
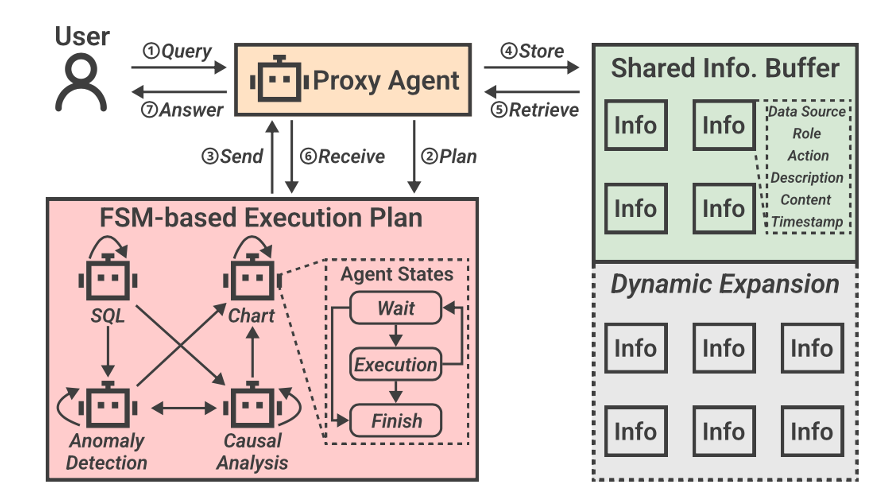
多智能体通信模块
研发团队将不同智能体之间的信息共享过程建模为一个有限状态机,并借助结构化信息和共享信息池的方式以系统化、结构化的方式处理智能体间的通信模式:
● 当接收到用户请求后,代理智能体自动生成一个以有限状态机形式表示的执行计划,并将子任务分配给不同的BI智能体。
● 在整个任务周期,代理智能体动态监控其他智能体的子任务完成情况,将它们的输出以结构化形式存储在共享信息池中,并根据当前任务状态从池中召回信息传递给相应的智能体,以促进子任务的进一步执行。
● 当所有子任务都已完成并且足以解决用户请求时,代理智能体总结并生成最终结果返回给用户
多模态Notebook
DataLab支持SQL, Python, Chart和Markdown四种类型的Cell,将不同用户的任务需求分为两个层级:
● Cell层面的协助,例如单个Cell内的代码修改
● Notebook层面的协助,例如直接根据用户意图创建新的Cell
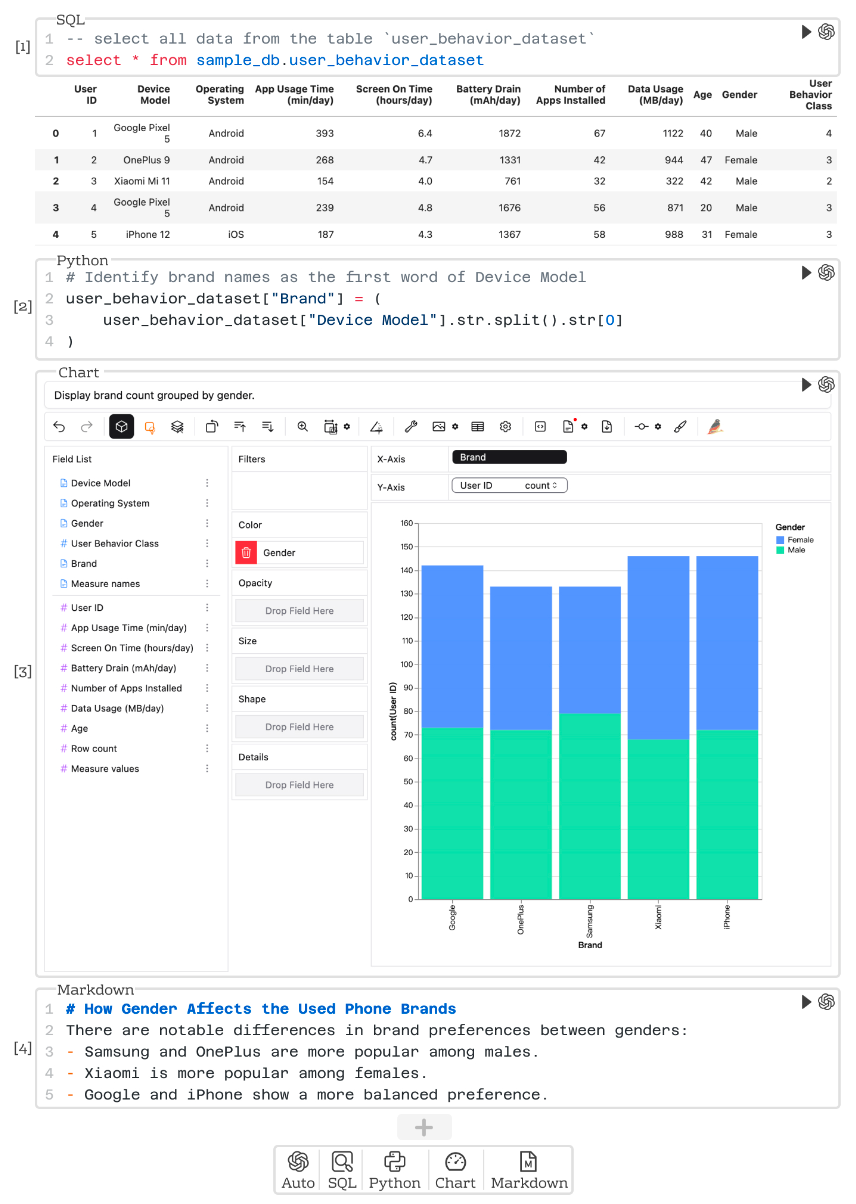
为了精准定位整个分析周期所需要的信息,研发团队构造了基于Cell的上下文管理模块,生成Notebook中Cell依赖关系的有向无环图,提取与用户请求相关的最小Cell子集,并过滤无关内容。结合共享信息池,模块可以高效提供完成请求所需的最小上下文。
03 实验评估
为了全面评估DataLab平台在BI流程中的有效性,研发团队同时利用学术界的标准基线和公司内部的工业数据集进行实验。
实验结果表明,利用领域知识注入与多Agent协作功能,在SQL生成(NL2SQL),数据洞察(NL2Insight)以及数据可视化(NL2Vis)场景,DataLab在公开测试集中都达到了SOTA的结果。
腾讯大数据落地的真实业务场景中,DataLab的元数据增强模块对比基线,在找库找表任务上达到了38个点的准确率提升;在BI DSL生成任务上达到了58个点的提升。
此外,得益于上下文管理模块,DataLab在达到与SOTA方法接近的准确率时,可以减少61%的Token调用。
更多实验结果可以参考论文原文。
04 难点讨论
在社区讨论中,大家都比较关心的问题有两点:
1. 如何让BI分析Agent适应各种领域知识(Domain Specific Knowledge)
2. 如何适应业务中遇到的各种脏数据以及不规范的表格(messy incomplete data)
针对第一点,研发团队设计领域知识注入模块,基于用户的日常数据分析流水(常用库表、执行/调度SQL、血缘信息),构造库级、表级、字段级、维表级以及算子级的知识,并将知识清理为可检索的图谱,通过RAG方法对用户问题进行改写增强;
针对第二点,研发团队结合PowerBI、Pandas等著名分析工具,在分析前对表格和字段进行清洗与概览,为每个字段自动推断类型,涵盖日期、时分秒、ID、数值、维度、码值等常用类型,并完成空字段合并、缺失值处理、字段命名补全等前置操作。在完成清洗研发团队针对不同类型,训练模型为不同的字段类型,产生特定的行为与分析逻辑。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-12-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号