Tesseract-OCR 介绍

Tesseract-OCR 介绍

用户6021899
发布于 2023-08-09 13:31:46
发布于 2023-08-09 13:31:46
Tesseract是一个开源的ocr(光学字符识别,即将含有文字的图片转化为文本)引擎,可以开箱即用,项目最初由惠普实验室支持,1996年被移植到Windows上,1998年进行了C++化。在2005年Tesseract由惠普公司宣布开源。2006年到现在,都由Google公司开发。
Tesseract-OCR的windows安装包网址是
https://digi.bib.uni-mannheim.de/tesseract/
上面的最新版是:
下载后即可安装,安装时需要勾选你需要的语言库。安装完成后需要将安装路径添加到环境变量。假如你选择的的安装路径是C:\Program Files\Tesseract-OCR,将这个路径添加到系统环境变量 path。
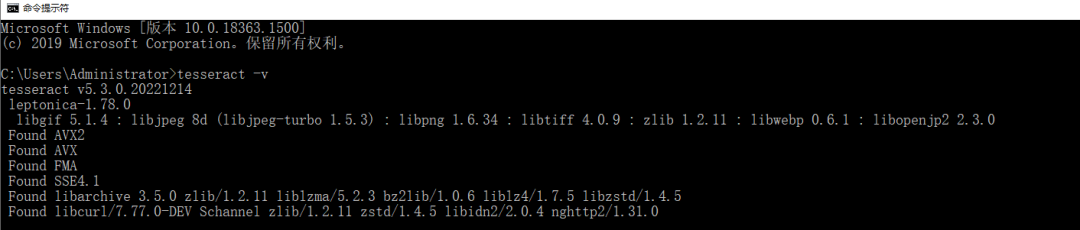
环境变量设置好之后可以在命令行输入
- tesseract -v
- 出现图片中类似的响应,即表明Tesseract-OCR 的安装和设置是成功的。
之后想要在Python 中调用 Tesseract-OCR,只需安装pytesseract。
(注意前提是成功安装Tesseract-OCR 和设置好环境变量!)
- pip install pytesseract
下面是Python 调用Tesseract-OCR的示例代码:
图片:

from PIL import Image
import pytesseract
img_path = r'D:\Backup\我的文档\My Pictures\捕获.PNG'
text=pytesseract.image_to_string(Image.open(img_path), lang="chi_sim", config="–psm 11 pdf")
# –psm 3 : 一块一块的识别
# –psm 6:一行一行的识别
# –psm 11 pdf:保留布局
#text=pytesseract.image_to_string(Image.open(img_path), lang="eng", config="–psm 3")
# print(help(pytesseract.image_to_string))
print(text)输出的文字:
OCRQ (Optical Character Recognition): 光学字符识别,是指电子设备 (例如扫描仪或数码相机) 检查纸上打印的字符,通过检测
瞳、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程。
TesseractQ : 开源的OCR识别引擎,初期Tesseract3|警由HP实验室研发,后来贡献给了开源软件业,后由Google进行改进、修
改bug、优化,重新发布。中文宋体识别的整体效果不错!
当然,英文识别的效果最佳,这里不再展示。
Tesseract-OCR 的更多的用法详细介绍请前往链接:
https://tesseract-ocr.github.io/tessdoc/Command-Line-Usage.html#s
implest-invocation-to-ocr-an-image
关于字库的训练请参考这篇网络文章:
https://blog.csdn.net/Mkite/article/details/126237898
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 Python可视化编程机器学习OpenCV 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号