Power Query 真经 - 第 6 章 - 从Excel导入数据

Power Query 真经 - 第 6 章 - 从Excel导入数据

BI佐罗
发布于 2022-05-17 08:31:34
发布于 2022-05-17 08:31:34
毫无疑问,对于开始就以表格形式处理数据的人来说,最简单的方法之一是打开 Excel 并开始在工作表中记录数据。虽然 Excel 并不是真正打算充当数据库的角色,但这正是实际发生的事情,因此 Power Query 将 Excel 文件和数据视为有效数据源。
与所有数据都存储在一个工作表中的 “平面” 文件不同,Excel 文件和数据则有更细微的差别。在 Excel 中一个文件不仅包含多个工作表,而且还有不同的方式来引用这些工作表中的数据,包括通过整个工作表、一个已定义的表或一个已命名的范围来引用。在处理 Excel 数据时,一般有如下两种方法。
- 连接到存放在当前工作簿中的数据。
- 连接到存储在外部工作簿中的数据。
在本章中,将分别探讨这些细微的差别,因为用户可以访问的内容实际上是根据所使用的连接器的不同而发生变化。
(译者注:工作簿等价于 Excel 文件,工作表等价于 Excel 文件中的每个页面,表格等价于按 Ctrl + T 所创建的 Excel 表格,很多地方也俗称:超级表,智能表,是指的一个事物。)
6.1 来自当前工作簿的数据
要探讨的第一种情况是数据存储在当前工作簿中的情况。
【注意】 本节中的示例必须在 Excel 中运行,因为 Power BI 没有自己的工作表,所以 Power BI 是不支持这种方式的。尽管如此,还是建议 Power BI 的读者关注本节,因为这种连接方式是非常重要的。
当从当前(活动)工作簿中导入数据时,Power Query 只能从以下几个地方读取。
- Excel 表。
- 命名区域(包括动态命名区域)。
与连接到正式的 Excel 表不同,将考察连接到仅仅是表格形式存在的数据,但还没有应用表格样式。将要使用的数据位于:“第 06 章 示例文件 \Excel data.xlsx” 中,它包含四个工作表,每个工作表上有相同的数据。
(译者注:表,这个名词在 Excel 中会大量出现,本节作者用四个工作表介绍了五种模式,分别是:表(Table):按 Ctrl + T 创建的结构化对象;区域(Range):矩形范围的一片单元格;命名区域(Named Range): 对区域进行命名;动态区域(Dynamic Range):由 Excel 公式计算给出的单元格范围;工作表(Sheet): 是 Excel 工作簿中的某个页面。)
- “Table”(其中的数据在名为 “Sales” 的表中已预先格式化)。
- “Unformatted”。
- “NamedRange”。
- “Dynamic”(其中也包含一个公式在 H2 中)。
将使用这四个工作表来演示 Power Query 是如何处理用于连接到数据的不同方式的。
6.1.1 连接到表
先从最容易导入的数据源开始:Excel 表(Table)。
- 打开 “第 06 章 示例文件 \Excel Data.xlsx” 文件。
- 转到 “Table” 工作表。
会看到这些数据已经被格式化为一个漂亮的 Excel 表格,如图 6-1 所示。

图 6-1 在 Excel 中名为 “Sales” 表的数据
要将这些数据导入 Power Query。
- 单击表格中的任意一个单元格。
- 创建一个新的查询,【获取数据】【自其他源】【来自表格 / 区域】。
【注意】 在微软 365 之前的 Excel 版本中,【来自表格 / 区域】按钮被称为其他名字。无论名称如何,它都可以在【数据】选项卡上的【获取数据】按钮附近找到,为用户节省了几次单击的时间。
与其他许多数据连接器不同,此时将立即进入 Power Query 编辑器,打开预览窗口。这很有意义,因为用户已经看到了想导入的数据,如图 6-2 所示。

图 6-2 数据被直接导入 Power Query 中,打开预览窗口
【注意】 如果将 Power Query 在【应用的步骤】窗口中记录的步骤与 “CSV” 文件中记录的步骤进行比较,会注意到从表导入时,没有 “Promoted Headers” 步骤。这是因为 Excel 表的元数据包括了表的标题信息,所以 “Source” 步骤已经知道标题是什么。
与任何数据源一样,当从 Excel 表导入时,Power Query 将获得数据,然后尝试为每一列设置数据类型。应该注意到,在这个过程中,Excel 工作表中的数据格式被忽略了。如果它看起来像一个数字,Power Query 将应用一个【小数】或【整数】的数据类型。这通常不是什么大问题,但是当涉及到日期时,Power Query 总是将这些数据设置为【日期 / 时间】数据类型,即使底层的日期序列号被四舍五入到 0 位小数。这意味着一个不需要的精度级别,所以需要调整它(以及用【货币】 数据类型覆盖最后三列。)
- 更改 “Date” 列的数据类型,选择 “Date” 右边的【日期 / 时间】类型小图标,选择【日期】,在生成的对话框中单击【替换当前转换】。
- 选择 “Cost” 列,按住 Shift 键后选择 “Commission” 列(译者注:选择连续的几列),右击所选列的任意一个标题,【更改类型】【货币】【替换当前转换】。
此时,数据已经准备好,可进行所希望任何进一步的清洗或重塑。由于这个示例的目的是演示连接器,所以先跳过这一点。另外还需要关注查询的名称,该查询自动继承了数据源的名称:“Sales”。问题是,当把查询加载到工作表中时,创建的表将以查询的名字命名:“Sales”。由于表名在工作表中必须是唯一的,在 “Table” 表中已经有一个名为 “Sales” 的表,所以这将产生冲突。因为 Power Query 从不更改数据源,所以新的表名将被更改为一个不冲突的名称,从而创建一个名为 “Sales_2” 的表。
【警告】 当 Power Query 创建一个新的表并由于冲突而重新命名输出表时,它不会更新查询的名称来匹配。这可能会使以后追踪查询变得困难。
为了避免潜在的命名冲突,那就在把这个查询加载到工作表中之前更改它的名称。
- 将查询的名称更改为 “FromTable”。
- 单击【关闭并上载至】【表】【新工作表】【确定】。
【注意】 在这个过程中,几乎没有理由不进行任何转换就创建一个表的副本。显示这个过程只是为了说明如何从 Excel 表连接和加载数据。
6.1.2 连接到区域
要探讨的下一种变化是,数据是以表格的形式出现的区域(Range),但没有被格式化为正式的 Excel 表格格式。可以在 “Unformatted” 工作表中找到这个示例,如图 6-3 所示。

图 6-3 这些数据与第一个示例相同,但没有应用表格格式
要导入这个数据,要做和第一个示例相同的事情。
- 单击 “Unformatted” 数据范围内的任何(单个)单元格。
- 创建一个新的查询,【获取数据】【自其他源】【来自表格 / 区域】。
此时,Excel 将自动开始创建一个正式的 Excel 表格的过程,提示用户确认表格的边界和数据集是否包括标题,如图 6-4 所示。

图 6-4 如果 Power Query 提供了这个选项,请单击【取消】
【警告】 如果用户单击【确定】,Excel 将把数据转换成一个表,但它会为这个表选择了一个默认的名称(如 Table1 ),然后立即启动 Power Query ,而不会给用户机会将表名更改为更符合逻辑 / 描述性的名字。问题在于,原始名称被硬编码到查询中,当用户以后更改表名时,查询就会中断。这就使用户不得不在查询的 “Source” 步骤中手动编辑公式来更新表名,尽管这看起来很有帮助,但建议用户,直到微软提供可以在这个对话框中定义表名的功能之前 ,立即单击【取消】并自己设置表名。
如果不小心单击了【确定】,请关闭 Power Query 编辑器并丢弃该查询。本书的意图是让用户在这里获得长期的成功,所以在将它加载到 Power Query 之前,先把它格式化为表格格式。
- 单击数据区域内的任何(单个)单元格。
- 进入【开始】【套用表格格式】,选择一种颜色风格(如果用户对默认的蓝色没有意见,也可以按 CTRL+T )。
- 进入【表设计】选项卡。
- 将【表名称(在最左边)】改为 “SalesData”(没有空格)。
为什么要这样做?因为表名是工作簿导航结构的一个重要组成部分。每个表和命名的范围都可以从公式栏旁边的 【名称框】中选择,并将直接跳到工作簿中的数据。想想看,如果只用 “表 1、表 2、表 3、......” 来命名表时情况将会非常的糟糕,所以恰当地命名表格将成为一个非常有用的功能,可以快速跳转到解决方案中的关键范围,如图 6-5 所示。

图 6-5 名称框中已经填充了三个项目
(译者注:在 Excel 中合理的为数据安排名称虽然不是必须的,但这其实体现了对数据进行管理的系统化思维模式,通过组织合理的名称,可以快速识别正在或希望使用的数据,大幅提升工作效率。一个用户是否是有数据素养的重要体现之一就是看他如何组合和管理数据,关于这方面的经验没有统一标准,大部分来自于个人的长期经验积累,关于这方面的最佳实践已经超过了本书的讨论,在此提出以让读者理解原作者在此给出四种 Excel 数据的连接方式背后的良苦用心。)
现在,随着表的设置完成,这就像使用之前使用的 “From table” 路线创建一个查询一样简单。为了完整起见,现在来进行如下操作。
- 进入名称框,选择 “SalesData”(这将选择整个表)。
- 选择【数据】选项卡,【获取数据】【自其他源】【来自表格 / 区域】。
- 更改 “Date” 列的数据类型,选择 “Date” 列左边的【日期 / 时间】小图标,更改数据类型为【日期】【替换当前转换】。
- 选择 “Cost” 列,按住 Shift 键后选择 “Commission” 列,右击所选列的标题之一,【更改类型】【货币】【替换当前转换】。
- 将查询的名称改为 “FromRange”。
- 单击【关闭并上载至】选择【表】【新工作表】【确定】。
尽管这个功能很好,很有帮助,但也有点令人沮丧,因为它强制在数据上使用表格格式。除了表和区域,这种方法是否可以从其他的 Excel 数据对象中获得数据呢?
6.1.3 连接到命名区域
将 Excel 数据以表或区域的形式导入 Power Query 是最简单的方法,但并不是唯一的方法。
应用表格格式所面临的挑战是,它锁定列标题(打破了由公式驱动的动态表列标题),应用颜色带并对工作表进行其他风格上的更改,而用户可能不希望这样。考虑这样一种情况:用户花了大量的时间来构建一个分析,并且用户不希望在数据范围内应用表格格式。
好消息是,也可以连接到 Excel 命名区域,只需要做一些工作就可以了。秘诀是在数据上定义一个命名。现在就来使用同一数据的另一个示例来研究这个问题。
按如下步骤开始。
- 转到 “NamedRange” 工作表。
- 选择单元格 “A5:F42”。
- 进入名称框,输入名称 “Data” 后按回车键。
此时结果如图 6-6 所示。

图 6-6 创建 “NamedRange” 工作表
【注意】 提交后,可以使用左边的下拉箭头选择这个名称。无论此时在工作簿中的哪个位置,它都会将跳到这个工作表,并选择 “NamedRange” 中的数据。
接下来的步骤非常关键。
- 到名称框中选择 “Data”。
- 创建一个新的查询,【数据】选项卡,【获取数据】【自文件】【来自表格 / 区域】。
【注意】 如果在使用【来自表格 / 区域】命令时,“NamedRange” 被选中并显示在【名称框】中,Power Query 将避免对数据强制使用表格格式,而是直接引用命名范围中的数据。
(译者注:如果某区域是未命名区域,导入 Power Query 时会自动转换为表;而对于命名区域,选中其中任何单元格,导入 Power Query 都不会自动转换为表。)
这时的 Power Query 界面更类似于导入带分隔符的文件,而不是与 Excel 表的连接,如图 6-7 所示。

图 6-7 通过命名区域导入的数据
Excel 表的一个特点是有一个预定义的标题行,由于命名区域不存在这个功能,Power Query 必须连接到原始数据源,并运行其分析,来确定如何处理数据。
与处理 “平面” 文件的方式类似,它确定了一个似乎是标题的行,对其进行了提升,然后尝试对列应用数据类型。
为了使这些数据与前面的示例一致,然后将其加载到一个新表中,将进行如下操作。
- 修改 “Date” 列的数据类型,选择【日期】类型,【替换当前转换】。
- 选择 “Cost” 列,按住 Shift 键后选择 “Commission” 列,右击所选列标题之一,【更改类型】【货币】【替换当前转换】。
- 将查询的名称更改为 “FromNamedRange”。
- 单击【关闭并上载至】【表】【新工作表】【确定】。
6.1.4 连接到动态区域
Excel 表的一大特点是,随着新数据的加入,它们会自动在垂直和水平方向上扩展。但同样的,挑战在于它们携带了大量的格式化。然而,使用命名区域会缺乏自动扩展能力,而动态区域的自动扩展能力可以神奇的解决这个问题。
(译者注:动态扩展性,是在任何一个数据分析中的重要设计要素,它将确保用户的工作是一劳永逸的。对于命名区域,若在下面添加一行新的数据,该命名区域并不会将其自动纳入到其中,如图 6-x-1 所示:

图 6-x-1 新的数据没有被纳入命名区域
所以,需要一种可以容纳动态扩展的方法。)
其方法是创建一个动态命名的区域,它将随着数据的增长而自动扩展。
这种方法不能通过单击按钮来实现的,需要在开始之前设置一个动态名称,所以现在就开始。
- 选择 “Dynamic” 工作表。
- 转到【公式】选项卡,【名称管理器】【新建】。
- 将名称改为 “DynamicRange”。
- 设置公式,如下所示:
= DynamicRange!$A$5:INDEX(DynamicRange!$F:$F,MATCH(99^99,DynamicRange!$A:$A))- 单击【确定】。
【注意】 如果用户不愿意输入整个公式,可以在动态工作表的 H2 中找到它。请确保不要复制单元格内容开头的字符。
(译者注:
动态区域属于 Excel 中的高级技巧,它本身与 Power Query 的功能无关,但它是解决区域动态扩展性关键技巧。
其中,DynamicRange!是 Excel 工作表引用,公式 A5:INDEX(DynamicRange!F:F,MATCH(99^99,DynamicRange!A:A) 则动态计算了所需要数据的范围,其动态性表现在:随着数据的增加,该公式可以动态计算出数据内容所处的区域范围边界。其中,用到了重要的 Excel 函数技巧。
例如:MATCH( 99^99 , Dynamic!A:A ) 查找在 Dynamic!A:A 列的有数据存在的下边界,99^99 表示 99 的 99 次方,这是刻意构造一个不可能实际使用的大数来动态匹配计算该区域有数据的下边界的技巧。如果在 Excel 的公式栏中选择这部分,按【F9】执行,可以看到效果如图 6-x-2 所示。

图 6-x-2 计算存在数据的下边界索引值
其结果 42 正是 MATCH( 99^99 , Dynamic!A:A ) 的运算结果,表明该列有数据的最后一行位于第 42 行。
而 INDEX( Dynamic!F:F, MATCH( 99^99 , Dynamic!A:A ) 的 INDEX 是查找数据区域的右下角边界。
如果在 Excel 的公式栏中选择这部分,按【F9】执行,可以看到效果如图 6-x-3 所示。

图 6-x-3 计算存在数据的右下边界索引值
其结果 0.9 正是 INDEX 所辖范围公式内容的计算结果。需要注意的是:其本身计算结果为一个单元格的引用,但其值是 0.9,也就是说:0.9 不是这里真正想要的值,而想要的是 0.9 所在位置的引用。这就构成了:
= DynamicRange!$A$5:x其中,x 为数据区域右下角的引用,如果不在 Excel 公示栏中计算,则 x 的计算结果为引用,而为了知道这个引用是不是被正确的计算,在 Excel 公示栏中按【F9】计算,会返回作为位置引用的 x 单元格中的值,而不是其位置引用本身。这是一个 Excel 的复杂技巧,需要反复实验体会。如果单独使用这个公式,其效果如图 6-x-4 所示。

图 6-x-4 演示公式动态计算区域的效果
在 Excel 365 中,即使是在一个单元格中输入公式,若该公式实际返回一个区域,则会将结果扩展到此单元格以外的整个区域,并用蓝色边框表示边界,这里充分说明了该公式的效果。不难推测或实验,随着原来数据区域的横向或者纵向伸展,该公式都可以动态计算出整个区域。
再次强调,这不是 Power Query 的相关功能,而属于 Excel 公式中的高级组合技巧,但在此处却演示了将 Excel 的高级技巧与 Power Query 联合使用的强大之处,希望这里的补充解读可以让大家更深的喜欢上 Power Query。
)
现在动态区域应该包含在【名称管理器】的名称列表中,如图 6-8 所示。

图 6-8 新的动态区域现在已经被创建
现在面临的挑战是,可以在公式中引用这个命名的范围,但是由于它是动态的,所示不能从 Excel 公式栏左边的名称框中选择它。那么,如果不能选择它,怎么能用 Power Query 连接到它呢?
(译者注:
Excel 公式栏左边的名称框中是无法引用到动态区域的,即使给它其一个名字,如图 6-x-5 所示。

图 6-x-5 无法在公式栏引用到动态区域
在公式栏的下拉框中无法找到已经命名的动态区域,但这个动态区域是的确可以使用的。图 6-x-6 所示。

图 6-x-6 Excel 公式中可以引用动态区域
在正常编辑 Excel 公式时可以引用到动态区域。
)
秘诀是创建一个【空白查询】,并告诉 Power Query 要连接到哪个范围。
- 创建一个新查询,【数据】【获取数据】【自其他源】【空白查询】。
- 在公式栏中,输入以下内容:
= Excel.CurrentWorkbook ()【注意】 如果在 Power Query 功能区和数据区域之间没有看到公式栏,请进入【视图】选项卡,勾选【编辑栏】复选框。
按下回车键后,会看到一个表格,其中列出了这个工作簿中所有可以连接的 Excel 对象,如图 6-9 所示。

图 6-9 Power Query 在当前 Excel 工作簿中看到的所有对象的列表
在底部的是刚刚创建的 “DynamicRange” 对象。单击 “Content” 列中的绿色文本 “Table”(在 “DynamicRange” 的左边),它将下钻进如图 6-10 所示的范围。

图 6-10 表 “DynamicRange” 展开后的视图
可以看到【应用的步骤】窗口中的步骤如下所示。
- 连接到数据源( Excel 工作簿)。
- 导航到 “DynamicRange” 表。
此时,Power Query 再次做了一些关于数据的假设,并自动地应用了几个步骤来提升列标题和设置数据类型。此时,要做的就是调整数据类型并将数据加载到工作表中,按如下操作即可。
- 更改 “Date” 列的数据类型,选择左边的【日期 / 时间】小图标,选择【日期】类型,【替换当前转换】。
- 选择 “Cose” 列,按住 Shift 键后选择 “Commisssion” 列。
- 右击所选列标题之一,选择【更改类型】【货币】【替换当前转换】。
- 将查询的名称改为 “FromDynamicRange”。
- 单击【关闭并上载至】【表】【新工作表】【确定】。
6.1.5 连接到工作表
不幸的是,无法从当前工作簿中获取整个工作表数据。然而,可以通过在工作表的大部分地方定义一个 “Print_Area” 来设计一个变通方案。由于 “Print_Area” 是一个命名的范围,用户就可以通过名称框选择它,并使用连接到命名区域中数据的方法从那里获取数据。
(译者注:如果在公式栏左边的下拉列表中看不到 “Print_Area”,可以在【页面布局】选项卡下的【页面设置】设置打印区域。)
6.2 来自其他工作簿的数据
虽然上述的所有技术都有助于建立完全包含在当前 Excel 中的解决方案,但如果数据每月都会出现在一个新的 Excel 文件中,或者使用 Power BI 做报告,那该怎么办?在这两种情况下,用户都需要连接到外部 Excel 文件并将其作为数据源,而不是在同一工作簿中构建解决方案 。
在这个例子中,将连接到 “第 06 章 示例文件 \External Workbook.xlsx”。其中包含两个工作表(“Table” 和 “Unstructured”)。虽然每个工作表都包含相同的销售信息,但 “Table” 工作表上的数据已被转换为一个名为 “Sales” 的表。“Unstructured” 工作表包含一个静态命名区域,一个动态区域,以及一个打印区域。
如果在 Excel 中打开这个工作簿,可以看到在【公式】【名称管理器】中定义的每个元素的名称,如图 6-11 所示。

图 6-11 在 “External Workbook.xlsx” 文件中存在的命名元素
6.2.1 连接到文件
首先,来看看当连接到一个外部 Excel 文件时,会发生什么。在一个新的工作簿(或 Power BI 文件)中按如下操作。
- 确保 “External Workbook.xlsx” 处于已关闭状态。
- 创建一个新的查询,进入【数据】选项卡,【获取数据】【来自文件】【从工作簿】。
【警告】 Power Query 不能从一个打开的工作簿中读取数据。在尝试连接它之前,请确保关闭它,否则将会收到一个错误。
会弹出一个查询【导航】窗口,允许用户选择想导入的内容,如图 6-12 所示。

图 6-12 在 “External Workbook.xlsx” 文件中的可用组件
会注意到,用户可以连接到以下每个对象。
- 表:(Sales)。
- 工作表:(Table 和 Unstructured)。
- 命名区域:(_xlnm.Print_Area 和 NamedRange)。
但是用户没有看到动态区域(“DynamicName”)。虽然通过这个连接器可以连接到工作表,但不幸的是,失去了从外部文件中的读取动态区域数据的能力。
此时,如果选择任何一个数据,Power Query 都将启动 Power Query 编辑器并下钻到该数据。但是用户如果想要同时获得多个数据呢?
非常诱人的是【选择多项】旁边的复选框。的确,这将会起作用,并且将会为选择的每个数据分别创建一个不同的查询。问题是,这将为每个查询创建一个与文件的连接。虽然用户可以通过数据源设置对话框一次性更新它们,但用户可能更愿意采取的方法是建立一个与文件的单个连接,然后引用该连接来提取用户所需要的任何其他数据。这样,用户就可以通过【数据源设置】对话框或通过编辑原始数据源查询中的 “Source” 步骤来更新数据源。
在这个例子中,将采取后一种方法,建立一个连接到文件的查询,然后引用该表来钻取一个表、一个工作表和一个命名区域。按如下所示连接文件。
- 右击文件名,单击【转换数据】。
- 将新查询的名称更改为 “Excel File”。
现在将看到一个表示文件内容的表格,如图 6-13 所示。

图 6-13 在 “External Workbook.xlsx” 文件中的内容
在这个预览中,有如下几件事需要注意。
- “Name” 列显示了每个 Excel 对象的名称。
- “Data” 列显示的是 “Table” 表,其中包含了需要检索到的特定对象的内容。
- “Item” 列显示了对象名称的更详细的表示(包括打印区域的工作表名称)。
- “Kind” 列显示数据列中的表包含的是哪种对象。
- “Hidden” 告诉用户该对象是否可见。
需要注意的另一件事是,“Data” 列中显示的 “Table” 对象与其他预览数据的颜色不同。这表明这些项是可以单击的,而且用户可以对它们进行钻取。
6.2.2 连接到表
为什么不先从连接到另一个工作簿中的表时所看到的内容开始呢?再建立一个新的查询,让它【引用】“Excel File” 查询,如图 6-14 所示。
- 展开左边的【查询】导航窗格(单击【查询】上面的 “>” 按钮)。
- 右击 “Excel File” 查询,【引用】。
- 双击导航器中的 “Excel File (2)” 查询,将其重命名为 “Table”。
- 单击 “Sales” 表的 “Table” 关键字( “Data” 列的第三行)。

图 6-14 下钻到 “Sales” 表的位置
结果是,现在可以看到,从外部工作簿中导入的表与从同一工作簿中导入的表的处理方式非常相似,如图 6-15 所示。

图 6-15 连接到外部工作簿中的一个表
【注意】 有趣的是,外部工作簿的数据类型算法似乎更好,因为它将 “Date” 显示为【日期】数据类型,而不是【日期 / 时间】数据类型。
需要注意的是,用户从预览窗口选择一个表或者同时选择多个表,【应用的步骤】窗口中的步骤都是相同的。另外,当连接到一个外部工作簿时,Power Query 总是先连接到该工作簿的路径,再导航到用户所选择的对象中,然后再连接到工作簿中。与这里不同的是,“Source” 步骤将直接指向文件,而不会引用 “Excel File” 查询。
6.2.3 连接到命名区域
按如下步骤连接到一个命名区域,结果将如图 6-16 所示。
- 转到【查询】导航器,右击 “Excel File” 查询,【引用】。
- 双击导航器中的 “Excel File (2)” 查询,将其重命名为 “Named Range”。
- 单击 “NamedRange” 表的 “Table” 关键字( “Data” 列的第四行)。

图 6-16 下钻到命名区域
此时,结果不应该太令人惊讶。由于命名区域包含了非结构化工作表上记录的标题和数据,但没有被格式化为正式的 Excel 表,Power Query 导航到该对象,假设第一行是标题,然后设置数据类型。
实际上,除了 “Date” 列被设置为【日期】数据类型外,与数据在同一工作簿中的情况几乎没有区别,如图 6-17 所示。

图 6-17 从外部工作簿中的命名范围导入
6.2.4 连接到工作表
现在,来尝试导入整个工作表的内容。
- 转到【查询】导航器,右击 “Excel File” 查询,【引用】。
- 双击导航器中的 “Excel File (2)” 查询,将其重命名为 “Worksheet”。
- 选择 “Worksheet” 查询,单击 “Unstructured” 表的 “Table” 关键字( “Data” 列的第四行)。
这一次,结果看起来并不太理想,如图 6-18 所示。

图 6-18 这些 “null” 值是怎么回事
与从 Excel 表或命名区域检索数据不同,连接到工作表会使用工作表的整个数据区域,包括数据区域的第 1 行到最后的行,以及数据区域的第 1 列到最后使用的列。该范围内的每个空白单元格都将被填入 “null”。
在这里,将会注意到连接器已经连接到了 Excel 文件,导航到工作表中,然后提升了标题。这导致 A1 中的值成为标题行,这并不是用户真正需要的。因此,需要控制这一切,把数据清理成用户希望看到的样子。
- 删除 “Changed Type” 步骤。
- 删除 “Promoted Headers” 步骤。
- 转到【主页】【删除行】【删除最前面几行】,在出现的对话框中,【行数】下面填 “4”【确定】。
- 转到【主页】下【将第一行用作标题】单击【将第一行用作标题】(此时会自动生成一个 “Changed Type” 步骤)。
完成后,数据看起来更干净,如图 6-19 所示。
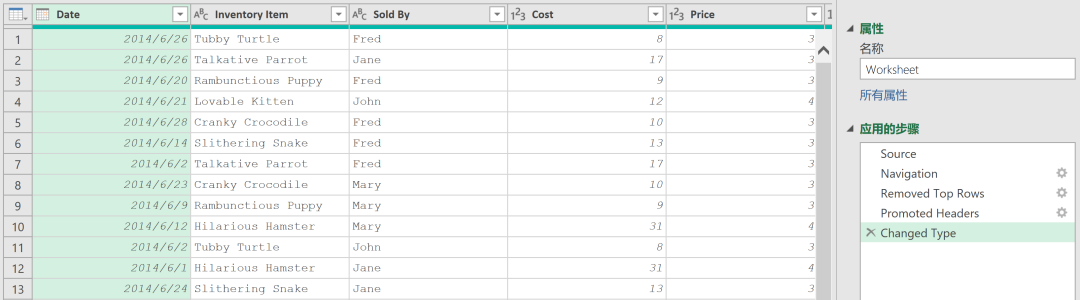
图 6-19 数据清洗成比较干净的样子
唯一的问题是,如果一直滚动到数据预览窗口的右边,会发现一个名为 “Column7” 的列,里面全是 “null” 值。在原 Excel 中,她并不包括在命名区域内,但作为从工作表中读取时,它就显示出来了。如果该列充满了 “null” 值,可以直接选择该列并将其删除,或者思考下,这里是不是可以直接将它删除呢?
此时,有必要来讨论一下可能会发生的问题,并避免将来由 “Changed Type” 步骤引起的步骤级错误。
注意,当提升标题时,Power Query 自动为该列添加了一个数据类型,将列名硬编码到步骤中,如图 6-20 所示。

图 6-20 为什么 “Column7” 是个问题?不能直接删除它吗?
这可能会带来一些潜在的问题,这取决于未来发生的事情,当用户进行如下操作,就会触发错误。
- 在 “Commission” 列旁边创建一个 “Profit” 列。在这种情况下,“Profit” 将作为列标题出现,而不是 “Column7”。
- 删除表中那一列存在的无关的数据。在这种情况下,“Column7” 根本就不会出现。
- 通过删除数据集中所有多余的列和行,重新设置 Excel 的数据范围。如果这是一个由 Excel 中使用的数据范围中额外单元格所引发的问题,那么列 “Column7” 将不再出现。
在上述情况下,查询将触发一个步骤级别的错误,因为在 “Changed Type” 步骤中硬编码的列 “Column7” 将不再存在。
【注意】 这是是通过在 Excel 中使用不同数据范围来演示这一点,通常用户不会在自己的 Excel 中加入各种无效数据。但是本例还是非常有用的,如果是某系统导出的 Excel 文件,并且可能更改列数,也可能会引发同样的问题。
在未来可能会遇到这个问题,为了减少将来发生步骤错误的可能性,而不是让事情碰运气,为此,应该只保留用户需要的命名列,而且 “Column7” 列永远不会被记录在 Power Query 步骤中,需要进行如下操作。
- 删除 “Changed Type” 步骤。
- 选择 “Date” 列,按住 Shift 键后单击 “Commission” 列,右击任何一个被选中的列标题,然后单击【删除其他列】。
- 重新选择所有的列,如果它们没有被选中的话。
- 转到【转换】【检测数据类型】。
通过使用【删除其他列】而不是删除指定的列,可以确保只保留用户知道将来会需要用到的列,而不会硬编码一个可能更改或消失的列。
要检查的最后一件事是,在数据集下面是否有大量的空白行。如果发生这种情况,可以通过以下操作来去除它们。
- 选择数据集中的所有列。
- 进入【主页】【删除行】【删除空行】。
这个解决方案的最后一个注意事项是:如果用户在电子表格中创建了一个新的 “Profit” 列,它也将被过滤掉,因为它将在 “Remove Other Columns” 的步骤中被删除。因此,虽然这些步骤可以防止无效的数据扰乱查询,但它们也可能阻止新的有效数据被导入(这就是在用户有选择的情况下,宁愿选择表格而不是工作表的原因之一)。
【注意】 如果用户能控制数据集,并且知道列的数量不会发生改变,那么这些步骤就不需了。只有当数据集在水平方向上增多或者减少时,用户才需要关注。
在建立了每种类型的连接示例后,用户现在可以将所有这些查询加载到工作表(或 Power BI 模型)。不幸的是,在 Power Query 的一个会话中建立了所有这些查询,用户只能在 Excel 中选择一个加载目的地。由于用户希望它们中的大部分都能加载到工作表中,所以可以按以下方式来处理。
- 选择【关闭并上载至】【表】【新工作表】【确定】。
- 右击 “Excel File” 工作表标签,选择【删除】单击【删除】。
现在,这些查询将分别加载到自己的工作表中,“Excel File” 查询被设置为【仅限连接】。
【注意】 如果在 Power BI 中工作,只需在选择【关闭并应用】之前,取消勾选 “Excel File” 查询的【启用加载】复选框。
6.3 关于连接到 Excel 数据的最后思考
在可能的情况下,最好是根据 Excel 表而不是命名区域或工作表来构建解决方案。它比其他方法更容易设置,更容易维护,而且对数据的存储位置相当透明。当然,在有些情况下(比如通过自动化创建文件)不能使用表。在这些情况下,确实可以选择使用其他技术。
在 Excel 文件中构建解决方案时,要考虑的另一件事是应该把数据存储在哪里。是把查询和数据放在同一个文件里,还是把源数据放在一个单独的 Excel 文件里,并把它作为数据源连接到该文件中。
在本书的许多例子中,都是在数据所在的同一文件中构建查询。
这纯粹是为了解决方案的方便和可移植性,因为它避免了用户为每一个打开的完整示例文件更新数据源。尽管如此,这使得在现实世界中分享和共同编写解决方案变得更加困难。
将 Excel 数据源保存在一个单独的文件中的有以下一些好处。
- 有能力让多个用户更新数据(甚至在使用共同创作时同时更新)。
- 当数据增长到应该在数据库中的位置时,可以很容易地升级解决方案(移动数据,并更新查询以指向新的源)。
- 能够在同一个 Excel 数据源上构建多个报表解决方案。
- 能够直接从工作表中读取数据。
另一方面,拆分文件的缺点如下。
- 不支持从动态区域读取数据。
- 需要为不同的用户管理和更新文件路径。
- 在编辑查询时,无法共享修改同一套逻辑。
最终,用户需求将决定最适合解决方案。然而,根据经验,倾向于将数据源与业务逻辑分开,除非有特殊的原因要这么做。
(译者注:短期临时使用的方案,在当前文件构建是敏捷的;而若提前知道某方案要支持长期的使用,则建议进行系统化的设计,将 Excel 文件作为一个文件数据仓库,通过 Power Query 将所有外部数据都 ETL 并加载到这个 Excel 文件的工作表中,此时,该 Excel 文件成了一个敏捷数据仓库文件,可以再次使用。优点是:结构清晰,维护方便;限制是:单个 Excel 表容量约 100 万行数据。但可以通过其他的组合技巧来消除相关限制。这些讨论超出了本书的范畴,但有必要提醒读者在这里进行思考以便获得更健壮的设计方案。)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2022-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号