【数据结构与算法】之有序链表去重(保留重复元素)



相关教程:
1.问题描述
给定一个已排序的单链表的头节点 head,要求去除链表中重复的元素,并返回新的头节点。每个重复元素只保留一个。
图一:
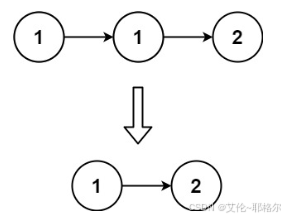
图二:
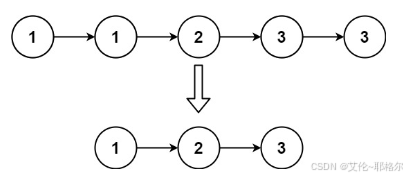
输入输出示例:
示例 1:
输入:head = [1,1,2]
输出:[1,2]
示例 2:
输入:head = [1,1,2,3,3]
输出:[1,2,3]2.思路讲解
由于链表已经排序,重复的元素必然相邻。我们可以使用一个指针 curr 遍历链表,如果 curr 的下一个节点 curr.next 的值与 curr 的值相同,则将 curr.next 指向 curr.next.next,跳过重复的节点。
3.Java 代码实现
public class RemoveDuplicatesFromSortedList {
// 定义链表节点
static class ListNode {
int val;
ListNode next;
ListNode(int val) {
this.val = val;
}
}
public static ListNode deleteDuplicates(ListNode head) {
if (head == null || head.next == null) { // 空链表或只有一个节点,直接返回
return head;
}
ListNode curr = head; // 当前节点指针
while (curr.next != null) { // 遍历链表,直到倒数第二个节点
if (curr.val == curr.next.val) { // 如果当前节点和下一个节点值相同
curr.next = curr.next.next; // 跳过下一个节点,删除重复节点
} else {
curr = curr.next; // 移动到下一个节点
}
}
return head; // 返回新的头节点
}
// 测试代码
public static void main(String[] args) {
// 示例 1
ListNode head1 = buildLinkedList(new int[]{1, 1, 2});
ListNode result1 = deleteDuplicates(head1);
printLinkedList(result1); // 输出:1 2
// 示例 2
ListNode head2 = buildLinkedList(new int[]{1, 1, 2, 3, 3});
ListNode result2 = deleteDuplicates(head2);
printLinkedList(result2); // 输出:1 2 3
// 示例 3: 空链表
ListNode head3 = buildLinkedList(new int[]{});
ListNode result3 = deleteDuplicates(head3);
printLinkedList(result3); // 输出:
// 示例 4: 单个节点
ListNode head4 = buildLinkedList(new int[]{1});
ListNode result4 = deleteDuplicates(head4);
printLinkedList(result4); // 输出:1
}
// 辅助函数:构建链表
private static ListNode buildLinkedList(int[] values) {
ListNode dummy = new ListNode(-1);
ListNode curr = dummy;
for (int val : values) {
curr.next = new ListNode(val);
curr = curr.next;
}
return dummy.next;
}
// 打印链表
private static void printLinkedList(ListNode head) {
ListNode curr = head;
while (curr != null) {
System.out.print(curr.val + " ");
curr = curr.next;
}
System.out.println();
}
}4.代码解释
- ListNode 类定义了链表节点的结构。
- deleteDuplicates 函数实现了有序链表去重的功能。
- curr 指针用于遍历链表。
- while 循环遍历链表,直到倒数第二个节点。
- if 语句判断当前节点和下一个节点的值是否相同。如果相同,则跳过下一个节点,删除重复节点。
- else 语句移动 curr 指针到下一个节点。
- 最后返回新的头节点。
- 包含了空链表和单节点链表的处理,使其更加健壮。
5.复杂度分析
- 时间复杂度: O(n),其中 n 是链表的长度。我们最多遍历链表一次。
- 空间复杂度: O(1),我们只使用了常数个额外变量。
6.其它方法
6.1 递归实现
思路分析:
递归函数负责返回:从当前节点(我)开始,完成去重的链表
- 若我与 next 重复,返回 next
- 若我与 next 不重复,返回我,但 next 应当更新
//递归伪代码分析
deleteDuplicates(ListNode p=1) {
deleteDuplicates(ListNode p=1) {
1.next=deleteDuplicates(ListNode p=2) {
2.next=deleteDuplicates(ListNode p=3) {
deleteDuplicates(ListNode p=3) {
// 只剩一个节点,返回
return 3
}
}
return 2
}
return 1
}
}代码实现:
public ListNode deleteDuplicates(ListNode p) {
if (p == null || p.next == null) {
return p;
}
if(p.val == p.next.val) {
return deleteDuplicates(p.next);
} else {
p.next = deleteDuplicates(p.next);
return p;
}
}6.2 双指针实现
思路分析:
-------------------------step1----------------------------
p1 p2
| |
1 -> 1 -> 2 -> 3 -> 3 -> null
p1.val == p2.val 那么删除 p2,注意 p1 此时保持不变
-------------------------step2----------------------------
p1 p2
| |
1 -> 2 -> 3 -> 3 -> null
p1.val != p2.val 那么 p1,p2 向后移动
-------------------------step3----------------------------
p1 p2
| |
1 -> 2 -> 3 -> 3 -> null
p1 p2
| |
1 -> 2 -> 3 -> 3 -> null
p1.val == p2.val 那么删除 p2
-------------------------step4----------------------------
p1 p2
| |
1 -> 2 -> 3 -> null
当 p2 == null 退出循环代码实现:
public ListNode deleteDuplicates(ListNode head) {
// 链表节点 < 2
if (head == null || head.next == null) {
return head;
}
// 链表节点 >= 2
ListNode p1 = head;
ListNode p2;
while ((p2 = p1.next) != null) {
if (p1.val == p2.val) {
p1.next = p2.next;
} else {
p1 = p1.next;
}
}
return head;
}7.总结
本文详细讲解了如何去除有序单链表中的重复元素且每个重复元素保留一个,并提供了 Java 代码实现和详细的解释。希望能帮助各位看官更好地理解和掌握这个算法。下期见,谢谢~
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-10-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号