
使用SQLAlchemy加速Pandas Dataframe插入Postgres DB
我有一个大约100 K行的postgres表。我提取了这个数据集并进行了一些转换,得到了一个包含100 K行的新熊猫数据。现在,我希望将此数据作为数据库中的一个新表加载。我使用to_sql来使用SQLAlchemy连接将数据转换为postgres表。然而,这是非常缓慢的,需要几个小时。如何使用SQLAlchemy加速数据库表中的数据插入?我想把插入速度从几个小时提高到几秒钟?有人能帮我吗?
我搜索了其他类似的关于Stackoverflow的问题。它们中的大多数将数据转换为csv文件,然后使用copy_from进行sql。我期待一个解决方案使用SQLAlchemy批量插入语句与熊猫数据。
下面是我的代码的一个小版本:
from sqlalchemy import *
url = 'postgresql://{}:{}@{}:{}/{}'
url = url.format(user, password, localhost, 5432, db)
con = sqlalchemy.create_engine(url, client_encoding='utf8')
# I have a dataframe named 'df' containing 100k rows. I use the following code to insert this dataframe into the database table.
df.to_sql(name='new_table', con=con, if_exists='replace')回答 1
Stack Overflow用户
发布于 2019-10-03 09:42:48
如果熊猫版本在0.24以上,试试下面的模型
DBs的替代to_sql()方法,该方法支持从io导入StringIO从导入csv复制 def psql_insert_copy(表、康涅狄格、键、data_iter):#获取一个DBAPI连接,该连接可以提供游标dbapi_conn = conn.connection和dbapi_conn.cursor()为cur: s_buf = StringIO() writer = csv.writer(s_buf) writer.writerows(data_iter) s_buf.seek(0) 列= ',‘.join(’{}“‘.format(K)表示k in键)如果table.schema: table_name =’{}。{}‘.format(table.schema,table.name),否则: table_name = table.name sql = 'COPY {}(}})从STDIN中复制{}({}}),使用CSV’..format( table_name,列) cur.copy_expert(sql=sql,file=s_buf) chunksize = 10 4 #取决于服务器配置。对于我的例子104 ~10**5是可以的。df.to_sql('tablename',con=con,if_if=‘chunksize=’,method=psql_insert_copy,chunksize= chunksize)
如果您使用上述psql_insert_copy模式,并且您的postgresql服务器正常工作,您应该享受飞行速度。
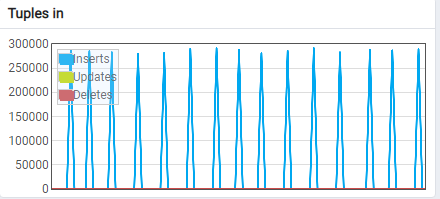
这是我的ETL速度。平均每批280~300 K元组(以秒计)。
https://stackoverflow.com/questions/44517976
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号