
DynamoDB性能差/慢
DynamoDB性能差/慢
提问于 2021-01-29 13:28:57
我在AWS Lambda中有一个非常简单的webservice,使用Python和Flask (服务A)。服务接收请求并执行DynamoDB查询并返回结果。DynamoDB具有随需应变的能力,几乎在所有情况下都返回1个结果。
我使用以下函数执行查询。
class DynamoDB:
def __init__( self ):
session = boto3.Session( )
self.dynamodb = session.resource( 'dynamodb' )
def query( self, table_name, **kwargs ):
# Selected Table
table = self.dynamodb.Table( table_name )
# Request to table
response = table.query( **kwargs )
return response查询表达式
"#user_id = :user_id and begins_with( #sort_key, :sort_key)" 响应尺寸~400 B
我在性能上遇到了一些问题,比如对于单个请求,使用AWS内存的1040 MB,使用128 MB的内存,以及使用95-100 MB的最大内存。除了在DynamoDB查询中消耗的4ms之外,所有时间都是如此。
下面是我增加内存时的响应时间。
128 MB -> 1040 ms
512 MB -> 520 ms
1024 MB -> 210 ms 现在,我在AWS (服务B)中有了另一个and服务,它使用Python、Flask、Pandas和PyODBC。该服务接收一个请求,并向MSSQL服务器执行2个简单查询,而MSSQL服务器不在AWS中托管,并返回结果。此服务有128 MB的内存和使用的最大内存:128 MB(消耗所有内存)。对此服务的单个请求的性能为500 is。
有人能解释一下这怎么可能吗?
是否有任何解决方案使服务A中的查询更快?
回答 2
Stack Overflow用户
回答已采纳
发布于 2021-01-31 09:22:41
我将ddb = DynamoDB()移到处理程序之外,并将lambda函数的内存增加到256 to。因此,我将响应减少到67 As 75 As。
Stack Overflow用户
发布于 2021-01-29 14:31:49
几件可能对你有帮助的事情:
limit.
- Instantiating
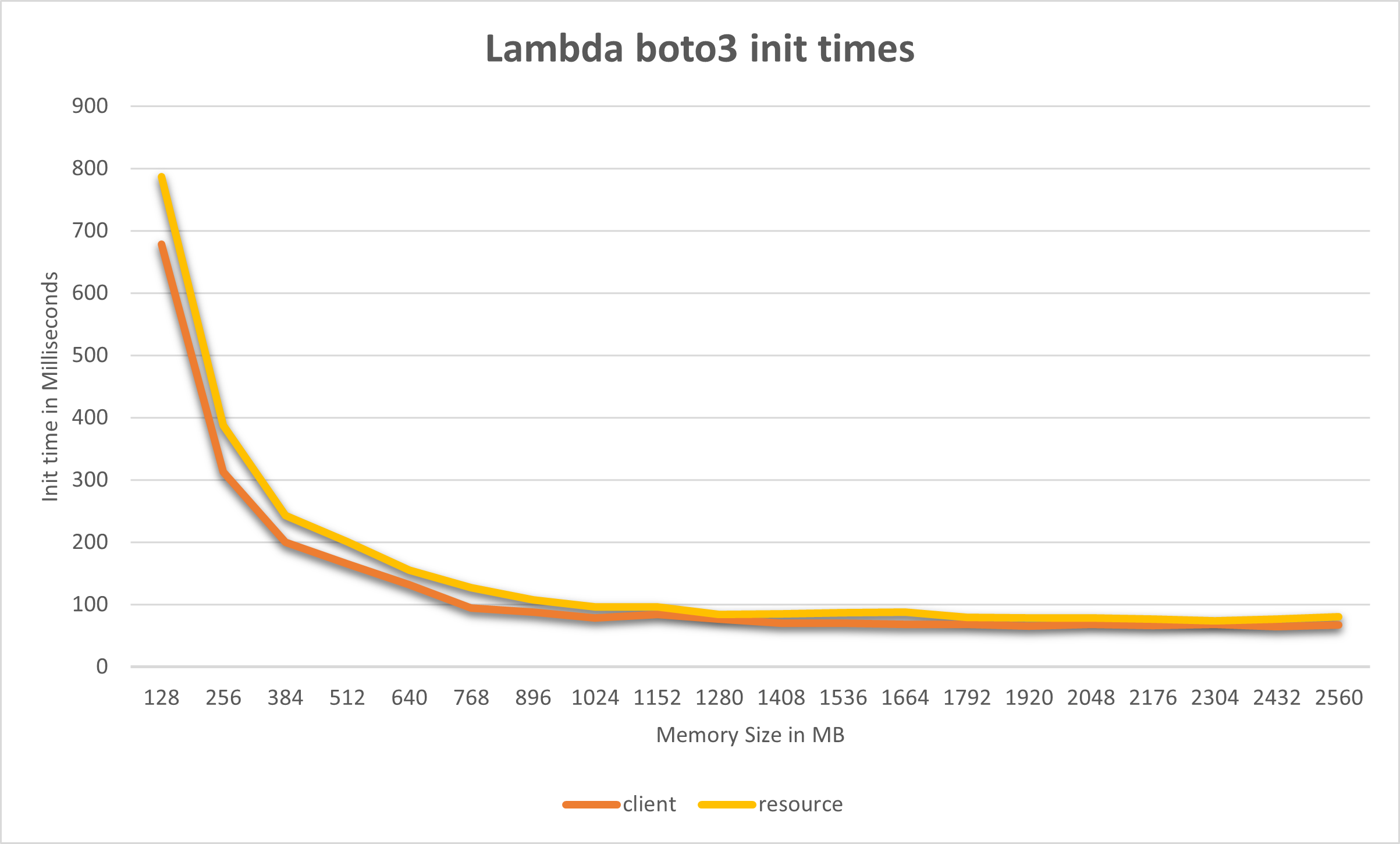
- 您提供的内存数量不仅会影响计算,而且还会影响Lambda函数的网络吞吐量,因此,根据您的工作负载,这可能是一个boto3资源,客户端在计算方面通常比较昂贵,因此缓存这些内存绝对值得,以便从您的时间中节省几毫秒时间--在我的相对强大的笔记本上,实例化第一个boto3客户端或资源需要
150ms,因为在第一次实例化时,它读取和解析一些JSON描述并构建整个对象层次结构,
,
- ,您可以考虑将X射线SDK添加到函数中,并在其上启用X射线。这将使您更详细地了解应用程序的哪一部分以及哪个API调用花了这么长时间。
编辑
男孩在第一次实例化boto3时,内存大小很重要!我在博客上写了一篇关于这个方法的文章,但是如果内存参数非常小,那么在lambda冷启动之后初始化第一个boto3客户机/资源似乎需要很长时间。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/65955409
复制相关文章
相似问题
腾讯云开发者
