预测编码和主动推理的大脑结构的演变

预测编码和主动推理的大脑结构的演变

CreateAMind
发布于 2023-09-26 08:30:19
发布于 2023-09-26 08:30:19
The evolution of brain architectures for predictive coding and active inference
- 抽象的
The evolution of brain architectures for predictive coding and active inference
预测编码和主动推理的大脑结构的演变
乔瓦尼·佩祖洛
,
托马斯·帕尔
和
卡尔·弗里斯顿
发布日期:2021 年 12 月 27 日https://doi.org/10.1098/rstb.2020.0531
抽象的
本文探讨了用于预测处理的大脑结构的演变。我们认为,预测感知和行动的大脑机制并不是像我们这样的高级生物的晚期进化添加。相反,它们是从更简单的预测循环(例如自主和运动反射)中逐渐出现的,这是我们早期进化祖先的遗产,并且是解决适应性调节基本问题的关键。我们根据生成模型来正式描述从简单到复杂的大脑,其中包括增加层次广度和深度的预测循环。这些可能从一个简单的稳态主题开始,并在进化过程中以四种主要方式进行阐述:其中包括多模式扩展将预测控制引入到动态调节环路中;它的复制形成多个感觉运动环路,从而扩展动物的行为能力;生成模型逐渐赋予层次深度(以处理在不同空间尺度上展开的世界的各个方面)和时间深度(以面向未来的方式选择计划)。反过来,这些阐述为日益复杂的动物所面临的生物调节问题提供了解决方案。我们的提议将关于预测处理的神经科学理论与不同动物物种大脑结构的进化和比较数据结合起来。
本文是“进化论视角下的系统神经科学”主题的一部分。
一、简介
人们越来越一致认为,人类和其他系统发育或高级生物的大脑在感知(预测编码 [ 1 , 2 ])和行动控制(主动推理 [ 3 , 4 ])方面以预测方式运行。然而,我们的高级预测能力在进化过程中是如何产生的仍不清楚。本文的目的是概述用于预测处理的大脑结构的进化历史。
我们建议的核心原则是,尽管预测通常被描述为一种复杂的认知功能,但它并不是像我们这样的高级动物在进化后期添加的。相反,我们复杂的预测能力(例如计划和想象力)是从更简单的预测和纠错循环(例如运动和自主反射)逐渐(例如通过系统渐进主义或间断平衡)出现的,而这些循环已经是我们早期进化祖先大脑的一部分——是解决适应性监管问题的关键[ 5-7 ]。
我们首先从“生成模型”的角度考虑祖先大脑的设计,该模型使用简单的预测主题进行适应性调节。然后我们讨论如何通过区分生成模型并赋予它们层次和时间深度来在进化过程中选择结构设计。反过来,这三个扩展增强了物种特定行为的能力,并提供了日益复杂的预测能力,例如计划和想象力,这是高级动物的特征。
2. 预测调节和控制是大脑的基本设计原理
每个生物体都面临着对其重要参数(例如体温或血糖水平)进行适应性调节和控制的基本问题。尽管一些生物体(例如植物)在没有大脑的情况下也能生存,但通过在世界上移动来解决适应性控制问题的可能性(例如寻找食物和住所)可能对大脑的进化产生了强大的选择压力。
从形式角度来看,可以将适应性控制概念化为仅“访问”一组有限的可能状态的必要条件,或者保持在满足存在要求的(依赖于有机体的)利基中。其中一个例子就是必须将体温保持在 37° 左右。用信息术语来说,位于这些可接受边界之外的状态是“令人惊讶的”。例如,感知到的体温远高于或低于 37°,或者金鱼离开水的感觉,在技术意义上都是“令人惊讶的”(从技术上讲,这种惊讶称为“惊讶”或“自我信息”) 。这意味着生物体必须尽量减少与生态位的感官交流的意外。
反过来,惊喜是两件事的函数:从世界中积极采样的感官观察和内部生成的关于观察的预测。具体来说,惊喜随着预测和观察之间的差异而增加(在高斯假设下,这种差异是预测和观察之间的平方差),见图1。
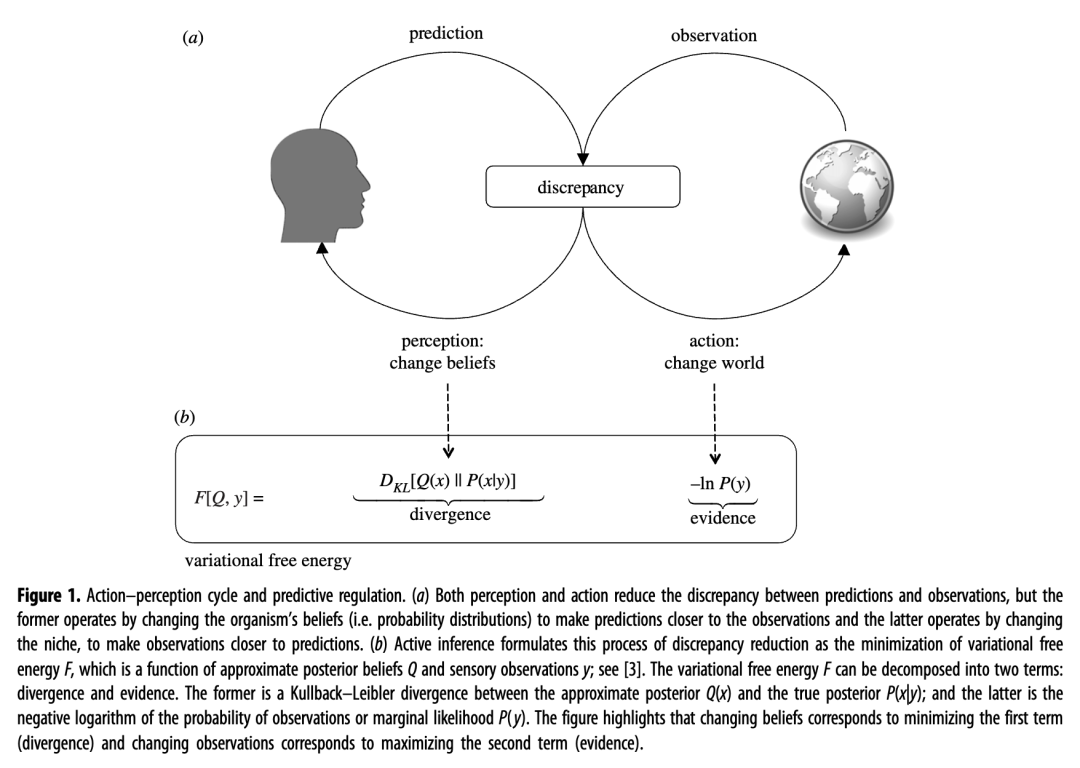
图 1.
- 下载图
- 在新选项卡中打开
- 下载幻灯片
有机体可以通过两种方式最小化这种差异:通过改变想法以更好地预测下一次观察(感知)或通过改变世界以确保下一次观察符合预测(行动)(见图1a)。主动推理将随后的惊喜解决形式化为变分自由能的最小化:一个量,它是惊喜的上限,其两个组成部分(分歧和惊喜)分别映射到感知和行动;技术细节参见图 1b和[ 3 ]。
如图1所示,行动和感知协同作用,最大限度地减少预测和观察(或正式的变分自由能)之间的差异。如果没有感知,动物将难以选择适当的行动(或者只能使用非常有限的技能,例如,如果没有食物,则移动得更快)。如果不采取行动来确保食物,动物就无法长时间生存来收集更多信息,或者更诗意地收集不证自明的信息[ 8 ]。
重要的是,行动的动机是对能够实现自己的预测的“乐观”信念。如果烈日下口渴的动物只是“改变主意”并开始预测晒伤和脱水的感觉,那么她就活不了多久了。相反,即使在烈日下,动物也能预测 37° 的恒温,并尽力寻找阴凉处。换句话说,虽然动物有时不得不改变主意,但它被赋予了一些关于它想要的结果的“先验”——例如将体温保持在 37° 的稳态先验——这是特别重要的,需要免受(过度)修改。这些先验与控制论中的“设定点”发挥相同的作用,以实现纠错和(负)反馈控制[ 9 – 11]。
“驱动状态”,例如饥饿和口渴,是优先结果优于首选结果的例子[ 12 ]。在主动推理中,这些和其他类似的命令位于动物控制层次的顶层,允许动物根据其期望的事态不断评估其当前状态;并在检测到偏差时引导行动 [ 13 ]。为此,将自上而下的先前预测(例如,预计体温为 37°)与自下而上的感觉(例如体温过高的内感受)不断进行比较,任何差异都需要适应性解决差异的监管流程,从而实施(负)反馈控制[ 14 ]。
这种观点有三个重要的推论。首先,在主动推理(和控制论)中,触发纠正措施的不是外部刺激,而是内部事件——“先前预测”(或“设定点”)与感觉之间的不匹配。换句话说,这些理论将动物描述为由内部设定的目标、匹配机制和纠错循环驱动的有目的的实体,而不是(仅)通过对环境刺激的反应,如将大脑描述为刺激反应系统的理论。这与良好调节定理和感知控制理论密切相关[ 9,10,15 ]。
其次,相同的不匹配(例如高渗透压)可以涉及多个调节和纠错过程,其范围从体内更简单的自主反应(例如抗利尿激素的释放)到复杂的目标导向计划,通过更长的环境循环来消除错误(例如,租一把沙滩伞或在阳光明媚的海滩上购买冰淇淋),具体取决于生物体的变速复杂性。
第三,同样的纠错方案——针对内部(稳态和驱动)状态起作用——也可以用于控制身体运动和外部变量。这可以通过在运动控制中使用“平衡点”来说明,并且可以通过在所需的运动端点设置固定点吸引器来引导身体动作[16 ]。同一原理的另一个例证是认知理论中“目标”的概念[ 17]。对于像我们这样复杂的动物来说,控制可以跨越认知和社会目标,例如赢得网球比赛或成为俱乐部成员。动物将努力通过与稳态控制类似的纠错方案来实现这些认知目标:通过选择预期减少当前状态与目标状态之间差异的行动方案[5 , 18 ]。
考虑到这三个前提,我们认为简单的纠错回路,或基本的“预测主题”,在大脑结构的进化史上很早就出现了,并且在多个领域(例如内感受控制、运动控制和目标导向)以大致相似的方式发挥作用。行为)。大脑结构的进化是通过在多个领域和行为(例如接近和逃跑、游泳、运动和攀爬)复制相同的方案来进行的,从而形成多个并行的感觉运动回路。此外,它通过使用更复杂的预测和纠错电路逐渐增强基本预测主题,使动物能够将其控制从身体生理学扩展到外部(和社会)环境。
3. 将大脑设计形式化为生成模型中的结构学习
在我们概述大脑设计的进化历史之前,我们使用生成模型的概念提供了一种解释进化轨迹的正式方法。生成模型是根据统计理论构建的,可生成有关观察结果的预测,并广泛应用于数据科学和机器学习中。在这里,我们关注的是生成模型来解释大脑如何工作。主动推理假设生物需要其感觉 (y) 的隐藏原因 ( x ) 的生成模型:见图2,了解这种形式主义的摘要。大脑的模型产生预测(例如关于环境突发事件或身体运动的影响)并引导适应性行动(u)带来所需的感觉(例如到达食物源)。
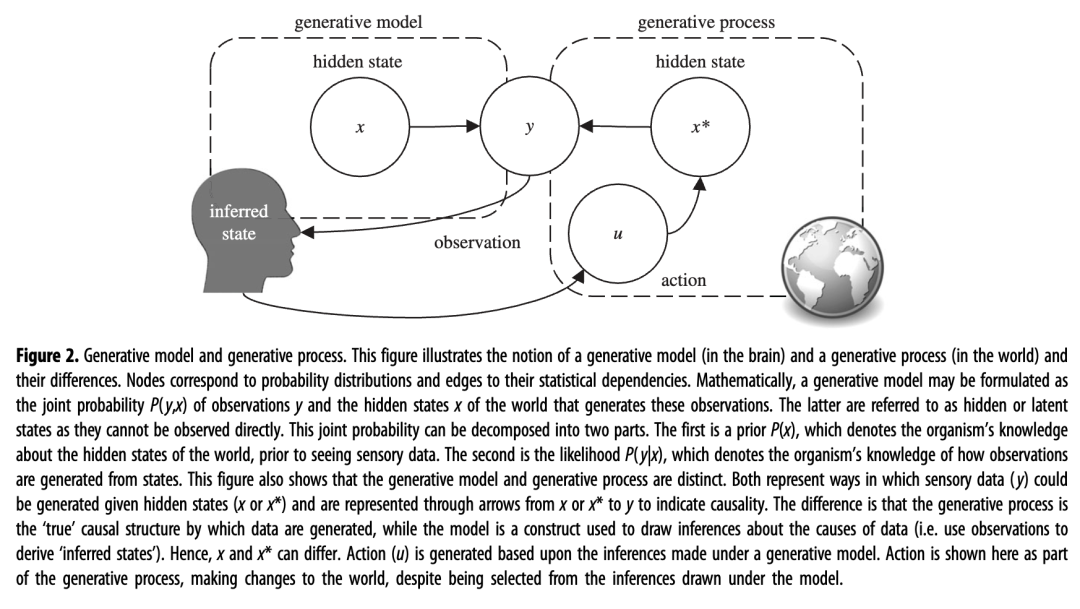
图 2.生成模型和生成过程。该图说明了生成模型(在大脑中)和生成过程(在世界中)的概念及其差异。节点对应于概率分布,边对应于它们的统计依赖性。在数学上,生成模型可以表示为观测值y和生成这些观测值的世界的隐藏状态x的联合概率P ( y , x ) 。后者被称为隐藏或潜在状态,因为它们无法直接观察到。这个联合概率可以分解为两部分。第一个是先验P ( x),它表示有机体在看到感官数据之前对世界隐藏状态的了解。第二个是可能性P ( y | x ),它表示有机体如何从状态生成观察结果的知识。该图还表明生成模型和生成过程是截然不同的。两者都表示在给定隐藏状态( x或x *)的情况下生成感官数据( y )的方式,并通过从x或x * 到y的箭头表示来表明因果关系。不同之处在于,生成过程是生成数据的“真实”因果结构,而模型是用于推断数据原因的构造(即使用观察来导出“推断状态”)。因此,x和x * 可以不同。动作(u)是根据生成模型下的推论生成的。尽管行动是从模型下得出的推论中选择的,但这里显示的行动是生成过程的一部分,对世界做出了改变。
- 下载图
- 在新选项卡中打开
- 下载幻灯片
大脑中的生成模型不需要是外部世界的内部副本。他们的主要目标是控制行动,而不是(或不一定)忠实地代表外部现实[ 19 , 20 ]。生成模型中假设的隐藏原因 ( x ) 不需要与实际产生有机体感觉 ( y ) 的世界“真实”过程(称为生成过程)的隐藏状态 ( x *) 相同;请参见图 2来了解这种差异。换句话说,我们用来解释我们的感觉中枢的模型可能包括外部世界中不存在的隐藏状态,反之亦然。如果动物的生成模型足以引导适应性行为,那么它“雕刻自然”的方式并不重要。
如上所述,有效的生成模型也与环境统计存在系统性差异。最值得注意的是,一些先验p ( x )——例如体温在 37° 左右波动的事实——可以被视为规定性目标根据有机体先前的偏好(“世界应该如何”)来描述有机体的特征,而不是关于环境的陈述。虽然在标准贝叶斯处理中,先验在推理过程中不断更新(遵循“今天的后验是明天的先验”的座右铭),但在主动推理中,一些先验保持不变,因为它们具有非常高的精度(因此非常难以更新) 。通过这种方式,它们可以充当促进体内平衡的设定点。然而,这些先天先验可以在较慢的(例如进化)时间尺度上更新[ 21 ],因此允许生物体“学习它们的偏好”并适应它们的生态位。
此外,生成模型有不同的种类。这意味着不同动物的大脑可能对应于不同(更简单或更复杂)的生成模型,这反过来又能够实现不同(或多或少复杂)的认知能力。然而,生成模型的多样性并不是无限制的,而是必须遵循两种约束。首先,所有生成模型都包含一些预测主题,并且在渐进主义下,最复杂的生成模型继承(并扩展)不太复杂模型的预测主题。这意味着特定动物可以进化的生成模型的空间受到其祖先的生成模型的限制。其次,可以先验地定义哪些问题可以或不能通过使用不同类型的生成模型来解决。这意味着每种特定动物的生成模型都受到其生态位统计数据和身体控制需求的严格限制[ 22 , 23 ]。
因此,可以通过以下方式对大脑设计的进化历史进行“逆向工程”:(i)从我们进化祖先的大脑中假定存在的简单“预测主题”开始;然后(ii)考虑这些主题的哪些扩展(例如更丰富的预测循环)是可能的以及它们解决了哪些新的生物学问题;(iii) 通过考虑解剖学和问题的性质以及动物生态位的自然统计数据,将这些基本或扩展的主题与谱系中特定动物的大脑相匹配。
在下文中,我们提供了一些示例,说明生成建模视角如何通过包含日益复杂的预测循环的生成模型来帮助构建从简单到复杂的大脑设计的进化轨迹。
4. 祖先大脑中简单预测主题的三个例子
我们使用三个预测和纠错循环示例通过生成模型开始本次游览。鉴于其简单性,这些生成模型可能成为“祖先”大脑设计的核心。
5.内感受变量稳态控制的生成模型
图 3所示的生成模型提供了单个内感受变量的稳态(图 3a , “稳态”)和变稳态(图 3c , “allostat”)调节,出于说明目的,我们在此将其称为“体温”;有关完整指定的示例,请参阅[ 20 ]。(可观察)变量y表示温度感受器激活,(隐藏)变量x表示体温。该模型通过结合对x的先验信念和内感受y来推断对x的后验信念。先验信念起到了控制论设定点的作用,以确保体温保持固定在 37°。
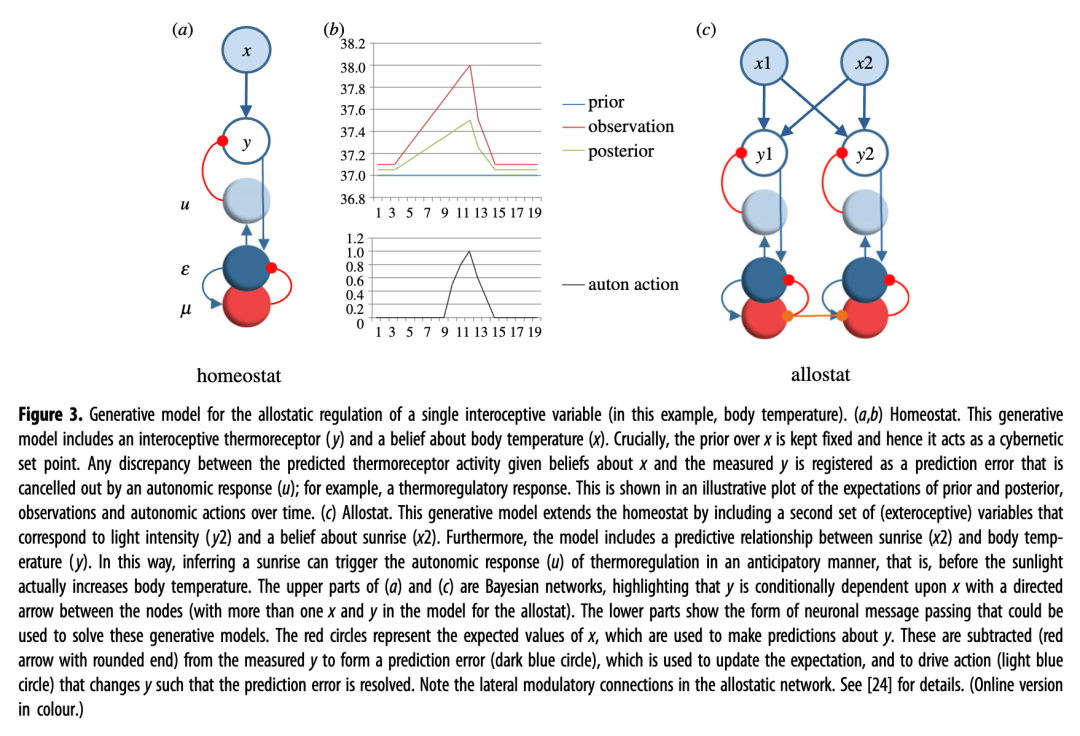
图 3.单个内感受变量(在本例中为体温)的动态调节生成模型。(a,b)稳态。该生成模型包括内感受温度感受器 ( y ) 和关于体温的信念 ( x )。至关重要的是, x 的先验保持固定,因此它充当控制论设定点。给定关于x 的信念的预测温度感受器活动与测量的y之间的任何差异都会被记录为预测误差,该误差会被自主反应 ( u);例如,体温调节反应。这在随时间变化的先验和后验、观察和自主行为的期望的说明图中显示。( c ) 分配器。该生成模型通过包含第二组(外感受)变量来扩展稳态,这些变量对应于光强度 ( y 2 ) 和对日出的信念 ( x 2 )。此外,该模型还包括日出 ( x 2) 和体温 ( y )之间的预测关系。通过这种方式,推断日出可以以预期的方式(即在阳光实际增加体温之前)触发体温调节的自主反应(u )。( a的上部) 和 ( c ) 是贝叶斯网络,强调y有条件地依赖于x ,节点之间有一个有向箭头(分配器模型中存在多个x和y )。下半部分显示了可用于解决这些生成模型的神经元消息传递的形式。红色圆圈代表x的期望值,用于对y进行预测。从测量的y中减去这些值(带有圆形末端的红色箭头)以形成预测误差(深蓝色圆圈),该误差用于更新期望,并驱动改变y的操作(浅蓝色圆圈)从而解决预测误差。注意非稳态网络中的横向调节连接。详细信息请参见[ 24 ]。(在线版本为彩色。)
- 下载图
- 在新选项卡中打开
- 下载幻灯片
与恒温器非常相似,该模型通过报告预测和感测到的温度感受器激活之间的差异来维持所需的温度,给定有关温度的(贝叶斯)信念,触发自主反射(u),从而导致血管舒张,从而解决预测误差。通过考虑图 3b所示的稳态控制(虚构)示例,可以理解该模型的功能。该图绘制了先前和后验观察以及自主行为随时间变化的期望。在此示例中,y最初在可接受的范围内,但不久之后它突然增加(例如,暴露在阳光下),导致预期的x在后验信念下增加。给定后验信念的预测y与测量的y之间的差异被记录为预测误差。鉴于主动推理的目标是最小化预测误差,模型会触发自主动作 ( u ),消除预测误差。请注意,在此示例中,对x的后验信念并不是体温的真实表示(它是由先验信念“按比例缩小”的)。这证明了控制需求比表征准确性更重要的事实。
该模拟说明了一个简单的生成模型(稳态)通过误差校正支持稳态:通过记录预测误差并主动取消它们。这种纠错方案可以被认为是主动推理生成模型的基本“预测主题”,并且与身体器官的生理控制中常见的反馈循环保持连续性。
虽然为了简单起见,我们考虑使用单个稳态来控制聚合变量(体温),但调节问题(例如体温调节)通常意味着多种异质(例如反馈和前馈)和部分独立机制的组合[ 25]。从这个角度来看,对单独(且简单)受控变量的设定点进行编码的多个稳态器可能会产生部分独立的控制回路。此外,稳态器可以与其他(例如前馈)机制协同操作,这些机制隐含地促进生理变量收敛到稳态有效值,而不是明确地表示设定点。最后,更复杂的机制也可能在发挥作用。虽然在稳态调节器中,只有在感知到预期(温度)信号时才会消除误差,但生理控制也可以进行预测(通过下丘脑);例如,动物在摄入食物后甚至在获得糖之前就会感到饱足。这个例子说明了更具前瞻性(或非稳态[ 26])监管和控制的形式,我们接下来讨论。
6. 内感受变量的动态控制生成模型
“稳态调节器”很简单,但也有局限性:它可以对抗感知到的体温变化,但无法预测体温(或其他变量)的可预测变化。在自然界中,有几种规律(例如昼夜或季节交替)可以很容易地结合起来,将上述生成模型扩展为从技术上讲的经验先验。预测我们的身体和内感受变量将如何变化的明显优势是能够施加一些预期(变速[ 26 ])控制。
例如,想象一下,对于生活在炎热地区的动物来说,日出时的苍白光线预示着它的体温将变得过高。如果智能体的生成模型结合了日出和体温之间的这种预测关系,它就可以预测其(自主)状态的变化,并在太阳升起之前启动自主动作(例如血管舒张),从而先发制人地缓解预期的温度升高。
图 3c ( allostat)所示的生成模型包括这种预测关系。与图 3a的生成模型一样, 3c的生成模型包括温度感受器 ( y ) 和相应的温度 ( x )。然而,它还包括一组新颖的变量:感光器 ( y 2) 和太阳光强度 ( x 2)。“allostat”是多模态的,因为它连接了两种感觉模态:外感受流(例如光感受器)和内感受流(例如温度感受器)。多模式“allostat”(图 3 c)可以通过稍微修改单峰“稳态”的设计(图3a )在进化过程中逐渐实现:即,通过包括不同模态之间的水平(预测)关系。
至关重要的是,“分配器”的两组变量在“日出”预计会引起光感受器和温度感受器激活的意义上是耦合的。通过将这种因果结构写入其生成模型(即神经元网络)中,“分配器”以预期方式调节体温。随着动物感光活动的增加,它对光强度的期望也增加。此外,最重要的是,在温度感受器预测错误出现之前,动物预计小动脉张力会降低。通过这样做,它可以防止太阳升起时体温升高,从而避免了体内平衡校正的需要。这与“稳态调节器”的功能形成鲜明对比,“稳态调节器”仅在温度感受器活动增加(参见[ 20 , 27 ],了解吸引分层模型的非稳态控制的替代公式;以及[ 28 ],了解多模态变量和收敛区的讨论)。
虽然我们在内感受调节任务中举例说明了“allostat”,但它可以应用得更广泛。例如,它可用于模拟远端感觉(例如嗅觉和视觉)和接近感觉(例如触觉)之间的预测关系,并允许动物在看到捕食者的阴影时触发逃跑行为。下面我们提供了运动的非稳态控制的生物学说明。
7. 简单行为控制的生成模型
“稳态调节器”和“平衡调节器”允许控制简单形式的游泳、运动、伸手和其他运动[ 29 ]。斑马鱼虚拟现实研究提供了一个生物学例子[ 30 ],该研究确定了动物端脑逃避行为期间纠错的神经元基础:一组进化上保守的大脑回路,参与其他脊椎动物(包括哺乳动物)的动作选择,例如皮质基底神经节回路[ 31 ]。
在这项研究中,动物被放置在白色的起始区域,然后变成蓝色(厌恶)或红色(安全)。如果起始区域变成蓝色,动物必须向前移动才能到达红色区域(GO 试验)。如果起始区变成红色,动物必须留下来(NOGO 试验)。未能到达(或留在)安全区导致触电。
该研究确定了一个编码基于颜色的规则(即“红色是好的”)的神经元集合,以及一个编码预测错误(即预测的视觉感觉之间的差异)的独立神经元集合(在三分之一的鱼中)。游泳时景观的向后移动和实际的视觉输入。有趣的是,具有后一种群体的鱼在回避行为方面更有效。这些鱼可以使用类似于图 3c的分配器的生成模型来解决任务。假定的分配器可以连续生成运动预测和预测误差,并通过触发适当的(游泳或停止)预期反应而不是(仅)使用自主反射来消除预测误差。为了评估行为实际上是由预测误差最小化引导的,一个重要的观察结果是,在控制(开环虚拟现实)试验中,游泳没有产生预测的(向后运动)感知,鱼不断拍打尾巴——似乎是这样,因为预测错误从未消失。
这个例子表明,简单的调节回路,例如斑马鱼的逃逸回路,通常被认为是刺激响应的典型例子,可以通过纠错机制来支持和改进[30 ]。斑马鱼端脑可以产生各种预测(例如关于预期的景观向后移动)并使用相应的预测误差来指导主动回避行为。我们最初在内感受调节的背景下描述的“allostat”架构足以解决[ 30 ]的回避任务(但斑马鱼可能使用具有时间或层次深度的更复杂的生成模型;见下文)。
8. 结构学习的进化代数
我们的中心论点是,进化是在遗传限制[ 32 ]和需要解决的新问题的选择压力下,通过对上述“预测主题”的逐步阐述而进行的,例如对更复杂的身体的控制和更丰富的生态系统的存在。壁龛;例如,大约 400 Ma 时脊椎动物开始在陆地上建立生命。
在连续的几代人中,生成模型可以保持稳定或沿着四个关键维度进行详细阐述,从而强烈限制了“可进化的东西”的空间。我们已经介绍了第一种阐述,从(单模态)稳态到(多模态)Allostat。第二种阐述是预测主题的重复,这扩大了动物的行为能力。第三和第四维度分别为生成模型配备时间和/或层次深度。这两种扩展实现了更丰富的预测主题,赋予了认知复杂性,例如计划或考虑在多个时间尺度上变化的事件的可能性[ 33 ]。
图 4说明了这四个维度,就好像它们是“进化代数”的运算,定义了生成模型的可能前景(请注意,代数还包括“恒等”运算,以解释生成模型可以保持不变的事实)。接下来,我们讨论重复和分层操作及其生物学相关性。
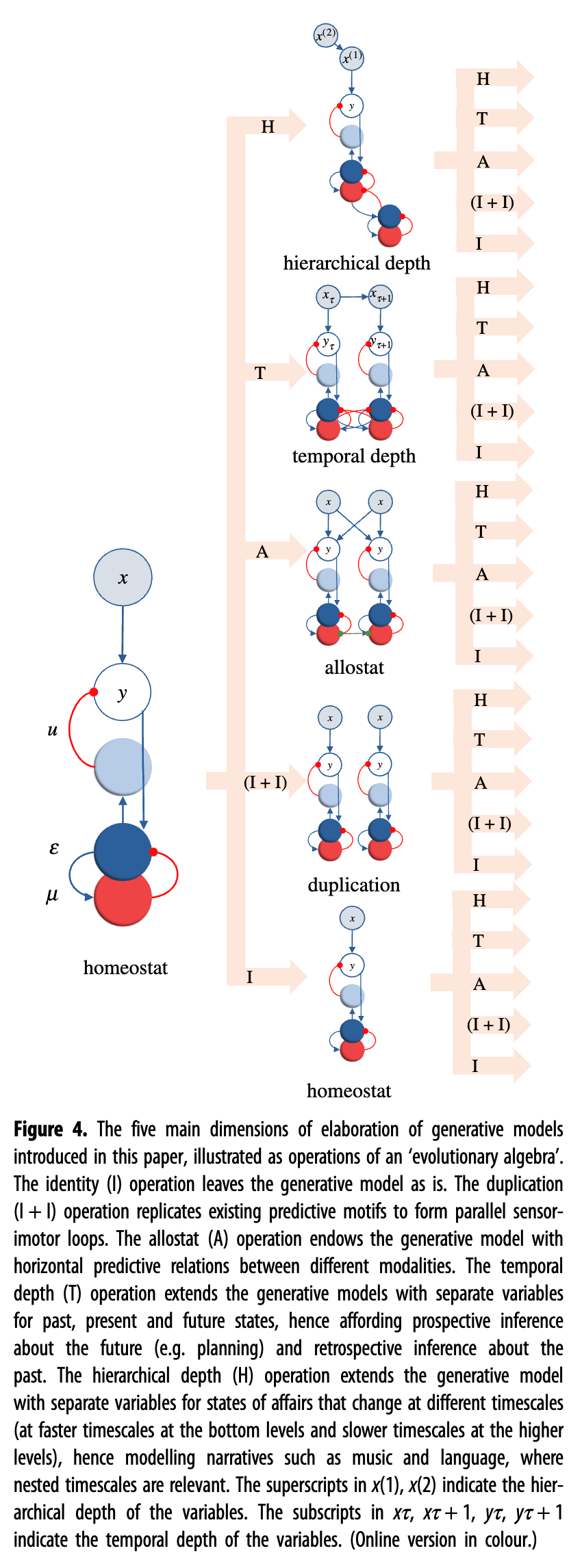
图 4.本文介绍了生成模型阐述的五个主要维度,以“进化代数”的运算来说明。恒等(I)操作使生成模型保持原样。复制 (I + I) 操作复制现有的预测图案以形成并行的感觉运动环路。allostat (A) 操作赋予生成模型不同模态之间的水平预测关系。时间深度(T)操作将生成模型扩展为过去、现在和未来状态的单独变量,从而提供关于未来的前瞻性推断(例如规划)和关于过去的回顾性推断。分层深度 (H) 操作使用针对在不同时间尺度(底层的时间尺度较快,高层的时间尺度较慢)变化的事态的单独变量来扩展生成模型,从而对音乐和语言等叙事进行建模,其中嵌套的时间尺度是相关的。中的上标x (1)、x (2)表示变量的层次深度。xτ、xτ + 1、yτ、yτ + 1中的下标表示变量的时间深度。(在线版本为彩色。)
- 下载图
- 在新选项卡中打开
- 下载幻灯片
9. 重复的预测主题可以实现多种行为
生成模型可以通过复制简单的预测主题来扩展,以形成更大的物种特定行为,例如接近、回避、触须控制[ 34 ]和视觉引导抓取。图 4中的算子 (I + I)说明了一个生成模型,其中相同的预测主题被重复和专门化,以形成由多个并行感觉运动回路组成的“基于行为”的架构。在这里,重复意味着整个生成模型包含多个较小的生成模型(每个行为学上有效的行为一个),这些模型并行运行并使用相同的纠错方案。相反,专业化意味着较小的生成模型使用不同的内部变量,并且对不同类型的行为相关可供性和感官信息敏感(例如,手臂可到达的用于抓握的空间或更远的用于运动的空间)。
复制可能是在进化过程中通过感觉运动回路的分化和分割而实现的,这些回路逐渐获得不同的(特定于行为的)功能角色。例如,用于视觉引导行为的单个电路可以区分为两个电路,每个电路专门用于不同类型的视觉引导行为,例如逃跑与觅食(参见[35 ]]详细讨论了用于空间定向的视网膜顶盖回路和用于觅食的视网膜端脑回路之间的区别)。在皮质水平上,这可能意味着不同(特定行为)皮质区域和动作图的形成,它们的普遍程度可能或多或少,取决于它们的相对重要性(例如,视觉回路对于昼行动物可能比夜间动物更普遍) [ 36 ]。
早期的大脑设计可能包括具有多个复制的感觉运动回路的生成模型。为了与这个想法保持一致,Cisek [ 35 ] 认为早期脊椎动物的体系结构可能由一组用于不同类型行为的顶盖回路组成,每个回路都实现为与世界的闭合反馈控制回路。这种组织在高级大脑的组织中仍然可见,其中各种复杂性的感觉运动环路由平行的基底神经节-丘脑皮层环路[ 37 ](以及小脑环路)精心编排。此外,在先进的大脑中,背内侧新皮质是围绕格拉齐亚诺所说的行为学行动图组织的:额顶叶回路致力于不同类别的物种特定行为[ 38 ]。
值得注意的是,由多个感觉运动环路组成的架构需要额外的机制来进行选择和优先级排序。在大脑中,行为选择(或更广泛地说,决策)似乎以分布式方式解决,不同的大脑区域负责决策的最一般到最详细的方面[35 ]。下丘脑可以调节一般大脑状态(例如清醒或睡眠)、生理周期和基本的动态平衡。不同类别的行为之间的仲裁,例如接近或回避,可能意味着基底神经节的循环[ 39]。特定行为之间的仲裁(例如不同的方法或抓取位置)可以作为皮质系统内的“可供性竞争”来解决,至少在高级动物中是如此[40 ]。最后,腹内侧脑区域可能支持不同层次级别的优先顺序,具体取决于它们当前的动机价值(参见下面的§11,了解我们对层次模型的讨论)[ 41 , 42 ]。尽管它们具有多样性,但这些选择和优先级电路可能都使用类似的动态竞争原理(例如,有偏见的竞争[ 43 ])——因此形成了像大脑这样的多用途架构的另一个“基序”。
从结构学习的角度来看,复制是构建生成模型的有效方法——从某种意义上说,动态在不同的感觉运动领域是保守的。从数学上讲,这种守恒类似于对生成模型中的概率分布进行因式分解,这已经在模块化架构[44]中进行了讨论,并且功能隔离作为功能性大脑架构的原则[ 45-47 ]。在贝叶斯统计和物理学中,这种因式分解无处不在,被称为平均场近似[ 48 ]。事实上,模型证据上的自由能界限是根据平均场近似来定义的,它为(感觉)数据提供了准确且最简单的解释[49 ]。
10.赋予生成模型时间深度支持前瞻性和回顾性推理
到目前为止讨论的生成模型仅考虑当前状态和观察结果。然而,它们可以扩展到时间深度模型,其变量明确表示未来(和过去)的状态和观察结果。
图 4中的算子 T说明了具有时间深度的(离散时间)生成模型。时间深度模型支持前瞻性和回顾性推理。例如,它们允许预测行动(或行动序列,即政策)的短期或长期后果,从而选择预期提供首选结果的行动过程,而不是仅仅利用现有的可供性[14 ]。此外,它们允许提前计划、想象新的情况和反事实推理,或者根据新的证据回顾性地重新评估一个人对过去的信念。
各种研究人员推测,深度时间模型发展的主要驱动力是觅食。与视觉定向和地标识别相比,觅食的认知和空间需求的增加可能有利于(视网膜-端脑)觅食回路的发展,该回路与基于可见地标的空间定向(视网膜-顶盖)回路不同。35 ]。有趣的是,支持空间导航和觅食的海马回路也参与了展望和想象[ 50 ]。这使得 Buzsáki 和 Moser 提出,前瞻性功能利用了海马-内嗅系统中的认知和预测图,因此记忆和规划机制是从物理世界的导航机制演变而来的[ 51 ]。
时间深度模型从更简单的模型的演化可以在演化过程中通过将最初未分化的模型(即不区分现在与过去和未来的模型)逐步分割为具有过去的单独潜在状态的模型来实现,现在和未来。这种因式分解或分割的关键驱动力可能是对动物在行动时创造和经历的感觉运动序列的观察和渐进内化——换句话说,是对自己的连续行为模式的自我建模[ 14 , 52 ];参见[ 53] 为计算示例。反过来,一旦这些感觉运动序列被内化形成深层时间模型,它们就可以内源性再生,以支持记忆和展望。浅层模型向深层时间模型的逐步发展可能已经发生过多次,跨越不同的大脑结构,例如海马体、额叶皮层等,从而使先进的大脑能够在各个认知领域生成未来的预测。
11. 赋予生成模型层次深度,提供多尺度推理
到目前为止,我们已经描述了可以处理在单一时间尺度上展开的世界各个方面的生成模型。然而,它们可以扩展到层次深度模型,其不同层次级别的变量编码在不同时间尺度上展开的潜在状态。一个例子是一首歌:即使我们听到(或唱)的音符快速变化,旋律仍然保持不变。同样,电影或叙述在几分钟内保持不变,场景在几秒钟内保持不变,但视觉刺激可能会在数百毫秒内发生变化。
图 4中的算子 H说明了获取层次深度的生成模型。这些模型允许对在不同时间尺度上变化的叙事、歌曲、电影和其他事件进行建模,通过在较高层次级别上编码变化较慢的变量(例如旋律或电影)和变化较快的变量(例如音符或视觉场景)在较低的层级。层次组织的两个神经生物学例子是哺乳动物的视觉区域和鸟鸣中控制声音手势的区域[ 54 , 55 ]。
感觉运动回路的相同复制——跨多个领域(如上所述)——也有可能在进化过程中产生了它们的“层次化”。换句话说,感觉运动电路的不同部分可能已经变得专门处理动作控制的不同时间尺度:从更简单的运动原语到复杂的行为,最后到决定行为时间顺序的有意义的序列[56 ]。在动态觅食的进化压力下,这种行为(和大脑结构)的分层组织似乎存在于果蝇等简单动物中[ 57 ],或许也存在于无脊椎动物中[ 58 , 59 ]。
在更高级的动物中,行动的层次控制可能已经扩展到复杂的“认知控制”和“执行功能”形式,这有助于优先考虑远端目标,同时抑制直接的可供性。可以推测,认知控制能力(与前额皮质的发育相关[ 60 ])可能是从动物用来实现外部(和社会)环境目标的控制政策的内化进化而来的。反过来,这有助于将控制从外向内转变:从对外部环境状态的控制转向对自身行为的自我调节——这是执行功能的标志[17 , 61 ]。
12. 生成模型进化的系统发育树
在上文中,我们根据生成模型形式化了大脑设计,其中包括各种复杂性的预测循环;然后讨论了生成模型设计的五种主要方式,或者说进化结构学习“代数”的五种主要运算(图 4)。
这意味着人们可以根据生成模型上有限数量的突变操作来描述大脑设计的进化轨迹。图5说明了一个示例(部分)“系统发育树”,其中突变操作的应用产生了各种生成模型,并用不同颜色的圆圈标记。虽然并非所有可能的生成模型扩展都在进化过程中实现,但其中一些可能对应于不同动物的实际大脑设计。通过规定哪些生成模型是可进化的、它们可能出现在系统发育树的哪个分支以及它们支持哪些适应性问题,这种分析可能有助于将预测处理的神经科学治疗与跨物种大脑结构的进化和比较数据结合起来。
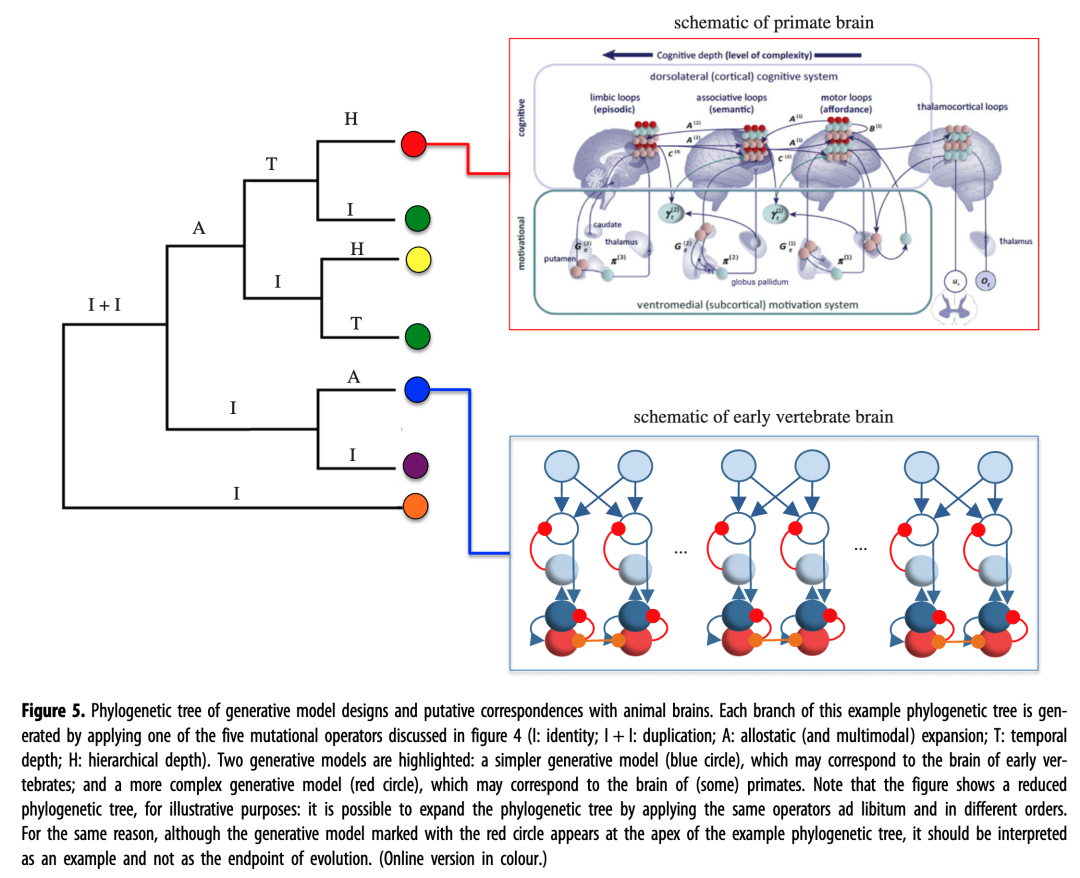
图 5.生成模型设计的系统发育树以及与动物大脑的假定对应关系。此示例系统发生树的每个分支都是通过应用图 4中讨论的五个突变运算符之一生成的(I:同一性;I + I:重复;A:非稳态(和多模式)扩展;T:时间深度;H:层次深度)。突出显示了两个生成模型:一个更简单的生成模型(蓝色圆圈),可能对应于早期脊椎动物的大脑;以及更复杂的生成模型(红圈),它可能对应于(某些)灵长类动物的大脑。请注意,出于说明目的,该图显示了简化的系统发育树:可以通过随意应用相同的运算符并以不同的顺序来扩展系统发育树。出于同样的原因,虽然用红圈标记的生成模型出现在示例系统发育树的顶点,但它应该被解释为一个示例,而不是进化的终点。(在线版本为彩色。)
- 下载图
- 在新选项卡中打开
- 下载幻灯片
有趣的是,变异算子是可交换的:通过以不同的顺序执行相同的操作可以获得相同的生成模型设计。例如,图 5中用绿色圆圈标记的两个生成模型都是 I + I、A、I 和 T 运算符(尽管顺序不同)应用的结果,因此是等效的 - 请注意,这同样适用分子水平上的替代突变。突变算子的交换性质可能揭示趋同进化,以及不相关的生物体在需要适应相似的生态位时独立进化相似特征(并通过不同的进化历史)的过程。
出于说明目的,我们强调了系统发育树中的两个生成模型。前一种生成模型(图5中的蓝色圆圈)可能对应于早期脊椎动物的大脑,正如上面关于斑马鱼所讨论的那样;它是由重复、恒等和分配算子产生的。该生成模型包括针对不同行为(例如接近和回避)的多个并行的变稳态基序和仲裁机制(例如皮下层,被认为是哺乳动物基底神经节的斑马鱼类比[62]),为简单起见,图中未显示。
后者的生成模型(红色圆圈)可能对应于(某些)灵长类动物的大脑,并且它将由复制、变速、时间和分层深度算子产生。该生成模型包括多个针对不同行为的并行感觉运动环路,每个环路都具有时间和层次深度。在此示意图中,有两组平行的分层电路,即背外侧控制分层结构和腹内侧激励分层结构。在背侧层次结构中,较低级别的电路实现简单的控制循环,可以直接由环境可供性(例如食物提供接近)触发,而较高级别的电路可以根据远端目标将较低级别的电路置于上下文中,或者合作支持它们或覆盖低级可供性(例如 对掠食者存在的情境记忆会提升逃跑目标)。层次之间的竞争是通过腹内侧动机层次结构来解决的,该层次结构优先考虑编码在背外侧控制层次结构中的更高层次的目标或较低层次的可供性,这取决于预计哪一个更有效;看 [41、42 ]了解详情。
与更简单的(蓝色)生成模型相比,这种先进的(红色)生成模型具有更复杂的方法来执行生物调节。例如,虽然更简单的生成模型只能通过快速逃脱来避免捕食者,但更复杂的生成模型可以设计前瞻性策略,例如构建防捕食者的经济体。然而,值得注意的是,即使在最复杂的生物体中,对于相同的生物问题,进化上新颖的解决方案也不会(完全)取代进化上较旧的解决方案。相反,旧的解决方案在很大程度上仍然可用,并且可以在适当的条件下进行选择,从而使操作选择与上下文相关[ 5 , 63]。例如,恐惧回路似乎是分层组织的,包括更简单的(反应性)和更复杂的(认知)层,可以根据外部条件(例如与捕食者的距离)以及内部条件(例如觉醒状态)来选择这些层。64 ]。
13. 讨论
在本文中,我们建议大脑结构或设计可以形式化为生成模型;我们进化祖先的大脑生成模型包括简单的“预测主题”;进化是通过对这些预测主题的连续阐述而进行的,形成我们在高级动物中观察到的更复杂的结构。我们强调了四个主要维度,沿着这些维度可以将简单的预测主题推进为复杂的预测主题,并使用这种形式分析来提出生成模型的“系统发育树”和相应的大脑设计。虽然这里提出的预测处理设计的进化轨迹肯定是暂时的和不完整的,
错误纠正机制可以涵盖更简单(稳态和失常)和更复杂(认知)形式的适应性行为的观点与心理学和神经科学的普遍观点有很大不同,心理学和神经科学倾向于诉诸不同的感觉运动处理和简单认知机制。(反应性控制器)和更高认知(预测性控制器)。继承自行为主义的一个广泛的观点是,大脑中适应性行为的构建模块是通过奖励慢慢强化的刺激-反应映射(或策略),其最小的形式可能对应于感觉和运动神经元之间的联系,在进化过程的早期就出现了 [ 65]。大脑可以通过允许更高的(控制)路径选择性地激活上述刺激-反应规则来利用认知的复杂性和深度——这些路径在进化过程中发展得更晚,并且可以服务于预测调节[66 ]。另一种有影响力的(对偶理论)观点假设大脑使用两种完全独立的决策机制,一种是直觉的,一种是深思熟虑的[ 67 ](有时等同于不同的、无模型和基于模型的强化学习控制器[ 68] ])。在这些和其他相关观点中(例如“三位一体大脑”的想法[ 69]),高级认知机制(包括预测循环)是晚期进化发明。然而,“二元理论”和相关观点中隐含的隔离是否能够与进化过程的渐进性和连续性相协调[ 32 , 35 ]——以及在机制之上的进化过程中如何出现更高认知的机制是值得怀疑的。对于感觉运动处理,如果两者应该完全不同。
这里追求的另一种假设是,早期的大脑设计已经使用了纠错机制,正如控制论理论所设想的那样,例如测试-操作-测试-退出(TOTE)模型[ 70 ]和主动推理。这一假设的好处之一是它不需要任何进化跳跃来解释复杂的认知行为。值得注意的是,大脑中的闭环控制可能不是最近的进化发明:它可能起源于更简单的代谢控制形式和细胞膜内营养物质的合成,然后扩展到细胞膜外以实现我们所说的“行为” [ 9 , 71 – 73 ]——从而实现生命和认知的连续性。
我们已经考虑了生成模型如何扩展,但我们没有解决“为什么”。尽管不是我们这里的重点,但选择压力产生新神经元结构的过程本身可以表示为意外或自由能最小化过程 [ 74 , 75 ]。这是因为费舍尔的基本定理可以被解读为基于边际可能性或模型证据的贝叶斯信念更新[ 76 ]。具体来说,我们可以将自然选择视为执行贝叶斯模型选择的自然方式——有时称为结构学习[ 77 ](即学习适合这种经济的生成模型)——其中模型证据只是适应性适应性。
这种观点(仍然是推测性的,并非没有受到挑战[ 78])表明生态位的复杂性决定了大脑需要具有的复杂性水平,以便达到(贝叶斯)最优。从统计学上来说,最大化模型证据相当于最大化准确性和复杂性之间的差异。因此,模型复杂性相对于进化的任何增加都(仅)通过模型准确性的更大增加获得许可(其中模型证据对应于准确性减去复杂性)。换句话说,大脑只有在满足足够的生态需求的情况下才会增加其复杂性,例如动物必须控制复杂的身体或以必要的准确度处理复杂的情况。这是因为,如果你生活在一个简单的环境中,拥有更复杂的大脑并没有帮助。这就是为什么进化不一定是通往日益复杂的大脑的线性道路,除非这些大脑让利基市场变得更加复杂。然而,随着利基变得更加复杂——由于越来越复杂的细节及其利基结构的填充——适合准确预测这些利基的生成模型的复杂性必然增加。例如,“社会大脑”假说指出,预测和处理复杂的社会动态的必要性是我们物种大大脑和复杂认知能力进化的主要驱动力。79 ]。简而言之,表现为复杂性逐渐增加的渐进主义依赖于经济模型中隐含的循环因果关系,而经济模型本身是由日益复杂的表型构成和构建的[ 80-83 ]。
准确性和复杂性的平衡可能不仅在物种之间起作用,而且在同一大脑内的不同机制之间也起作用。上面,我们讨论了两个例子——体温调节和恐惧回路——其中多种异质机制(例如前馈和反馈;更简单的稳态和具有时间深度的更复杂模型),似乎在进化过程中的不同时刻达到成熟,共存和协同解决控制问题。这些机制可能专门处理生物体经济的不同方面,遵循以下原则:(仅)需要处理更具挑战性的问题时才允许招募更复杂的机制,这将使更简单的机制变得不准确。这种(有限理性)观点有助于解释在何种意义上将认知复杂性与任务需求相匹配是最佳的。值得注意的是,这种观点还协调了本文提供的“预测处理”视图中最优控制和强化学习中流行的简单(例如刺激响应)控制器。例如,一项模拟研究表明,反应性控制器和预测性控制器都可以在总体生成建模视角中表达;并且主动推理优先考虑更简单的反应控制器而不是更复杂的预测控制器,在特定情况下使前者足够准确(例如,当上下文不确定性已减少时)[ 刺激-响应)控制器在本文提供的“预测处理”视图中的最优控制和强化学习中很流行。例如,一项模拟研究表明,反应性控制器和预测性控制器都可以在总体生成建模视角中表达;并且主动推理优先考虑更简单的反应控制器而不是更复杂的预测控制器,在特定情况下使前者足够准确(例如,当上下文不确定性已减少时)[ 刺激-响应)控制器在本文提供的“预测处理”视图中的最优控制和强化学习中很流行。例如,一项模拟研究表明,反应性控制器和预测性控制器都可以在总体生成建模视角中表达;并且主动推理优先考虑更简单的反应控制器而不是更复杂的预测控制器,在特定情况下使前者足够准确(例如,当上下文不确定性已减少时)[ 模拟研究表明,反应性控制器和预测性控制器都可以在总体生成建模的角度内表达;并且主动推理优先考虑更简单的反应控制器而不是更复杂的预测控制器,在特定情况下使前者足够准确(例如,当上下文不确定性已减少时)[ 模拟研究表明,反应性控制器和预测性控制器都可以在总体生成建模的角度内表达;并且主动推理优先考虑更简单的反应控制器而不是更复杂的预测控制器,在特定情况下使前者足够准确(例如,当上下文不确定性已减少时)[84 ]。
一个可能提出的反对意见是,在多细胞系统中存在一种更简单的控制形式,它不是(显然)具有预测性的。这是 2 神经元反射,包括感觉神经元和运动神经元 [ 65]。当前者感测到的量偏离某个目标值(即设定点)时,感觉神经元相对于其静息活动增加或减少其放电率。这会促使运动神经元的活动增加或减少,直到感测到的量返回到其目标值。从表面上看,这个例子似乎是一个纯粹的前馈机制(感觉到运动),没有预测循环。然而,对此的另一种解释是,系统的模型提供了与上下文无关的预测,即感测量处于其设定点。从感知量到感觉神经元到运动神经元再到感知量的环路可以被视为反馈环路。这意味着 2 神经元反射实际上是最简单的预测控制形式。为什么这是一个有用的观点?第一的,它回答了上述反对意见。其次,更有趣的是,它提供了与更复杂模型的连续点。在两者之间包含一个中间神经元,并允许其他神经系统调节该 3 神经元通路,为我们提供了本文中所示模型中所示的上下文相关预测。从进化的角度来看,这种连续性至关重要,我们需要考虑增量步骤,其中一种预测机制可能建立在另一种预测机制之上。为我们提供了本文所示模型中所示的上下文相关预测。从进化的角度来看,这种连续性至关重要,我们需要考虑增量步骤,其中一种预测机制可能建立在另一种预测机制之上。为我们提供了本文所示模型中所示的上下文相关预测。从进化的角度来看,这种连续性至关重要,我们需要考虑增量步骤,其中一种预测机制可能建立在另一种预测机制之上。
最后,重要的是要承认大脑设计、身体、生态和文化生态位是独立进化的。鉴于我们对大脑设计的进化感兴趣,我们假设了一种以大脑为中心的视角,并方便地关注动物大脑中的生成模型。然而,认知并不需要被限制在“头骨内”,而是可以扩展到头骨之外,以涵盖(例如)工具和社会维度[ 85 ]。此外,身体设计(而不仅仅是大脑设计)在解决控制问题中发挥着重要作用[ 86]。承认认知可以“扩展”和“具体化”,这表明并非控制的所有方面都需要通过中心生成模型来解决(或在其中表示)。例如,主动推理强调某些方面(大致对应于最优控制中逆模型的概念)可以通过脊髓中的反射弧直接实现[ 87 ]。控制的其他方面可能会被转移到适当设计的利基(例如协调多个驾驶员的周转)或利用身体设计的便利特征(例如手的理解力)来减轻大脑生成模型的负担。这些和其他例子(参见[ 88-90])表明,考虑认知的扩展和具体方面提供了适应性行为的更广泛视野,其中生成建模能力可能分布在大脑、身体和环境生态位中。反过来,在大脑、身体和环境中应用生成建模视角可以帮助理解它们在进化过程中的协同相互作用。
数据可访问性
这篇文章没有额外的数据。
作者的贡献
GP、TP 和 KF 构思了该研究并撰写了本文。
利益争夺
我们声明我们没有竞争利益。
资金
这项研究获得了欧盟地平线 2020 研究和创新框架计划的资助,具体资助协议编号为 785907 和 945539(人脑项目 SGA2 和 SGA3),GP 和欧洲研究理事会根据资助协议编号为 785907 和 945539(人脑项目 SGA2 和 SGA3)。820213 (ThinkAhead) 至 GP 这项工作是在 Wellcome 人类神经影像中心的资助下进行的(参考号:205103/Z/16/Z)。
脚注
主题为“从进化论的角度看系统神经科学”的 16 篇文章之一。
“进化论视角下的系统神经科学”由 Paul Cisek 和 Benjamin Y. Hayden 编译和编辑
本期主题论文从进化的角度解决了神经科学中的不同重大问题。他们的共同点是对进化的主要原理(自然选择和遗传限制)的关注,以及他们的见解如何帮助解决神经科学中的许多突出问题。
本期可以购买印刷版。请访问我们的读者信息页面了解购买选项。
介绍
介绍
神经科学需要进化
- 保罗·西塞克
和
- 本杰明·Y·海登
发布日期:2021 年 12 月 27 日文章编号:20200518
https://doi.org/10.1098/rstb.2020.0518
通过约束闭合搭建分层控制架构:洞察大脑进化和发展
- 斯图尔特·P·威尔逊
和
- 托尼·普雷斯科特
发布日期:2021 年 12 月 27 日文章编号:20200519
https://doi.org/10.1098/rstb.2020.0519
从脊索动物到灵长类动物行为控制的进化
- 保罗·西塞克
发布日期:2021 年 12 月 27 日文章编号:20200522
https://doi.org/10.1098/rstb.2020.0522
预测编码和主动推理的大脑结构的演变
- 乔瓦尼·佩祖洛
,
- 托马斯·帕尔
和
- 卡尔·弗里斯顿
发布日期:2021 年 12 月 27 日文章编号:20200531
https://doi.org/10.1098/rstb.2020.0531
脊索动物大脑组织和功能的进化视角:来自文昌鱼的见解和感知问题
- 瑟斯顿·拉卡利
发布日期:2021 年 12 月 27 日文章编号:20200520
https://doi.org/10.1098/rstb.2020.0520
从进化的角度看脊椎动物运动行为的神经基础
- Shreyas M. Suryanarayana
,
- 布丽塔·罗伯逊
和
- 斯坦·格里纳
发布日期:2021 年 12 月 27 日文章编号:20200521
https://doi.org/10.1098/rstb.2020.0521
自学是大脑的一个重要设计特征
- 大卫·A·利奥波德
和
- 布鲁诺·B·阿弗贝克
发布日期:2021 年 12 月 27 日文章编号:20200530
https://doi.org/10.1098/rstb.2020.0530
- 空气呼吸的进化如何塑造海马功能
- 露西娅·F·雅各布斯
发布日期:2021 年 12 月 27 日文章编号:20200532
https://doi.org/10.1098/rstb.2020.0532
- 抽象的
- 水陆过渡的神经生态学和脊椎动物大脑的进化
- 马尔科姆·A·麦基弗
和
- 芭芭拉·芬利
发布日期:2021 年 12 月 27 日文章编号:20200523
https://doi.org/10.1098/rstb.2020.0523
- 抽象的
- 定量灵敏度的演变
- 玛格丽特·A·布莱尔
,
- 莎拉·E·库普曼
,
- 杰西卡·坎特伦
,
- 史蒂文·T·皮安塔多西
,
- 埃文·L·麦克莱恩
,
- 约瑟夫·M·贝克
,
- 迈克尔·J·贝兰
,
- …查看所有作者
发布日期:2021 年 12 月 27 日文章编号:20200529
https://doi.org/10.1098/rstb.2020.0529
- 抽象的
- 灵长类动物摆脱夜间瓶颈以及视觉处理背侧和腹侧流的进化
- 乔恩·H·卡斯
,
- 齐惠新
和
- 伊沃娜·斯特普涅夫斯卡
发布日期:2021 年 12 月 27 日文章编号:20210293
https://doi.org/10.1098/rstb.2021.0293
- 抽象的
意见篇
整个前额皮质是前运动皮质
- 贾斯汀·M·法恩
和
- 本杰明·Y·海登
发布日期:2021 年 12 月 27 日文章编号:20200524
https://doi.org/10.1098/rstb.2020.0524
- 抽象的
评论文章
专家在行动:为什么我们需要具身社会大脑假说
- 路易丝·巴雷特
,
- S·彼得·亨齐
和
- 罗伯特·巴顿
发布日期:2021 年 12 月 27 日文章编号:20200533
https://doi.org/10.1098/rstb.2020.0533
- 抽象的
评论文章
计算有效性:使用计算来翻译跨物种的行为
- A·大卫·雷迪什
,
- 亚当·凯佩克斯
,
- 丽莎·M·安德森
,
- 奥利维亚·卡尔文
,
- 尼古拉·M·格里森
,
- 安·F·海诺斯
,
- 莎拉·R·海尔布隆纳
,
- 亚历山大·赫尔曼
,
- …查看所有作者
发布日期:2021 年 12 月 27 日文章编号:20200525
https://doi.org/10.1098/rstb.2020.0525
- 抽象的
评论文章
重新聚焦神经科学:从心理类别转向复杂行为
- 路易斯·佩索阿
,
- 洛雷塔·梅迪纳
和
- 酯·德斯菲利斯
发布日期:2021 年 12 月 27 日文章编号:20200534
https://doi.org/10.1098/rstb.2020.0534
- 抽象的
- 一旦有生命,就有危险:生存行为的深层历史和意识的浅层历史
- 约瑟夫·E·勒杜
发布日期:2021 年 12 月 27 日文章编号:20210292
https://doi.org/10.1098/rstb.2021.0292
Theme issue‘Systems neuroscience through the lens of evolutionary theory’compiled and edited by Paul Cisek and Benjamin Y. Hayden
The papers in this theme issue tackle different major questions in neuroscience from the perspective of evolution. What unites them is a focus on the major principles of evolution – natural selection and the constraints of descent – and how their insights can help resolve many outstanding problems in neuroscience.
This issue is available to buy in print. Visit our information for readers page for purchasing options.
INTRODUCTION
Introduction
Neuroscience needs evolution
- Paul Cisek
- and
- Benjamin Y. Hayden
Published:27 December 2021Article ID:20200518
https://doi.org/10.1098/rstb.2020.0518
ARTICLES
Research articles
Scaffolding layered control architectures through constraint closure: insights into brain evolution and development
- Stuart P. Wilson
- and
- Tony J. Prescott
Published:27 December 2021Article ID:20200519
https://doi.org/10.1098/rstb.2020.0519
Review articles
Evolution of behavioural control from chordates to primates
- Paul Cisek
Published:27 December 2021Article ID:20200522
https://doi.org/10.1098/rstb.2020.0522
Opinion piece
The evolution of brain architectures for predictive coding and active inference
- Giovanni Pezzulo
- ,
- Thomas Parr
- and
- Karl Friston
Published:27 December 2021Article ID:20200531
https://doi.org/10.1098/rstb.2020.0531
Opinion piece
An evolutionary perspective on chordate brain organization and function: insights from amphioxus, and the problem of sentience
- Thurston Lacalli
Published:27 December 2021Article ID:20200520
https://doi.org/10.1098/rstb.2020.0520
- Abstract
- Full text
- References
Preview Abstract
Review articles
The neural bases of vertebrate motor behaviour through the lens of evolution
- Shreyas M. Suryanarayana
- ,
- Brita Robertson
- and
- Sten Grillner
Published:27 December 2021Article ID:20200521
https://doi.org/10.1098/rstb.2020.0521
Review articles
Self-tuition as an essential design feature of the brain
- David A. Leopold
- and
- Bruno B. Averbeck
Published:27 December 2021Article ID:20200530
https://doi.org/10.1098/rstb.2020.0530
Review articles
How the evolution of air breathing shaped hippocampal function
- Lucia F. Jacobs
Published:27 December 2021Article ID:20200532
https://doi.org/10.1098/rstb.2020.0532
Review articles
The neuroecology of the water-to-land transition and the evolution of the vertebrate brain
- Malcolm A. MacIver
- and
- Barbara L. Finlay
Published:27 December 2021Article ID:20200523
https://doi.org/10.1098/rstb.2020.0523
Research articles
The evolution of quantitative sensitivity
- Margaret A. H. Bryer
- ,
- ,
- … See all authors
Published:27 December 2021Article ID:20200529
https://doi.org/10.1098/rstb.2020.0529
Review articles
Escaping the nocturnal bottleneck, and the evolution of the dorsal and ventral streams of visual processing in primates
- Jon H. Kaas
- ,
- Hui-Xin Qi
- and
- Iwona Stepniewska
Published:27 December 2021Article ID:20210293
https://doi.org/10.1098/rstb.2021.0293
Opinion piece
The whole prefrontal cortex is premotor cortex
- Justin M. Fine
- and
- Benjamin Y. Hayden
Published:27 December 2021Article ID:20200524
https://doi.org/10.1098/rstb.2020.0524
Review articles
Experts in action: why we need an embodied social brain hypothesis
- Louise Barrett
- ,
- S. Peter Henzi
- and
- Robert A. Barton
Published:27 December 2021Article ID:20200533
https://doi.org/10.1098/rstb.2020.0533
Review articles
Computational validity: using computation to translate behaviours across species
- ,
- … See all authors
Published:27 December 2021Article ID:20200525
https://doi.org/10.1098/rstb.2020.0525
Review articles
Refocusing neuroscience: moving away from mental categories and towards complex behaviours
- Luiz Pessoa
- ,
- Loreta Medina
- and
- Ester Desfilis
Published:27 December 2021Article ID:20200534
https://doi.org/10.1098/rstb.2020.0534
Opinion piece
As soon as there was life, there was danger: the deep history of survival behaviours and the shallower history of consciousness
- Joseph E. LeDoux
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-24 10:40,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号