
将共享数据share中最大数量属性的类分组
将共享数据share中最大数量属性的类分组
提问于 2022-06-30 16:59:20
我有一组带有独特特征的电影的数据。我想做的是找到最相似的一组电影。
以下是原始数据的示例:
sub_df = pd.DataFrame(columns=['Title', 'Trait'],
data= [['across the universe', 'drug addiction'],
['across the universe', 'romantic'],
['across the universe', 'trippy'],
['across the universe', 'hippy'],
['across the universe', 'rock & roll'],
['walk the line', 'romantic'],
['walk the line', 'rock & roll'],
['walk the line', 'drug addiction'],
['walk the line', 'rebel'],
['dreamgirls', 'singing'],
['dreamgirls', 'yearning'],
['dreamgirls', 'drug addiction'],
['rocketman', 'rock & roll'],
['rocketman', 'drug addiction'],
['rocketman', 'singing'],
['rocketman', 'music biopic'],
['rocketman', 'romantic'],
])我想看的是宇宙中的电影,走在这条线上,还有火箭手,因为虽然他们没有相同的特质,但他们有着比梦想女孩更多的共同特征。
理想情况下,我希望看到那些拥有更多特征的电影集群。
我有数千张这样的记录,每个标题都有一个独特的特征,所以“频率矩阵”看起来就像这样(单元格实际上只有1/0):
PD.crosstab(films_df['Trait'], films_df['Title'], margins=True).sort_values(by = ['All'], ascending = False)
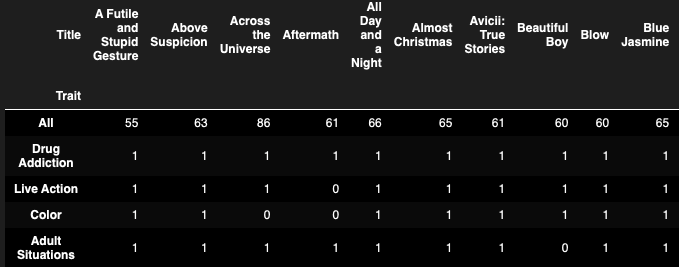
(如有任何帮助,将不胜感激:)
回答 1
Stack Overflow用户
发布于 2022-07-01 13:10:49
我想出了一个解决办法。我想知道有没有办法让它形象化?
# create a dictionary of the films and their traits
film_dict = {}
def add_film(data):
for i in range(len(data)):
film_dict[data.iloc[i]['Title']] = data.iloc[i]['Trait']
add_film(sub_df)
# given dictionary of films and their traits, count the number of similar traits between a film and every other film
film_sims = []
def get_sim(dict):
for film in dict:
for other_film in dict:
if film != other_film:
# bind to dataframe
similar_traits = len(set(dict[film]).intersection(set(dict[other_film])))
new = pd.DataFrame(columns=['film', 'other_film', 'similar_traits'],
data= [[film, other_film, similar_traits]])
# append new to film_sims
film_sims.append(new)
# print(film, other_film)
get_sim(film_dict)
film_sims = pd.concat(film_sims)这将返回如下数据:
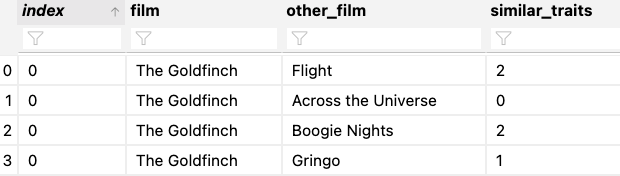
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/72819505
复制相关文章
相似问题
腾讯云开发者
