MiniGPT4,开源了。


大家好,我是 Jack。
一个月前,我发布过一篇文章,讲解了 GPT4 的发布会。
ChatGPT 的对话能力,想必大家也早已体验过了,无论是文本生成能力,还是写代码的能力,甚至是上下文的关联对话能力,无不一次又一次地震撼着我们。
你还记不记得发布会上,GPT4 的多模态能力,就是输入不仅是可以是文字,还可以是文本和图片。
输入:(看图)手套掉下去会怎样?
输出:它会掉到木板上,并且球会被弹飞。

甚至画个网站的草图,GPT4 就可以立马生成网站的 HTML 代码。
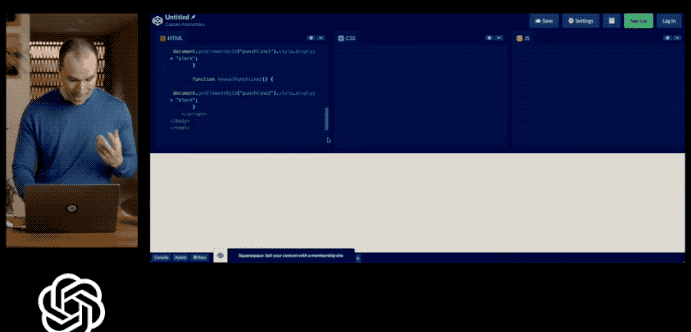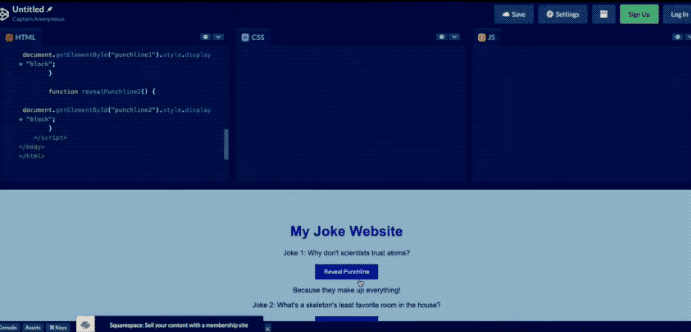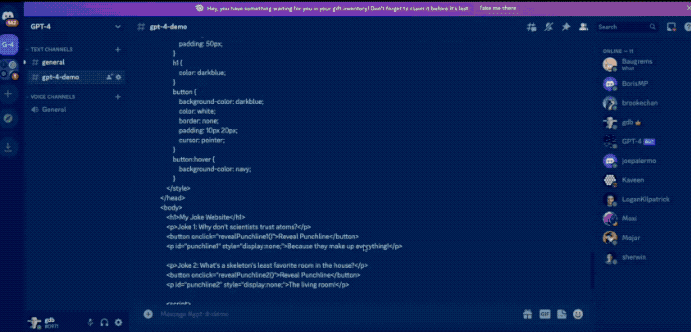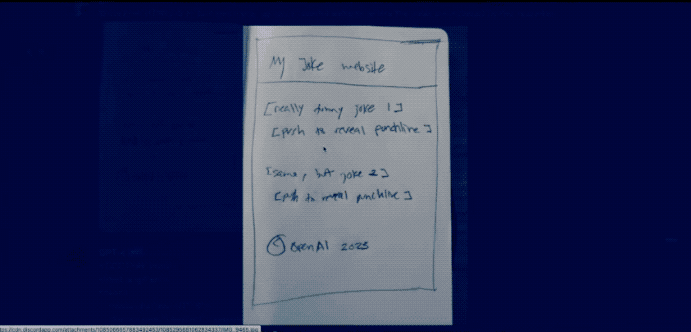
然而,已经过去一个多月了!OpenAI 至今也没有提供发布会所展示的多模态处理能力!
原本以为还要再等几个月的官方更新,才能体验上这个功能,没想到,我看到了这么一个项目。
该项目名为 MiniGPT-4,是阿卜杜拉国王科技大学的几位博士做的。
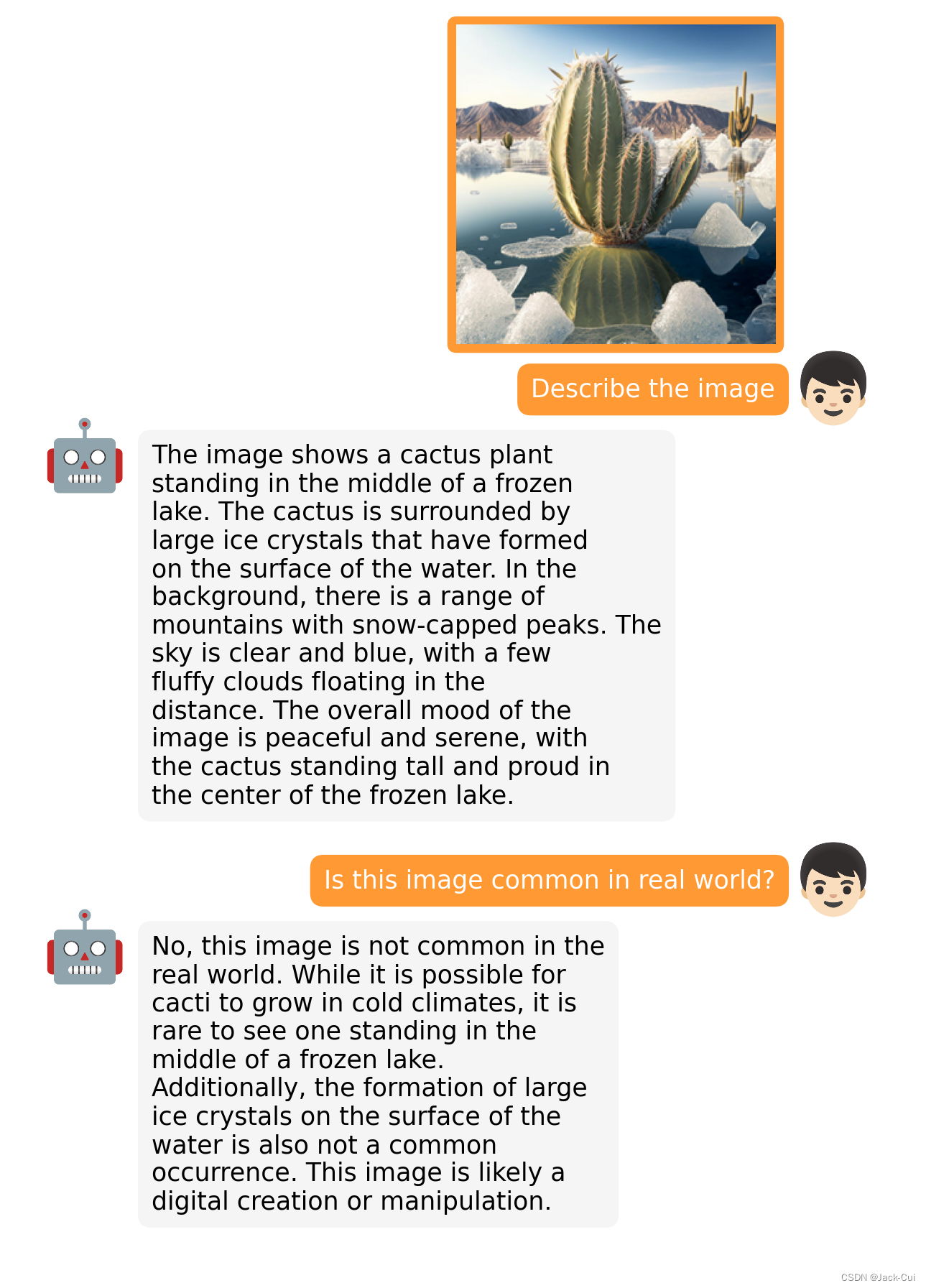
最主要的是,完全开源!比如,描述一下这张图片:
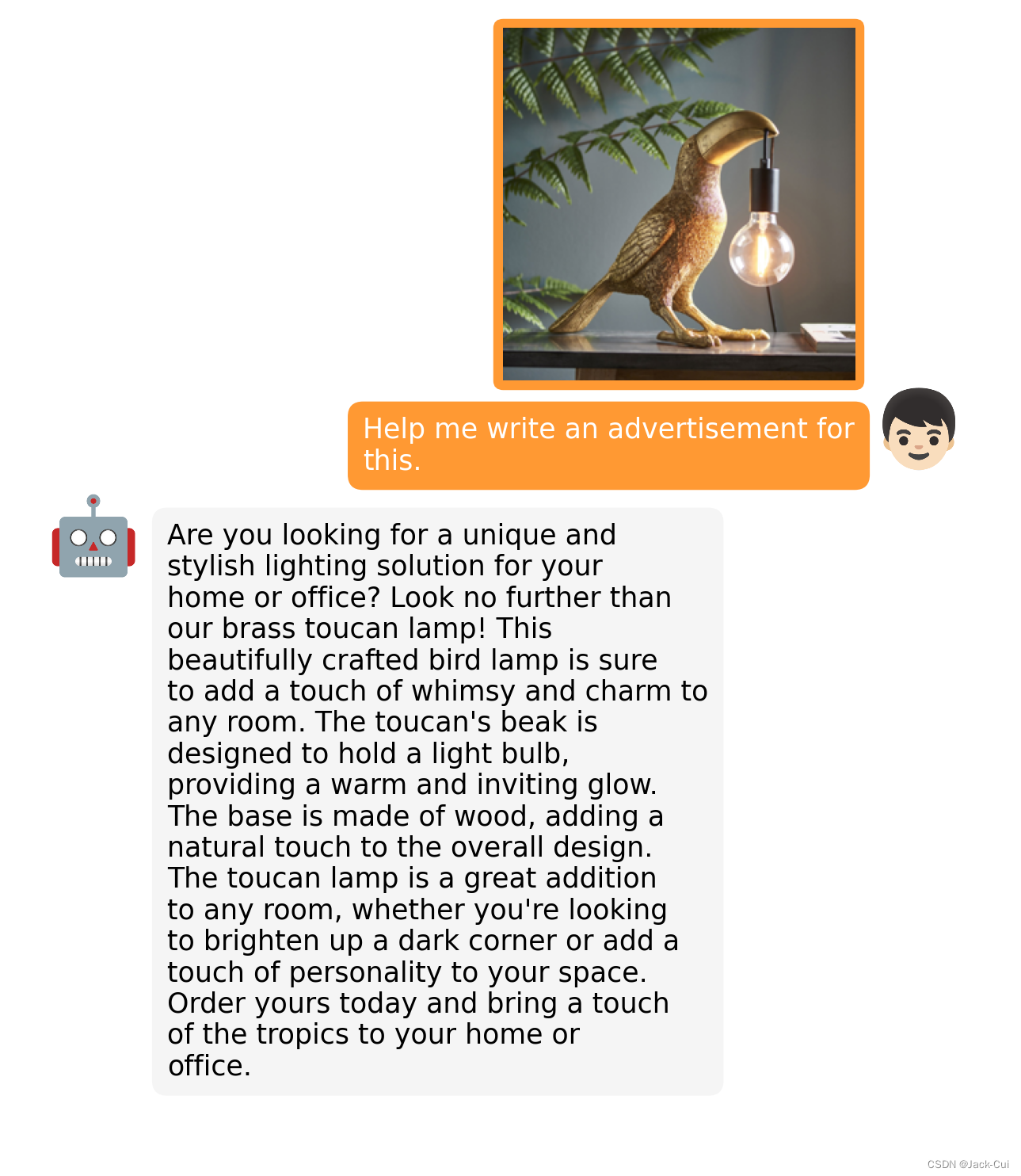
帮忙写个广告语:
可以看到,MiniGPT-4 能够支持文本和图片的输入,实现了多模态的输入功能。
GitHub:https://github.com/Vision-CAIR/MiniGPT-4 在线体验:https://minigpt-4.github.io
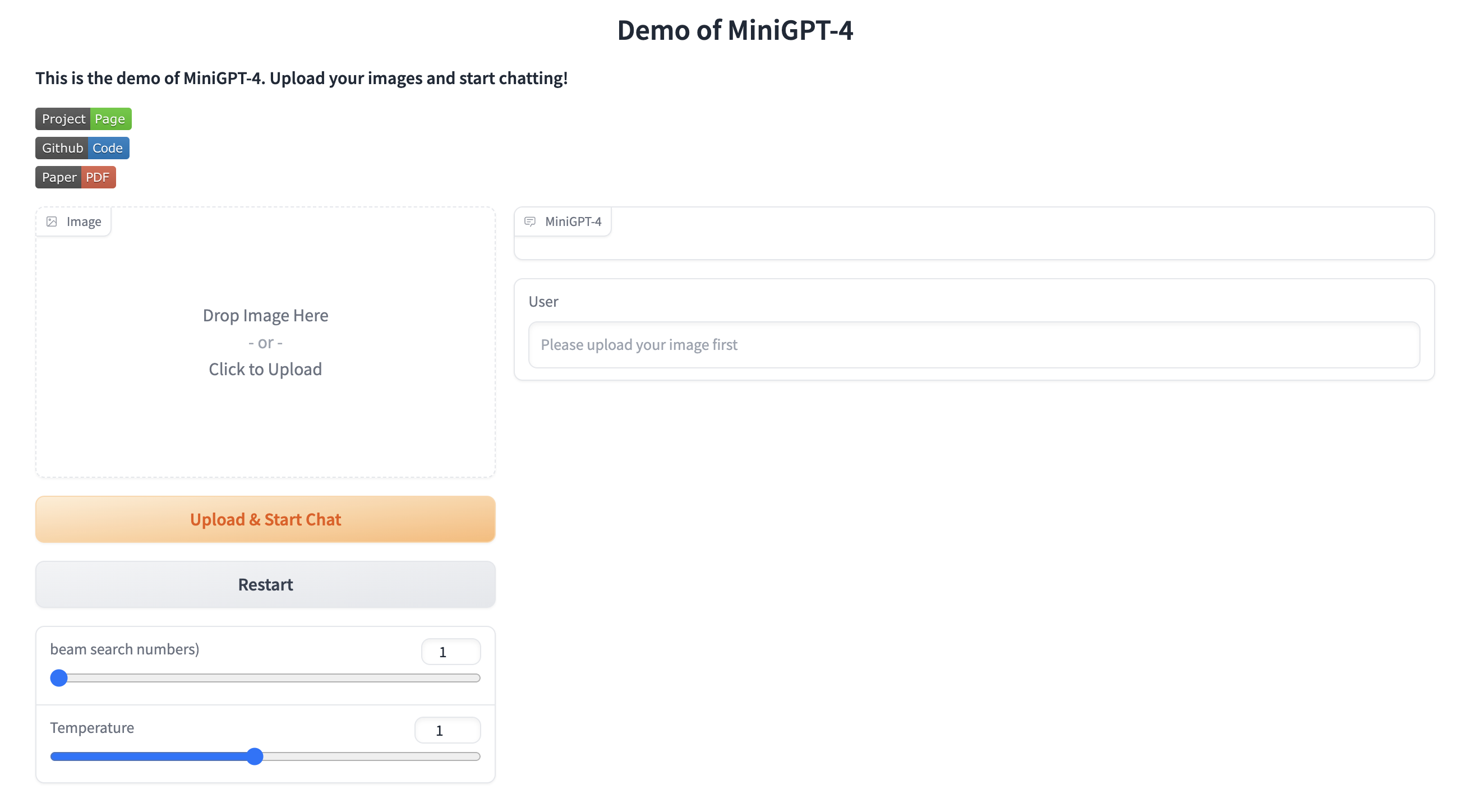
作者还提供了网页 Demo,可以直接体验:
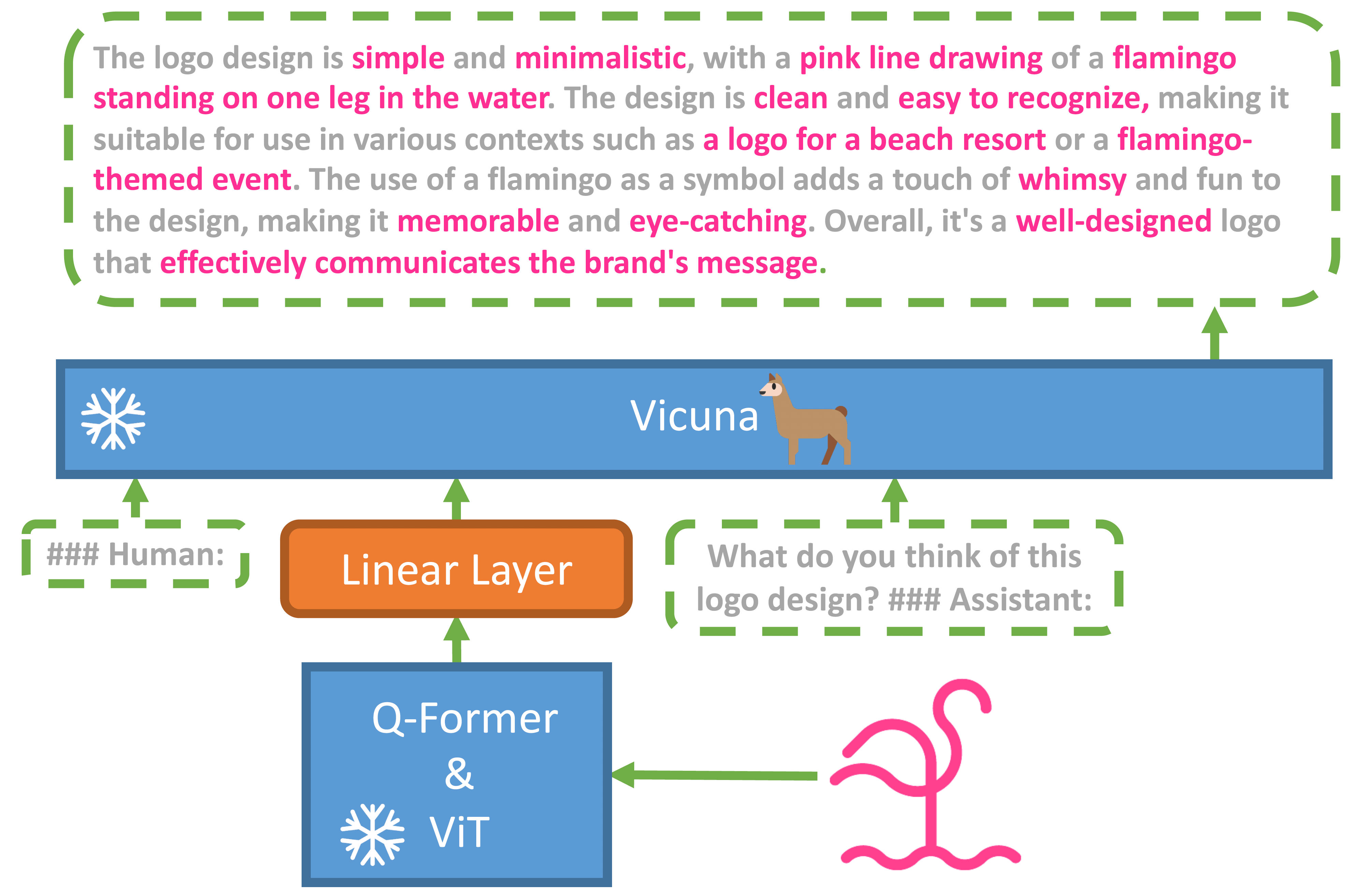
MiniGPT-4 是在一些开源大模型基础上训练得到的,fine tune 分为两个阶段,先是在 4 个 A100 上用 500 万图文对训练,然后再用一个一个小的高质量数据集训练,单卡 A100 训练只需要 7 分钟。
不过目前使用的人数较多,可以错峰使用,或者本地部署一个服务。
本地部署也不复杂,根据官方教程直接配置环境:
git clone https://github.com/Vision-CAIR/MiniGPT-4.git
cd MiniGPT-4
conda env create -f environment.yml
conda activate minigpt4然后下载预训练模型:
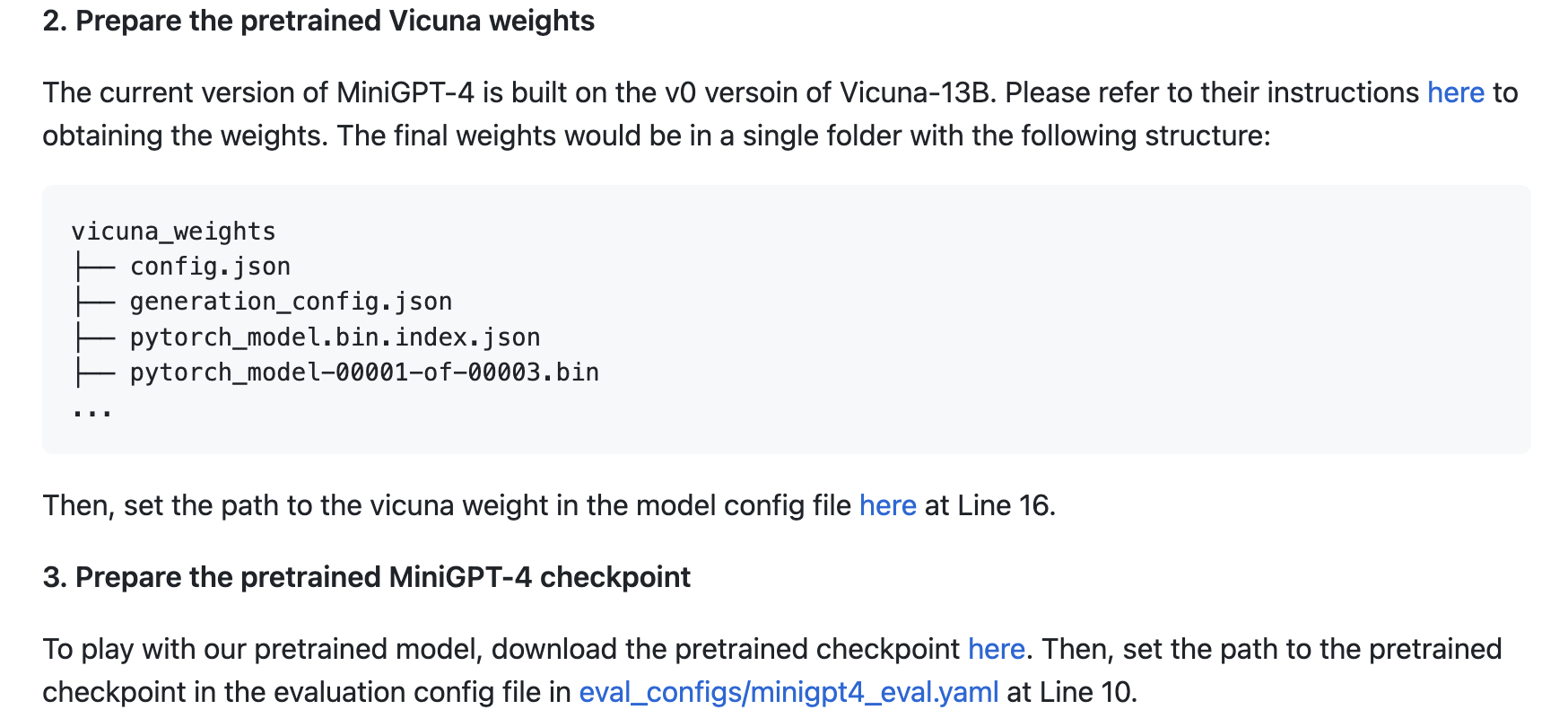
输入指令直接运行:
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml这个过程需要保证有网络,需要下载一些 BLIP 之类的依赖库。
相信不久的将来,不仅仅是可以多模态输入,还可以多模态输出。
我们可以输入:文本、图像、音频、视频
AI 就能根据我们的需求,生成我们需要的文本、图像、音频、甚至是视频。
一起期待一下吧~
最后再送大家一本,帮助我拿到 BAT 等一线大厂 offer 的数据结构刷题笔记,是一位 Google 大神写的,对于算法薄弱或者需要提高的同学都十分受用:
以及我整理的 BAT 算法工程师学习路线,书籍+视频,完整的学习路线和说明,对于想成为算法工程师的,绝对能有所帮助:
别光收藏,来个赞哦,笔芯~
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-04-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号