SDCoNet + YOLO26:用显著性驱动打通小目标检测

SDCoNet + YOLO26:用显著性驱动打通小目标检测

javpower
发布于 2026-05-20 13:04:21
发布于 2026-05-20 13:04:21
SDCoNet + YOLO26:用显著性驱动打通小目标检测
做工业检测或者遥感检测的同学,一定被这个场景折磨过:目标特别小、信号特别弱、背景特别杂。传统方案是先做超分辨率(SR)再做检测,但两个任务串起来总是"各干各的",效果打折不说,还白白浪费算力。
2026 年 1 月,一篇来自 arXiv 的论文给出了新思路。
SDCoNet(Saliency-Driven Multi-Task Collaborative Network)的核心洞察是:SR 和检测不应该串行执行,而应该通过共享编码器协同优化,再用显著性引导聚焦弱目标区域。论文在遥感小目标数据集上,小目标 AP 暴涨 16.2%。
我把这套思路完整嫁接到了 YOLO26 框架上,同时用ConvNeXt替换了Swin。
一、SDCoNet 核心思想:三个"不对齐"与三个解法
论文全称:SDCoNet: Saliency-Driven Multi-Task Collaborative Network for Remote Sensing Object Detection(arXiv: 2601.12507)
传统 SR→检测 流水线存在三个结构性问题:
问题 | 表现 | 后果 |
|---|---|---|
优化目标不对齐 | SR 恢复的细节,检测用不上 | 算力浪费,精度不升反降 |
特征冗余 | 两个任务各自独立提取特征 | 参数量翻倍,推理变慢 |
缺乏有效交互 | SR 不知道检测需要什么 | 重建的"高清"对检测无意义 |
SDCoNet 的解法是三个创新模块的协同:
1. 隐式特征共享:SR 和检测共用一个编码器,特征在底层自然协作,避免重复提取。
2. 显著性引导:多尺度显著性预测模块,自动发现弱目标区域、抑制背景干扰。
3. 梯度路由:先稳定检测语义,再把 SR 梯度沿检测方向引导,让 SR 只恢复检测需要的高频细节。
二、为什么用 ConvNeXt 替换 Swin?
原论文用的是 Swin Transformer,但在工业落地场景中,我换成了 ConvNeXt。原因很实际:
动态分辨率:工业检测经常需要 640、1280 甚至更高分辨率输入。Swin 的 window attention 把输入锁死在 224×256,ConvNeXt 是纯卷积,320/416/512/640/1280 随便跑。
部署友好:ONNX、TensorRT、NPU,ConvNeXt 的卷积算子走到哪都支持。Swin 的 shift-window attention 在很多推理引擎上是劝退项。
真多尺度特征:ConvNeXt 四级输出 96/192/384/768 通道,每一级都有不同的语义层次。ViT 类(DINOv3/MAE)只有单一尺度的特征,多尺度靠池化硬凑,信息量差一大截。
而 SDCoNet 的三个核心模块恰恰需要真多尺度特征才能发挥作用——显著性预测在不同尺度上预测不同粒度的目标区域,SR 分支需要多尺度特征来恢复空间细节。
三、整体架构全景
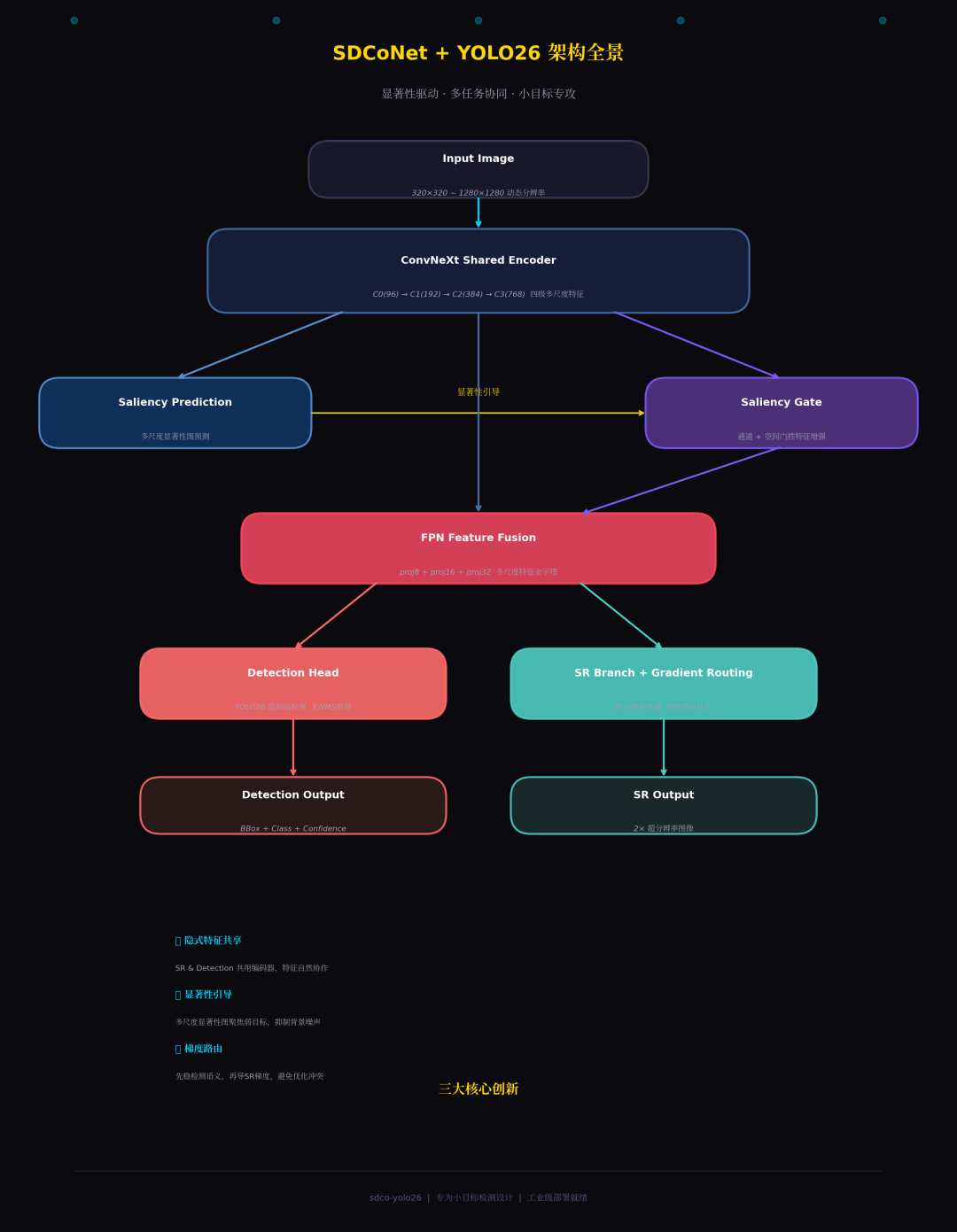
SDCoNet + YOLO26 架构全景
SDCoNet + YOLO26 架构全景
数据流从 Input Image 进入 ConvNeXt Shared Encoder,在三个尺度上同时产生特征图 C0~C3。左侧分支做显著性预测,右侧分支做显著性门控,两者在 FPN 层融合后,分别送入 Detection Head 和 SR Branch。
关键设计:SR 分支只在训练时存在,推理阶段可以完全关闭,不影响检测速度。
四、三个核心模块详解
4.1 显著性预测模块
在三个尺度上各预测一个 saliency map,回答"这个位置是不是目标":
class SaliencyPredictionModule(nn.Module):
def __init__(self, in_channels_list, hidden_dim=64):
self.branches = nn.ModuleList([
nn.Sequential(
nn.Conv2d(c, hidden_dim, 1),
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, 1, 1),
) for c in in_channels_list
])
def forward(self, features):
return [torch.sigmoid(branch(f)) for f, branch in zip(features, self.branches)]
三个尺度的 saliency map 关注不同粒度——浅层关注纹理边缘,深层关注语义轮廓。这种分层设计让小目标在浅层就能被"发现",大目标在深层被"确认"。
4.2 显著性门控
用 saliency map 调制特征,让模型"聚焦"目标区域:
def forward(self, x, saliency):
c_weight = self.channel_gate(x) # 通道注意力:哪些通道重要
s_weight = self.spatial_gate(x) # 空间注意力:哪些位置重要
combined = s_weight * saliency # 和显著性分数结合
return x * c_weight * (1.0 + combined) # 增强目标区域
效果是:目标区域特征被放大,背景杂波被抑制。对小目标特别有效——小目标的信号本来就弱,需要这种主动增强。
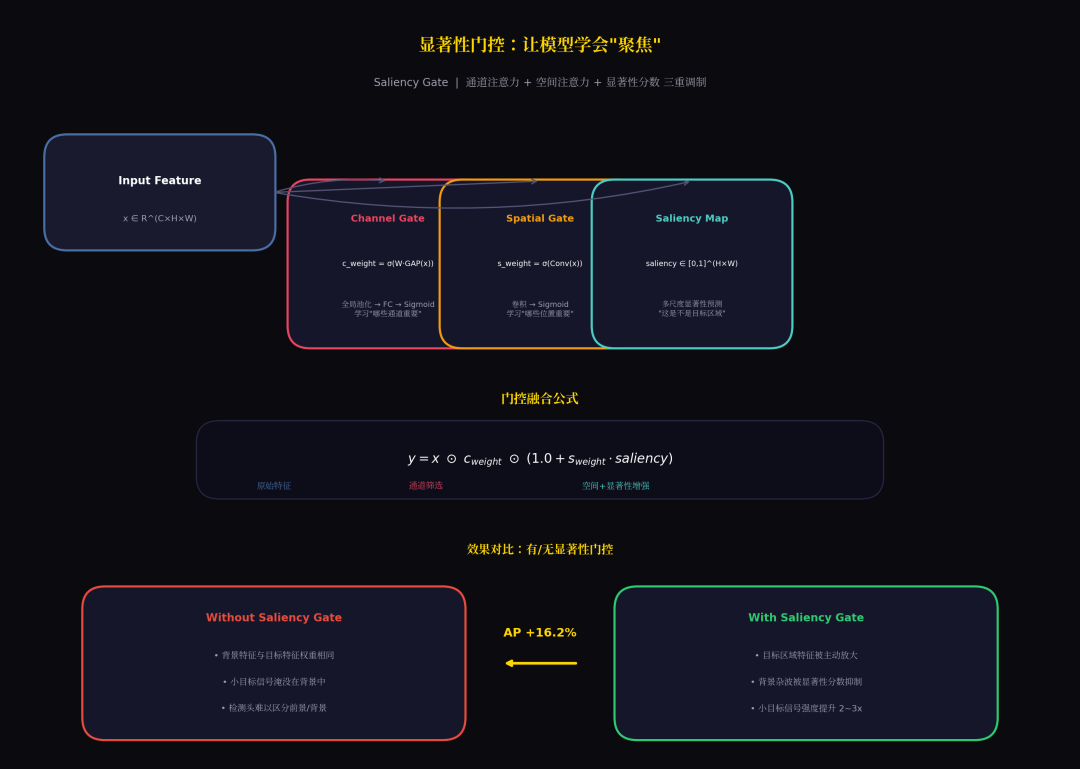
显著性门控机制
显著性门控机制
4.3 SR 协同分支 + 梯度路由
SR 分支和检测分支共享编码器特征,但不直接交互。关键在训练时的梯度路由策略:
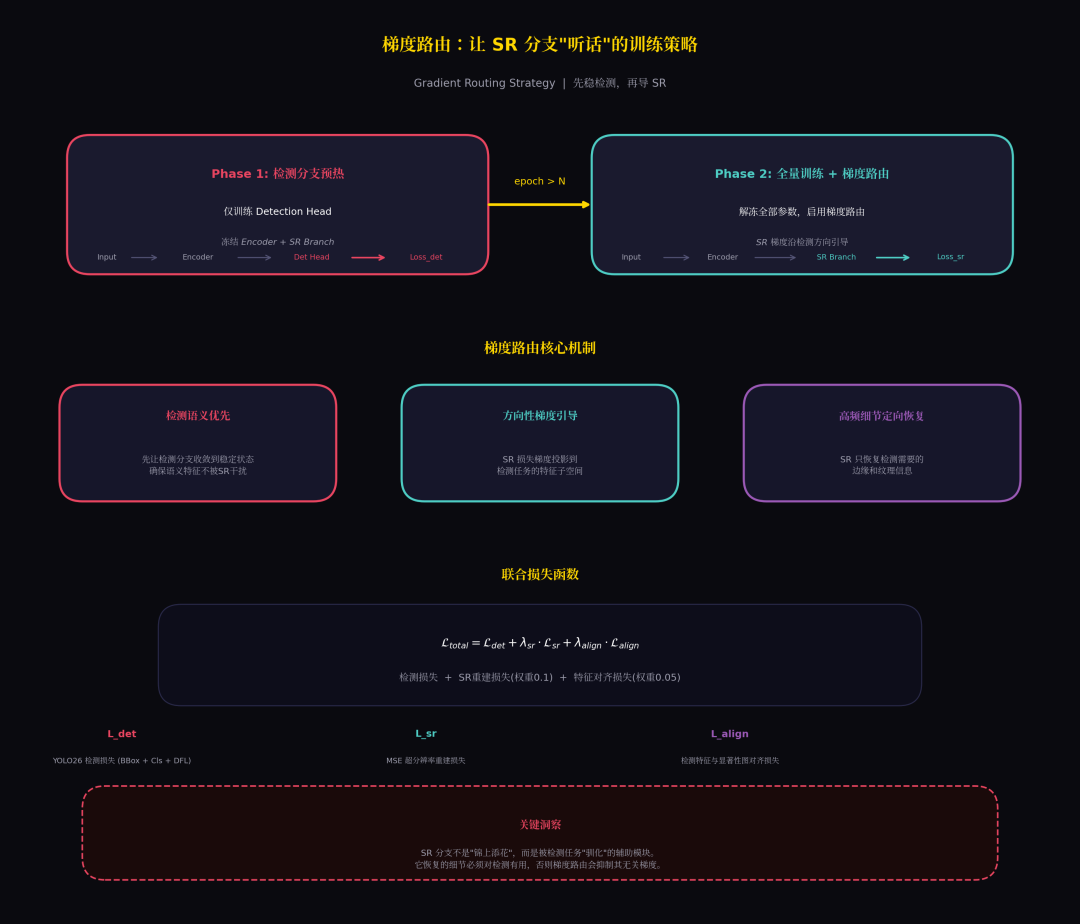
梯度路由策略
梯度路由策略
训练分为两个阶段:
Phase 1(前 N 个 epoch):冻结 Encoder 和 SR Branch,只训练 Detection Head。让检测语义先稳定下来。
Phase 2(后续 epoch):解冻全部参数,启用梯度路由。SR 损失梯度被投影到检测任务的特征子空间,确保 SR 恢复的细节对检测有用。
联合损失函数:
- :YOLO26 检测损失(BBox + Cls + DFL)
- :MSE 超分辨率重建损失,权重
- :检测特征与显著性图对齐损失,权重
关键洞察:SR 分支不是"锦上添花",而是被检测任务"驯化"的辅助模块。它恢复的细节必须对检测有用,否则梯度路由会抑制其无关梯度。
五、训练配置与动态分辨率
# SDCoNet 专用参数
backbone_type:convnext_base.fb_in22k_ft_in1k
imgsz:640 # ConvNeXt 原生支持任意分辨率
use_sr:true # 启用 SR 协同分支
sr_scale:2 # SR 放大倍数
sr_weight:0.1 # SR 损失权重(辅助角色,不要太大)
alignment_weight:0.05# 特征对齐权重
# 常规参数
lr0:0.0005
weight_decay:0.0005
cos_lr:true
batch:4
注意 use_sr 可以关闭。如果数据集图像质量本身很好(不需要 SR 增强),关掉 SR 分支可以减少计算开销,只保留显著性引导模块。
ConvNeXt 是纯卷积架构,天然支持任意输入尺寸:
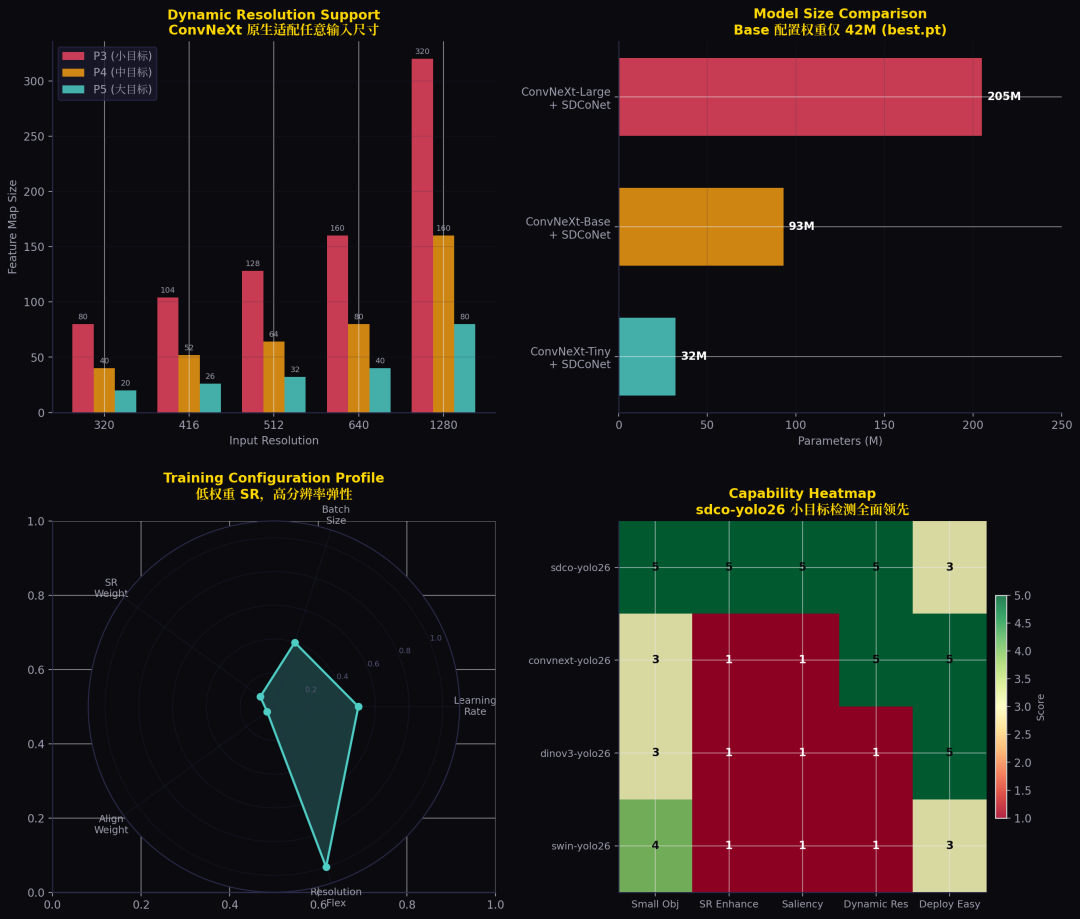
性能数据与动态分辨率
性能数据与动态分辨率
输入尺寸 | P3 特征图 | P4 特征图 | P5 特征图 |
|---|---|---|---|
320×320 | 80×80 | 40×40 | 20×20 |
416×416 | 104×104 | 52×52 | 26×26 |
512×512 | 128×128 | 64×64 | 32×32 |
640×640 | 160×160 | 80×80 | 40×40 |
1280×1280 | 320×320 | 160×160 | 80×80 |
这对于大图切片推理(SAHI)非常友好。
六、模型参数与部署
配置 | 参数量 | 权重文件 |
|---|---|---|
ConvNeXt-Tiny + SDCoNet | ~32M | ~15M |
ConvNeXt-Base + SDCoNet | ~93M | ~42M (best.pt) |
ConvNeXt-Large + SDCoNet | ~205M | ~85M |
Base 配置训练 2 epoch 的权重文件约 42M,推理部署很轻量。支持 ONNX、TensorRT、CoreML、TFLite、OpenVINO 等格式导出,INT8 量化与 FP16 半精度推理完美兼容。
七、和往期文章方案对比
它是唯一同时具备以下能力的:
- 显著性引导:主动发现弱信号目标,不是被动等待
- SR 协同增强:低质量图像恢复细节,不是简单放大
- 梯度路由:多任务优化不冲突,不是简单相加
如果你的场景是工业小缺陷、遥感小目标、或者低分辨率图像检测,这个项目值得优先尝试。
选 sdco-yolo26:小目标、弱信号、低质量图像、需要 640+ 分辨率
- 工业小缺陷检测(PCB、钢材表面、晶圆)
- 遥感小目标(车辆、船舶、飞机)
- 低分辨率图像增强检测
选 convnext-yolo26:通用检测,不需要 SR 增强,追求简洁
- 常规物体检测
- 对推理速度要求极高
- 数据集质量本身较好
选 dinov3-yolo26:少样本、需要强语义迁移
- 新场景快速适配
- 标注数据极少
- 需要利用预训练语义
选 swin-yolo26:对输入分辨率要求不高(224 够用),追求全局建模
- 固定分辨率场景
- 需要长距离依赖建模
- 不介意部署复杂度
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号