
如何防止Excel从时间戳中删除秒?
我有一个具有第二分辨率的时间序列的DataFrame,我将其保存到一个CSV文件中:
import pandas as pd
dr = pd.date_range('01/01/2020 9:00', '01/01/2020 9:10', freq='1s')
df = pd.DataFrame(index=dr, data=range(len(dr)))
df.to_csv('some_data.csv', header=False)然后,我可以在Excel中打开它,一切看起来都很好:
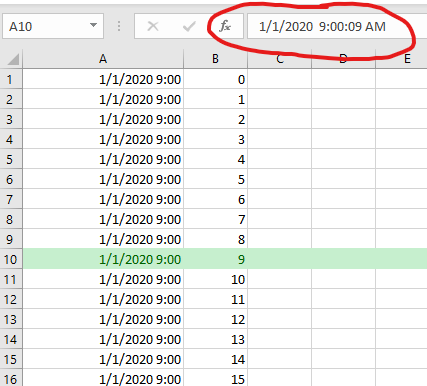
如果我将该文件保存在Excel中(不更改任何内容),则在重新打开时,秒数被舍入为0。

查看记事本中保存的Excel文件会显示秒数丢失了。
1/1/2020 9:00,0
1/1/2020 9:00,1
1/1/2020 9:00,2
...此更改在保存为副本或覆盖时发生。奇怪的是,如果保存后保持原始文档打开,则仍然会看到保存的秒数,直到关闭并重新打开为止。
在上下文中,我正在为其他可能使用Excel与其数据交互的用户(非Python用户)编写文件。甚至调整列的大小都会提示保存,所以我发现它们很可能会无意中丢失数据。
当我使用Python创建这个示例时,我也看到了用其他语言编写的时间戳问题。
是否有更好的方法来记录时间序列数据以防止这种情况发生?或者,Excel中是否有一个修复程序(最好是永久选项或设置),可以与以这种格式获取数据的用户共享?
回答 1
Stack Overflow用户
发布于 2020-07-04 18:00:32
根据这些评论发表答复:
保存为XLSX而不是CSV
直接保存到Excel格式(df.to_excel()而不是df.to_csv()),或者将您的CSV保存为Excel格式。这将保留时间戳,不需要任何额外的格式设置。给 和 的这种方法。
在中对CSV数据的格式化
另一个选项是使用"Format Cell“选项(对于单元格或整个日期列),并使用"Custom”格式(在本例中,将模板"m/d/yyyy :mm“更改为"m/d/yyyy :mm:ss”)。此选项允许您保留CSV格式和时间数据的全部范围。给 的这个答案。。
每个选项都有一个小的缺点。首先,您必须锁定用户使用Excel查看数据。但是有许多免费的工具可以将数据从一种格式转换为另一种格式,因此这对用户来说很容易处理。对于第二个选项,格式设置不是永久性的,每次打开文件时都必须执行。对于用户来说,这似乎不太方便,但在某些情况下仍然很有用。
https://stackoverflow.com/questions/62665687
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号