
不更新权重的tensorflow模型
我有一个模型,就是训练(它经历了步骤和阶段,评估损失),但权重不是训练。
我试着训练一个鉴别器来区分图像是合成的还是真实的。这是甘斯模型的一部分,我正在努力建造。
基本结构如下:
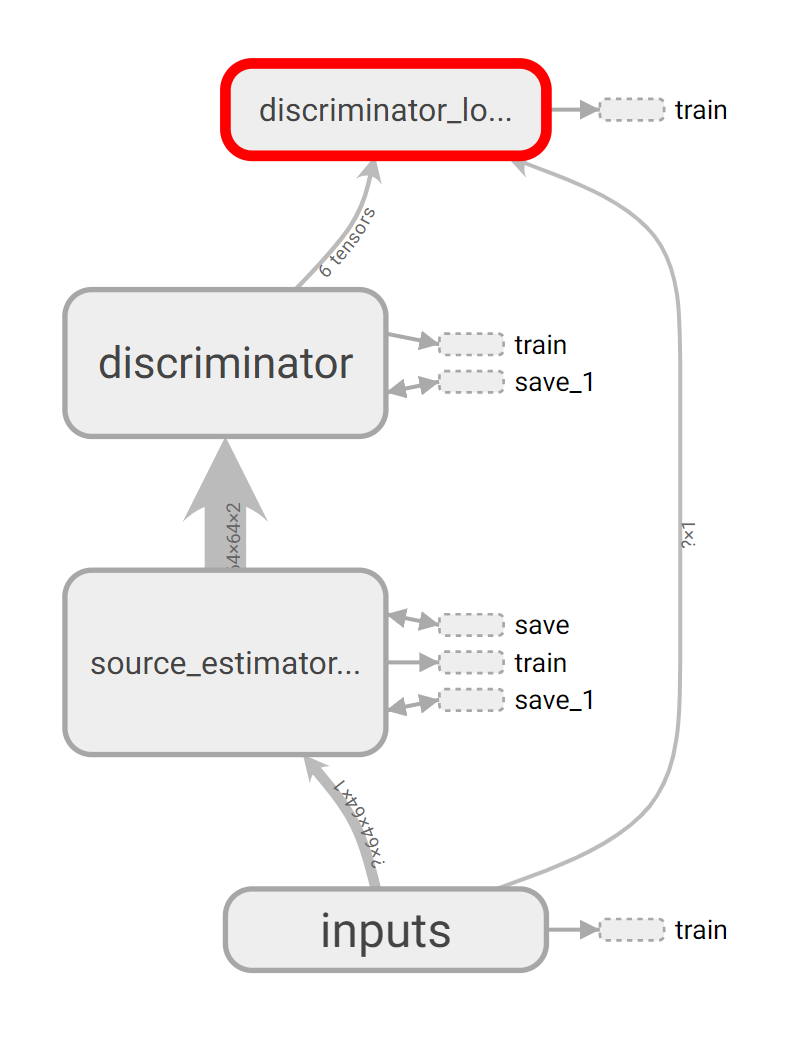
我有两个输入: 1.图像(可以是真实的,也可以是合成的) 2.标签(0表示真实,1表示合成)
源估计是我从图像中提取特征的地方。我已经训练了模型,恢复了重量和偏差。这些层被冻结(不可训练)。
def SourceEstimator(eye, name, trainable = True):
# source estimator and target representer shares the same structure.
# SE is not trainable, while TR is.
net = tf.layers.conv2d(eye, 32, 3, (1,1), padding='same', activation=tf.nn.leaky_relu, trainable=trainable, name=name+'_conv2d_1')
net = tf.layers.conv2d(net, 32, 3, (1,1), padding='same', activation=tf.nn.leaky_relu, trainable=trainable, name=name+'_conv2d_2')
net = tf.layers.conv2d(net, 64, 3, (1,1), padding='same', activation=tf.nn.leaky_relu, trainable=trainable, name=name+'_conv2d_3')
c3 = net
net = tf.layers.max_pooling2d(net, 3, (2,2), padding='same', name=name+'_maxpool_4')
net = tf.layers.conv2d(net, 80, 3, (1,1), padding='same', activation=tf.nn.leaky_relu, trainable=trainable, name=name+'_conv2d_5')
net = tf.layers.conv2d(net, 192, 3, (1,1), padding='same', activation=tf.nn.leaky_relu, trainable=trainable, name=name+'_conv2d_6')
c5 = net
return (c3, c5)歧视者如下:
def DiscriminatorModel(features, reuse=False):
with tf.variable_scope('discriminator', reuse=tf.AUTO_REUSE):
net = tf.layers.conv2d(features, 64, 3, 2, padding='same', kernel_initializer='truncated_normal', activation=tf.nn.leaky_relu, trainable=True, name='discriminator_c1')
net = tf.layers.conv2d(net, 128, 3, 2, padding='same', kernel_initializer='truncated_normal', activation=tf.nn.leaky_relu, trainable=True, name='discriminator_c2')
net = tf.layers.conv2d(net, 256, 3, 2, padding='same', kernel_initializer='truncated_normal', activation=tf.nn.leaky_relu, trainable=True, name='discriminator_c3')
net = tf.contrib.layers.flatten(net)
net = tf.layers.dense(net, units=1, activation=tf.nn.softmax, name='descriminator_out', trainable=True)
return net输入到SourceEstimator模型并提取特性(c3、c5)。
然后将c3和c5沿信道轴连接,并传递给鉴别器模型。
c3, c5 = CommonModel(self.left_eye, 'el', trainable=False)
c5 = tf.image.resize_images(c5, size=(self.config.img_size,self.config.img_size))
features = tf.concat([c3, c5], axis=3)
##---------------------------------------- DISCRIMINATOR ------------------------------------------##
with tf.variable_scope('discriminator'):
logit = DiscriminatorModel(features)最终损失与train_ops
##---------------------------------------- LOSSES ------------------------------------------##
with tf.variable_scope("discriminator_losses"):
self.loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logit, labels=self.label))
##---------------------------------------- TRAIN ------------------------------------------##
# optimizers
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
disc_optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate)
self.disc_op = disc_optimizer.minimize(self.loss, global_step=self.global_step_tensor, name='disc_op')火车的步子和时代。我用的是32批。和数据生成器类来获取图像的每一步。
def train_epoch(self):
num_iter_per_epoch = self.train_data.get_size() // self.config.get('batch_size')
loop = tqdm(range(num_iter_per_epoch))
for i in loop:
dloss = self.train_step(i)
loop.set_postfix(loss='{:05.3f}'.format(dloss))
def train_step(self, i):
el, label = self.train_data.get_batch(i)
## ------------------- train discriminator -------------------##
feed_dict = {
self.model.left_eye: el,
self.model.label: label
}
_, dloss = self.sess.run([self.model.disc_op, self.model.loss], feed_dict=feed_dict)
return dloss当模型经过步骤和周期时,重量保持不变。
损失在训练过程中波动,但每个时期的损失都是一样的。例如,如果我不对每个时代的数据集进行洗牌,那么图表上的丢失将遵循相同的模式。
我认为这意味着模型能够识别不同的损失,而不是根据损失来更新参数。
以下是我尝试过但没有帮助的其他几件事:
- 尝试小和大的学习率(0.1和1e-8)
- 尝试使用SourceEstimator层trainable==True
- 翻转标签(0 ==合成,1 ==真实)
- 在鉴别器中增加内核大小和过滤器大小。
我已经在这个问题上被困了一段时间了,我真的需要一些洞察力。提前谢谢。
编辑1
def initialize_uninitialized(sess):
global_vars = tf.global_variables()
is_initialized= sess.run([tf.is_variable_initialized(var) for var in global_vars])
not_initialized_vars = [v for (v, f) in zip(global_vars, is_initialized) if not f]
# for var in not_initialized_vars: # only for testing
# print(var.name)
if len(not_initialized_vars):
sess.run(tf.variables_initializer(not_initialized_vars))
self.sess = tf.Session()
## inbetween here I create data generator, model and restore pretrained model.
self.initilize_uninitialized(self.sess)
for current_epoch in range(self.model.current_epoch_tensor.eval(self.sess), self.config.num_epochs, 1)
self.train_epoch() # included above
self.sess.run(self.model.increment_current_epoch_tensor)回答 2
Stack Overflow用户
发布于 2018-12-07 07:22:08
我可以看到,您正在调用session.run()中的minimize和loss函数。您应该只调用minimize()函数。即只有self.model.disc_op,它将内部调用损失函数。而且,我在任何地方都看不到您的会话初始化调用。确保它只被叫一次。
查看更新的代码,我可以看到,您将tf.is_variable_initialized()调用等同于is_not_initialized。因此,它正在初始化已经初始化的变量。
Stack Overflow用户
发布于 2018-12-11 06:45:34
我从来没有发现代码有什么问题。
我的同事建议在不同的孤立环境中尝试相同的模型,所以我使用Keras重写了代码。
现在起作用了。:/
我们仍然不知道上面的代码到底出了什么问题--我没有改变任何东西。我甚至使用相同的代码进行重量转移和变量初始化。
如果有人遇到类似的问题,我建议在不同的环境中尝试相同的模式。
或者,如果有人知道上面的代码有什么问题,请分享!
https://stackoverflow.com/questions/53664423
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号