
如何循环到达各类链路,提取R中的属性容量座位
如何循环到达各类链路,提取R中的属性容量座位
提问于 2020-10-26 21:20:35
实际上,我想为这个链接中的每个class提取class属性。这是实际的链接https://ssb.bannerprod.memphis.edu/prod/bwckschd.p_get_crse_unsec
如果发布的链接不起作用,请这样做
In this link `https://ssb.bannerprod.memphis.edu/prod/bwckschd.p_disp_dyn_sched`
Select by term -> Spring Term 2021 (view only) -> Submit
Subject -> select ARCH Architecture -> scroll down and click Class Search例如:
对于主题ARCH,类如下所示:
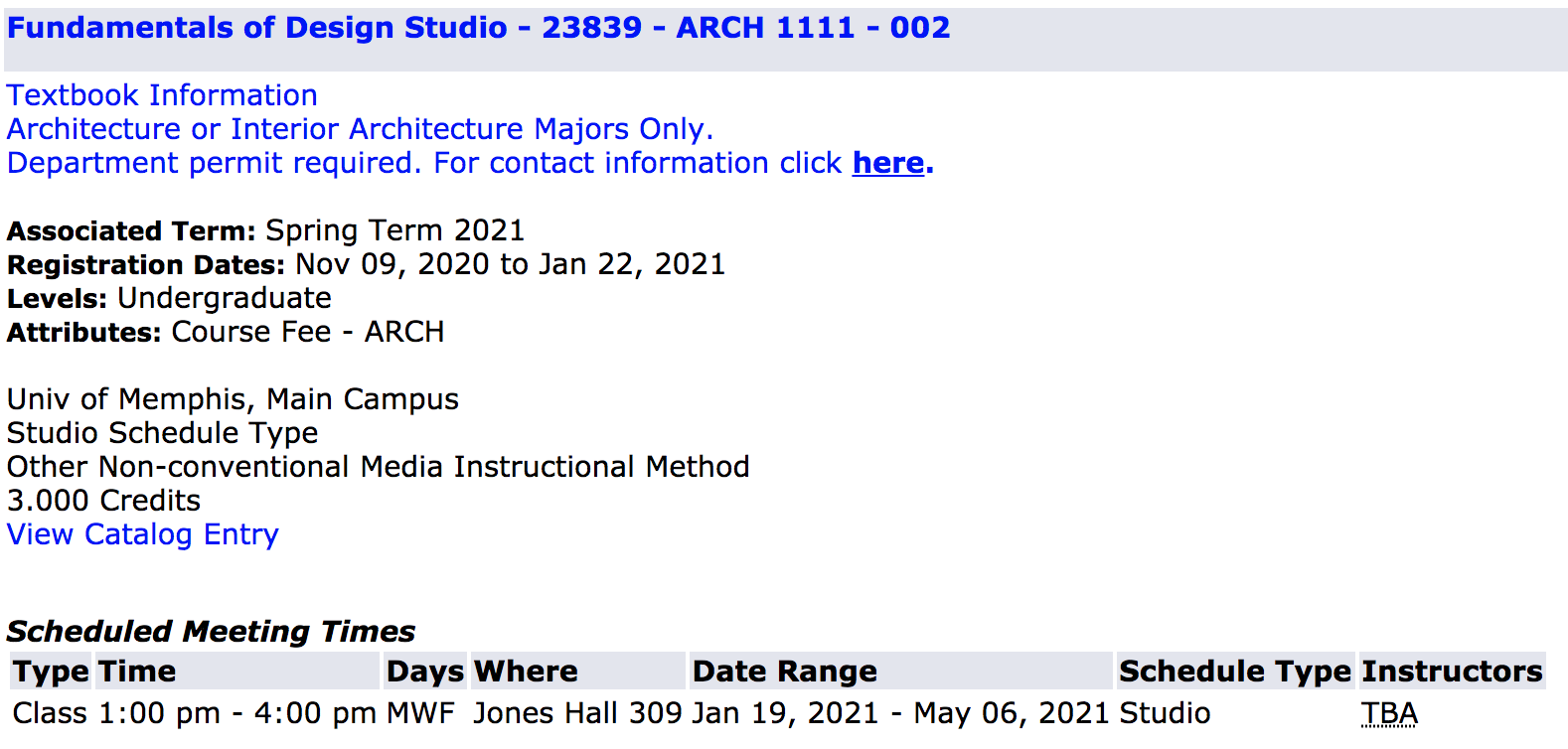
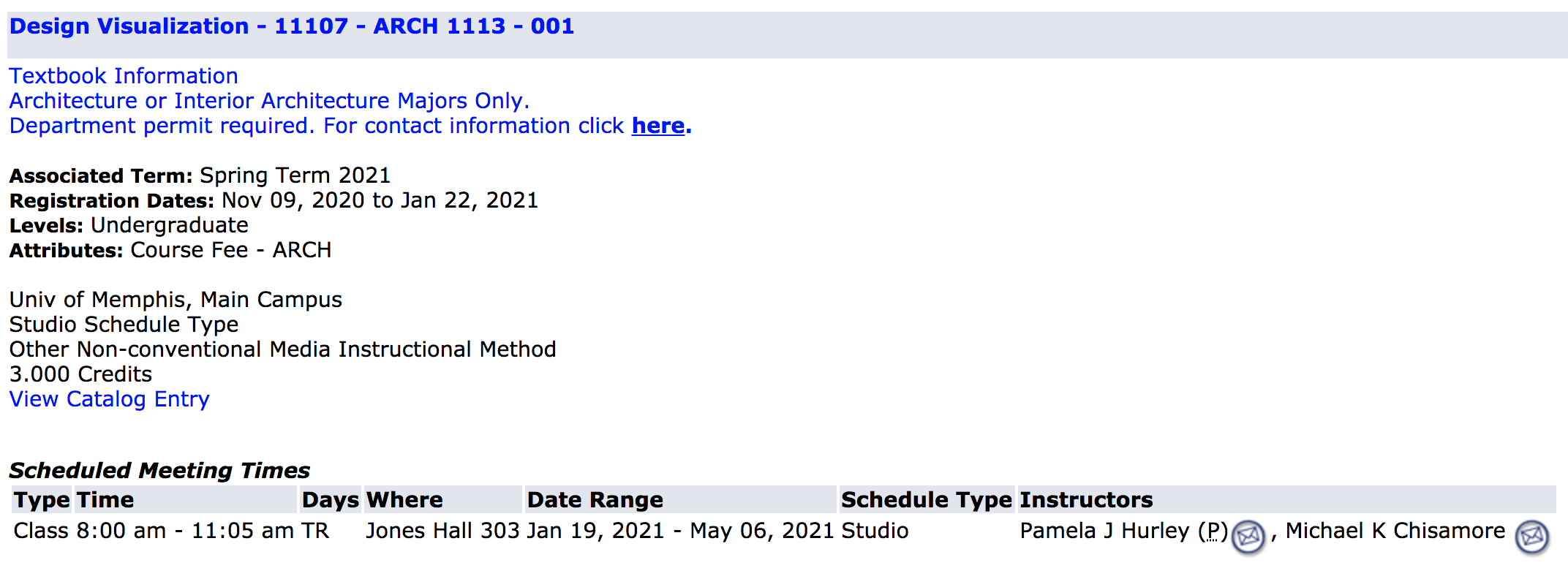
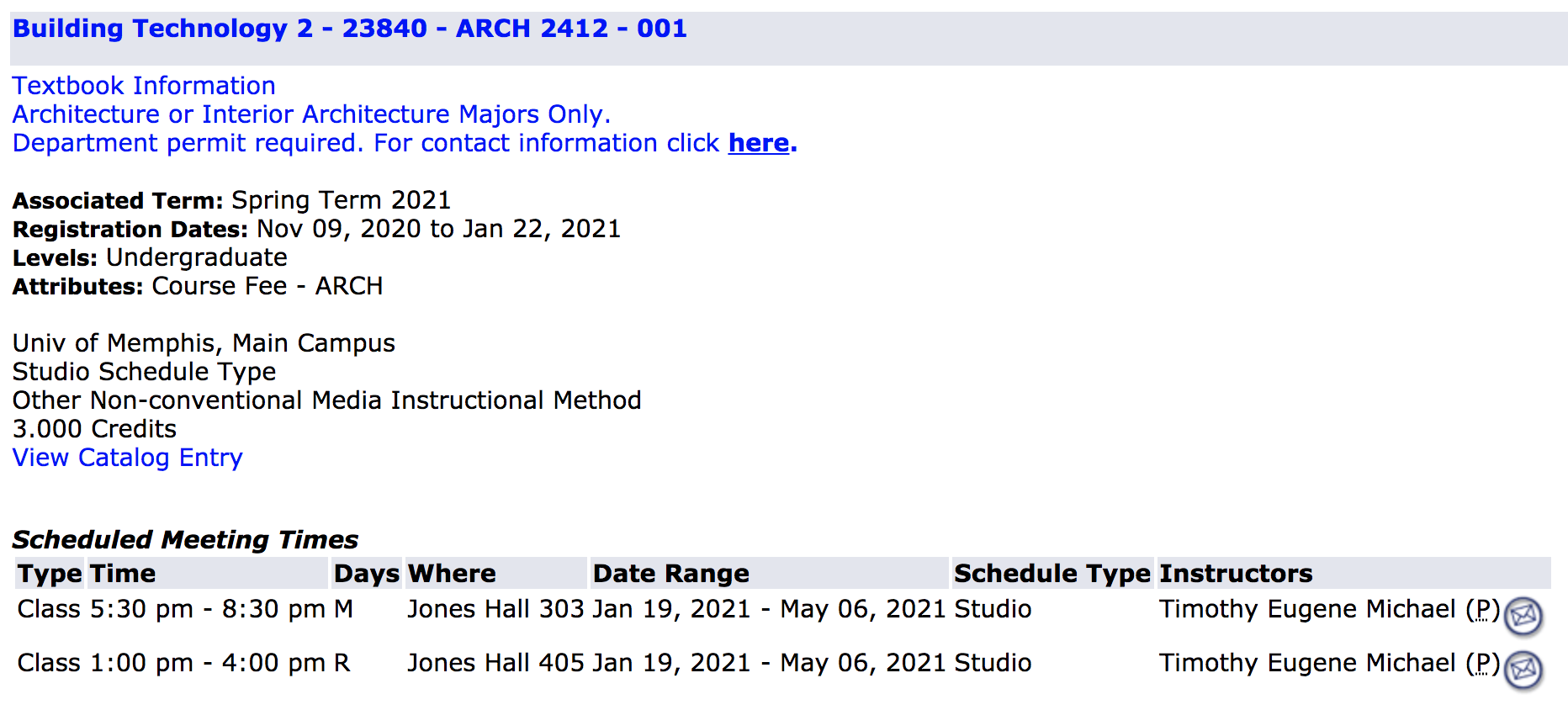
以上图片只是少数几类主题ARCH。尽管如此,还是有很多课程。如果单击每个类,您将看到属性capacity,它显示了seats编号。
我希望输出如下所示:
classes capacity - seats
Fundamentals of Design Studio - 23839 - ARCH 1111 - 002 15
Design Visualization - 11107 - ARCH 1113 - 001 15
Building Technology 2 - 23840 - ARCH 2412 - 001 20如何在R中创建一个循环来获取每个subject的每个class的capacity (seats)属性。
这个问题是我上一篇文章https://stackoverflow.com/questions/64515601/problem-with-web-scraping-of-required-content-from-a-url-link-in-r的延续
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-10-27 22:57:01
此解决方案与以前的解决方案非常相似。
因为指向类大小的链接与类标题位于同一个节点上,所以它更直接。根据您需要清理的类大小表的哪些信息,才能与其余的数据合并。
此外,由于一个将查询多个网页在网站上,请介绍一个轻微的系统暂停,以礼貌和避免出现像黑客。
注没有错误检查以确保正确的表是可用的,我建议您在编写此生产代码之前考虑这一点。
#https://stackoverflow.com/questions/64515601/problem-with-web-scraping-of-required-content-from-a-url-link-in-r/64517844#64517844
library(rvest)
library(dplyr)
# In this link `https://ssb.bannerprod.memphis.edu/prod/bwckschd.p_disp_dyn_sched`
# Select by term -> Spring Term 2021 (view only) -> Submit
# Subject -> select ARCH Architecture -> scroll down and click Class Search
url <- "https://ssb.bannerprod.memphis.edu/prod/bwckschd.p_get_crse_unsec"
query <- list(term_in = "202110", sel_subj = "dummy", sel_day = "dummy",
sel_schd = "dummy", sel_insm = "dummy", sel_camp = "dummy",
sel_levl = "dummy", sel_sess = "dummy", sel_instr = "dummy",
sel_ptrm = "dummy", sel_attr = "dummy", sel_subj = "ARCH",
sel_crse = "", sel_title = "", sel_insm = "%",
sel_from_cred = "", sel_to_cred = "", sel_camp = "%",
sel_levl = "%", sel_ptrm = "%", sel_instr = "%",
sel_attr = "%", begin_hh = "0", begin_mi = "0",
begin_ap = "a", end_hh = "0", end_mi = "0",
end_ap = "a")
html <- read_html(httr::POST(url, body = query))
classes <- html %>% html_nodes("th.ddtitle")
dfs<-lapply(classes, function(class) {
#get class name
classname <-class %>% html_text()
print(classname)
#Pause in order not be a denial of service attach
Sys.sleep(0.5)
classlink <- class %>% html_node("a") %>% html_attr("href")
fulllink <- paste0("https://ssb.bannerprod.memphis.edu", classlink)
newpage <-read_html(fulllink)
#find the tables
tables <- newpage %>% html_nodes("table.datadisplaytable")
#find the index to the correct table
seatingtable <- which(html_attr(tables, "summary") == "This layout table is used to present the seating numbers.")
size <-tables[seatingtable] %>% html_table(header=TRUE)
#may want to clean up table before combining in dataframe
# i.e size[[1]][1, -1]
data.frame(class=classname, size[[1]], link=fulllink)
})
answer <- bind_rows(dfs)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64545146
复制相关文章
相似问题
腾讯云开发者
