
数据库中的DataFrame.show()抛出错误
数据库中的DataFrame.show()抛出错误
提问于 2020-08-11 11:15:27
我正在尝试使用Azure数据库从Azure数据仓库获取数据。
连接部分很好,因为我可以看到在DataFrame中返回的行,但是当我试图在DataFrame中保存或显示记录时,它会引发错误。以下是我尝试过的:
df = spark.read \
.format("com.databricks.spark.sqldw") \
.option("url", sqlDwNew) \
.option("tempDir", temDir_location) \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("query", "select * from AccessPermission") \
.load()
df.count()输出
(1) Spark Jobs
df:pyspark.sql.dataframe.DataFrame
AccessPermissionId:integer
AccessPermission:string
Out[16]: 4错误
df.show()输出
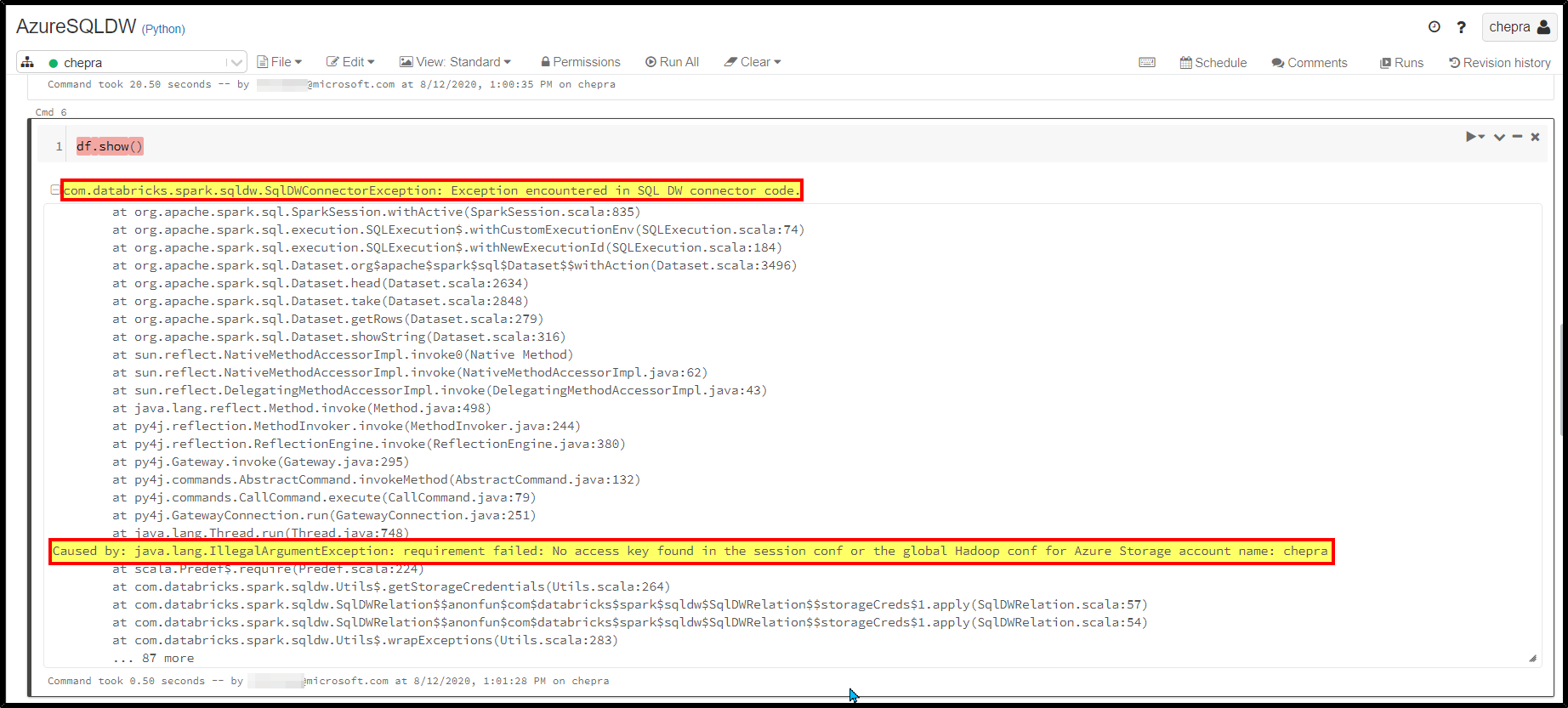
com.databricks.spark.sqldw.SqlDWSideException: SQL DW failed to execute the JDBC query produced by the connector.回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-12 08:13:46
要知道确切的原因,我要求您检查完整的堆栈跟踪,并试图找出问题的根本原因。
根据我的repro,我遇到了完全相同的错误消息,并且能够通过查看堆栈跟踪和发现存储帐户配置的问题来解决这个问题。
com.databricks.spark.sqldw.SqlDWSideException: SQL DW failed to execute the JDBC query produced by the connector.
.
.
.
.
.
Caused by: java.lang.IllegalArgumentException: requirement failed: No access key found in the session conf or the global Hadoop conf for Azure Storage account name: chepra
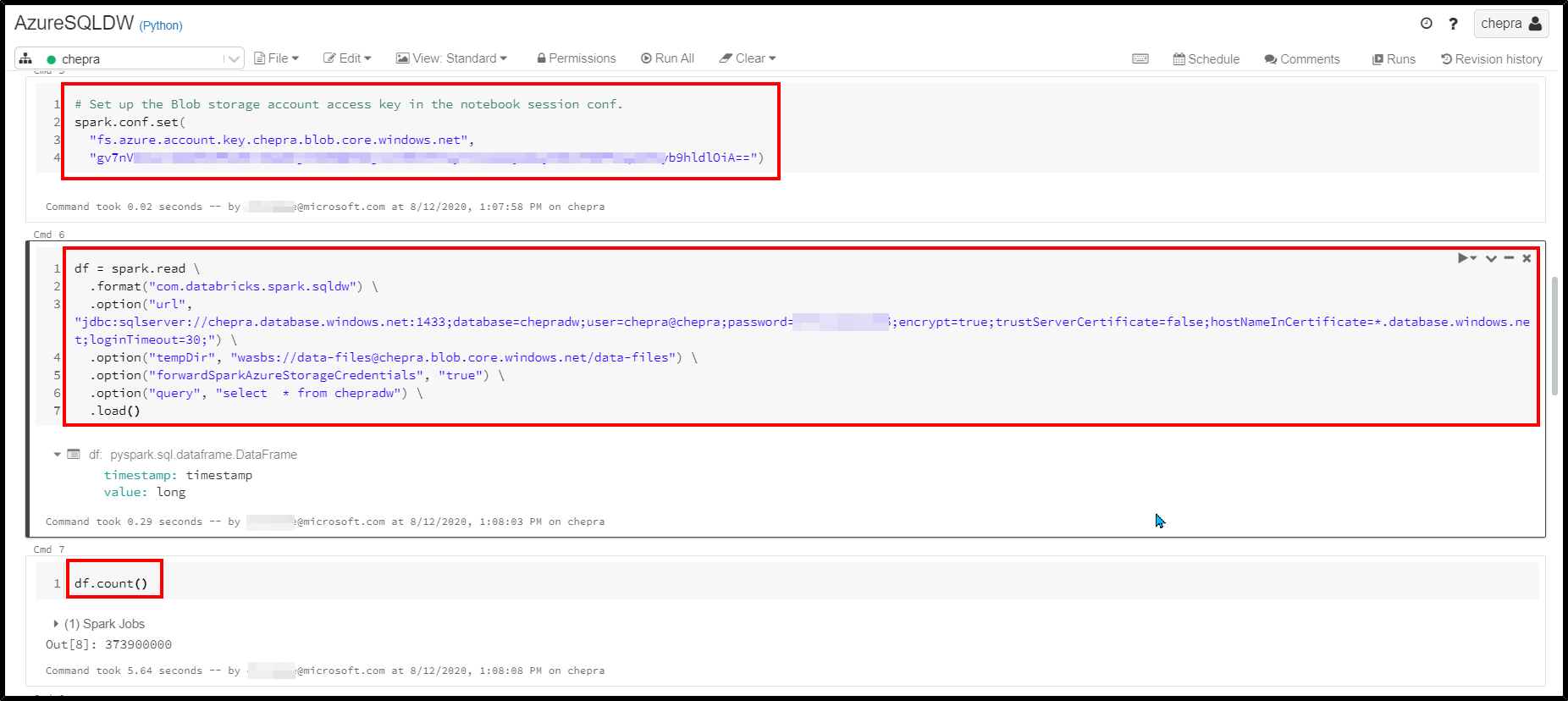
Step1:在笔记本会话配置中设置了Blob存储帐户访问密钥。
spark.conf.set(
"fs.azure.account.key.<your-storage-account-name>.blob.core.windows.net",
"<your-storage-account-access-key>")Step2:从Azure Synapse查询加载数据。
df = spark.read \
.format("com.databricks.spark.sqldw") \
.option("url", "jdbc:sqlserver://<the-rest-of-the-connection-string>") \
.option("tempDir", "wasbs://<your-container-name>@<your-storage-account-name>.blob.core.windows.net/<your-directory-name>") \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("query", "select * from table") \
.load()Step3:显示或显示数据
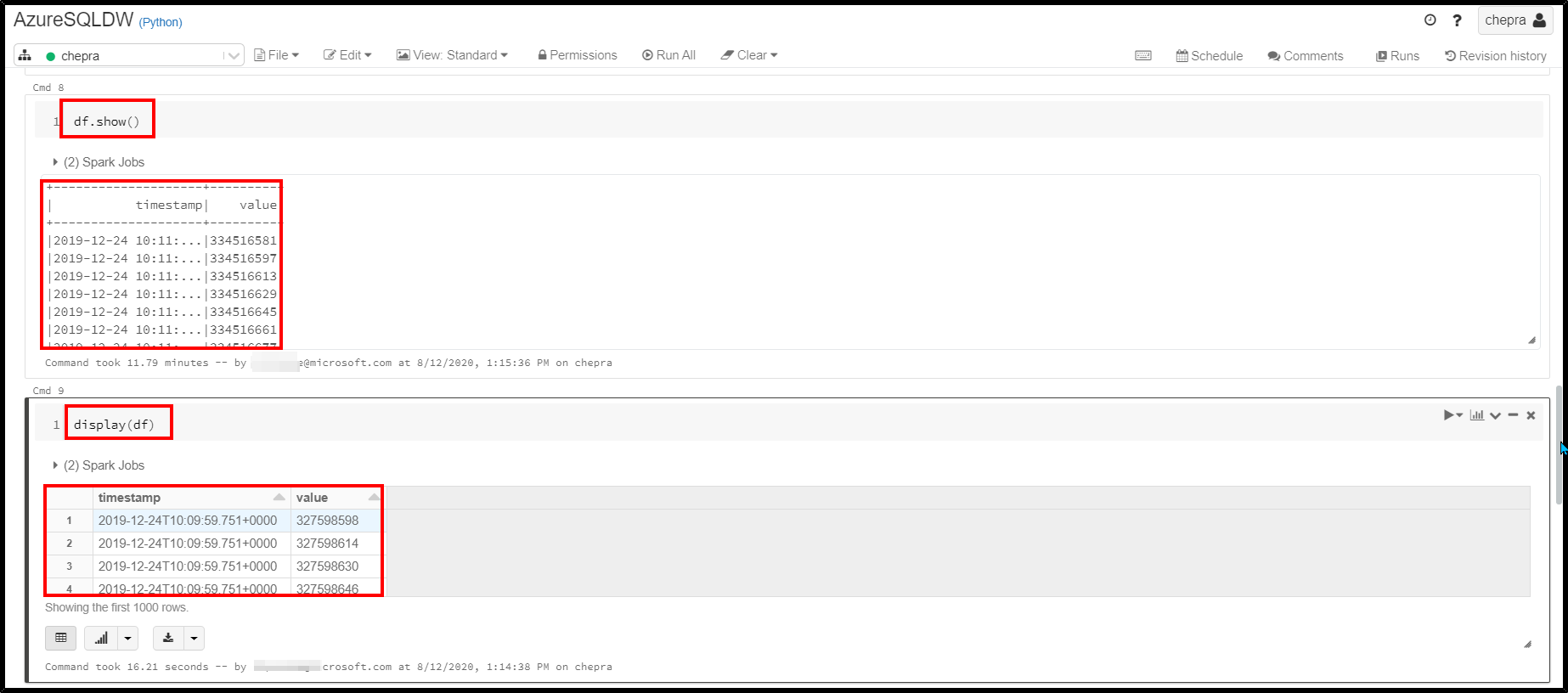
df.show()
display(df)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63357011
复制相关文章
相似问题
腾讯云开发者
