
如何下载用python完成需要5秒的文件?
如何下载用python完成需要5秒的文件?
提问于 2022-07-28 22:50:52
我正在尝试编写一些代码来下载文件。现在这个来自这个网站的文件,特别是,一旦您继续到那个链接,它需要花费5秒的时间来实际提示下载,例如:https://sourceforge.net/projects/esp32-s2-mini/files/latest/download
我尝试过使用明显的方法,例如wget.download和urllib.request.urlretrieve。
urllib.request.urlretrieve('https://sourceforge.net/projects/esp32-s2-mini/files/latest/download', 'zzz')
get.download('https://sourceforge.net/projects/esp32-s2-mini/files/latest/download', 'zzzdasdas')但是,这不起作用,它下载其他东西,但不是我想要的。
任何建议都会很好。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-07-29 00:43:53
使用chrome的下载页面(ctrl+j应该打开它,或者在下载文件时单击“should”),我们可以看到所有最近的下载。您提供的链接只是开始下载的页面,而不是实际文件本身的位置。右键单击蓝色名称可以将地址复制到正在下载的实际文件中。
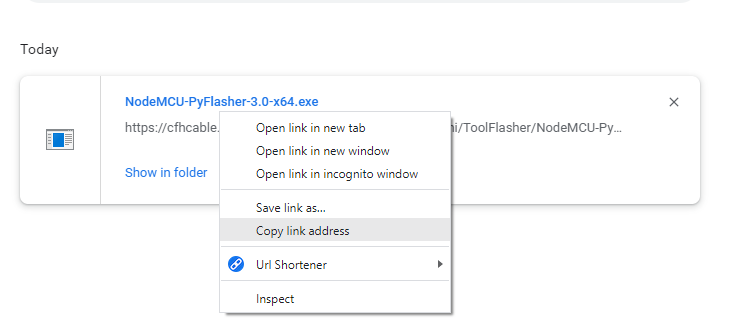
在本例中,文件的实际链接是https://cfhcable.dl.sourceforge.net/project/esp32-s2-mini/ToolFlasher/NodeMCU-PyFlasher-3.0-x64.exe。
然后我们可以发出一个GET请求来下载该文件。使用bash wget进行测试,可以正确下载该文件。
wget https://versaweb.dl.sourceforge.net/project/esp32-s2-mini/ToolFlasher/NodeMCU-PyFlasher-3.0-x64.exe当然,您也可以使用python请求来完成这一任务。
import requests
response = requests.get(r"https://cfhcable.dl.sourceforge.net/project/esp32-s2-mini/ToolFlasher/NodeMCU-PyFlasher-3.0-x64.exe")
with open("NodeMCU-PyFlasher-3.0-x64.exe", "wb") as f:
f.write(response.content)注意,我们使用的是wb (写字节)模式,而不是默认的w (写)模式。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73159965
复制相关文章
相似问题
腾讯云开发者
