
使用Google功能刮取网站
使用Google功能刮取网站
提问于 2021-02-01 06:59:42
我需要刮从这个网站链接的"Cpn比率Ann Amt“细胞。
我试过这样做:
=IMPORTXML("https://www.quantumonline.com/search.cfm?tickersymbol=BAC-P&sopt=symbol","/html/body/font/table/tbody/tr/td[2]/p[1]/table[2]/tbody/tr[2]/td[2]/font")正如我在网上看到的每一个教程所建议的那样,但我就是无法让它发挥作用。也许它只是不起作用,因为网站有.cfm页面。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-02-01 07:39:54
我相信你的目标如下。
- 从
I need to scrape the "Cpn Rate Ann Amt" cell from this website LINK.中,您希望使用IMPORTXML检索Cpn Rate Ann Amt头部的值。
在本例中,下面的示例公式和xpath如何?当我在URL中看到HTML时,我认为<tr bgcolor="FFEFB5">的背景色只是表的颜色,这可能可以用作xpath。
样本公式:
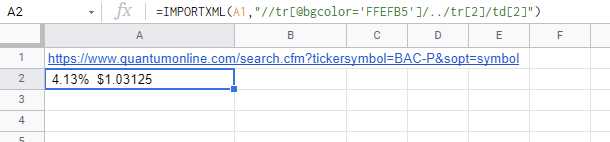
=IMPORTXML(A1,"//tr[@bgcolor='FFEFB5']/../tr[2]/td[2]")- 单元格"A1“具有
https://www.quantumonline.com/search.cfm?tickersymbol=BAC-P&sopt=symbol的URL。
结果:
注意:
- 当您想要
Cpn Rate Ann Amt的值时,也可以使用以下公式。 =IMPORTXML(A1,“//tr@bgcolor=‘FFEFB5 5’/Th2”) - 在这个示例中,公式和xpath用于
https://www.quantumonline.com/search.cfm?tickersymbol=BAC-P&sopt=symbol的URL。因此,当URL被更改时,xpath可能无法工作。所以请小心点。
参考资料:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65988364
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号