
如何在Keras中建立一个递归神经网络,其中每个输入首先通过一个层?
如何在Keras中建立一个递归神经网络,其中每个输入首先通过一个层?
提问于 2018-02-15 23:27:51
我试图在Keras上建立一个神经网络,它看起来像这样:
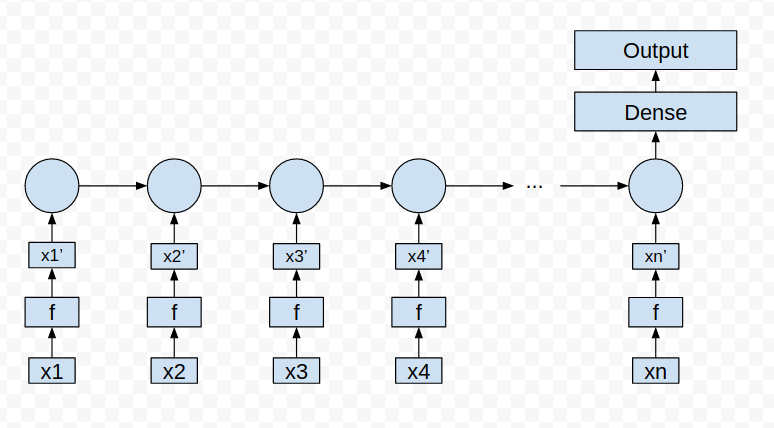
x_1,x_2,..。是经历同样变换的输入向量。f本身是一个必须学习其参数的层。序列长度n在实例之间是可变的。
我在这里很难理解两件事:
- 输入应该是什么样子? 我在考虑一个二维张量,形状(number_of_x_inputs,x_dimension),其中x_dimension是单个向量$x$的长度。这样的二维张量能有可变的形状吗?我知道张量可以有可变形状的批处理,但我不知道这是否对我有帮助。
- 在将输入向量输入到RNN层之前,如何通过相同的转换传递它? 是否有某种方式来扩展,例如GRU,以便在通过实际GRU单元之前添加f层?
回答 1
Stack Overflow用户
发布于 2018-02-17 09:08:19
我不是专家,但我希望这能帮上忙。
问题1:
向量x1,x2.xn可以有不同的形状,但我不确定x1的实例是否有不同的形状。当我有不同的形状时,我通常用0来填充短序列。
问题2:
我不确定是否要扩展GRU,但我会这样做:
x_dims = [50, 40, 30, 20, 10]
n = 5
def network():
shared_f = Conv1D(5, 3, activation='relu')
shated_LSTM = LSTM(10)
inputs = []
to_concat = []
for i in range(n):
x_i = Input(shape=(x_dims[i], 1), name='x_' + str(i))
inputs.append(x_i)
step1 = shared_f(x_i)
to_concat.append(shated_LSTM(step1))
merged = concatenate(to_concat)
final = Dense(2, activation='softmax')(merged)
model = Model(inputs=inputs, outputs=[final])
# model = Model(inputs=[sequence], outputs=[part1])
model.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
return model
m = network()在这个例子中,我使用了一个Conv1D作为共享的f转换,但是您可以使用其他的东西(嵌入等等)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48817914
复制相关文章
相似问题
腾讯云开发者
