
新的基数估计器( Server 2014)离我们很远
我有一个数据仓库数据库,我面临新的Server 2014基数估计器的问题。
在将数据库服务器升级到server 2014之后,我发现查询性能有很大差异。有些查询的执行速度要慢得多( SQL 2012为30秒,SQL 2014为5分钟)。在研究了执行计划之后,我发现SQL Server 2014上的基数估计值是远远不够的,我找不到理由。
下面是SQL 2012和SQL 2014中查询执行计划(左上角操作符)的示例:
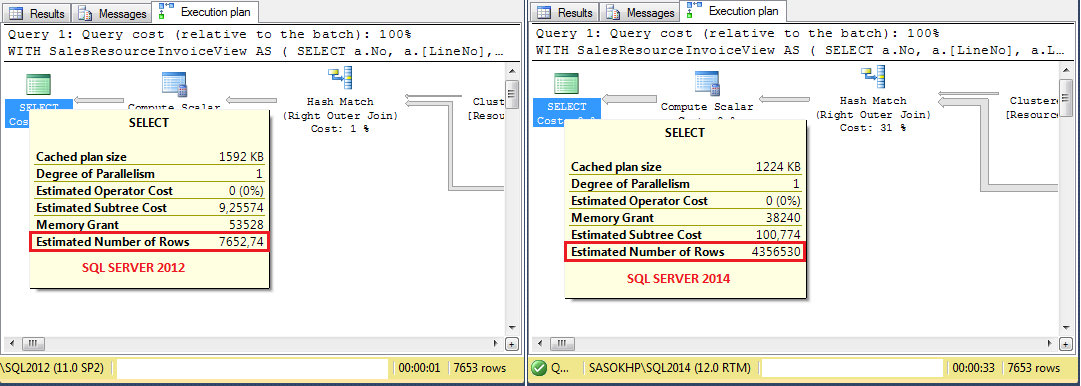
一些细节:
- 我的查询是典型的数据仓库事实表加载查询。我查询一个事务性表并加入很多(15-20)维表(始终有0或1条记录从多维表中加入)。
- 我已经更新了所有表的统计数据(使用FULLSCAN),以确保统计数据是最新的。
- 维度表的业务键被编入索引(唯一的非聚类索引)。在我看来,由于这个索引的唯一性,旧的基数估计器(SQL 2012)正确地假定存在最大值。1连接的记录(执行计划中记录的估计数不会改变)。
我试图将问题缩小到最简单的示例--带有2个联接的SELECT:
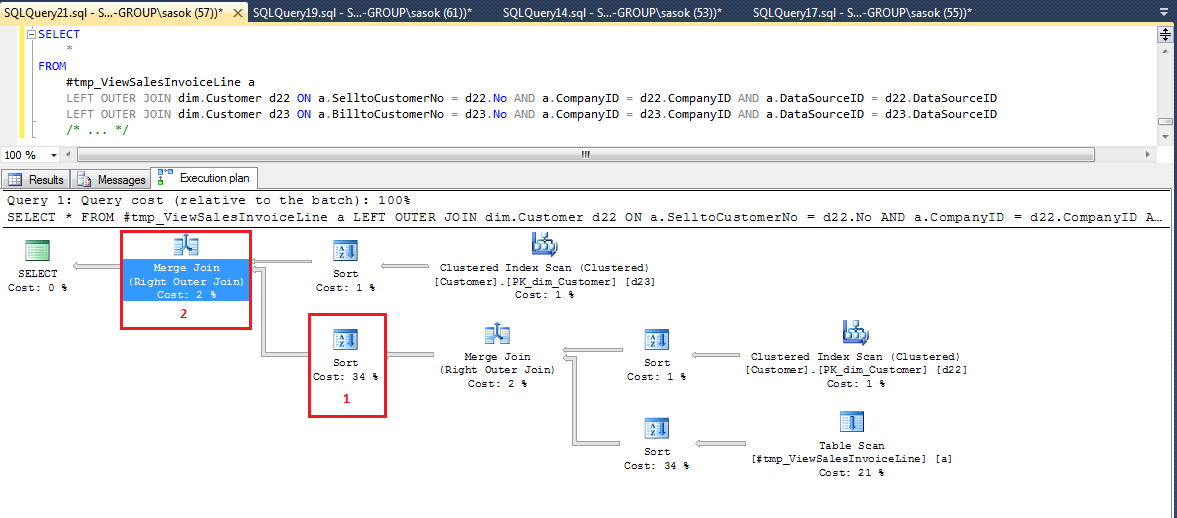
下面是SQL 2012和SQL 2014中操作符1和2的基数估计:
| Est.rows - SQL2012 | Est.rows - SQL2014
Operator 1 | 7653 | 7653
Operator 2 | 7653 | 10000正如您所看到的,Server 2014的漏报率超过30% (10000比7653)。因为我有cca。15-20加入一个典型的查询,最终的估计就会发生变化。
我可以将数据库置于较低的兼容性模式(110)中,然后它可以正常工作(类似于Server 2012),但我真的想知道造成这种行为的原因是什么。为什么Server 2014基数估计的结果是错误的?
回答 3
Stack Overflow用户
发布于 2014-11-10 20:05:13
我认为今天对这个有趣的问题没有简单的答案。我所知道的最好的答案是以下视频:http://channel9.msdn.com/events/TechEd/NorthAmerica/2014/DBI-B331#fbid=。它有许多新的和旧的估计量的例子。视频是关于50+分钟长,但它是值得的时间。
与这一问题有关的视频摘要:
基数估计的旧假设:
- 均匀性-数据均匀分布。
- 独立-第1栏与第2栏无关。
- 包容-当两个属性可能是相同的,它们被假定是相同的。
- 包括-应该有匹配的。
若要在SQL SERVER 2014中使用SQL SERVER 2012基数估计器,请使用以下选项:
- 选项(querytraceon 9481) -恢复到2012年
新的估计器在做什么(基于视频):
- Server在索引中使用平均选择性,并通过将键的密度乘以索引中的行总数来估计行数。
- 对于锯齿分布,新的估计器不能很好地工作。
- 估计量之间的大多数差异都是基于WHERE子句的。
- 新的基数估计器认为表之间存在相关性。
- 您可以创建筛选的统计信息以改进查询。(http://msdn.microsoft.com/en-us/library/ms188038.aspx )
做/核对表:
1. Auto Create / Update Stats
2. Check database compatibility mode (120/110)
3. Test using query trace flags
4. XML showplan更新基数估计器中的新内容( Server 2016)
- 越准确。
- CE预测查询可能返回多少行
- Server 2016查询存储区
- 跟踪CE基数预测的另一个选项是使用名为query_optimizer_estimate_cardinality的扩展事件
- 行政长官明白最大值可能较上次收集统计数字时为高。
- CE明白,在同一表上筛选的谓词通常是相关的。
- CE不再假设来自不同表的筛选谓词之间存在任何相关性。
更多详细信息:
https://www.sqlshack.com/query-optimizer-changes-in-sql-server-2016-explained/
Stack Overflow用户
发布于 2015-02-01 06:16:43
我想知道,你是否正围绕着多色选择性估计来探讨这个问题:
http://www.sqlskills.com/blogs/kimberly/multi-column-statistics-exponential-backoff/
似乎仍然有一些怪癖与新的CE尝试也使用TF 4137概述,看看这是否有帮助。
最后,请确保您在最新的CU上,并与TF 4199一起运行,以覆盖启用所有查询优化器修复程序(如果可能的话),在非生产环境中对此进行测试(如果可能的话),并在全局启用设置时注意其他查询中的回归。
Stack Overflow用户
发布于 2016-10-10 06:33:40
这并不是对这个问题的直接回答,但它可能有助于那些面临与SCCM (又名ConfigMgr)数据库有关的与基数估计(CE)更改相关的类似性能问题的人。由于Server 2014和Server 2016中新的基数估计(CE)更改,SQL查询可能超时或ConfigMgr控制台运行缓慢。微软已经给出了这个问题的解决方案,这里建议应用适当的SQL基数估计(CE)兼容性级别,如下表所示:
SQL Server version Supported compatibility Recommended compatibility
level values level for ConfigMgr
SQL Server 2016 130, 120, 110, 100 130
SQL Server 2014 120, 110, 100 110希望这能有所帮助!
https://stackoverflow.com/questions/26528713
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号