进击消息中间件系列(二十):Kafka 生产调优最佳实践

进击消息中间件系列(二十):Kafka 生产调优最佳实践

民工哥
发布于 2023-08-22 14:25:40
发布于 2023-08-22 14:25:40
操作系统
kafka推荐使用linux操作系统。
Kafka硬件配置选择
场景说明
- 100 万日活,每人每天 100 条日志,每天总共的日志条数是 100 万 * 100 条 = 1 亿条。
- 1 亿/24 小时/60 分/60 秒 = 1150 条/每秒钟。
- 每条日志大小:0.5k - 2k(取 1k)。
- 1150 条/每秒钟 * 1k ≈ 1m/s 。
- 高峰期每秒钟:1150 条 * 20 倍 = 23000 条。
- 每秒多少数据量:20MB/s。
服务器台数选择
服务器台数= 2 * (生产者峰值生产速率 * 副本 / 100) + 1,即 2 * (20m/s * 2 / 100) + 1= 3 台。建议 3 台服务器。
磁盘选择
kafka 底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。建议选择普通的机械硬盘。
每天总数据量:1 亿条 * 1k ≈ 100g,100g * 副本 2 * 保存时间 3 天 / 0.7 ≈ 1T。建议三台服务器硬盘总大小,大于等于 1T。
内存选择
Kafka 内存组成:堆内存 + 页缓存
- Kafka 堆内存建议每个节点:10g ~ 15g
在 kafka-server-start.sh 中修改
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx10G -Xms10G"fi
查看 Kafka 进程号
[atguigu@hadoop102 kafka]$ jps2321 Kafka5255 Jps1931 QuorumPeerMain
根据 Kafka 进程号,查看 Kafka 的 GC 情况
[atguigu@hadoop102 kafka]$ jstat -gc 2321 1s 10
S0C S1C S0U S1U EC EU OC OU MC MU CCSC CCSU YGC YGCT FGC FGCT GCT
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 60416.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
0.0 7168.0 0.0 7168.0 103424.0 61440.0 1986560.0 148433.5 52092.0 46656.1 6780.0 6202.2 13 0.531 0 0.000 0.531
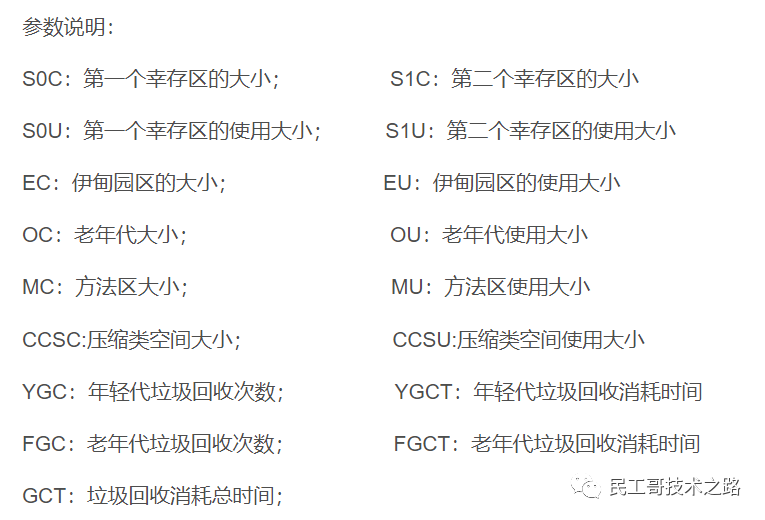
页缓存:页缓存是 Linux 系统服务器的内存。我们只需要保证 1 个 segment(1g)中25%的数据在内存中就好。
每个节点页缓存大小 =(分区数 * 1g * 25%)/ 节点数。例如 10 个分区,页缓存大小=(10 * 1g * 25%)/ 3 ≈ 1g。
CPU选择
- num.io.threads = 8 负责写磁盘的线程数,整个参数值要占总核数的 50%。
- num.replica.fetchers = 1 副本拉取线程数,这个参数占总核数的 50%的 1/3。
- num.network.threads = 3 数据传输线程数,这个参数占总核数的 50%的 2/3。
建议 32 个 cpu core。
网络选择
网络带宽 = 峰值吞吐量 ≈ 20MB/s 。选择千兆网卡即可。100Mbps 单位是 bit;10M/s 单位是 byte ; 1byte = 8bit,100Mbps/8 = 12.5M/s。一般百兆的网卡(100Mbps )、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
Kafka 总体调优指南
Kafka 是一个高吞吐量、低延迟、分布式的消息中间件,但还是有必要进行性能调优以确保其正常运行。下面是一些性能调优的建议:
- 配置适当的 num.io.threads 参数使每个Kafka实例的网络I/O线程数量与CPU核心数大致相等
- 调整 max.message.bytes 和 replica.fetch.max.bytes 参数,以提高 Kafka 的吞吐量和延迟性能
- 为每个Kafka的分区配置适当数量的ISR (in-sync replicas),避免ISR集合太小而导致消息在网络上的长时间等待
- 使用SSD硬盘可提高 Kafka 的读写I/O性能和稳定性
提升生产吞吐量
- buffer.memory:发送消息的缓冲区大小,默认值是 32m,可以增加到 64m。
- batch.size:默认是 16k。如果 batch 设置太小,会导致频繁网络请求,吞吐量下降;如果 batch 太大,会导致一条消息需要等待很久才能被发送出去,增加网络延时
- linger.ms,这个值默认是 0,意思就是消息必须立即被发送。一般设置一个 5-100毫秒。如果 linger.ms 设置的太小,会导致频繁网络请求,吞吐量下降;如果 linger.ms 太长,会导致一条消息需要等待很久才能被发送出去,增加网络延时。
- compression.type:默认是 none,不压缩,但是也可以使用 lz4 压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大 producer 端的 CPU 开销。
2)增加分区
3)消费者提高吞吐量
- 调整 fetch.max.bytes 大小,默认是 50m。
- 调整 max.poll.records 大小,默认是 500 条。
4)增加下游消费者处理能力
数据精准一次
1)生产者角度
- acks 设置为-1 (acks=-1)。
- 幂等性(enable.idempotence = true) + 事务 。
2)broker 服务端角度
- 分区副本大于等于 2 (--replication-factor 2)。
- ISR 里应答的最小副本数量大于等于 2 (min.insync.replicas = 2)。
3)消费者
- 事务 + 手动提交 offset (enable.auto.commit = false)。
- 消费者输出的目的地必须支持事务(MySQL、Kafka)。
合理设置分区数
- 创建一个只有 1 个分区的 topic。
- 测试这个 topic 的 producer 吞吐量和 consumer 吞吐量。
- 假设他们的值分别是 Tp 和 Tc,单位可以是 MB/s。
- 然后假设总的目标吞吐量是 Tt,那么分区数 = Tt / min(Tp,Tc)。
例如:producer 吞吐量 = 20m/s;consumer 吞吐量 = 50m/s,期望吞吐量 100m/s;
- 分区数 = 100 / 20 = 5 分区
- 分区数一般设置为:3-10 个
分区数不是越多越好,也不是越少越好,需要搭建完集群,进行压测,再灵活调整分区个数。
单条日志大于1m
message.max.bytes
#默认 1m,broker 端接收每个批次消息最大值。
max.request.size
#默认 1m,生产者发往 broker 每个请求消息最大值。针对 topic级别设置消息体的大小。
replica.fetch.max.bytes
#默认 1m,副本同步数据,每个批次消息最大值。
fetch.max.bytes
#默认 Default: 52428800(50 m)。消费者获取服务器端一批消息最大的字节数。如果服务器端一批次的数据大于该值(50m)仍然可以拉取回来这批数据,因此,这不是一个绝对最大值。一批次的大小受 message.max.bytes (broker config)or max.message.bytes (topic config)影响。
服务器挂了
在生产环境中,如果某个 Kafka 节点挂掉。正常处理办法:
- 先尝试重新启动一下,如果能启动正常,那直接解决。
- 如果重启不行,考虑增加内存、增加 CPU、网络带宽。
- 如果将 kafka 整个节点误删除,如果副本数大于等于 2,可以按照服役新节点的方式重新服役一个新节点,并执行负载均衡。
- 集群压力测试
Kafka 压测
用 Kafka 官方自带的脚本,对 Kafka 进行压测。
- 生产者压测:kafka-producer-perf-test.sh
- 消费者压测:kafka-consumer-perf-test.sh
Kafka Producer 压力测试
先说结论:
- 增大batch.size,能提升吞吐量
- 增大linger.ms,能提升吞吐量
- 增大buffer.memory,能提升吞吐量
- 压缩方式compression.type 设置为 zstd 或gzip,能提升吞吐量
创建一个 test topic,设置为 3 个分区 3 个副本
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrapserver hadoop102:9092 --create --replication-factor 3 --partitions 3 --topic test
在/opt/module/kafka/bin 目录下面有这两个文件。我们来测试一下
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384 linger.ms=0
- record-size 是一条信息有多大,单位是字节,本次测试设置为 1k。
- num-records 是总共发送多少条信息,本次测试设置为 100 万条。
- throughput 是每秒多少条信息,设成-1,表示不限流,尽可能快的生产数据,可测出生产者最大吞吐量。本次实验设置为每秒钟 1 万条。
- producer-props 后面可以配置生产者相关参数,batch.size 配置为 16k。
输出结果:
ap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=16384
linger.ms=0
37021 records sent, 7401.2 records/sec (7.23 MB/sec), 1136.0 ms avg latency, 1453.0 ms max latency.
50535 records sent, 10107.0 records/sec (9.87 MB/sec), 1199.5 ms avg latency, 1404.0 ms max latency.
47835 records sent, 9567.0 records/sec (9.34 MB/sec), 1350.8 ms avg latency, 1570.0 ms max latency.
。。。 。。。
42390 records sent, 8444.2 records/sec (8.25 MB/sec), 3372.6 ms avg latency, 4008.0 ms max latency.
37800 records sent, 7558.5 records/sec (7.38 MB/sec), 4079.7 ms avg latency, 4758.0 ms max latency.
33570 records sent, 6714.0 records/sec (6.56 MB/sec), 4549.0 ms avg latency, 5049.0 ms max latency.
1000000 records sent, 9180.713158 records/sec (8.97 MB/sec), 1894.78 ms avg latency, 5049.00 ms max latency, 1335 ms 50th, 4128 ms 95th, 4719 ms 99th, 5030 ms 99.9th.
调整 batch.size 大小
①batch.size 默认值是 16k。本次实验 batch.size 设置为 32k。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=32768 linger.ms=0
输出结果:
49922 records sent, 9978.4 records/sec (9.74 MB/sec), 64.2 ms avg latency, 340.0 ms max latency.
49940 records sent, 9988.0 records/sec (9.75 MB/sec), 15.3 ms avg latency, 31.0 ms max latency.
50018 records sent, 10003.6 records/sec (9.77 MB/sec), 16.4 ms avg latency, 52.0 ms max latency.
。。。 。。。
49960 records sent, 9992.0 records/sec (9.76 MB/sec), 17.2 ms avg latency, 40.0 ms max latency.
50090 records sent, 10016.0 records/sec (9.78 MB/sec), 16.9 ms avg latency, 47.0 ms max latency.
1000000 records sent, 9997.600576 records/sec (9.76 MB/sec), 20.20 ms avg latency, 340.00 ms max latency, 16 ms 50th, 30 ms 95th, 168 ms 99th, 249 ms 99.9th.
②batch.size 默认值是 16k。本次实验 batch.size 设置为 4k。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=0
输出结果:
15598 records sent, 3117.1 records/sec (3.04 MB/sec), 1878.3 ms avg latency, 3458.0 ms max latency.
17748 records sent, 3549.6 records/sec (3.47 MB/sec), 5072.5 ms avg latency, 6705.0 ms max latency.
18675 records sent, 3733.5 records/sec (3.65 MB/sec), 6800.9 ms avg latency, 7052.0 ms max latency.
。。。 。。。
19125 records sent, 3825.0 records/sec (3.74 MB/sec), 6416.5 ms avg latency, 7023.0 ms max latency.
1000000 records sent, 3660.201531 records/sec (3.57 MB/sec), 6576.68 ms avg latency, 7677.00 ms max latency, 6745 ms 50th, 7298 ms 95th, 7507 ms 99th, 7633 ms 99.9th.
调整 linger.ms 时间
linger.ms 默认是 0ms。本次实验 linger.ms 设置为 50ms。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50
输出结果:
16804 records sent, 3360.1 records/sec (3.28 MB/sec), 1841.6 ms avg latency, 3338.0 ms max latency.
18972 records sent, 3793.6 records/sec (3.70 MB/sec), 4877.7 ms avg latency, 6453.0 ms max latency.
19269 records sent, 3852.3 records/sec (3.76 MB/sec), 6477.9 ms avg latency, 6686.0 ms max latency.
。。。 。。。
17073 records sent, 3414.6 records/sec (3.33 MB/sec), 6987.7 ms avg latency, 7353.0 ms max latency.
19326 records sent, 3865.2 records/sec (3.77 MB/sec), 6756.5 ms avg latency, 7357.0 ms max latency.
1000000 records sent, 3842.754486 records/sec (3.75 MB/sec), 6272.49 ms avg latency, 7437.00 ms max latency, 6308 ms 50th, 6880 ms 95th, 7289 ms 99th, 7387 ms 99.9th.
调整压缩方式
①默认的压缩方式是 none。本次实验 compression.type 设置为 snappy。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=snappy
输出结果:
17244 records sent, 3446.0 records/sec (3.37 MB/sec), 5207.0 ms avg latency, 6861.0 ms max latency.
18873 records sent, 3774.6 records/sec (3.69 MB/sec), 6865.0 ms avg latency, 7094.0 ms max latency.
18378 records sent, 3674.1 records/sec (3.59 MB/sec), 6579.2 ms avg latency, 6738.0 ms max latency.
。。。 。。。
17631 records sent, 3526.2 records/sec (3.44 MB/sec), 6671.3 ms avg latency, 7566.0 ms max latency.
19116 records sent, 3823.2 records/sec (3.73 MB/sec), 6739.4 ms avg latency, 7630.0 ms max latency.
1000000 records sent, 3722.925028 records/sec (3.64 MB/sec), 6467.75 ms avg latency, 7727.00 ms max latency, 6440 ms 50th, 7308 ms 95th, 7553 ms 99th, 7665 ms 99.9th
②默认的压缩方式是 none。本次实验 compression.type 设置为 zstd。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=zstd
输出结果:
23820 records sent, 4763.0 records/sec (4.65 MB/sec), 1580.2 ms avg latency, 2651.0 ms max latency.
29340 records sent, 5868.0 records/sec (5.73 MB/sec), 3666.0 ms avg latency, 4752.0 ms max latency.
28950 records sent, 5788.8 records/sec (5.65 MB/sec), 5785.2 ms avg latency, 6865.0 ms max latency.
。。。 。。。
29580 records sent, 5916.0 records/sec (5.78 MB/sec), 6907.6 ms avg latency, 7432.0 ms max latency.
29925 records sent, 5981.4 records/sec (5.84 MB/sec), 6948.9 ms avg latency, 7541.0 ms max latency.
1000000 records sent, 5733.583318 records/sec (5.60 MB/sec), 6824.75 ms avg latency, 7595.00 ms max latency, 7067 ms 50th, 7400 ms 95th, 7500 ms 99th, 7552 ms 99.9th.
③默认的压缩方式是 none。本次实验 compression.type 设置为 gzip。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=gzip
输出结果:
27170 records sent, 5428.6 records/sec (5.30 MB/sec), 1374.0 ms avg latency, 2311.0 ms max latency.
31050 records sent, 6210.0 records/sec (6.06 MB/sec), 3183.8 ms avg latency, 4228.0 ms max latency.
32145 records sent, 6427.7 records/sec (6.28 MB/sec), 5028.1 ms avg latency, 6042.0 ms max latency.
。。。 。。。
31710 records sent, 6342.0 records/sec (6.19 MB/sec), 6457.1 ms avg latency, 6777.0 ms max latency.
31755 records sent, 6348.5 records/sec (6.20 MB/sec), 6498.7 ms avg latency, 6780.0 ms max latency.
32760 records sent, 6548.1 records/sec (6.39 MB/sec), 6375.7 ms avg latency, 6822.0 ms max latency.
1000000 records sent, 6320.153706 records/sec (6.17 MB/sec), 6155.42 ms avg latency, 6943.00 ms max latency, 6437 ms 50th, 6774 ms 95th, 6863 ms 99th, 6912 ms 99.9th.
④默认的压缩方式是 none。本次实验 compression.type 设置为 lz4。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 compression.type=lz4
输出结果:
16696 records sent, 3339.2 records/sec (3.26 MB/sec), 1924.5 ms avg latency, 3355.0 ms max latency.
19647 records sent, 3928.6 records/sec (3.84 MB/sec), 4841.5 ms avg latency, 6320.0 ms max latency.
20142 records sent, 4028.4 records/sec (3.93 MB/sec), 6203.2 ms avg latency, 6378.0 ms max latency.
。。。 。。。
20130 records sent, 4024.4 records/sec (3.93 MB/sec), 6073.6 ms avg latency, 6396.0 ms max latency.
19449 records sent, 3889.8 records/sec (3.80 MB/sec), 6195.6 ms avg latency, 6500.0 ms max latency.
19872 records sent, 3972.8 records/sec (3.88 MB/sec), 6274.5 ms avg latency, 6565.0 ms max latency.
1000000 records sent, 3956.087430 records/sec (3.86 MB/sec), 6085.62 ms avg latency, 6745.00 ms max latency, 6212 ms 50th, 6524 ms 95th, 6610 ms 99th, 6695 ms 99.9th.
调整缓存大小
默认生产者端缓存大小 32m。本次实验 buffer.memory 设置为 64m。
[atguigu@hadoop105 kafka]$ bin/kafka-producer-perf-test.sh --topic test --record-size 1024 --num-records 1000000 --throughput 10000 --producer-props bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092 batch.size=4096 linger.ms=50 buffer.memory=67108864
输出结果:
20170 records sent, 4034.0 records/sec (3.94 MB/sec), 1669.5 ms avg latency, 3040.0 ms max latency.
21996 records sent, 4399.2 records/sec (4.30 MB/sec), 4407.9 ms avg latency, 5806.0 ms max latency.
22113 records sent, 4422.6 records/sec (4.32 MB/sec), 7189.0 ms avg latency, 8623.0 ms max latency.
。。。 。。。
19818 records sent, 3963.6 records/sec (3.87 MB/sec), 12416.0 ms avg latency, 12847.0 ms max latency.
20331 records sent, 4062.9 records/sec (3.97 MB/sec), 12400.4 ms avg latency, 12874.0 ms max latency.
19665 records sent, 3933.0 records/sec (3.84 MB/sec), 12303.9 ms avg latency, 12838.0 ms max latency.
1000000 records sent, 4020.100503 records/sec (3.93 MB/sec), 11692.17 ms avg latency, 13796.00 ms max latency, 12238 ms 50th, 12949 ms 95th, 13691 ms 99th, 13766 ms 99.9th.
Kafka Consumer 压力测试
一次拉取条数为 500
修改/opt/module/kafka/config/consumer.properties
max.poll.records=500
消费 100 万条日志进行压测
[atguigu@hadoop105 kafka]$ bin/kafka-consumer-perf-test.sh --bootstrap-server hadoop102:9092,hadoop103:9092,hadoop104:9092 --topic test --messages 1000000 --consumer.config config/consumer.properties
--bootstrap-server #指定 Kafka 集群地址
--topic #指定 topic 的名称
--messages #总共要消费的消息个数。本次实验 100 万条。
输出结果:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-01-20 09:58:26:171, 2022-01-20 09:58:33:321, 977.0166, 136.6457, 1000465, 139925.1748, 415, 6735, 145.0656, 148547.1418
一次拉取条数为 2000
输出结果:
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-01-20 10:18:06:268, 2022-01-20 10:18:12:863, 977.5146, 148.2206, 1000975, 151777.8620, 358, 6237, 156.7283, 160489.8188
调整 fetch.max.bytes 大小为 100m
①修改/opt/module/kafka/config/consumer.properties 文件中的拉取一批数据大小 100m。
fetch.max.bytes=104857600
②再次执行
start.time, end.time, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec, rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
2022-01-20 10:26:13:203, 2022-01-20 10:26:19:662, 977.5146, 151.3415, 1000975, 154973.6801, 362, 6097, 160.3272, 164175.0041
参考文章:https://blog.csdn.net/guaituo0129/article/details/131366898
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-08-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号