最先进单插槽专业绘图解决方案


Quadro RTX 4000将NVIDIA Turing GPU架构与最新的内存和显示技术相结合,以单插槽PCI-e结构提供最佳性能和功能。 享受更大的流畅性与如照片真实感渲染,体验启用AI-应用更快的性能和创建详细的,栩栩如生的虚拟现实体验。更具成本效益和更加广泛与弹性的工作站机箱配置。
性能特点
Turing GPU 架构
Quadro RTX 4000 GPU 由最先进的 12nm FFN (FinFET NVIDIA) 高性能制程制造,为 NVIDIA 订做,包含 2304 个 CUDA 核心,为专业桌面上针对 HPC,AI,VR 和绘图工作负载最强大的运算平台。Turing GPU 架构实现了自 NVIDIA 在 2001 年发明可程序化着色器以来,计算机实时绘图成像最大的跃进 。它在 545 平方公厘的尺寸上整合了 136 亿个晶体管,可提供超过 7.1 TFLOPS 单精度(FP32),14.2 TFLOPS 半精度 (FP16),28.5 TOPS 整数精度 (INT8),以及 57.0 TFLOPs Tensor运算能力,完美支持各种计算密集的工作附载。
RT 核心
新的硬件光线追踪技术让 GPU 首次实现实时产生电影质量般逼真的对象和环境,包括精确的物理阴影,反射,和折射。即时光线追踪引擎与 NVIDIA OptiX,Microsoft DXR,和 Vulkan API 配合,提供远超出传统成像技术所能达到的真实程度。RT 核心使用通过像素投射少量光线来加速边界体积层次 (BVH) 遍历和光线投射功能。
加强的Tensor核心
新的混合精度核心为了深度学习矩阵运算而设计,训练时可提供前一代 8 倍的 TFLOPS。Quadro RTX 4000 利用 288 个Tensor核心,每个Tensor核心每个频率可执行 64 个浮点融合乘加 (FMA) 运算,每个 SM 每个频率可执行总共 1024 个独立的浮点运算。除了支持 FP16/FP32 矩阵运算,新的Tensor核心针对矩阵运算增加了 INT8 (每个频率 2048 个整数运算) 和实验性的 INT4 和 INT1 (二进制) 精度模式。
先进的着色技术
网格着色:基于运算的几何管线,以加速几何复杂模型和场景的几何处理和剔除。网格着色对于受限于几何能力的工作负载提供高达两倍的效能提升。 可变速率着色 (VRS):根据场景内容,注视方向,和动作来改变着色速率,以提高成像效率。可变速率着色提供相似的影像质量,但着色的像素减少 50%。 材质空间着色:对象/材质空间着色可提高像素着色繁重的工作负载效能,如景深和动态模糊。材质空间着色对于像素着色繁重的 VR 工作负载,重复使用预先着色材质像素,以提高吞吐量,增加逼真程度。
高效能 GDDR6 内存
Quadro RTX 4000 采用 Turing 的高度优化 8GB GDDR6 内存子系统,具备业界最快的绘图内存 (416 GB/s 峰值带宽),为专门处理大型数据集并对延迟敏感的应用程序理想平台。Quadro RTX 4000 提供比前一代增加 70% 的内存带宽。
单一指令,多线程 (SIMT)
新的独立线程排程功能可在小型工作间共享资源,实现平行线程之间更精细的同步和合作。
先进串流多处理器 (SM) 架构
结合共享内存和 L1 快取以大幅提高效能,并简化程序和减少所需的调整来得到最佳的应用程序效能。每组 SM 包含 96 KB L1/共享内存,可根据运算或绘图工作负载,配置各种容量。对于运算工作,最多可分配 64 KB 到 L1 快取和共享内存,而绘图工作负载最多可分配 48 KB 到共享内存;32 KB L1 和 16 KB 材质单元。 结合 L1 快取和共享内存可降低延迟并提供更高带宽。
混合精度运算
16 位浮点精度运算,可将吞吐量加倍并降低储存需求,实现更大型神经网络的训练和部署。 Turing SM 具备独立的平行整数和浮点数据路径,对于运算和地址计算混合的工作负载更有效率。
错误修正码内存 (ECC)
符合关键性任务应用程序对数据完整性的严格需求,为工作站提供无可比拟的计算精确度和可靠性。
图形抢占
像素等级抢占提供更细微的控制,对时间相关的工作支持更佳,例如 VR 动态追踪。
计算抢占
指令等级抢占提供对计算工作更精细的控制,以避免长时间执行的应用程序独占系统资源或超时。
H.264 和 HEVC 编码/译码引擎
两个专属的 H.264 和 HEVC 编码引擎以及独立于 3D/运算管线之外的译码引擎可提供比实时更快的转档,影片编辑,和其他编码应用程序效能。
NVIDIA GPU BOOST 4.0
自动最大化应用程序效能,而不会超出卡的功耗和散热范围。允许应用程序在更高温下停留在加速频率状态更久,才会再降到第二温度设定的基本频率。此功能需要软件应用程序来启动,而不是独立的程序。
影像质量

全景反锯齿 (FSAA)
使用高达 64X FSAA (SLI 模式下 128倍) 大幅降低视觉混迭伪像或「锯齿」以获得优秀的影像质量和极为逼真的场景。
32K 材质和成像处理
材质来自并成像到 32K x 32K 表面以支持需要最高分辨率和质量的图像处理应用程序。
显示特性
VirtualLink™
新的开放式业界标准连接性,适用于下一代 VR 头盔,提供四个高速 HBR3 DisplayPort 信道,USB3.1 数据信道和高达 27 瓦的供电。USB-C 的备用模式针对延迟和带宽需求进行优化,以提供更高的显示分辨率,并采用高带宽相机,在 VR 头盔上用于追踪和扩增实境。
Multi-View
可一次产生四个独立画面,大幅降低绘图管线工作负载并提高真实感。同步多重投影 (SMP) 引擎比上一代的投影中心加倍,可执行多达两倍的几何成像工作负载。这可让与位置无关的画面具有更大灵活性,产生更多创意场景。
DisplayPort 1.4
支持最多四个 5K 屏幕 @ 60Hz,或每卡两个 8K 显示器。Quadro RTX4000 支持 HDR 色彩,包括 4K @ 120Hz 10/12b HEVC 译码以及高达 4K @ 60Hz 10b HEVC 编码。 每个 DisplayPort 连接头可驱动 4096x2160 @ 120 Hz 的超高分辨率及 30-bit 色彩。
NVIDIA® Mosaic™ 技术
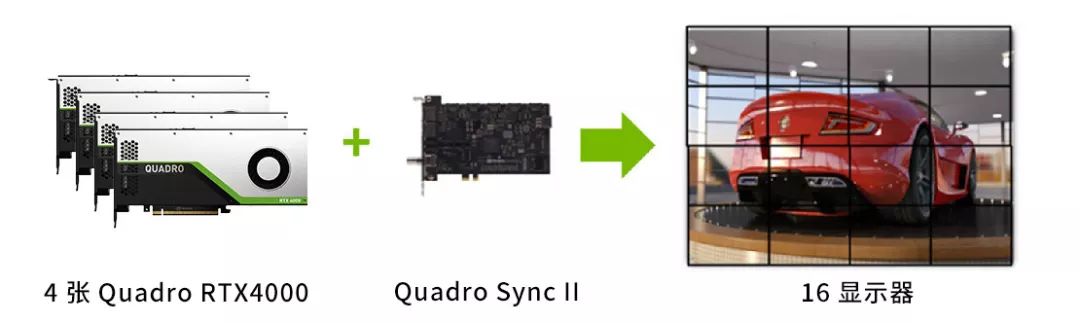
将桌面和应用程序从单一工作站扩展到最多 4 个 GPU 和 16 个显示器,同时提供完整的效能和影像质量。

NVIDIA® Quadro Sync II
在单一系统的 8 个 GPU 中同步最多 32 个显示器的显示和画面输出 (透过两张 Sync II 适配卡连接),减少建立高阶影像可视化环境所需的机器数量。
NVIDIA® nView® 进阶桌面软件
在单一大型显示器或多显示器环境下让终端用户对桌面体验取得前所未有的的控制,以提高生产力。
框页锁 (Frame Lock)连接器卡榫
每个框页锁连接器都设计有自动锁定保持机制,以确保与框页锁定扁平电缆的连接,提供强大的连接性和最高的生产力。
OpenGL 四缓冲立体支持
为专业应用程序提供流畅与身历其境的 3D 立体体验。
支持超高分辨率桌面
在最大 32K 桌面大小的高分辨率显示器上获得更多 Mosaic 拓扑选择。
专业 3D 立体同步
稳定控制三维效果,经由专属连接直接将 3D 立体硬件同步到 Quadro 显卡。
软件支持
针对 Turing 优化的软件
深度学习框架例如 Caffe2, MXNet, CNTK, TensorFlow 等可以大幅加快训练时间并提高多节点训练效能。GPU 加速函式库如 cuDNN, cuBLAS, 和 TensorRT 为深度学习推理和高速计算 (HPC) 应用程序提供更高的效能。
NVIDIA® CUDA® 平行运算平台
原生执行标准程序语言如 C/C++ 和 Fortran,以及 API 如 OpenCL,OpenACC 和 Direct Compute,以加速光线追踪,影片和图像处理,以及流体力学计算等技术。
单一内存
单一无缝的 49 位虚拟地址空间可让数据在 CPU 和 GPU 完全分配的内存内透明的移动。
NVIDIA® GPUDirect for Video
GPUDirect for Video 经由避免不必要的系统内存数据复制和 CPU 负担来加速 GPU 和影像 I/O 装置间的沟通。
NVIDIA 企业管理工具
将系统正常运作时间最大化,无缝管理大规模部署并远程控制图形和显示设置,以实现高效率运作。

NVIDIA 包装及配件
- NVIDIA Quadro RTX4000
- Quadro RTX 快速入门指南
- Quadro 支持手册
- 1 DisplayPort 转 DVI 转接头
- 1 DisplayPort 转 HDMI 转接头
- 1 USB-C 转 DP 转接头
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2019/03/28 18:00:00,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号