【Pytorch基础】深度残差神经网络

【Pytorch基础】深度残差神经网络

yhlin
发布于 2023-02-27 17:00:15
发布于 2023-02-27 17:00:15
回顾
前面我们讨论的神经网络的层数都不会很大,但是对于一些深层的神经网络来说,训练它将会变得非常困难。其中一个原因是对于深层神经网络其越接近输入的层越有可能出现梯度消失和梯度爆炸问题,导致网络无法继续学习到更多特征。
梯度消失、梯度爆炸
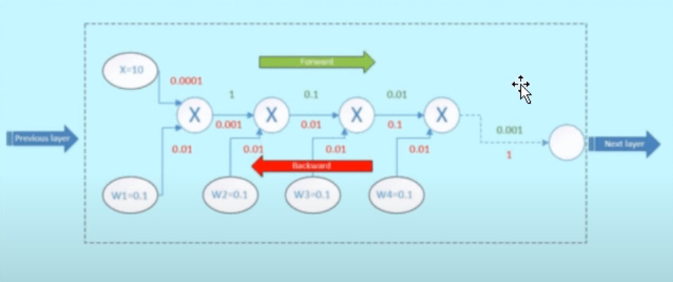
假设有如下图神经网络:

由于我们的梯度更新方式为:
前馈传播方式:
根据链式法则计算第一层的梯度:
对于上式,由于我们初始化的网络权重值 w 通常都在 0 附近。显然,当网络层数越多使得 w_4\cdot w_3 \cdot w_2 越小因而导致梯度消失,使得权重几乎无法更新。反之,若 w 都大于 1,权重乘积就会变得很大使得权重更新幅度过大,则会使其产生梯度爆炸。
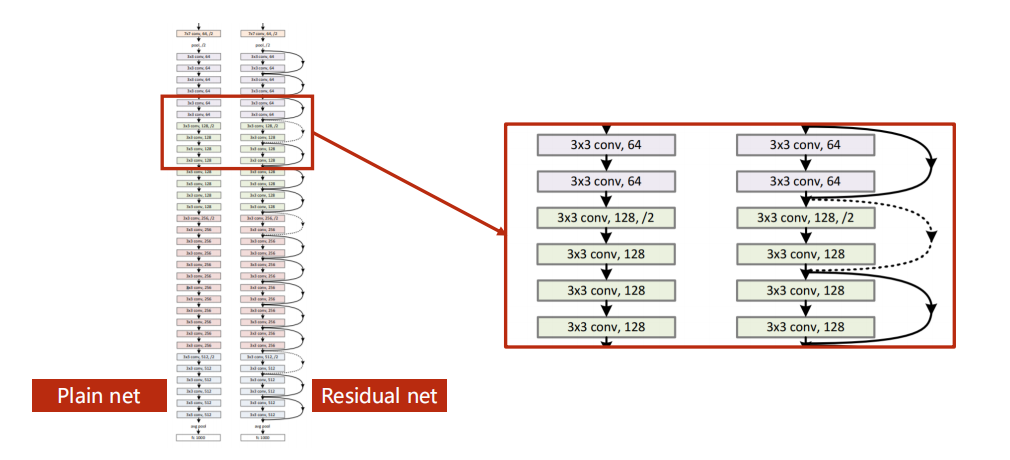
深度残差神经网络
为了解决上述问题,大佬们提出了深度残差神经网络,对比普通的平原神经网络 (Plain Net):
残差模块
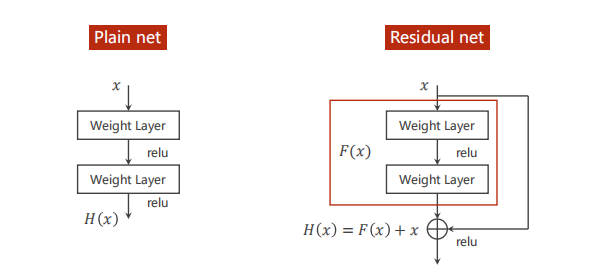
上图中的 WeightLayer 可以是卷积层也可以是线性层。可以看出,平原网络的输出为 H(x),而残差网络由于在输出前将其与输入相加使得最终输出为 H(x)=F(x)+x。做一下反向传播:
如此一来,即使 \frac{\partial F}{\partial x} 的值非常小 \frac{\partial F}{\partial x} + 1 的值也会在 1 左右,不至于过小,从而避免梯度消失。但是必须注意的是,F(x) 的输出的张量维度必须与输入 x 完全一样,才能做后面的加法运算。
实现(MNIST 数据集)
残差模块的实现
class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = torch.nn.Conv2d(channels,chennels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)定义网络

class ResNet(torch.nn.Module):
def __init__(self):
super(ResNet,self).__init__()
self.conv1 = torch.nn.Conv2d(1,16,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(16,32,kernel_size = 5)
self.mp = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = torch.nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1)
return self.fc(x)完整代码
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
# 对数据的处理:神经网络希望输入的数据最好比较小,最好处于(-1,1)内,最好符合正态分布。transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))
])
# 训练集
train_dataset = datasets.MNIST(root='./dataset/mnist/',train=True,download=True,transform=transform)
train_loader = DataLoader(train_dataset,shuffle=True,batch_size=batch_size)
# 测试集
test_dataset = datasets.MNIST(root='./dataset/mnist/',train=False,download=True,transform=transform)
test_loader = DataLoader(test_dataset,shuffle=False,batch_size=batch_size)
# 残差模块
class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
self.conv2 = torch.nn.Conv2d(channels,channels,kernel_size=3,padding=1)
def forward(self,x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
# 模型类
class ResNet(torch.nn.Module):
def __init__(self):
super(ResNet,self).__init__()
self.conv1 = torch.nn.Conv2d(1,16,kernel_size = 5)
self.conv2 = torch.nn.Conv2d(16,32,kernel_size = 5)
self.mp = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = torch.nn.Linear(512,10)
def forward(self,x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size,-1)
return self.fc(x)
model = ResNet()
# 损失函数和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(model.parameters(),lr=0.01,momentum=0.5) # 随机梯度下降,带冲量
e_list = []
l_list = []
running_loss = 0.0
# 单轮训练的函数
def train(epoch):
running_loss = 0.0
Loss = 0.0
for batch_idx, data in enumerate(train_loader,0):
inputs, target = data
optimizer.zero_grad()
# 前馈计算
outputs = model(inputs)
# 损失计算
loss = criterion(outputs,target)
# 反馈计算
loss.backward()
optimizer.step()
running_loss += loss.item() # 累加损失
Loss += loss.item()
# 每 300 次迭代(minibatch)训练更新, 计算一次平均损失
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
e_list.append(epoch)
l_list.append(running_loss/300)
def test():
correct = 0 # 预测正确数
total = 0 # 总样本数
with torch.no_grad(): # 声明不计算梯度
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # 按列找最大值的下标,返回两个:最大值,下标
total += labels.size(0) # labels 矩阵的行数
correct += (predicted == labels).sum().item() # 相等为 1,否则为 0
print('Accuracy on test set: %d %%' % (100 * correct / total))
# 训练
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
import matplotlib.pyplot as plt
plt.figure(figsize=(8,5))
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(e_list,l_list,color='green')
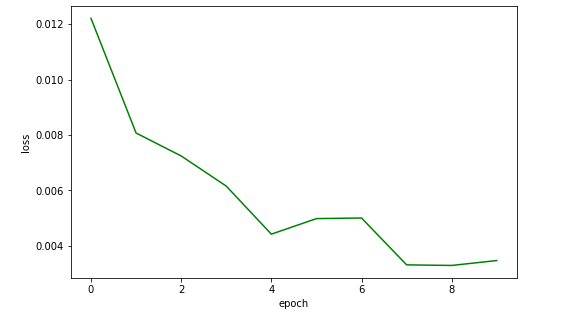
plt.show()收敛图像
经过十轮训练,网络的测试准确率就到达 99% 了,Amazing
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-01-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号