在接收多个Gbit/s流量的数据包记录器应用程序中执行磁盘IO的好/实用策略是什么?
考虑以下情况:
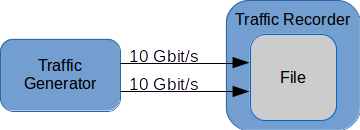
业务生成器生成20 Gbit/s的网络流量,并使用两个10 Gbit链路将其发送给流量记录器。在流量记录器内,所有数据包都应该写到一个文件中。
这就是我试图从更高层次的角度去做的。现在来看一下数据包记录器的内部结构:
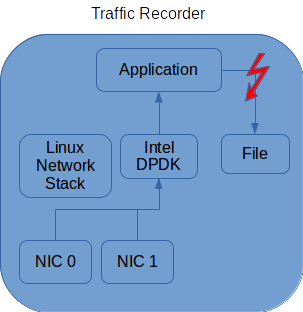
两个NIC都使用Intel (http://dpdk.org/)来处理传入的数据包。因此,所有传入的通信量都存储在预先分配的mbuf结构池的mbuf结构中,该mbuf结构位于上服务器空间。到目前为止一切都很好。所有数据包都到达应用程序。如果需要聚合数据,甚至可以将每个包都存储到更大的缓冲区中。
我遇到的困难是将数据写入文件。我试图用应用程序和文件之间的红色闪光灯来表示这一点。
到目前为止,我采取的任何一种方法都没有奏效。其中一些是:
- Memcpy‘’ing数据包进入一个更大的(预先分配的)缓冲区,并在缓冲区已满时写入文件。
- 与1相同,但具有独立线程,用于使用多个缓冲区进行缓冲和写入。
- 类似于2,但使用线程池
- 用Linux异步写入
- 内存映射文件
在应用程序的执行过程中,我使用iostat来监视磁盘利用率。大多数时候,磁盘利用率不是很高,或者磁盘根本不写。
我的想法是,它应该不断地写入数据到磁盘尽可能快。当数据包以20 Gbit/s的速度传入时,磁盘需要写2.5G字节/s(理论)。
需要注意的一件重要的事情是,磁盘需要足够快才能处理那么多的数据。我使用fio (https://github.com/axboe/fio)测量IO性能,如果做对了,应该没有问题,这样才能达到足够的速度。不过,正确的做法才是问题所在。
在这种情况下,实现磁盘IO最大化的好策略/解决方案是什么?
如何提高磁盘利用率?
任何来源(文学,博客,.)与这一主题相关的内容也将受到欢迎。
谢谢。
编辑1: --这是方法1的一些示例代码。我稍微简化了一些代码,但实际上并没有太多的内容。我试着在不同数量的线程上运行它,具有不同的缓冲区大小,而不是写,等等。
1 static int32_t store_data(struct storage_config *config)
2 {
3 sturct pkt *pkts[MAX_RECV];
4 char *buf = malloc(BUF_SIZE);
5 uint32_t bytes_total = 0;
6
7 while (config->running) {
8 uint32_t nb_recv = receive_pkts(pkts);
9 for (uint32_t i = 0; i < nb_recv; ++i) {
10 if (bytes_total + pkts[i]->len > BUF_SIZE) {
11 write(config->fd, buf, bytes_total);
12 bytes_total = 0;
13 }
14 memcpy(buf + bytes_total, pkts[i]->data, pkts[i]->len);
15 bytes_total += pkts[i]->len;
16 }
17 }
18 return 0;
19 }其他方法以类似的方式编写。例如,线程池变化使用多个缓冲区而不是一个,并将该缓冲区传递给另一个线程。因此,将第11行中的写调用提取到它自己的函数中,线程将在该行上执行IO任务,store_data()函数将使用其中一个附加缓冲区。
编辑2:在提及Andriy的回答时,我采纳了他的建议并使用了书面形式。应用程序现在看起来如下所示:
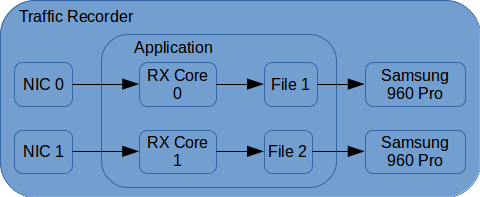
在两个rx核(DPDK)中的每个核上运行以下代码:
while (quit_signal == false) {
nb_rx = rte_eth_rx_burst(conf->port, 0, pkts, RX_RING_BURST_SIZE);
if (nb_rx == 0) { continue; }
for (i = nb_enq; i < nb_rx; ++i) {
len = rte_pktmbuf_pkt_len(pkts[i]);
nb_bytes_total += len;
iov[iov_index].iov_len = len;
iov[iov_index].iov_base = rte_pktmbuf_mtod(pkts[i], char *);
rte_pktmbuf_free(pkts[i]);
++iov_index;
if (iov_index >= IOV_MAX) {
if (writev(conf->fd, iov, IOV_MAX) != nb_bytes_total) {
printf("Couldn't write all data\n");
}
iov_index = 0;
nb_bytes_total = 0;
}
}
}(RX_RING_BURST_SIZE是32,因为默认情况下,这是DPDK的最大值,而我不知道如何更改它。我不知道这会不会有什么区别)
当两个NIC接收到大约10 Gbit/s (1.25 G字节/s)的通信量时,当数据包大小为1024字节时,大约一半的数据丢失。如果数据包大小为64字节,性能甚至会更差,大约80%的数据会丢失。这有点道理,因为较小的数据包意味着更多的系统,而rx环的填充速度更快。根据iostat的说法,没有意义的是,驱动器大部分时间都没有全速写入。
回答 2
Stack Overflow用户
发布于 2017-10-12 05:24:02
这个问题太宽泛了,但总的来说:
- 避免文件系统,即使用原始分区/设备。
- 看看SPDK。它类似于DPDK,但用于存储(NVMe):http://www.spdk.io/
编辑1:
在您提供的代码片段中,应该使用单个writev()调用,而不是循环+ memcpy + write()。另外,从片段中还不清楚实际的突发大小是多少。最好合并几个小的突发,然后在一个syscall中编写它们。
编辑2:
- 在实际编写之前,代码中有一个bug : rte_pktmbuf_free()。
- MAX_IOV在我的平台上是1024,所以最好在调用写之前将一些突发信息合并到IOV_MAX上。
- 若要避免轮询核心上的syscalls,请使用另一个lcore进行写入。在核之间使用单个生产者单消费环缓冲器。
- 由于您已经熟悉了fio,并且它的性能对您来说还可以,所以请使用与fio相同的方法,即相同的IO引擎、类型等。
- 创建一个测试应用程序,它在循环中写入相同的缓冲区,即消除代码的RX部分,只测量编写性能。
https://stackoverflow.com/questions/46710357
复制相似问题
腾讯云开发者
