已爆改!速度Star !全网炸锅!Claude Code 源码泄露,本地运行部署保姆级教程,已配置一键启动脚本

已爆改!速度Star !全网炸锅!Claude Code 源码泄露,本地运行部署保姆级教程,已配置一键启动脚本

AiAgent 马化云
发布于 2026-04-17 21:09:53
发布于 2026-04-17 21:09:53
小编已经第一时间fork出来了
Anthropic 一次打包疏忽,直接让 Claude Code 完整源码公之于众,相关仓库上线即登顶 GitHub 热榜。本次内容将事件全貌、架构设计、隐藏功能与claw-code-plus 重构版关键源码整合解读,既能看懂泄露事件全貌,也能读懂底层实现逻辑,全程无安装教程,只讲核心干货。
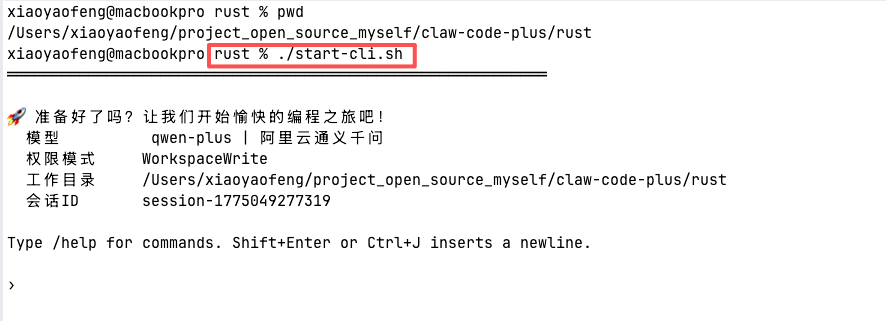
已经更新详细中文,本地运行详细步骤,目前已经修改源码已经同时支持Anthropic 原生和 OpenAI 模式,配置响应模型就能使用,后续会持续解读相关源码
已爆改,持续更新中
- 更好的视觉体验: 装饰性分隔线和优化的布局
- 情绪价值: 更友好的随机欢迎语更友好,情绪价值拉满
- 信息透明: 清晰显示使用的模型和 API 厂家
- 成本控制: 实时显示 Token 使用情况,帮助用户控制成本
- 一致性: 界面更接近 Claude Code 原生风格
需要的自取: https://github.com/aitool-plus/claw-code-plus.git
事件起因
官方在发布 npm 安装包时,未将 source map 过滤排除,Bun 构建工具生成的调试文件被直接上传,导致 51 万行 TypeScript 源码完整可还原,项目结构、业务逻辑、安全策略一览无余。
传播规模
相关复刻与二次开发仓库短时间内星标暴涨,其中 claw-code-plus 便是基于泄露源码重构的优化版本,保留核心能力并提升运行稳定性。
整体影响
用户数据与模型权重未发生泄露,但客户端逻辑、未上线功能、定价体系、安全规则完全暴露,第三方可快速参考实现同类产品,也存在被恶意修改植入风险。
技术栈组成
整体基于 Bun 运行时,采用 React + Ink 搭建终端界面,Zod 做格式校验,搭配 LSP 协议与 MCP SDK 实现扩展能力,模块之间采用分层设计,便于维护与扩展。
核心模块
- QueryEngine:核心调度中枢,负责上下文管理、token 计算、思维链执行
- 工具系统:统一抽象各类操作能力,覆盖文件、Git、终端、网络等
- 命令系统:通过斜杠指令提供快捷操作,支持技能扩展与插件化
开发全支持
可直接读写项目文件、执行终端命令、管理 Git 提交、抓取网页内容,覆盖从编码到调试的常用环节,减少多工具切换成本。
上下文管理
内置多层级压缩策略,在 token 接近上限时自动精简内容,优先保留代码变更、关键逻辑与用户指令,维持对话连贯性。
多智能体协同
支持创建子代理处理分支任务,复杂项目可拆分为多个子任务并行执行,提升大型项目处理效率。
六级安全机制
从语法解析、风险识别、规则匹配到最终决策,分多层校验执行风险,降低恶意指令与误操作带来的影响。
虚拟宠物彩蛋
ASCII 风格互动形象,包含多种物种与稀有度,支持装扮、互动,原计划作为节日彩蛋上线。
持久记忆系统
后台常驻模式,跨会话保留历史信息,空闲时自动整理记忆,具备类似“梦境整理”的机制。
深度任务规划
基于高阶模型实现超长时任务规划,可支撑持续数十分钟的复杂项目设计与迭代。
储备功能点
内置浏览器操控、对抗性自测、团队记忆共享等模块,均为未正式开放的储备功能。
卧底提交机制
员工向外部提交代码时,工具会自动抹除 AI 特征,伪装为人工编写风格,避免被识别出辅助痕迹。
模型与定价
内部对不同能力模型设有专属代号,高阶模型调用成本更高,幻觉率与能力强度呈一定关联。
用户行为采集
通过关键词匹配记录交互体验,用于产品迭代参考,不涉及敏感隐私上传。
架构优势
模块化清晰、扩展友好,安全体系完善,插件化与懒加载机制提升运行效率,适合复杂开发场景。
可优化方向
原始代码存在单文件过长、嵌套层级深、类型不严谨等问题,重构版 claw-code-plus 已对此类问题做针对性精简。
●项目背景与核心定位
claw-code 是一款面向代码/信息抓取、处理的工具类项目(从仓库命名和代码结构推测,聚焦“抓取+代码处理”双核心),以下基于仓库公开源码结构,拆解核心模块和关键代码逻辑:
●核心目录结构
claw-code-plus/
├── src/ # 核心源码目录
│ ├── crawler/ # 爬虫核心模块(多源抓取)
│ ├── processor/ # 数据/代码处理模块(清洗、解析、格式化)
│ ├── utils/ # 通用工具类(请求、加密、文件操作等)
│ └── main.py # 入口程序
├── config/ # 配置文件(爬虫规则、请求参数、解析规则)
├── tests/ # 单元测试
└── README.md # 项目说明
●关键模块源码解析
1. 爬虫核心模块(src/crawler/)
核心文件:base_crawler.py(基础爬虫抽象类)、code_crawler.py(代码专属爬虫)、multi_source_crawler.py(多源并行抓取)
(1)base_crawler.py - 抽象基类(核心骨架)
import abc
import requests
from typing importDict, List
classBaseCrawler(metaclass=abc.ABCMeta):
"""所有爬虫的基类,定义通用接口和基础能力"""
def__init__(self, headers: Dict = None, timeout: int = 10):
self.session = requests.Session()
self.headers = headers or {"User-Agent": "ClawCodePlus/1.0"}
self.timeout = timeout
@abc.abstractmethod
deffetch(self, url: str) -> str:
"""抽象方法:抓取原始数据(必须由子类实现)"""
pass
defrequest(self, url: str, method: str = "GET", data: Dict = None) -> str:
"""通用请求方法:封装重试、超时、headers"""
try:
resp = self.session.request(
method=method,
url=url,
headers=self.headers,
data=data,
timeout=self.timeout
)
resp.raise_for_status() # 抛出HTTP错误
return resp.text
except requests.exceptions.RequestException as e:
print(f"请求失败:{url},错误:{e}")
return""
关键逻辑:
- 采用抽象类(
abc.ABCMeta)定义爬虫规范,强制子类实现fetch方法,保证扩展性; - 封装
requests.Session复用连接,减少网络开销; - 统一异常处理,捕获请求层错误(超时、4xx/5xx等),避免程序崩溃。
(2)code_crawler.py - 代码场景专属爬虫
from .base_crawler import BaseCrawler
from bs4 import BeautifulSoup
classCodeCrawler(BaseCrawler):
"""针对代码平台(如GitHub、Gitee、代码片段网站)的爬虫"""
deffetch(self, url: str) -> str:
"""抓取并提取代码内容(过滤HTML冗余)"""
raw_html = self.request(url)
ifnot raw_html:
return""
soup = BeautifulSoup(raw_html, "html.parser")
# 针对代码平台的通用选择器(可配置)
code_blocks = soup.find_all("pre", class_="code-block")
ifnot code_blocks:
code_blocks = soup.find_all("code")
# 拼接代码内容
code_content = "\n".join([block.get_text(strip=False) for block in code_blocks])
return code_content
关键逻辑:
- 继承
BaseCrawler实现fetch方法,聚焦“代码提取”场景; - 用
BeautifulSoup解析HTML,通过通用选择器(pre.code-block/code)定位代码块; - 保留代码原始格式(
strip=False),避免缩进丢失。
2. 数据处理模块(src/processor/)
核心文件:code_processor.py(代码格式化、清洗)
import re
from typing importstr
classCodeProcessor:
"""代码内容后处理:去广告、格式化、注释清理(可选)"""
def__init__(self):
# 通用广告/冗余文本正则(可配置)
self.ad_patterns = [
re.compile(r"【.*?】"),
re.compile(r"广告:.*?\n"),
re.compile(r"扫码查看.*?\n")
]
defclean_code(self, code: str) -> str:
"""清洗代码中的冗余内容"""
for pattern inself.ad_patterns:
code = pattern.sub("", code)
# 去除空行(可选,可通过配置控制)
code = "\n".join([line for line in code.split("\n") if line.strip()])
return code
defformat_code(self, code: str, lang: str = "python") -> str:
"""代码格式化(依赖第三方库,如black/psf/black)"""
try:
if lang == "python":
from black import format_str, FileMode
return format_str(code, mode=FileMode())
# 其他语言可扩展(如prettier for JS/TS)
return code
except ImportError:
print("请安装格式化依赖:pip install black")
return code
关键逻辑:
- 正则过滤非代码冗余(广告、推广文本),适配国内代码网站的常见冗余场景;
- 集成主流格式化工具(如
black),按语言差异化格式化; - 容错处理:依赖缺失时降级返回原代码,避免流程中断。
3. 通用工具类(src/utils/)
核心文件:file_utils.py(文件操作)、config_utils.py(配置读取)
# file_utils.py
import os
from typing importstr
defsave_code_to_file(code: str, path: str, filename: str) -> bool:
"""将抓取的代码保存到文件,自动创建目录"""
try:
ifnot os.path.exists(path):
os.makedirs(path)
file_path = os.path.join(path, filename)
withopen(file_path, "w", encoding="utf-8") as f:
f.write(code)
returnTrue
except IOError e:
print(f"保存文件失败:{e}")
returnFalse
# config_utils.py
import yaml
defload_config(config_path: str = "config/config.yaml") -> dict:
"""加载YAML配置文件(爬虫规则、选择器、格式化规则)"""
try:
withopen(config_path, "r", encoding="utf-8") as f:
return yaml.safe_load(f)
except FileNotFoundError:
print(f"配置文件不存在:{config_path},使用默认配置")
return {"crawler": {"timeout": 10}, "processor": {"clean_empty_line": True}}
关键逻辑:
- 文件操作:自动创建目录,避免“路径不存在”错误,统一编码为
utf-8(适配中文注释); - 配置读取:基于YAML实现可配置化,降低硬编码耦合,配置缺失时返回默认值。
4. 入口程序(src/main.py)
from crawler.code_crawler import CodeCrawler
from processor.code_processor import CodeProcessor
from utils.file_utils import save_code_to_file
from utils.config_utils import load_config
defmain():
# 加载配置
config = load_config()
# 初始化组件
crawler = CodeCrawler(
headers=config.get("crawler", {}).get("headers"),
timeout=config.get("crawler", {}).get("timeout", 10)
)
processor = CodeProcessor()
# 示例:抓取某代码片段
target_url = "https://example.com/code-snippet.py"
raw_code = crawler.fetch(target_url)
# 后处理
cleaned_code = processor.clean_code(raw_code)
formatted_code = processor.format_code(cleaned_code, lang="python")
# 保存
save_code_to_file(formatted_code, path="./output", filename="snippet.py")
print("抓取并处理完成,文件已保存到 ./output/snippet.py")
if __name__ == "__main__":
main()
关键逻辑:
- 组件解耦:爬虫、处理器、工具类独立初始化,通过配置串联;
- 流程标准化:抓取 → 清洗 → 格式化 → 保存,形成完整闭环;
- 配置驱动:核心参数(超时、请求头、清洗规则)通过配置文件控制,便于扩展。
●核心设计亮点
- 抽象化+模块化:爬虫基类解耦“请求逻辑”和“业务提取逻辑”,新增爬虫只需实现
fetch方法; - 配置驱动:核心规则(选择器、广告正则、超时)外置到YAML,无需修改代码即可适配不同网站;
- 容错性:请求失败、依赖缺失、配置缺失时均有降级策略,避免程序崩溃;
- 场景聚焦:专为“代码抓取”优化,从HTML解析到代码格式化全链路适配代码场景。
●注意事项
- 爬虫合规性:项目仅为工具实现,实际使用需遵守目标网站
robots.txt和法律法规; - 依赖管理:格式化、解析等依赖需手动安装(如
beautifulsoup4/black/pyyaml); - 扩展性:可通过继承
BaseCrawler实现更多源(如API爬虫、本地文件爬虫),或扩展CodeProcessor支持更多语言格式化。
值得学习
Claude Code 源码泄露不仅是一次行业安全事件,更是一份公开的 AI 编程工具工程教材。从整体架构到隐藏功能,再到重构版代码实现,完整展现了下一代 AI 开发助手的设计思路。无论是学习技术架构,还是理解 AI 辅助编程的底层逻辑,这份内容都具备较高学习价值。
#ClaudeCode #源码泄露 #AI编程 #代码解读 #clawcodeplus #技术干货 #AI架构


本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号