功能连接体指纹的特征选择框架
原创

基于功能连接组(FC)来独特描述个体特征的能力是迈向精确精神病学的关键要求。为此,神经成像界对FC指纹进行了越来越多的研究,开发了多种有效的FC指纹识别方法。最近的独立研究表明,在大样本尺寸和较粗的分区用于计算FC时,指纹识别的精度会受到影响。量化这一问题,了解这些因素影响指纹准确性的原因,对于开发更准确的大样本量指纹提取方法至关重要。指纹识别的部分挑战在于,FC既能捕捉通用信息,也能捕捉特定个体的信息。一种识别特定个体FC信息的系统方法对于解决指纹问题至关重要。在本研究中,我们解决了我们对FC指纹识别问题的理解中的三个空白。首先,我们研究了样本量和分区粒度的联合效应。其次,我们解释了随着样本量的增加和分区粒度的减小,指纹识别精度降低的原因。为此,我们使用了来自数据挖掘社区的聚类质量指标。第三,我们开发了一个通用的特征选择框架,用于系统地识别静止状态功能连接(RSFC)元素,该元素捕获信息,以唯一地识别主体。综上所述,我们从这个框架中评估了六种不同的方法,通过量化受试者特定指纹的准确性和随着样本量增加而降低的准确性,以确定哪种方法对质量指标的改善最大。
1. 简介
自Finn等人(2015)开创性的工作以来,人们开发了多种使用RSFC进行指纹识别的方法,该工作为在功能连接矩阵中表征特定个体信息并对其进行量化铺平了道路。为了便于比较,我们将这些方法分为两个类:原生RSFC方法和RSFC派生的方法。原生RSFC方法将RSFC矩阵作为一个整体或选择其中的一部分进行指纹识别。示例包括Finn等人(2015)提出的方法,该方法利用目标RSFC矩阵和每个参考RSFC矩阵的连通性值之间的相关性来确定最佳匹配。Finn等人(2015)也使用了RSFC矩阵中预定义子网的连通性值,而不是使用整个RSFC矩阵中的连通性值。Peña-Gómez等人(2018)提出的另一种方法使用与指纹相关的选定区域的连通性。相反,RSFC衍生的方法从RSFC构建新的特征用于指纹。例子包括基于PCA的特征重建,一个基于图嵌入的方法,以及基于深度学习的方法。原生RSFC方法是这两种方法中比较简单的,因为它们使用来自RSFC矩阵的原始连接值的子集。相比之下,RSFC衍生的方法使用了具有数千个参数的复杂机器学习模型,将RSFC矩阵投射到一个新的、不熟悉的嵌入空间,使受试者之间的方差最大化。尽管它们的复杂性有很大的不同,但这两种方法在性能上都比基线方法有相似的提高。这表明,RSFC派生的方法不能捕获比原生RSFC矩阵中可用的任何更多的信号。此外,原生RSFC方法还导致可解释特征的选择,因为FC信息是使用BOLD时间序列的相关性计算的。
原生RSFC方法的基本假设是,FC包含特定个体和通用信息。为了准确地进行指纹识别,需要有效地描述独特的个体特定信息。原生RSFC方法非常适合于此,它具有捕获可解释特性的额外优势。虽然已经独立研究了几种原生RSFC方法,但需要对这些方法进行系统的比较研究,以确定如何最有效地使用RSFC元素和程序进行指纹识别。
在本研究中,我们解决了我们对FC指纹识别问题的理解中的三个空白。首先,我们研究了样本量和分区粒度对指纹识别精度的联合影响。其次,我们使用了一种新的技术来帮助解释随着样本量的增加和分区粒度的减少,指纹识别的准确性降低的原因。为此,我们使用了来自数据挖掘社区的聚类质量指标。第三,我们开发了一个通用的特征选择框架,用于系统地识别过程和RSFC元素,捕获信息以唯一地识别个体。我们从这个框架中评估了六种不同的方法,量化了指纹识别的准确性以及随样本量增加而降低的准确性。我们还在两组独立的受试者中评估了所选特征的再现性。
2. 方法简述
2.1 被试数据
使用HCP1200分区+时间序列+Netmats(PTN)数据。HCP静息态数据经过最小预处理管道处理后,用组PCA和组空间ICA生成基于组的不同粒度的独立成分:15,25,50,100,200,300.组独立成分使用双回归映射到个体fMRI数据计算个体时间序列。我们将每个成分考虑为节点。该处理仅在1003名健康年轻成人(22 35岁,469男性,534女性)进行了4次静态功能磁共振成像(fMRI)测试,每个测试1200个时间点(共计4800个时间点),得到了15、25、50、100、200、300粒度的4组节点时间序列(每个扫描1组)。
2.2 FC指纹
在本节中,我们定义在本文其余部分中使用的术语,并讨论用于指纹分析的过程。我们将功能磁共振成像扫描称为参考扫描,因为我们知道它们是从哪个受试者那里收集的。我们将与参考扫描匹配的新扫描集称为目标扫描。给定一组N个参考扫描{R1,R2,…,RN}从N个不同的对象,和一组相同对象的目标扫描{T1,T2,…TN},FC指纹识别的问题是通过匹配其FC为每个目标扫描Ti确定对应的参考扫描Rj。这里有两个关键步骤:(a)计算FC, (b)匹配FC。
2.2.1 计算FC
将来自于2天的LR和RL标准化级联节点时间序列z分数化,创造两个~30min每天的每个被试的节点时间序列。计算每一对时间序列的皮尔森相关,得到相关矩阵。两天分别计算,得到每个被试的两天FC矩阵FCd1和FCd2.然后分别得到不同粒度的两天的相关矩阵。
2.2.2 匹配FC
为了匹配FC,我们使用了Finn等人(2015)中描述的方法。具体来说,对于从目标扫描Ti计算的每个FC,我们计算了目标FC矩阵的所有上三角值与每个参考FC的值之间的Pearson相关性。与目标FC显示最高相关性的引用FC被视为匹配。由于这种方法使用所有区域对的连接性值,我们将这种方法称为全-FC方法。
指纹识别的准确性计算为目标扫描与参考扫描正确匹配的受试者的比例。由于我们每个受试者都有两个FC (FCd1和FCd2),我们通过两种方式计算指纹的准确性:(a)以FCd1为参考,以FCd2为目标,(b)以FCd2为参考,以FCd1为目标。前一种和后一种情况的结果标记为Day1 Ref;Day2 Tgt和Day2 Ref;Day1 Tgt。
2.3 基于轮廓系数的FC指纹分析
2.3.1 样品大小和分区粒度对FC指纹的影响
为了研究样本量和分区粒度对FC指纹识别精度的影响,我们首先计算了不同样本量和分区封粒度的指纹识别精度。我们使用的样本大小从100到1000名受试者,步长为100,每个分区粒度(15,25,50,100,200和300)。每个样本尺寸和粒度重复150随机样本集。为了估计在非常大的样本规模下的指纹识别精度(目前无法对上述情况进行登记和研究),我们首先使用对数转换的受试者数量和由此产生的精度学习线性模型,然后在10万受试者下估计指纹识别精度。
2.3.2 轮廓系数
Finn等人(2015)的方法的基本假设是,从同一主体产生的所有FC在某些高维空间中距离很近,并且与从其他主体产生的FC分离得很好。然而,这一观点受到了最近研究观察的挑战,研究发现,随着受试者数量的增加,指纹识别的准确性会下降。我们的新假设是,随着来自不同受试者的FC数量的增加,先前与同一受试者的FC正确匹配的一个FC可能与来自不同受试者的新FC匹配的几率也会增加。
为了验证这一假设,我们使用轮廓系数,一个来自数据挖掘社区的常用聚类评估集合,以确定在高维空间中,被评分的个体FC与其他个体FC的分离程度。轮廓系数度量数据集中一些数据点聚类的内聚性和分离性(见图1左)。每个数据点的值从-1到1计算,接近-1的值表明该数据点更类似于分配给其他集群的点,而不是分配给它的集群内的点,而接近1的值表明该数据点更类似于其分配的集群内的点,而不是分配给其他集群的点。对于指纹识别假设,为一个对象计算的FC被视为一个集群的成员。在这种情况下,负值表示FC更类似于来自其他个体的FC,而不是来自自身主体的FC。
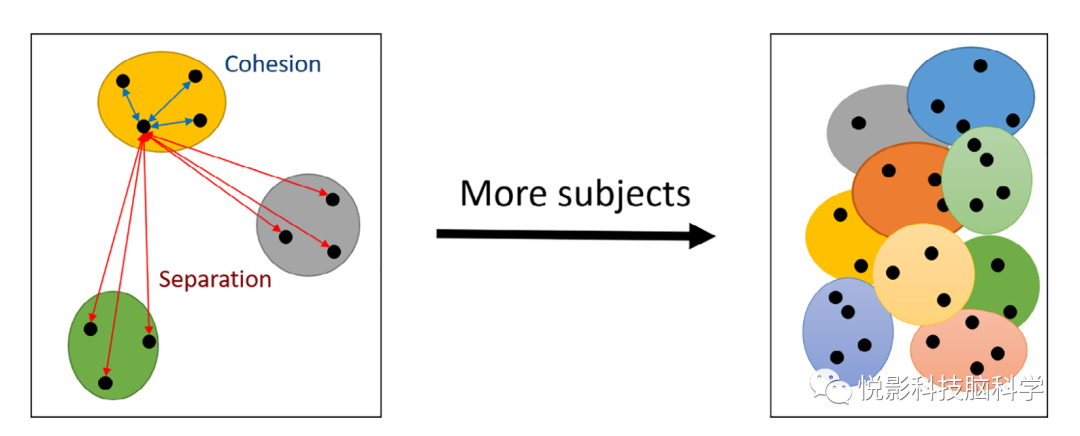
图1 左:FC在几何空间中的表示,这反映了FC指纹的基本假设,即来自同一主体的FC具有高度的内聚性,即彼此非常相似,一个主体的FC与其他主体的FC充分分离。右图:这反映了我们的假设,即随着受试者数量的增加,受试者空间的重叠程度会增加,从而减少分离.
2.4 特征选择框架改善FC指纹
个体级别的FC包含通用信息和个体特定信息。通过检测FC中包含特定个体信息的元素,我们可以有效地利用这些元素来减少FC的杂波,提高大样本FC指纹识别的准确性。我们开发了一个通用的FC特征选择框架,从FC矩阵中发现特定个体的信息。我们的框架计算每个特征中呈现的特定个体信息的数量,方法是考虑每个个体的FC与其他主体的FC的分离情况,并选择具有最多特定个体信息的特征。我们的FC特征选择框架包括四个设计参数:(a)什么被视为特征?(b)使用什么FC距离度量来量化两个FC之间的差异?(c)用什么评分标准来确定特征中特定个体信息的数量?(d)会选择多少特征?四个设计参数的组合选择将产生一种特征选择方法。从我们的框架中产生的参数选择以及最终的特性选择方法列在表1中。节点选择和边选择如图2所示。

图2 FC特征选择框架的特征定义。
2.5 FC特征选择方法的比较评价和轮廓系数分析
为了确定哪一种FC特征选择方法(如表1所示)在提高FC指纹识别精度方面比全FC方法更有效,我们对所有这些方法(包括全FC方法)进行了比较评估。
2.6 评价用最有效的方法选择RSFC元素的重现性
为了研究通过最有效的特征选择方法选择的FC特征的再现性,我们将数据任意地分成两个队列,并比较从不同队列中选择的特征。
3. 结果
3.1 FC指纹的基于轮廓系数的分析
我们通过不同的受试者数量和分区粒度分别计算基于RSFC的指纹识别精度。对于每个组合,我们测量了150个bootstrap样本数据的指纹识别精度。这使我们能够稳健地模拟这两个参数对指纹准确性的影响,并在目前可行的情况下推断样本大小的准确性。所有组合的自举样本指纹平均准确率如图3a所示,用于场景Day1 Ref;Day2 Tgt。我们从图3a中观察到,样本吧尺寸的增加导致指纹识别精度的降低,而分区粒度的增加导致指纹识别精度的提高。当分区粒度为300时,当样本量从100增加到1000时,指纹识别的准确率从94.05下降到89.64%,下降了4.41%。而当样本量为100时,当分区粒度从15增加到300时,指纹识别精度从63.48提高到94.05%,提高了30.57%。
为了揭示在HCP数据集之外的样本大小下的指纹识别性能,我们模拟了在分区粒度为300的情况下样本大小对指纹识别精度的影响。为了学习我们的模型,我们使用指纹精度测量每个bootstrap样本在不同的样本大小。这些数据在图3b中显示为每个样本大小的箱线图。我们观察到,与我们之前的观察相比,随着样本大小的增加,准确性有类似的下降,对于两个场景。Day1 Ref;Day2 Tgt和Day2 Ref;Day1 Tgt,前者的场景精度略高。我们学习了一个模型,该模型基于对受试者数量的对数来预测准确性。结果模型显示为图3b蓝色(Day1 Ref;Day2 Tgt)和红色(Day2 Ref;Day1 Tgt)虚线。
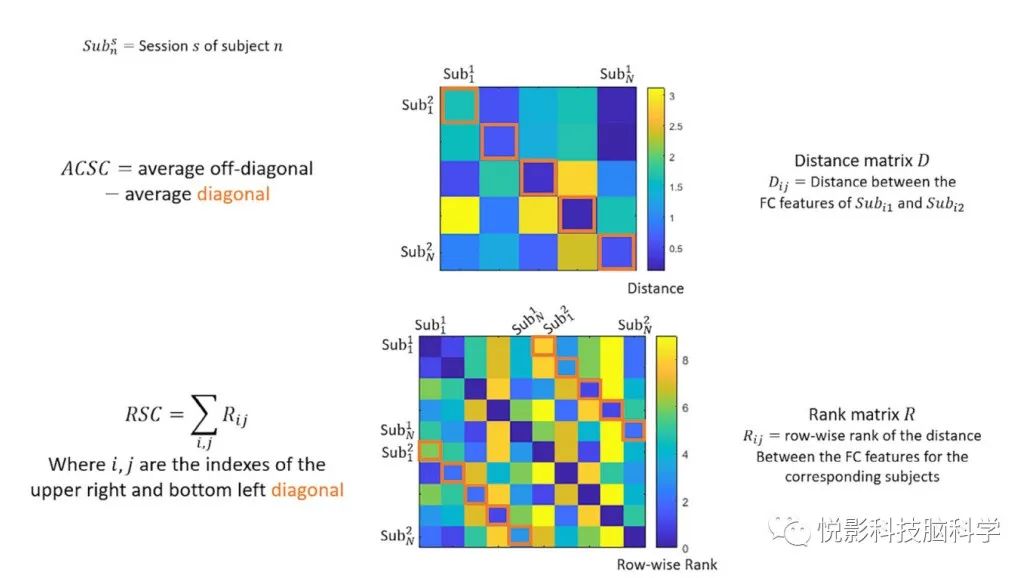
图3 用于评分的ACSC和RSC成本函数的说明
3.2 FC特征选择方法的比较评价
我们对FC特征选择方法进行了比较评估,包括基线的Full-FC方法。这些方法的平均指纹识别精度如图4a所示。所有特征选择方法的性能都优于全FC方法,全FC方法使用了FC矩阵中的所有边进行指纹提取。在特征选择方法中,ES方法优于NS方法。关于评分指标,ES方法与ACSC导致略好于RSC的准确性。这也是使用相关性作为距离度量的NS方法的情况,ACSC比RSC表现得更好。相比之下,对于使用标准化欧几里得距离的NS方法, RSC的表现优于ACSC。我们在运动审查数据上重复了这一分析,并做出了与补充数据的1.3节相同的观察结果。
为了研究这些方法在更大样本量下提高FC指纹识别准确性的潜力,我们学习了每种方法(包括Full-FC方法)在对数转换的受试者数量上的线性模型,然后估计10万受试者的准确性。最终的模型如图4a中的曲线所示。
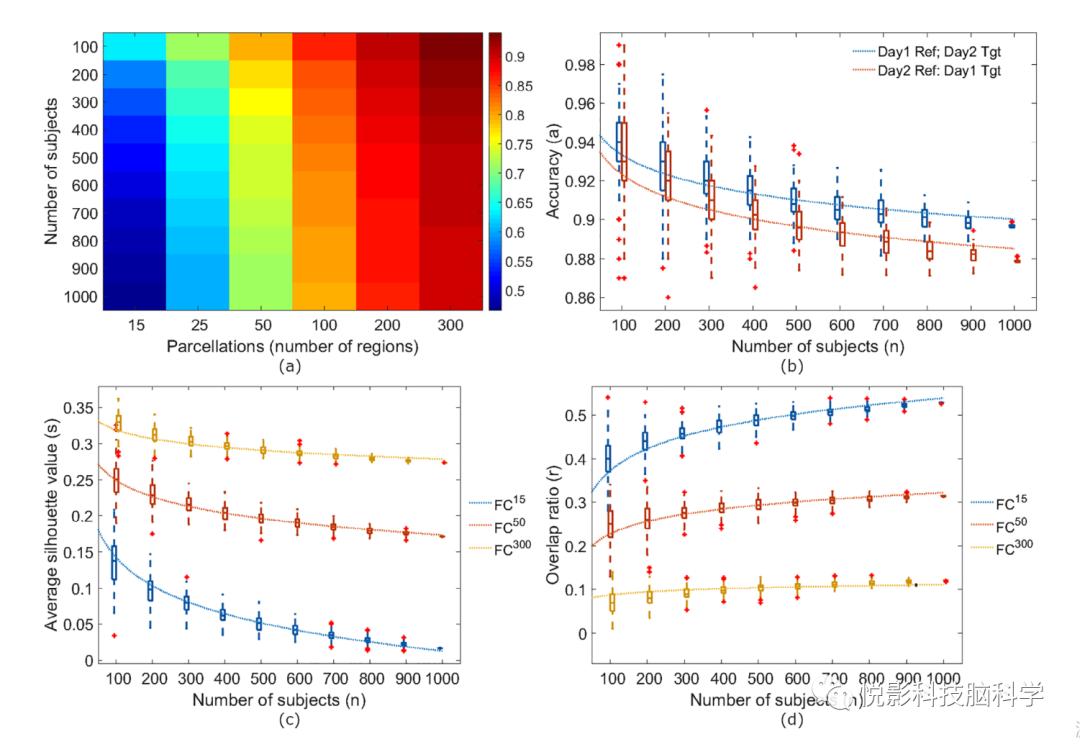
图4 上图:样本量和分区粒度对准确性的影响。下图:廓形系数分析,解释了样本量和分区粒度对指纹识别精度的影响
3.3基于轮廓系数的分析解释FC特征选择框架的应用
我们研究了特征选择方法对每个方法在不同样本量下的平均被试轮廓系数值的影响。这些结果如图4b所示。与Full-FC方法相比,ES方法产生了最高的平均轮廓系数值,NS方法产生了更好的平均轮廓系数值。关于得分,利用ACSC的ES方法得到的平均轮廓系数比RSC略好。然而,在NS方法的情况下,RSC导致一个更好的平均轮廓系数比ACSC。这是因为RSC同时考虑了会话内和会话间的FC距离,而ACSC只考虑后者。
使用特征选择方法选择的特征数量与平均轮廓系数和重叠率一起报告在表2中。产生最高平均轮廓系数值和最小重叠率的方法是ES-ACSC_δ方法(259条边),而全FC方法(44850条边)产生的性能最低。使用少量边的ES方法产生了最好的分离,即重叠率为0.02,而Full-FC方法为0.12。这一观察结果与第3.2节相同,支持了我们的假设,即FC包含特定个体信息和特定人群信息,边选择方法能够识别代表特定个体信息的边。
与精度结果一样,我们对平均受试者轮廓系数值(s)的对数转换受试者数量(n)计算线性模型,以调查更大样本量下的这些测量。结果发现的模型如图4b所示。
3.4 评估ES_ACSC_δ方法选择的FC元素的再现性
通过调查从两个不重叠的受试者队列中选择的特征之间的重叠程度,我们评估了ES_ACSC_δ方法选择的FC特征的重现性。所选特征的高度重叠表明所选特征在捕获特定于个体的信息时是可重复的。当我们从两个不重叠的500个受试者对了A和B(从FC300数据集中选择)中选择最上面的259条边时,我们发现所选的185个特征存在重叠。为了测量这种重叠的重要性,我们计算了一个超几何分布值。259个选择中有185个重叠,p值为0。该p值表明该量级的重叠在统计上是显著的,表明ES_ACSC_δ方法一致地再现了FC指纹有效的受试者特定边。
我们通过在图5a中绘制每个队列相对于其他队列的优势得分来可视化这种一致性。为了研究FC中259个得分最高的边之间的空间关系,我们绘制了一张热图,这些边根据它们的得分被着色,如图5b所示。ES_ACSC_δ选择的边如图5c所示。所选边的一般连接是在三个主要区域之间:额叶皮层、顶叶区域和皮层下区域。
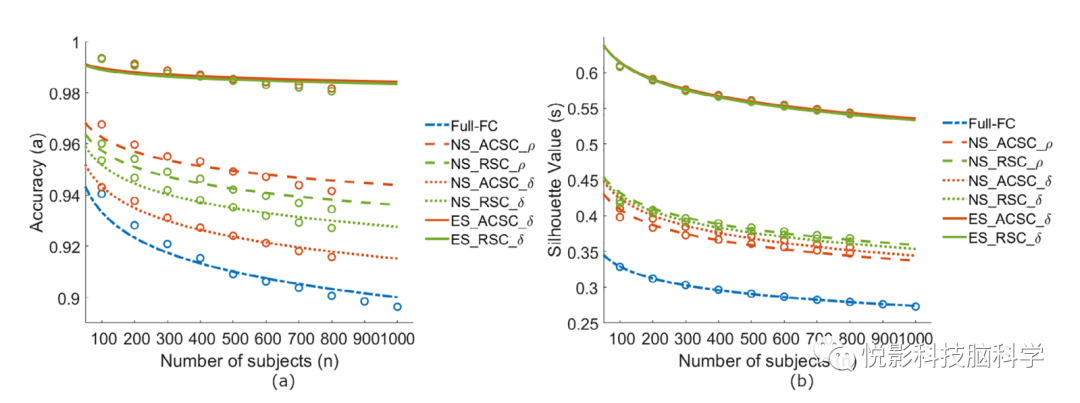
图5 FC特征选择方法和全FC方法的性能。
ES方法的优越性能是由于选择的边具有较高的会话间方差,但较低的主体内差异,因为这些是FC指纹最有效的。节点包含高方差和低方差边的混合,因此NS方法不如ES方法。为了演示这一点,我们将ES_ACSC_δ选择的边的方差与每个节点中存在的边的方差进行比较,绘制每个节点中边的边方差密度以及ES_ACSC_δ选择的边的方差(如图6d所示)。我们观察到,与ES_ACSC_δ选择的边相比,所有节点都包含了很大一部分低方差边。这些结果强调了ES方法捕捉边的十密度,这些边在不同被试之间表现出高差异。
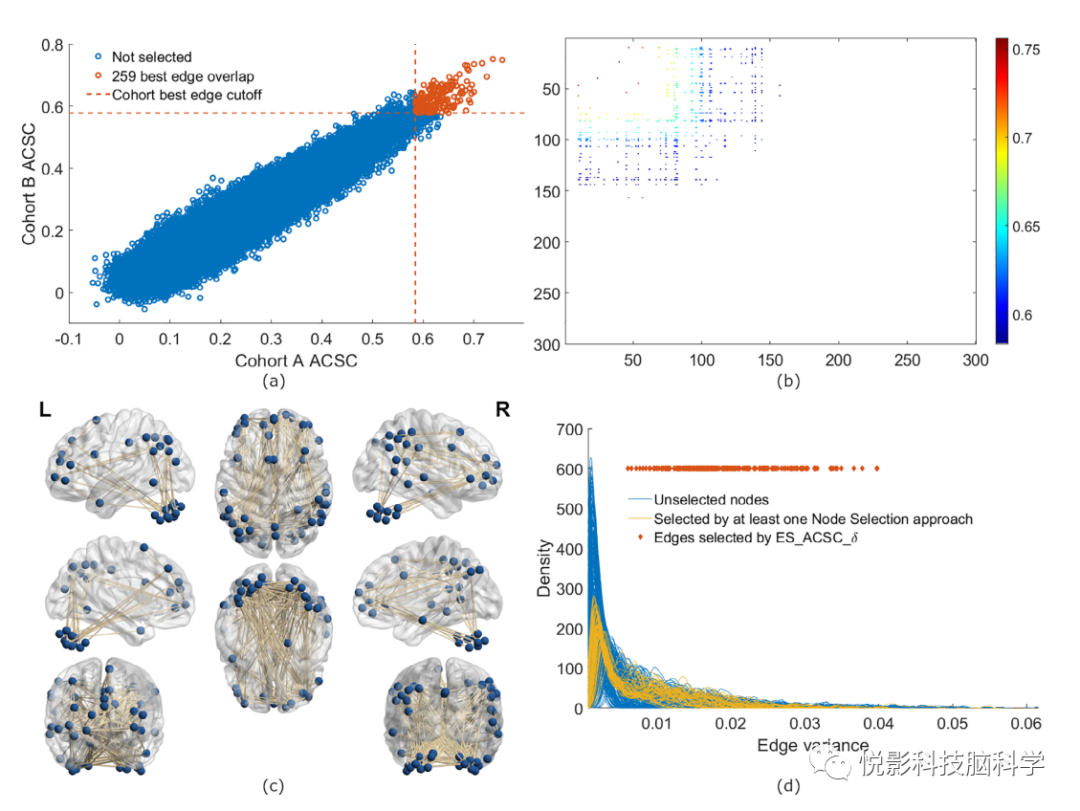
图6 上图:指纹识别精度最高的方法ES_ACSC_δ方法发现的特征的再现性。底部:(c)在队列中使用ES_ACSC_δ方法选择的边。(d)所有300个节点的边方差密度。
4. 讨论
在这项研究中,我们发现样本量的增加会导致指纹识别精度的降低,而分区粒度的增加会增加指纹识别精度。我们使用轮廓系数来发现这些观察背后的原因,轮廓系数是数据挖掘文献中用于评估聚类质量的度量指标。结果表明,随着被试人数的增加,高维空间变得更加杂乱,导致不同被试的FC之间具有较高的相似性。为了提高指纹识别的准确性,我们引入了一个通用的特征选择框架,该框架类似于数据挖掘中用于分类问题的特征选择技术,以识别信息量最大的特征。我们评估了我们的框架的不同实例,以确定最有效的方法。边选择方法,特别是ES_ACSC_δ,被观察到是最有效的识别个体特定的特征,尽管包含相对较少的边数量。我们展示了使用基于轮廓度量的分析如何选择边,从而更好地分离来自同一个体的FC。我们的结果最后表明,使用ES_ACSC_δ选择的边具有很高的重现性,并且与使用其他方法选择的边(和相关边)有本质上的不同。
我们观察到,样本量的增加导致指纹识别精度的降低,而分区粒度的增加导致指纹识别精度的提高,这与现有的文献一致。
这项工作的主要贡献之一是揭示了指纹识别精度随受试者数量和分区粒度变化的原因,其中我们使用了轮廓系数,该系数通常用于通过测量聚类点的凝聚力和聚类的分离来评估数据点聚类的质量。
这项工作的另一个贡献是提出的特征选择框架,以缓解聚类问题。这个框架由四个设计选择组成:(a)哪些FC元素被定义为特征,例如,节点或边?(b)使用什么成本函数对特征进行评分,以确定选择的最优特征?(c)用什么方法来计算我们的代价函数的距离?(d)用什么停止标准来决定要选择的最终特征的数量?我们测试了我们的框架的各种可能的实例,以深入了解哪些特征、成本函数和距离测量在提高FC指纹精度方面最有效。为此,我们比较了两个特征,节点配置文件(节点选择(NS))和边(边选择(ES));两种代价函数,平均跨会话代价(ACSC)和秩和代价(RSC);两种距离度量,标准化欧氏相关(SE)和皮尔森相关(correlation)。
对于每一个特征,本工作中研究的选择方法,我们建立了随着样本量增加准确度下降的速率模型。
在我们的框架中,使用最佳方法(ES_ACSC_δ)选择的边存在于三个主要区域:额叶皮质、顶叶区域和皮层下区域。
5. 总结
在本研究中,我们使用数据挖掘社区中常用的轮廓系数方法,展示了指纹识别性能随样本容量增加而下降的原因。提出了一种通用的特征选择框架。FC的特征非常适合唯一识别个体。我们评估了该框架下的六种不同方法,结果表明,基于ES的方法在指纹识别准确性和准确率随样本量增加而下降的速度方面优于基于NS的方法。我们还观察到,使用最佳方法选择的边是独立于收集数据的队列,但跨队列一致。希望目前的研究结果能够为进一步提高未来FC指纹调查的测量质量提供清晰度和指导。
参考文献:Feature selection framework for functional connectome fingerprinting.
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号