【愚公系列】《Python网络爬虫从入门到精通》024-多进程和创建进程的常用方式
原创
【愚公系列】《Python网络爬虫从入门到精通》024-多进程和创建进程的常用方式
原创
愚公搬代码
发布于 2025-09-13 09:36:23
发布于 2025-09-13 09:36:23

震撼头图
💎 行业认证·权威头衔
- ✔ 华为云天团核心成员 :特约编辑/云享专家/开发者专家/产品云测专家
- ✔ 开发者社区全满贯 :CSDN双料专家/阿里云签约作者/腾讯云内容共创官
- ✔ 技术生态共建先锋 :横跨鸿蒙/云计算/AI等前沿领域的技术布道者
🏆 荣誉殿堂
- 🎖 连续三年蝉联 "华为云十佳博主" (2022-2024)
- 🎖 双冠加冕 CSDN"年度博客之星TOP2" (2022&2023)
- 🎖 十余个技术社区 年度杰出贡献奖 得主
📚 知识宝库
◾ 编程语言:.NET/Java/Python/Go/Node...
◾ 移动生态:HarmonyOS/iOS/Android/小程序
◾ 前沿领域:物联网/网络安全/大数据/AI/元宇宙
◾ 游戏开发:Unity3D引擎深度解析
🚀前言
在如今这个数据驱动的时代,网络爬虫已成为获取信息的重要工具。然而,当面对复杂的网站结构和庞大的数据量时,传统的单进程爬虫往往难以满足迅速、高效的数据采集需求。为了解决这一问题,多进程爬虫应运而生,它通过并行处理来显著提升爬虫的性能,让我们能够更快地获取所需的信息。
在本期文章中,我们将深入探讨多进程爬虫的基本原理、实现方式以及在实际应用中的优势与挑战。我们将介绍如何利用Python等编程语言,搭建高效的多进程爬虫系统,帮助您在数据采集的过程中事半功倍
🚀一、多进程和创建进程的常用方式
🔎1.什么是进程
在了解进程之前,我们首先需要了解多任务的概念。多任务,顾名思义,就是指操作系统能够同时执行多个任务。例如,使用 Windows 或 Linux 操作系统时,你可以同时进行看电影、聊天、查看网页等操作。此时,操作系统在执行多个任务,而每个任务就是一个进程。
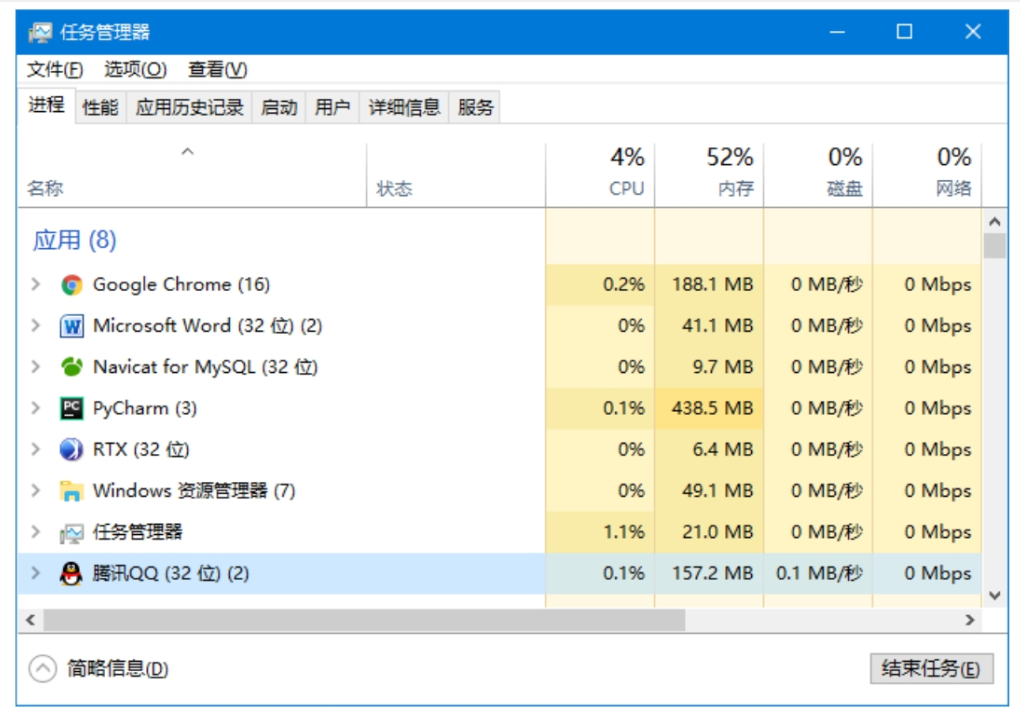
你可以通过打开 Windows 的任务管理器来查看当前操作系统正在执行的进程,图11.8中就显示了这些进程。图中的进程不仅包括各种应用程序(如 QQ、谷歌浏览器等),还包括系统进程。
进程与程序的区别
进程(process)是计算机中已经在运行的程序的实体。它是程序(包括指令和数据)的真正运行实例,而程序本身仅仅是指令、数据及其组织形式的描述,并不具备实际运行功能。
例如,当你没有打开 QQ 时,QQ 只是一个程序。它的代码和数据只是存在磁盘上,还没有被操作系统加载到内存中并执行。但是,当你打开 QQ 时,操作系统为其分配了资源,并启动了一个新的进程来执行 QQ 程序。此时,QQ就成了一个进程。
此外,如果你再打开一个 QQ,操作系统将为第二个 QQ 创建一个新的进程。所以,即便是同一个程序,运行的多个实例也会分别拥有各自独立的进程。图11.9展示了这种情况。
🔎2.创建进程的常用方式
Python中创建进程的常用模块包括:
os.fork():仅适用于UNIX/Linux/Mac系统,不兼容Windows。multiprocessing模块:跨平台支持,适用于复杂进程管理。Pool进程池:跨平台,适合批量创建进程任务。
本文重点介绍 multiprocessing模块和 Pool进程池。
🦋2.1 使用multiprocessing.Process类创建进程
multiprocessing模块提供Process类表示进程对象。
语法与参数
Process(group=None, target=None, name=None, args=(), kwargs={})- 参数说明:
group: 保留参数,始终为None。target: 进程启动时调用的可执行对象(函数)。name: 进程别名(默认Process-N,N从1递增)。args: 传递给target的位置参数元组。kwargs: 传递给target的关键字参数字典。
基础示例
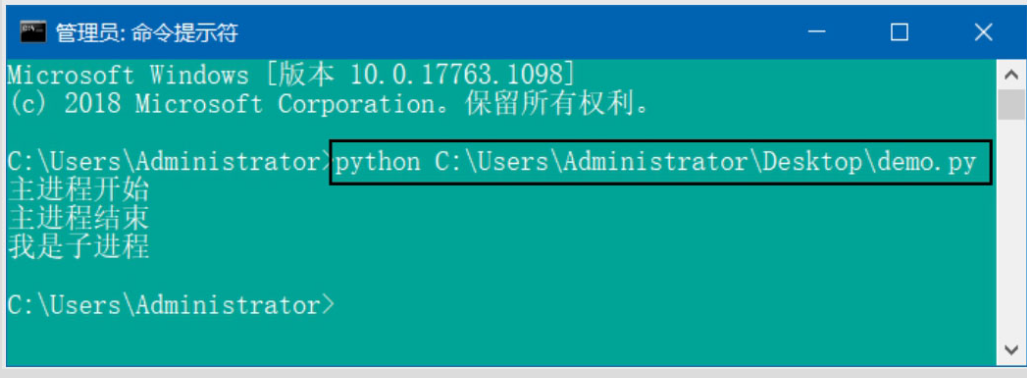
from multiprocessing import Process
def test(interval):
print("我是子进程")
if __name__ == '__main__':
print("主进程开始")
p = Process(target=test, args=(1,)) # 实例化进程
p.start() # 启动子进程
print("主进程结束")运行结果
注意事项
- 在IDLE中运行可能不显示子进程输出,建议使用命令行执行:
python 文件名.py。
☀️2.1.1 Process类常用方法
方法 | 说明 |
|---|---|
| 启动子进程 |
| 判断进程是否在运行 |
| 等待进程结束(可设置超时时间) |
| 强制终止进程 |
| 若未指定 |
☀️2.1.2 Process类常用属性
属性 | 说明 |
|---|---|
| 进程别名(默认 |
| 进程的PID值 |
☀️2.1.3 示例:Process类方法和属性演示
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
import os
#两个子进程将会调用的两个方法
def child_1(interval):
print("子进程(%s)开始执行,父进程为(%s)" % (os.getpid(), os.getppid()))
t_start = time.time() # 计时开始
time.sleep(interval) # 程序将会被挂起interval秒
t_end = time.time() # 计时结束
print("子进程(%s)执行时间为'%0.2f'秒"%(os.getpid(),t_end - t_start))
def child_2(interval):
print("子进程(%s)开始执行,父进程为(%s)" % (os.getpid(), os.getppid()))
t_start = time.time() # 计时开始
time.sleep(interval) # 程序将会被挂起interval秒
t_end = time.time() # 计时结束
print("子进程(%s)执行时间为'%0.2f'秒"%(os.getpid(),t_end - t_start))
if __name__ == '__main__':
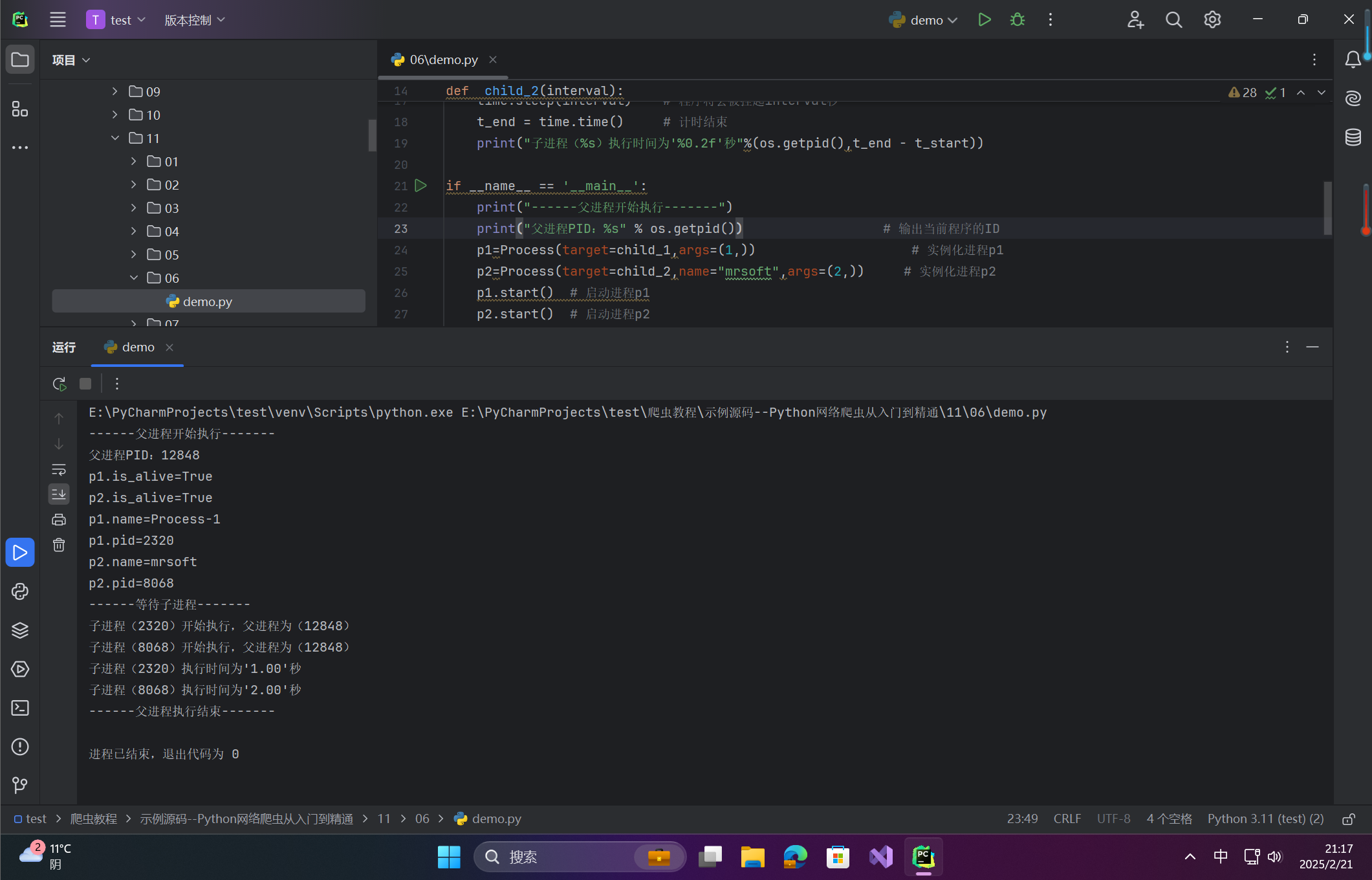
print("------父进程开始执行-------")
print("父进程PID:%s" % os.getpid()) # 输出当前程序的ID
p1=Process(target=child_1,args=(1,)) # 实例化进程p1
p2=Process(target=child_2,name="mrsoft",args=(2,)) # 实例化进程p2
p1.start() # 启动进程p1
p2.start() # 启动进程p2
#同时父进程仍然往下执行,如果p2进程还在执行,将会返回True
print("p1.is_alive=%s"%p1.is_alive())
print("p2.is_alive=%s"%p2.is_alive())
#输出p1和p2进程的别名和PID
print("p1.name=%s"%p1.name)
print("p1.pid=%s"%p1.pid)
print("p2.name=%s"%p2.name)
print("p2.pid=%s"%p2.pid)
print("------等待子进程-------")
p1.join() # 等待p1进程结束
p2.join() # 等待p2进程结束
print("------父进程执行结束-------")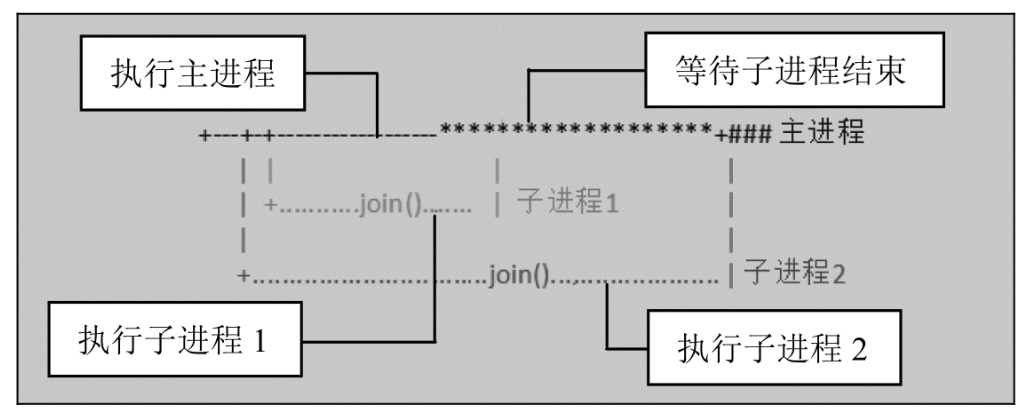
运行结果
🦋2.2 继承Process子类创建进程
通过自定义类继承Process类,重写run()方法实现复杂任务。
示例:子类化Process
# -*- coding:utf-8 -*-
from multiprocessing import Process
import time
import os
#继承Process类
class SubProcess(Process):
# 由于Process类本身也有__init__初识化方法,这个子类相当于重写了父类的这个方法
def __init__(self,interval,name=''):
Process.__init__(self) # 调用Process父类的初始化方法
self.interval = interval # 接收参数interval
if name: # 判断传递的参数name是否存在
self.name = name # 如果传递参数name,则为子进程创建name属性,否则使用默认属性
#重写了Process类的run()方法
def run(self):
print("子进程(%s) 开始执行,父进程为(%s)"%(os.getpid(),os.getppid()))
t_start = time.time()
time.sleep(self.interval)
t_stop = time.time()
print("子进程(%s)执行结束,耗时%0.2f秒"%(os.getpid(),t_stop-t_start))
if __name__=="__main__":
print("------父进程开始执行-------")
print("父进程PID:%s" % os.getpid()) # 输出当前程序的ID
p1 = SubProcess(interval=1,name='mrsoft')
p2 = SubProcess(interval=2)
#对一个不包含target属性的Process类执行start()方法,就会运行这个类中的run()方法,
#所以这里会执行p1.run()
p1.start() # 启动进程p1
p2.start() # 启动进程p2
# 输出p1和p2进程的执行状态,如果真正进行,返回True,否则返回False
print("p1.is_alive=%s"%p1.is_alive())
print("p2.is_alive=%s"%p2.is_alive())
#输出p1和p2进程的别名和PID
print("p1.name=%s"%p1.name)
print("p1.pid=%s"%p1.pid)
print("p2.name=%s"%p2.name)
print("p2.pid=%s"%p2.pid)
print("------等待子进程-------")
p1.join() # 等待p1进程结束
p2.join() # 等待p2进程结束
print("------父进程执行结束-------")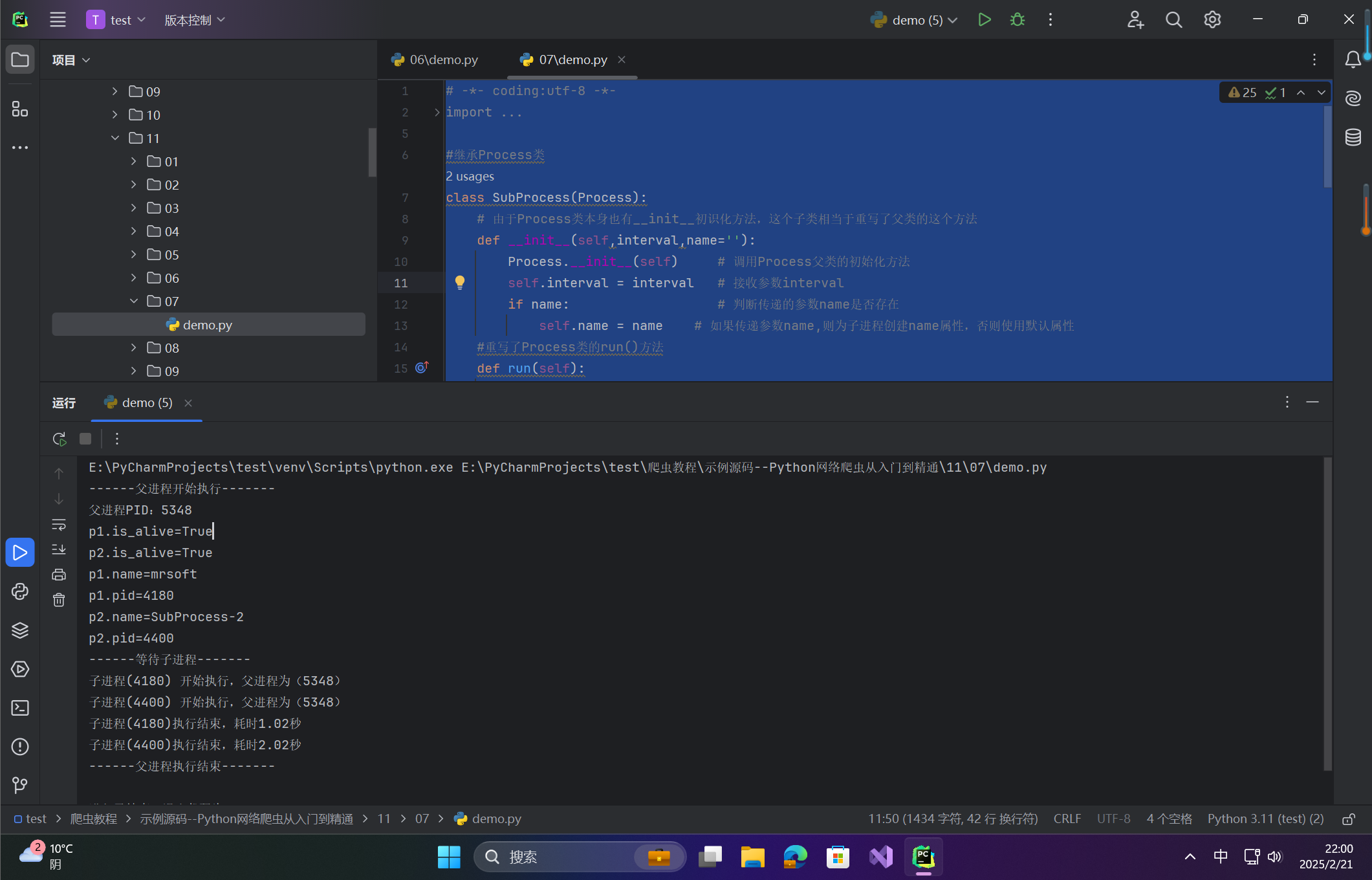
关键点
- 必须调用
super().__init__()以确保父类初始化。 start()方法会自动调用子类的run()方法。
🦋2.3 使用进程池Pool创建进程
Pool类用于管理多个进程,适合批量任务处理。
Pool类核心方法
方法 | 说明 |
|---|---|
| 非阻塞方式并行执行任务 |
| 阻塞方式顺序执行任务 |
| 关闭进程池,禁止添加新任务 |
| 等待所有子进程结束(需在 |
示例:进程池使用
# -*- coding=utf-8 -*-
from multiprocessing import Pool
import os, time
def task(name):
print('子进程(%s)执行task %s ...' % ( os.getpid() ,name))
time.sleep(1) # 休眠1秒
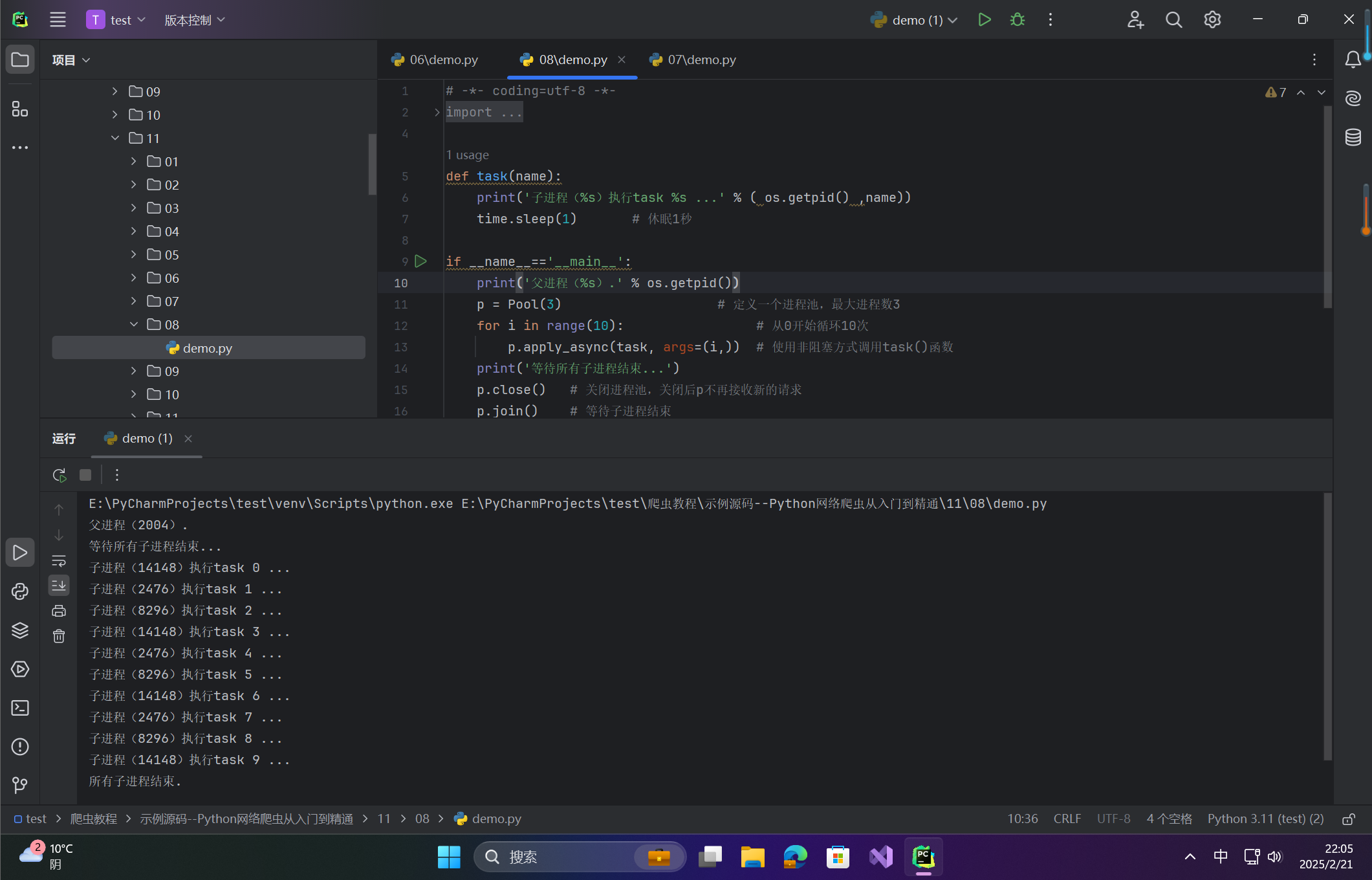
if __name__=='__main__':
print('父进程(%s).' % os.getpid())
p = Pool(3) # 定义一个进程池,最大进程数3
for i in range(10): # 从0开始循环10次
p.apply_async(task, args=(i,)) # 使用非阻塞方式调用task()函数
print('等待所有子进程结束...')
p.close() # 关闭进程池,关闭后p不再接收新的请求
p.join() # 等待子进程结束
print('所有子进程结束.')运行结果
🦋2.4 总结
Process类:适合少量进程的精确控制。- 子类化Process:适合复杂任务封装。
- Pool进程池:适合批量任务的高效并发处理。
通过灵活选择不同方式,可应对多进程编程中的各类场景。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号