A RateupDB(TM)Experience of Building a CPU/GPU Hybrid Database Product(翻译)

A RateupDB(TM)Experience of Building a CPU/GPU Hybrid Database Product(翻译)

jhonye
修改于 2023-09-28 11:44:17
修改于 2023-09-28 11:44:17
原文标题:The Art of Balance: A RateupDB(TM) Experience of Building a CPU/GPU Hybrid Database Product
作者:中科院 Rubao Lee、Minghong Zhou
公司:成都量子象云计算科技有限公司
产品:RateupDB
摘要
GPU加速的数据库系统已经研究了10多年,从原型开发到在多个数据应用领域提供服务的行业产品。现有的GPU数据库研究解决方案通常专注于并行算法和系统实现的特定特性,而行业产品开发通常集中于通过考虑整体性能和成本来交付整个系统。为了填补学术研究和行业开发之间的差距,我们在一个完整的CPU/GPU HTAP系统上进行了全面的行业产品研究,称为RateupDB。我们坚信"平衡的艺术"解决了RateupDB开发中的主要问题。具体而言,我们考虑在软件开发周期中平衡多个因素,如OLAP和OLTP之间的权衡、系统性能和开发生产力之间的权衡,以及产品中算法的平衡选择。我们还展示了RateupDB在TPC-H测试性能方面的完整表现,以展示它相对于其他现有GPU DBMS产品的显著优势。
前言
在过去的十年中,GPU加速的数据库系统从概念验证阶段(例如[22])迅速发展,开始进行预演和原型设计(例如GDB [48]、GPUDB [115]、Ocelot [53]),以及学术界的许多个别项目(例如[18, 28, 44, 61, 78, 90, 95, 98, 99, 101, 105, 113]),发展到为各种关键应用的大规模部署在数据库行业中推出产品的阶段。已经建立了几个商业GPU DBMS,其中一些是通过GPU定制设计实现的,例如Kinetica [6]、OmniSci [9](以前称为MapD [84])、SQream [10],或者通过扩展现有数据库系统实现的,例如基于PostgreSQL的Brytlyt [2]和HeteroDB [4]。GPU数据库的设计空间很大,可以进行许多优化来提供多种可能性来改善性能。然而,许多研究项目中的系统改进并不一定是为了整体性能,而是为了孤立的情况。基于我们在高性能GPU数据库产品RateupDB的开发经验,我们证明了实现整体系统平衡是关键问题,通过权衡多个重要的性能因素来实现。只有这样,我们才能为GPU数据库实现高性能、可扩展性和可持续性。
GPU数据库的起源
GPU数据库系统的兴起主要是由真实世界的应用需求推动的。随着人类社会进入由越来越多和多样化的应用程序驱动的数据计算时代,这些应用程序得到了社会中的新技术和创新概念的支持,如移动计算、数字内容共享、共享经济等,新的应用需求往往超出了传统数据库系统提供和优化的功能范围。基于我们与数据行业从业者和客户的合作,我们将这些新需求总结为以下三个类别。
- 对实时业务洞察的需求:这是用户最重要的应用需求,他们需要通过对及时更新的数据应用各种分析来获得即时的业务洞察(例如[33, 39, 106, 119])。一个典型的场景是实时车辆位置管理,如Uber中使用的AresDB和USPS中使用的Kinetica的案例所示。我们从一家拥有数百万运营车辆的全球主要服务公司那里了解到,基于实时车辆位置的动态路线规划和偏离率分析不仅对降低运营成本和改善用户体验至关重要,而且对于司机和乘客来说,及时检测恶意行为以进行犯罪预防也是至关重要的。
- 对极端计算能力的需求:处理越来越庞大的非结构化数据的爆炸性趋势严重挑战了仅依靠CPU的数据库系统的有限计算能力,特别是在这个后摩尔定律时代。我们目睹了许多日常生产案例,这些案例需要通过硬件加速的解决方案来处理关系数据库中的非传统和庞大数据集,这对于包括但不限于DNA测序[14, 80]、空间数据分析[16, 35, 110]和3D结构分析[79, 96]等应用非常重要。令人惊讶的是,我们观察到用户仍然更喜欢使用数据库产品来管理他们的数据,尽管他们经常对数据库系统在他们的任务中的性能感到不满意。这是因为数据库在为用户提供简单接口方面具有优势。如果他们使用多个分散的软件工具,他们可能需要手动管理它们。
- 对一站式数据管理的需求:随着对实时数据分析的需求(从简单的聚合到复杂的统计分析),用户通常要求使用一站式解决方案来统一数据写入、查询处理和机器学习。与常用的两阶段解决方案(例如RocksDB+Spark [29, 118])相比,单个数据库(例如[5][12])可以显著节省用户在使用和管理方面的成本,并且可以避免在独立系统之间进行数据传输。其他例子包括Teradata Vantage [71]和Google BigQuery云服务 [1],它们将机器学习功能嵌入到其关系查询执行引擎中;因此,不再需要使用单独的机器学习系统来处理数据库中的数据。然而,性能隔离和服务级别协议的要求为一站式数据库的实现带来了新的挑战。
- 快速的硬件进步:硬件技术的快速发展使得GPU能够提供越来越强大的并行计算能力和大容量内存空间。通过NVLink协议 [8],单个服务器可以提供几百GB的快速访问内存池,为GPU核心提供数据处理支持。因此,这种硬件进步趋势正在创造一种GPU风格的内存计算环境,这在最近的数据库研究工作中已经出现(例如[116][99][90])。 十多年前(2010年),当RAMCloud提出实现全内存数据存储的概念时,用于支持该案例的两个关键因素是每台服务器64GB的DRAM容量和每GBDRAM的60美元成本。如今,这样的概念已经成为数据处理的现实,例如在主内存数据库系统中(例如[34, 64, 120])。
同样,如今的GPU硬件能力已经超过或保持与RAMCloud中配置相同的水平,无论是容量还是价格/容量。即使是单个Nvidia A100也可以拥有80GB的内存,这比RAMCloud中每台服务器的DRAM容量还要大。就价格而言,亚马逊上的公共GPU卡(PNY NVIDIA Quadro RTX 8000,48GB GDDR6内存,售价4,997美元,EVGA GeForce RTX 3090,24GB GDDR6内存,售价2,499美元)已经提供了每GB内存约100美元的价格 - 即使我们只计算内存部分的最终价格。商品化的GPU发展为我们提供了一个充满希望的前景,我们可以乐观地说,GPU的计算能力将在大容量内存空间中实现最佳利用。
构建GPU数据库的目标问题
尽管已经进行了许多学术研究来优化GPU数据库处理(例如[18, 28, 44, 61, 90, 95, 98, 99, 101, 105]),但它们通常只关注单个方面,没有提供构建真实数据库产品的完整参考。本文试图解决以下三个问题。 算法选择问题:存在各种算法(例如哈希连接和排序合并连接),但如何在它们之间做出正确选择是一个行业产品的关键问题。 简单数据分析问题:在现有的GPU数据库文献中,我们经常发现性能评估是通过类似SSB(星型模式基准)的工作负载进行的。然而,行业产品需要通过复杂的数据分析工作负载进行密集的性能评估,例如需要更多实际SQL功能的TPC-H查询[11]。 隔离环境问题:在现有的GPU数据库文献中,我们经常发现查询性能是在隔离环境中评估的,假设没有伴随的数据修改。然而,实际中的日常数据库操作不可避免地涉及读取和写入。
贡献
本文旨在通过介绍RateupDB的基本结构、设计选择和性能洞察来解决上述问题。为了填补学术研究和产品开发之间的差距,我们做出以下贡献。 通过综合考虑做出正确选择: 我们介绍了一组宏观级别的设计选择,用于实现RateupDB,并解释了为什么做出这些选择。我们提出了几个重要部分的实现技术,特别是如何将查询执行和事务处理结合起来。 在生产环境中通过复杂数据分析揭示RateupDB的性能: 我们展示了RateupDB在完整的TPC-H测试中的性能:(1)使用官方基准规范和(2)严格满足测试要求。我们全面的评估结果证实了RateupDB中系统平衡原则的价值。
架构
我们首先讨论了几个已确定的宏观级别的平衡点,这为RateupDB的整体设计策略奠定了基础。
系统构建需要平衡的关键点
RateupDB是一个异构混合事务和分析处理(简称为异构HTAP,或H2TAP [18][95],在本文中我们简化为HTAP)数据库系统,旨在最大程度地利用CPU、GPU和大容量DRAM内存来同时运行混合工作负载。为了实现行业产品的目标,RateupDB的开发侧重于以下三个关键的平衡点,这些平衡点涉及技术挑战和工程成本。
- 平衡点1:事务与查询。HTAP系统的一个主要目标是在共享数据库平台上优化事务处理和查询执行,同时提供性能隔离,以满足用户对服务质量(QoS)的满意体验。这一点与主要的系统策略密切相关,包括硬件资源分区、数据存储格式和访问方法,以及并发控制方法。在一个庞大的设计空间中进行平衡性能权衡是具有挑战性的,因为存在各种冲突因素(例如RUM猜想[19][93]或多源集成分析[94])。
- 平衡点2:性能与工程成本。与学术研究项目不同,行业产品的开发必须考虑工程成本,这是来自财务资源预算和生产截止日期要求的约束。因此,系统设计选择和各种算法采用必须平衡多个因素,包括性能、适应性、稳健性和实现成本(例如与其他系统组件的独立程度)。这个平衡点的一个典型例子是GPU连接算法的选择,这将在本文后面讨论。
- 平衡点3:性能与可移植性。在软件开发中实现高性能和可移植性的目标是具有挑战性的。具体而言,在高性能计算中,例如[92][46],我们经常追求两个相互冲突的目标:(1)最大限度地利用硬件平台和软件库中的所有功能,以及(2)在某些硬件功能不普遍可用时最大化软件的适应性。这个平衡点对于RateupDB的开发非常重要,因为它经常需要针对GPU硬件进行优化的算法(例如本文后面将讨论的内存管理问题)。
架构总览
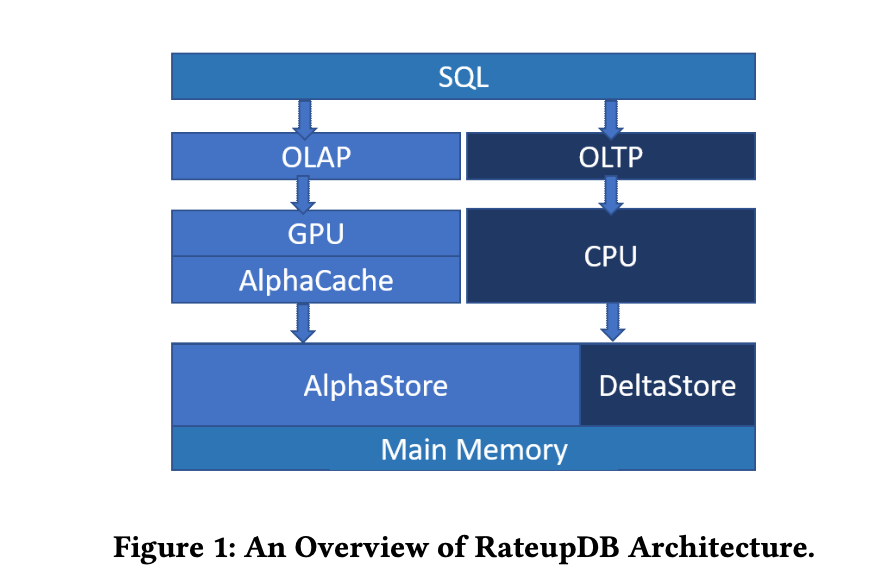
Figure 1 shows an architectural overview of RateupDB. We sum- marize RateupDB’s main features as follows.
硬件保证的性能隔离:构建HTAP系统的一个主要挑战是尽量减少事务工作负载和分析工作负载之间的性能干扰,因为这两种类型的工作负载具有不同的执行模式、SLA(服务级别协议)要求和优化策略。在仅使用CPU的HTAP系统中实现性能隔离和频繁数据更新的双重目标是具有挑战性的[95]。然而,基于GPU的HTAP系统由于能够在不同的硬件设备上分配和运行不同的工作负载,因此在解决这个问题上具有独特的优势。如图1所示,RateupDB使用CPU执行OLTP工作负载(即插入/删除/更新),并使用GPU在共享数据存储中执行各种OLAP工作负载的查询。由于CPU和GPU是独立的硬件设备,如果相应的软件定义良好,就可以硬件保证的性能隔离:构建HTAP系统的一个主要挑战是尽量减少事务工作负载和分析工作负载之间的性能干扰,因为这两种类型的工作负载具有不同的执行模式、SLA(服务级别协议)要求和优化策略。在仅使用CPU的HTAP系统中实现性能隔离和频繁数据更新的双重目标是具有挑战性的[95]。然而,基于GPU的HTAP系统由于能够在不同的硬件设备上分配和运行不同的工作负载,因此在解决这个问题上具有独特的优势。如图1所示,RateupDB使用CPU执行OLTP工作负载(即插入/删除/更新),并使用GPU在共享数据存储中执行各种OLAP工作负载的查询。由于CPU和GPU是独立的硬件设备,如果相应的软件定义良好,就可以保证性能隔离。
基于MVCC的双数据存储:作为持久性存储库的数据存储在查询执行和事务处理中起着重要的基础作用,特别是当这两种工作负载同时运行时。由于RateupDB建立在CPU和GPU上,数据存储的设计和实现必须以一种方式进行,以便(1)在GPU上进行查询执行高效,并且(2)尽量减少性能干扰。为了实现这两个目标,RateupDB在主内存中使用“双存储”,它由两部分组成:AlphaStore和DeltaStore(见图1)。对于给定时间的数据库,AlphaStore存储数据库中的现有数据以供查询处理,而DeltaStore存储新事务对数据库所做的更改。多版本并发控制(MVCC)被用于协同管理这两个存储。通过这种方式,GPU设备可以通过从AlphaStore和DeltaStore组合获取数据库的快照来独立处理OLAP查询,而CPU可以执行事务以修改DeltaStore中的数据库状态。此外,RateupDB使用GPU设备内存的一部分(称为AlphaCache)来缓存AlphaStore中经常使用的数据项,以避免从主机内存到GPU设备内存的不必要的数据传输。目前,AlphaStore和DeltaStore都采用列存储格式,即将表的每一列独立存储。
数据格式
数据存储格式很重要!
虽然关系表的基本数据格式可以是行存储或列存储,但在设计空间中有多种选择,例如:(1)选择基本存储之一,(2)混合它们以形成混合格式(例如[15, 51, 58]),以及(3)使用多个数据存储组合基本存储。表1列出了每个数据存储类别的几个典型数据库系统,显示了不同数据库系统中多样化的设计选择。
双存储的必要性
作为一个HTAP数据库系统,RateupDB采用了双存储的方法(列+列),原因有几个。传统的智慧认为,行存储更适合处理事务工作负载(例如PostgreSQL),而列存储更适合处理分析工作负载(例如MonetDB [27])。但是对于需要处理事务和分析工作负载的HTAP系统来说,无论是行存储还是列存储都不足够。因此,几个HTAP系统(Hyper [62]、SAP HANA [100]、Caldera [18]、BatchDB [81])采用了不同的方式来组合这两种存储。基本上,这四个系统可以分为两类:(1)单存储:允许用户选择行存储、列存储或混合存储;(2)多存储:组合两个甚至三个存储以最好地服务于事务和查询。基于CPU的HyPer和基于GPU的Caldera是第一类中的典型例子,而SAP HANA和BatchDB则属于第二类。对于第一类,与HyPer相比,Caldera的性能结果表明,混合数据存储比纯行存储或纯列存储更有效。对于第二类,SAP HANA使用三级存储(L1 Delta、L2 Delta和主存储),其中第一级采用行存储用于吸收事务,而后两级采用列存储用于查询处理。BatchDB(以及TiDB [59])使用单独的存储(通过副本)来隔离OLTP和OLAP。Oracle Database In-Memory (ODIM) [70, 91]也属于这一类,它采用了双格式的内存存储(列存储用于OLAP,行存储用于OLTP - 缓存磁盘数据)。
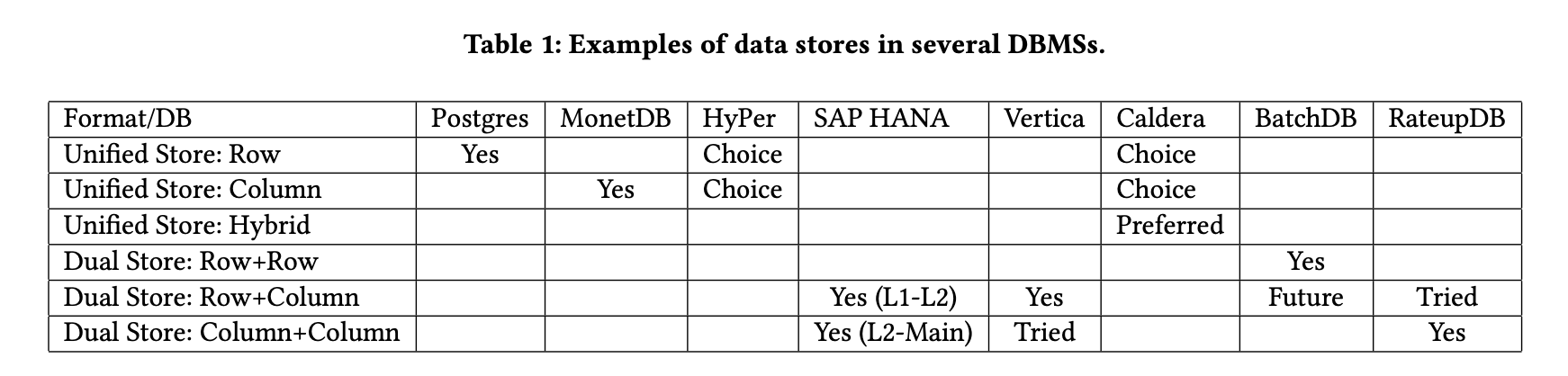
表1中的统一单存储方法和分离的双存储方法都有优缺点。
首先,维护单独的存储需要额外的成本来管理和合并多个数据存储。然而,将事务和查询分开存储可以最大程度地减少对共享数据的干扰,这对于CPU-GPU异构数据库系统特别适用,其中查询在GPU上执行,而事务在CPU上执行。理想情况下,当GPU开始执行只读查询时,它应该通过避免让CPU执行过多的格式解析或数据准备来最小化对CPU的干扰。此外,当CPU执行事务时,其写操作和同步相关操作(锁或闩锁)不应干扰GPU的处理。如果管理得当,双存储是实现这些目标的有效解决方案。
为什么是列存储 + 列存储?
现在的问题是在双存储中应该使用什么数据格式。首先,对于分析任务来说,列存储是最佳选择,因为它具有各种性能优势[103][13]。因此,几乎所有上述提到的HTAP系统都在其分析部分使用列存储。唯一的例外是BatchDB [81],它使用行+行存储的组合,因为其目的是展示使用单独的存储来处理OLTP和OLAP的必要性。尽管如此,BatchDB团队承认列存储在分析方面的优势,并计划在未来版本中实现它。
其次,对于事务任务,我们观察到并不是所有系统都一致使用行存储,尽管行存储声称在OLTP工作负载方面具有优势。SAP HANA采用混合方法,通过在其面向列的主内存存储之前应用行存储的L1-delta和列存储的L2-delta来连接事务任务和分析任务[100]。另外两个系统案例(HyPer和Vertica)展示了使用列存储来吸收对数据库的事务写入的可能性。HyPer [62]:“HyPer可以配置为行存储或列存储。对于OLTP,我们没有遇到显著的性能差异。”Vertica [72]:“WOS随着时间的推移从行导向变为列导向,然后再次变回行导向。我们没有发现这些方法之间有任何显著的性能差异,这些变化主要是由软件工程考虑驱动的。”使用列存储来处理事务的根本原因是它可以极大地加速查询处理和表合并操作,而对于OLTP来说,它的性能降低是可以忽略或可接受的。与Vertica类似,RateupDB最初采用了行+列的双存储,但很快改为了列+列的双存储,以加速分析工作负载,同时保持事务在可接受的性能水平上。
RateupDB 的数据存储
AlphaStore: AlphaStore(即主存储)是一个面向列的数据存储,从磁盘加载到主内存中,其中每个表列都存储在连续的数据块中。当存储在磁盘上时,AlphaStore不包含任何MVCC(多版本并发控制)信息。加载后,所有元组都是只读的,并且对所有后续事务可见,除非它们被删除,这将由DeltaStore记录。实质上,当执行查询时,AlphaStore中的数据将被传输到GPU进行查询处理。RateupDB使用GPU设备内存中的一个区域,称为AlphaCache(参见图1),通过LRU算法将AlphaStore中的频繁使用的数据存储在其中。
DeltaStore: DeltaStore是基于MVCC的列存储,它记录每个事务完成后对AlphaStore的更改。对于插入命令,新插入的数据将追加到DeltaStore的相应列中。对于删除命令,被删除的行的ID将由DeltaStore记录在一个删除向量中。对于更新命令,它实质上被转换为插入和删除操作。存储的详细并发控制将在第5节中介绍。
GPU查询处理
RateupDB使用基于GPU的查询执行引擎。在本节中,我们关注以下三个方面:
- (1)引擎结构:它实质上决定了查询计划树中一系列关系操作如何在GPU设备上连接和执行;
- (2)算法选择:它涉及如何最好地利用GPU硬件来实现各种运算符的具体算法;
- (3)复杂查询处理:它解决了如何执行具有各种子查询形式的复杂SQL查询的问题。
浅谈查询引擎的结构
RateupDB的查询引擎结构采用了一种逐个运算符的方法,这是从其早期原型GPUDB [115]继承而来的。基本上,查询计划树中的所有运算符按照树结构的顺序依次完成。对于每个运算符,在其所有输入数据传输到GPU内存后,执行一组GPU内核,而运算符的最终输出结果保留在GPU设备内存中,以供后续运算符执行使用。尽管这种模型具有普遍执行所有SQL查询的优点,但它可能无法有效地执行具有相关性的多个运算符,因此可以通过组合方式完成。为了解决这个问题,RateupDB采用了组合运算符的方法来优化某些重要的OLAP查询场景。RateupDB使用Star Join和Self Operator来实现最佳利用GPU计算资源并最小化数据传输开销的目标,这将在后面讨论。
关于 Join and Grouping
RateupDB的重要工作之一是集中在如何有效地在GPU上执行各种关系操作,特别是连接和分组/聚合操作。关于如何实现这两个操作以及选择什么的问题,已经有很长时间的争论:基于排序的算法还是基于哈希的算法。现有的研究工作在多核或众核CPU上解决上述两个问题的线索往往得出不同的结论。然而,一个广泛接受的结论是,需要一个复杂的成本模型来考虑数据分布和硬件参数,以比较这两类连接算法。我们面临的挑战是如何在大规模的算法设计空间中考虑先前的研究结果来构建一个查询引擎。
4.2.1 排序 vs 哈希再探。我们首先对CPU和GPU数据库中排序和哈希的问题进行了简要调查,这为我们在算法设计和实现中的方法奠定了基础。Kim等人[63]提出了两种SIMD优化的并行连接算法:基数哈希连接算法和使用比特拼接网络和多路归并来实现底层排序操作的排序-合并连接算法[30]。他们的性能分析结果显示,对于具有更宽的SIMD和更小的每核内存带宽的未来众核硬件,排序-合并连接可能优于哈希连接。Blanas等人[25]表明,非分区哈希连接(使用共享哈希表)可以优于更复杂的基于分区的哈希连接算法,包括基数哈希连接。Albutiu等人[17]提出了NUMA优化的、大规模并行的排序-合并连接算法,使用基于范围分区的合并连接技术,结合多种排序算法,包括基数排序和快速排序。他们的性能比较表明,排序-合并连接比基数哈希连接和非分区哈希连接更快。Balkesen等人[21]提出了优化的基数哈希连接(通过减少缓存未命中和TLB未命中)和SIMD优化的排序-合并连接,其排序利用排序网络和比特拼接网络。除了证明他们的连接实现比[25]和[17]中的实现更快之外,他们还表明他们的哈希连接比排序-合并连接更快。然而,对于大型工作负载,性能是可比较的。
从多核转向GPU带来了关于排序和哈希的新的讨论。He等人[49]在早期的GPU硬件上比较了基数哈希连接和排序-合并连接,使用了比特拼接排序和快速排序,并得出结论基数哈希连接比排序-合并连接更快。Yuan等人[115]提出了在GPU上用于星型模式查询的非分区哈希连接。Shanbhag等人[99]进行的最近一项与GPU相关的研究也使用了这种非分区策略,并指出与基数哈希连接相比,非分区哈希连接的优势在于其在流水线多连接中的有效使用。尽管基数哈希连接在单连接性能上优于非分区哈希连接[21],但考虑到用于快速合并的GPU Merge Path算法[45][87]和其他基数排序算法[102],与GPU优化的排序-合并连接相比,其性能优势减弱了。Rui和Tu [98]通过避免两次哈希探测实现了改进的基数哈希连接,以及使用GPU Merge Path进行排序阶段和合并连接阶段的排序-合并连接。他们的性能分析表明,在GPU上,排序-合并连接优于基数哈希连接。值得一提的是,他们的通用合并排序不是最快的基于基数的排序[102],对于任意数据类型有一定的限制。Siloulas等人[101]实现了硬件感知的基数哈希连接,并展示了它相对于非分区哈希连接的加速效果。
4.2.2 RateupDB的方法。理想情况下,所有上述提到的连接算法都应该在一个数据库管理系统中实现,并且该系统进一步利用具有精确成本模型的查询优化器来为给定的查询选择正确的算法。然而,实现这样一个查询优化器(例如,[74])是一项非常复杂的任务,它涉及一系列执行组件,包括数据分布估计和运行时统计信息收集。然而,在实践中,它的价值往往是微不足道的[77]。
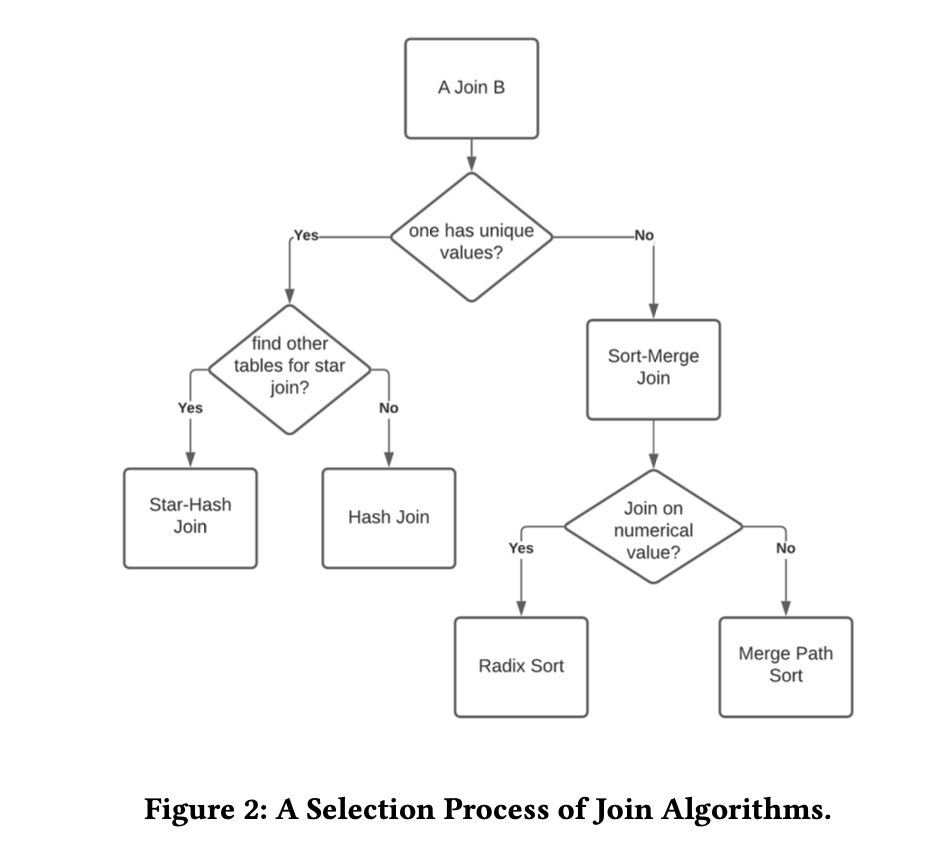
为了平衡数据库性能和工程工作量,我们在实现连接算法时采用了以下三个原则。首先,实现一个默认的通用连接算法。我们使用排序-合并连接来实现这个目的。它的排序阶段根据连接键的特性使用基数排序和合并路径排序,而合并连接阶段使用合并路径算法。其次,优化以星型连接为主导的数据仓库查询。我们使用非分区哈希连接来实现这个目的。此外,它还提供了基于二进制非分区哈希连接的星型哈希连接,用于多个连接。最后,使用简单的规则来选择连接算法。我们不使用任何成本模型,只使用基于模式信息的简单规则。我们的连接算法选择过程如图2所示。
我们选择排序-合并方法作为默认连接算法而不是基数哈希连接的原因既与性能有关,也与开发成本有关。性能考虑:正如[98]所指出的,如果两者都通过利用GPU进行优化,排序-合并连接比基数哈希连接更快。这个结论与[21]提供的结果一致,表明排序-合并连接对于大型输入表更有利。工程和开发成本考虑:排序-合并连接在处理数据大小变化和对称性方面都具有一定的优势,不需要查询优化器指定哪个表用于哈希构建或探测。此外,排序阶段是一个通用的并行计算问题,可以与连接阶段分开处理,这样CUDA工程师可以独立优化排序阶段,而无需具备数据库背景知识。
4.2.3 关于分组。在GPU数据库中,像连接一样,处理分组也可以基于哈希(例如,GPUDB [115])或基于排序(例如,CoGaDB [28])。默认情况下,RateupDB使用基于排序的分组策略。首先,当分组数目较大时,基于排序的分组策略优于基于哈希的分组策略。之前的研究工作[61][105]报告称,在分组时,当分组数目少于200,000个时,哈希算法更快。然而,一旦哈希表太大无法存储在L2缓存中,其性能显著低于排序算法。这种现象实际上类似于多核CPU连接的情况[21]。其次,相比于哈希分组,排序分组可以更容易实现和更好地优化,考虑到(1)排序可以单独实现,(2)在一般数据集上实现高效的哈希表以最小化或完全消除冲突是一项非常复杂的任务[53][105]。
关于子查询
子查询处理对于数据库产品中的SQL性能非常重要,例如SQL Server [37]和Oracle Database [23]。RateupDB不使用通用的子查询处理算法(例如[86][41])。然而,我们实现了常用的子查询展开技术,可以将子查询转换为各种连接和聚合操作(例如Kim方法[65]),这使得RateupDB能够高效地执行类似TPC-H的查询。
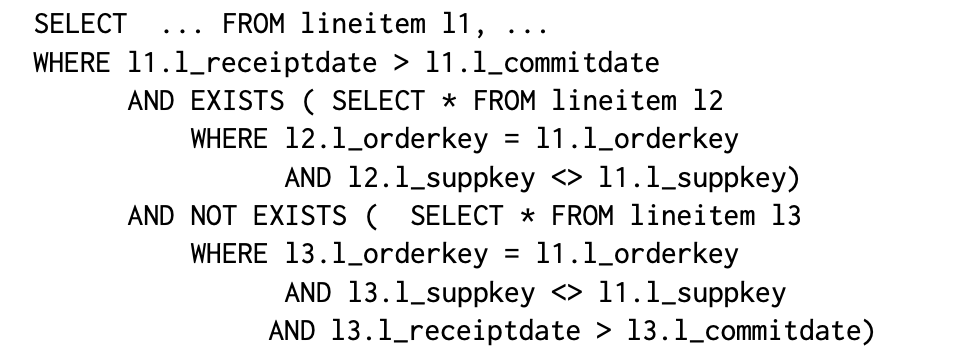
4.3.1 一个示例。虽然在本文中全面介绍子查询处理超出了范围,但我们介绍了如何优化一个重要的子查询类型:EXISTS和NOT EXISTS。下面的代码是TPC-H Q21的一部分,它基本上使用两个子查询从𝑙𝑖𝑛𝑒𝑖𝑡𝑒𝑚中过滤出一些记录。我们采用了一种典型的子查询展开技术来执行查询:(1) 使用半连接来执行EXISTS子查询,(2) 使用反连接来执行NOT EXISTS子查询。
4.3.2 半连接/反连接和自连接。实现半连接和反连接与等值连接类似,可以使用基于哈希或基于排序的算法。由于左表的每个元组只输出一次或不输出,输出缓冲区可以预先分配为左表的长度。并行线程可以使用AtomicAdd将结果写入正确的位置,而无需在哈希等值连接中进行两次探测或在排序等值连接中进行前缀扫描。
然而,考虑到Q21中的查询语义,简单地执行过滤和两个连接操作会很慢,因为所有操作都只在同一张表上进行。为了利用这种相关性[75][57],我们实现了一个自连接操作符,将多个操作组合到一个公共阶段中。这类似于Microsoft SCOPE [76]和HorseQC [43]中的超级操作符概念。如果对同一张表进行多个操作具有相同的分区机会,即整个任务可以分为独立的子任务,那么将启用自连接操作符。在同样的示例中,自连接将根据共享的连接键𝑙_𝑜𝑟𝑑𝑒𝑟𝑘𝑒𝑦对𝑙𝑖𝑛𝑒𝑖𝑡𝑒𝑚进行分区,并为每个分区执行这三个操作。
自连接操作符可以基于哈希或基于排序,这取决于分区列是否具有唯一值。对于同样的示例,自连接是基于排序的。类似于基于排序的分组,首先对表进行分组。在一个分组内,自连接将执行所需的操作(通过调用其他操作符模块中的相应函数),类似于Pig Latin中使用的GROUP概念,允许用户执行任意代码而不仅仅是聚合操作。
事务处理
基本 MVCC 方法
我们使用类似于PostgreSQL的多版本并发控制(MVCC)来在RateupDB中实现快照隔离。如图3所示,RateupDB使用双存储模式,即AlphaStore和DeltaStore。这两个存储都是列存储。AlphaStore是只读的,并由永久存储设备支持,而DeltaStore仅驻留在主内存中,用于读取和写入操作。
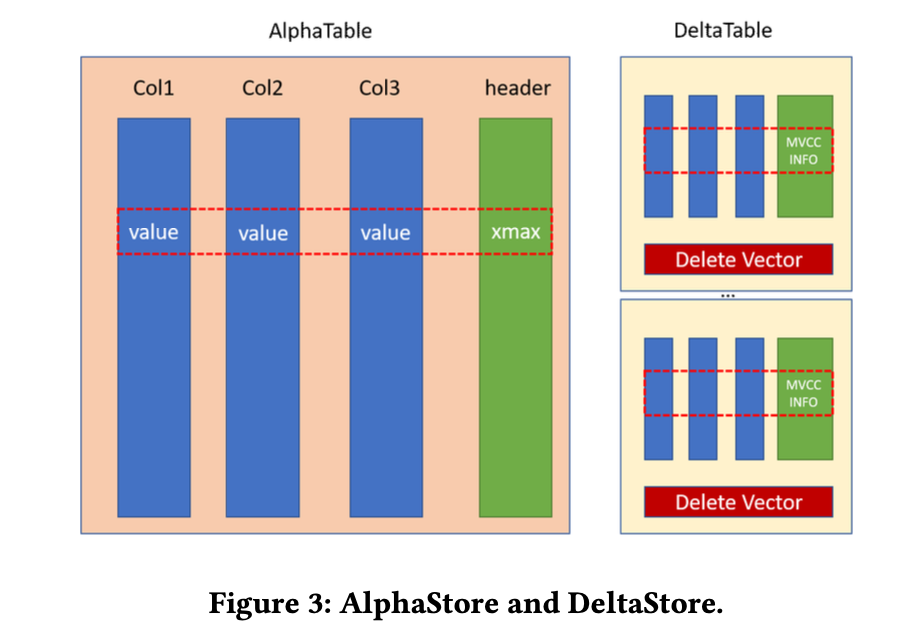
当启动RateupDB时,它将从永久存储设备加载AlphaStore到主内存中。对于每个表,AlphaStore仅包含其列式数据,没有任何MVCC信息。加载后,列式数据变为只读。RateupDB将为每个表添加一个特殊的头部列,用于记录每个元组的MVCC信息。然而,由于AlphaStore对所有后续事务可见,存储在头部列中的MVCC信息是不完整的,仅记录了𝑥𝑚𝑎𝑥信息(即删除元组的事务ID),而没有𝑥𝑚𝑖𝑛信息(即创建元组的事务ID)。
DeltaStore存储事务的数据修改,可以有多个块。当一个块已满时,将分配并使用另一个块,如图3所示。尽管DeltaStore的整体设计与PostgreSQL类似,但它有两个独特的区别。首先,它不使用𝑝𝑎𝑔𝑒概念,因为DeltaStore只是一个主内存存储[34]。其次,它使用删除向量来记录与AlphaStore相关的删除信息。当插入新元组时,其数据将追加到相应的列中。当删除元组时,该元组将被设置为𝑥𝑚𝑎𝑥(与AlphaStore和DeltaStore相同),而其元组ID(仅适用于AlphaStore)将追加到删除向量中。当使用新元组更新旧元组时,将执行删除和插入操作。在DeltaStore中,每个新元组和删除记录都具有完整的MVCC信息(例如𝑥𝑚𝑖𝑛和𝑚𝑎𝑥以及其他标志)。
在执行查询时,CPU将对DeltaTable执行MVCC扫描,生成两种快照内容:(1) 对于查询不可见的AlphaStore中的元组ID(即已删除的元组),以及(2) 对于查询可见的DeltaStore中所有元组的列数据。当GPU需要处理一列数据时,CPU将与AlphaStore中的原始列一起将这两种快照内容发送到GPU。在这种情况下,GPU不需要处理任何MVCC信息,而只需执行一个简单的内核来从原始列中过滤出不必要的元组(类似于过滤内核),然后将新数据与后续查询处理相结合。如果原始列已经缓存在GPU设备内存(AlphaCache)中,则只需将这两种快照内容从主机内存传输到GPU。考虑到DeltaStore的大小相对较小,比AlphaStore小得多,这样的设计可以有效加速GPU端的查询执行。然而,CPU端的MVCC扫描并非没有成本,因为PostgreSQL风格的MVCC实现使用统一存储,未提交的元组和已提交的元组混合在一起,并且根据MVCC信息(例如𝑥𝑚𝑖𝑛和𝑥𝑚𝑎𝑥)对每个元组进行复杂的可见性检查是不可避免的。加速MVCC可见性检查对性能至关重要,例如Netezza [42]使用FPGA进行检查,以避免传输不可见的元组。在RateupDB中,我们实现了一个特殊的MVCC不变式,旨在加速检查过程。
快速查询的执行优化
作为实现快照隔离的一种方法,如何实现MVCC的可见性检查对于一个元组可能是不同的。在最初介绍快照隔离的论文中[24],对于物理实现的要求没有提及,只是提到了以下声明:“在任何时候,每个数据项可能有多个版本,由活动和已提交的事务创建。”。由未提交事务写入的元组对其他事务应该是不可见的。然而,对于这样一个元组的不可见性检查在不同的实现中可能有两种方法:(1) 一个事务可以访问该元组,然后发现它是不可见的;(2) 事务根本无法访问该元组。前者意味着所有的元组都被写入到一个公共空间中,无论事务是否已提交(例如,PostgreSQL),而后者意味着一个未提交的事务只能将其写入的元组保留在其私有空间中,直到它提交这些元组才会被安装到公共空间中。第二种情况在[40]中重新定义的快照隔离中暗示了,该论文指出一个事务“将其自己的写入结果保存在本地内存存储器中”。此外,第二种方法更类似于乐观并发控制(OCC)方法[69]和其他并发控制算法和实现(例如[108, 117])。
早期版本的RateupDB使用了第一种方法,但已改为第二种方法以加速查询执行。对于事务执行而言,与第一种方法相比,第二种方法的缺点是存在双重写入问题,导致插入的元组在内存中被写入两次。然而,它的优点是避免了扫描未提交事务的已写入元组,特别是来自需要以批处理模式写入多个元组的事务,在面向分析的环境中更为常见。此外,由于DeltaStore仅记录已提交事务的元组,RateupDB可以按照已提交事务的顺序组织DeltaStore,每个事务提交都将追加到DeltaStore中。因此,当查询执行开始时,它只需要扫描最新已提交事务之前的元组,并忽略任何后续的元组,因为它们对查询是不可见的。更重要的是,扫描不需要比较𝑥𝑚𝑖𝑛或𝑥𝑚𝑎𝑥。当然,如果元组出现在删除向量中,它仍然可能是不可见的,只有已提交删除的记录才会留在删除向量中。第二种方法的另一个优点是更容易将DeltaStore合并到AlphaStore中。对于已满的DeltaStore块,如果修改该块的最新事务ID已经被当前事务ID超过,那么意味着该块中的元组已经对任何未来的事务可见,因此可以将该块追加到AlphaStore中。
CPU 任务 VS GPU 任务
CPU 上的查询执行
目前,RateupDB不支持CPU OLAP查询,而是仅依赖基于CUDA的GPU查询引擎。由于CPU和GPU之间的执行模式差异,维护一个额外的CPU查询引擎是一个非常复杂的工程任务。我们早期的GPUDB原型支持CUDA和OpenCL,以便查询可以在CPU和GPU上运行。然而,根据可靠性考虑,我们从开发经验中得知,在商业产品中使用OpenCL可能不是一个有效的选择。如果不使用OpenCL,一个与GPU CUDA查询引擎完全不同的CPU查询引擎将需要大量的软件开发工作。
RateupDB允许CPU和GPU共同处理某些查询。这发生在两种情况下:1. 当GPU设备内存无法容纳所有输入数据时,启用基于分区的策略。CPU需要对主内存中的数据执行必要的预分区、合并和材料化操作。2. 对于某些SQL函数(例如MySQL中的GROUP_CONCAT函数),如果并行线程的输出大小无法预测或它们具有非均匀分布,该函数将在CPU上执行,因为很难为每个线程的输出数据有效地预分配GPU内存。
目前,RateupDB使用GPU来执行更新语句中的where条件部分(可能包含嵌套子查询)。这种策略适用于具有两个特点的TPC-H风格的工作负载:(1) 并发插入,和(2) 并发批量更新,从预定义的查找键表中选择多行。这种方法的好处是避免了在CPU端建立索引,但对于更新操作,需要接受一定的查询延迟。然而,我们意识到,在具有大量点查询(即键查找)的高负载OLTP工作负载中,无法避免基于CPU的索引扫描。我们计划在下一个版本中添加这样的功能。
索引
目前,RateupDB在OLAP查询中不使用任何索引。但是,在将新元组插入具有主键或外键的表时,它使用一种特殊的索引方法来加速OLTP工作负载的约束检查。对于大表而言,如果没有辅助索引结构,插入操作将主要由主键检查所占据。与传统的数据库(例如PostgreSQL)不同,后者通常利用统一的B+树来进行检查,RateupDB在双存储中使用混合索引方法。首先,对于DeltaStore,建立一个哈希索引,根据主键快速定位元组ID。其次,对于AlphaStore,由于其只读性质,主键的列数据已经按照主键的顺序进行了排序。
更多的可能性
目前,查询优化器和事务引擎仅在CPU上运行。虽然可以在GPU上执行这些任务,但我们没有这样做的原因如下。首先,对于查询优化器,已经进行了研究来探索使用GPU执行一些关键的查询优化任务,例如选择性估计[52]和连接顺序优化[83]。此外,最近基于机器学习的查询优化工作(例如[66–68, 82, 104, 107, 112, 114])通过使用深度学习或强化学习算法,提出了使用GPU的自动查询优化软件的可能性,这可以极大地受益于GPU的大规模并行计算能力。然而,在HTAP数据库中如何最好地利用这些算法,以在整体效益、性能隔离和工程成本之间取得平衡,目前还不清楚。其次,对于具有与只读OLAP查询处理不同执行模式的事务引擎,之前的研究[50] [121] [56]也证明了使用GPU执行事务或构建底层键值存储的可能性。然而,这些系统存在一定的限制(例如,仅支持预定义的存储过程或仅作为数据存储而没有事务支持),因此它们不是通用的GPU事务引擎。
异构内存
两个内存的说明
自从通用GPU计算兴起以来,计算机系统研究的重点已经集中在解决由两种内存引起的问题:CPU核心的主机内存(DDR DRAM)和GPU核心的GPU设备内存(GDDR SDRAM),它们在物理上是分离的,但通过通信链路(PCIE或NVLink)连接在一起。由于GPU核心只能直接访问GPU的设备内存,其主要缺点总结如下。
- 容量太小无法容纳大型数据集:有限的物理GPU内存大小是主要的GPU编程挑战之一。从硬件和系统的角度来看,已经做出了各种努力,添加虚拟内存支持以提供无限内存空间的幻觉[73][109][122][20],或者使用硬件压缩算法来节省内存空间[32]。从应用程序的角度来看,这个问题导致了额外的编程工作量,需要将大型输入数据分割成多个块进行分别处理,可以通过利用多个GPU设备进行并行处理,或者在GPU内存和主机内存之间传输数据块来实现。自从通用GPU计算兴起以来,计算机系统研究的重点已经集中在解决由两种内存引起的问题:CPU核心的主机内存(DDR DRAM)和GPU核心的GPU设备内存(GDDR SDRAM),它们在物理上是分离的,但通过通信链路(PCIe或NVLink)连接在一起。由于GPU核心只能直接访问GPU的设备内存,其主要缺点总结如下。
- 内存距离远:由于存在两个物理上分离的内存,GPU数据库的主要瓶颈是PCIE传输,即所谓的“阴阳问题”[115]。已经提出了各种优化技术,例如(1)利用数据压缩减少传输数据的大小[38],(2)在GPU内存中缓存传输的数据以便进行数据重用[111],(3)一旦传输就最大化数据使用[43],(4)通过延迟和/或共享传输避免不必要的数据移动[95],以及(5)重叠传输和计算以隐藏延迟[97][111]。
- 编程困难:上述两个问题的结合使得早期阶段的GPU编程变得困难,因为缺乏一个统一的虚拟内存,可以使程序员从手动管理两个独立内存的负担中解脱出来。自从Nvidia Pascal GPU架构(CUDA 8软件)[47]以来,使用ManagedMemory API的统一内存编程模型已经可用,因此GPU程序可以在较少的内存限制下开发。然而,由于无法控制的页面错误和抖动,当GPU内存超额使用时仍然会导致显著的性能下降[47][32]。
设计选择
考虑到GPU的多种内存管理方法的可用性,GPU数据库应该平衡多个因素,包括单个查询性能、并发查询吞吐量和编程工作的成本。在介绍RateupDB的内存管理实现之前,我们将以下两个目标作为设计的基础。
- 最大化单个查询性能:RateupDB的开发始于GPUDB [115] 原型,将GPU视为一个协处理器,采用显式的GPU内存分配和数据传输。对于每个操作符,需要进行仔细的数据分割步骤,根据运行任务和GPU内存大小的预测空间分配,确定可以一次处理多少数据。然而,准确估计所需的内存空间的困难使得这种方法难以实现并发查询处理。
- 最大化编程简易性:AlphaStore完全采用统一内存进行实现,最初使用cudaMallocManaged进行分配。因此,后续的查询执行直接应用于AlphaStore,无需进行任何显式的数据传输。所有临时数据结构(例如中间结果或哈希表)也以这种方式实现。这种编程简易性使我们能够在不考虑可用物理GPU大小的情况下开发RateupDB。然而,对于大型工作负载的未受控数据抖动可能会导致性能下降。
RateupDB 内存管理
考虑到前面讨论的问题和可能的设计选项,我们采用了一种混合方法来管理RateupDB的内存。首先,作为一个数据库服务器应用程序,RateupDB将GPU设备内存分为两个区域:(1)AlphaCache区域,用于缓存AlphaStore中的热数据(目前使用LRU算法进行缓存替换);(2)工作区域,提供内核执行的空间(即存储必要的数据结构和内核执行的结果)。其次,工作区域以需要显式内存分配和传输的方式使用(如果需要),而不使用ManagedMemory API。最后,RateupDB仅在一些特殊情况下使用ManagedMemory,这些情况下所需的内存空间不容易估计,例如由于冲突而进行多次重新哈希后仍无法构建哈希表的糟糕区域,或者两个表的笛卡尔积的输出。这些情况在实践中很少见,因此为它们使用ManagedMemory不会影响性能,而且可以显著减少编程工作量。
RateupDB的混合内存管理实现是在性能和实现简易性之间取得平衡的结果。首先,作为服务器应用程序的主要性能因素,内存层次结构中的局部性对于并发数据访问起着最重要的作用。然而,让CUDA的统一内存机制管理局部性是不现实的,因为其处理典型内存系统问题(如抖动)的效率低下。其次,为了最大化单个查询性能,完全忽略了查询之间的局部性,以便每个查询可以使用GPU设备内存的全部空间来实现最佳性能。然而,考虑到数据重用的机会,这种方法并不针对整体吞吐量进行优化。第三,由于工作区域仅在查询片段执行期间使用,通过“内存管理“进行显式内存管理可以高度保证查询性能,而不涉及任何自动机制。最后,完全禁用统一内存的使用是不必要且低效的。例如,在许多算法中,为具有未知大小的数据预分配空间通常采用两次执行的方法,即算法(例如哈希探测操作)首先执行一次以确定可能的空间大小,然后在第二次执行中使用分配的内存大小来写入输出结果[49, 98]。“内存管理“可以简化动态分配内存的方法。
AlphaCache的大小
RateupDB使用可配置的参数来指定AlphaCache的大小。正如现有的自动调优数据库系统参数的研究所示[36][55],在缓存大小和性能优化之间找到最佳点是困难的,通常是基于经验的。对于RateupDB,AlphaCache的大小与多个因素相关,其中主要因素包括GPU内存大小、工作集大小以及最重要的数据结构的大小(例如用于连接或聚合的常用哈希表)。默认情况下,RateupDB建议将AlphaCache的大小设置为GPU内存大小的50%。
当输入表的数据集比GPU设备内存的大小大一个数量级时,必须使用基于分区的执行策略,以便将整个设备内存安排为一次执行一个分区的操作。在这种情况下,为了允许单个分区的执行充分利用所有GPU设备内存空间,AlphaCache应设置为0。因为即使是单个查询也必须顺序扫描多个分区,AlphaCache无法保存工作集以提供有效的缓存来支持并发查询执行。
性能评估
在本节中,我们对RateupDB 1.0版本进行了详细的性能分析。首先,我们通过执行22个TPC-H查询来展示其纯OLAP性能。然后,我们通过严格执行完整的TPC-H基准测试来展示其整体性能。
系统配置。我们使用Supermicro 743TQ-X11工作站进行所有实验。CPU是Intel Xeon Silver 4215,频率为2.50 GHz,具有8个核心(禁用超线程)和11MB末级缓存。GPU是Nvidia Quadro RTX 8000,具有48GB GDDR6内存和4,608个CUDA并行处理核心[7],通过PCIe 3.0总线连接。该机器配备256GB DDR4 DRAM和两个镜像的1TB SSD。我们使用Ubuntu 18.04 LTS操作系统和CUDA Toolkit 10.0。
工作负载和软件。我们使用TPC-H 2.18.0实现了三个规模因子(1、10和100)。为了将RateupDB与商业GPU数据库产品的最新版本进行比较,我们选择了OmniSci的最新版本,考虑到它在最近的研究文献中的广泛使用[44, 90, 99]。
查询性能

Table 2: Execution times (in seconds) of TPC-H queries by RateupDB and OmniSci. TPC-H scale factors used: 1, 10, and 100. (R: RateupDB, O: OmniSci, DNF: Did Not Finish.)
我们首先测量了RateupDB和OmniSci的只读查询执行性能。表2列出了在三个TPC-H规模因子下的所有22个查询的执行时间。每个查询被执行了四次,表中的结果是第四次执行的结果。在接下来的几个小节中,我们将深入研究我们在实验中观察到的性能洞察。
8.1.1 总体分析。RateupDB可以完成所有三个规模因子下的查询。然而,OmniSci只能在使用规模因子1时完成13个查询。这个观察结果与之前在[44]中进行的研究一致。当增加到规模因子10和100时,OmniSci的失败情况更多。结果显示,RateupDB通过子查询优化对复杂查询具有有效性。
在规模因子1下,即总数据大小为1GB,RateupDB执行大多数查询的时间都在0.1秒以下。当增加到规模因子10时,所有查询的执行时间相应增加,但仍然在1秒以下。OmniSci的性能结果各不相同:有些查询的时间从规模因子1到10几乎没有变化,例如Q5-Q8;有些查询无法完成(Q10,Q16);还有一些查询的执行时间非常长(Q18)。
当使用规模因子100时,RateupDB有几个特殊的查询无法在1秒内完成。最长的查询执行时间出现在Q1、Q18、Q21和Q9上,我们将在后面具体分析。对于OmniSci,它只能完成22个查询中的4个(Q1、Q6、Q15、Q19)。通过检查错误信息,我们发现大多数失败的情况与三个异常相关:(1)哈希表太大,与多个连接相关(例如Q9);(2)内存使用过大(例如Q18);(3)类型不可序列化,通常出现在子查询处理中(例如Q2)。
8.1.2 重度聚合查询:TPC-H Q1。TPC-H Q1是一个典型的查询,需要对大量记录执行多个聚合操作。RateupDB在三个规模因子下的执行时间分别为0.10秒、0.73秒和7.38秒,基本上反映了随着输入数据大小的线性增加而增加的时间。然而,通过使用一组微观实验进行仔细的时间分解,我们发现这种增加实际上不是由Q1中的分组或过滤等操作引起的,而是由于固定点算术操作的实现所导致的,这对于金融相关的数据库工作负载(例如TPC-H)是必需的[85]。
由于我们不能使用双精度执行TPC-H,GPU的高TFLOPS不能轻易转化为固定点算术操作的高性能。我们实现了一个通用的GPU库,用于十进制表示和计算,它使用了一个固定的20字节设计,支持(36, 30)的精度/比例,而OmniSci使用了一个更小的精度,使用2-8字节的设计,最大支持18位数字的精度。在RateupDB中,我们没有为其十进制类型实现任何TPC-H特定的优化(例如[26])。因此,它的Q1性能(以及具有重度聚合子查询的Q18的一部分)受到固定点算术操作的影响。
8.1.3 重度连接查询:TPC-H Q9。作为涉及多个连接的OLAP查询的典型示例,Q9通常是数据库OLAP性能的关键指标。由于其对星型连接的优化,RateupDB在所有三个规模因子下始终优于OmniSci的Q9。RateupDB使用其星型连接运算符来执行查询中的多个连接。通过这种方式,来自事实表的元组可以迭代地探测多个哈希表,从而实现在GPU内存中最大化数据使用的目标[44, 90]。虽然RateupDB尚未采用基于JIT编译的内核执行方法,但其使用星型连接运算符可以有效地产生类似的效果。由于星型连接是OLAP工作负载中的主要连接模式,RateupDB的实现可以被广泛使用。实际上,星型连接也用于在RateupDB中执行其他TPC-H查询,包括Q5、Q7、Q8和Q10。
8.1.4 复杂子查询的查询:TPC-H Q21。子查询优化是RateupDB处理各种OLAP查询的重要措施。我们也认为,处理各种子查询的能力是GPU数据库管理系统成为行业产品的重要进展,因为学术研究原型通常会专注于简单的分析[41, 90, 115]。如表2所示,RateupDB可以通过使用相应的展开技术有效地执行包含子查询的所有TPC-H查询。
作为TPC-H查询中的一个经典案例,我们需要付出大量努力来优化Q21,这对数据库系统的查询优化器和引擎实现构成了挑战。如4.3.2节所介绍的,RateupDB使用Self运算符来执行查询中的所有子查询。通过Self运算符和在Q9(也在Q21中)中使用的Star Join运算符的反映,将多个操作编排成一个组合操作是一个关键的优化策略。
内存管理
我们进行了一个实验,以检查两种不同的内存管理方法在执行所有22个TPC-H查询时如何影响查询性能。第一种方法是RateupDB旧的解决方案,仅使用“内存管理“,第二种方法是RateupDB的新解决方案,使用AlphaCache。在这个实验中,AlphaCache占据了GPU设备内存的50%,即24GB。图4显示了新解决方案相对于旧解决方案在所有22个查询中的加速比,显示大多数查询的执行速度显著加快,平均加速比为1.22倍。
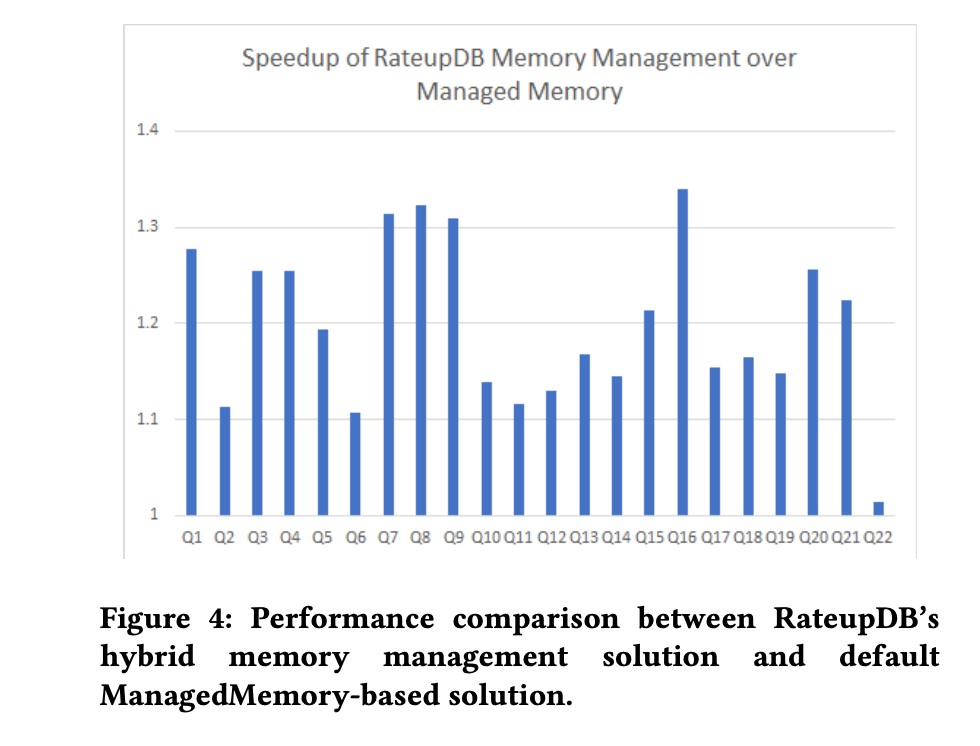
Figure 4: Performance comparison between RateupDB’s hybrid memory management solution and default ManagedMemory-based solution.
使用“内存管理“,GPU的虚拟机机制会自动管理中间数据和输入表数据的查询处理。然而,这种方法的缺点是数据库无法控制这两种数据之间的内存空间争用。通过新的解决方案,我们明确将内存空间划分为表区域(AlphaCache)用于缓存共享表数据,以及工作区域用于存储非共享的查询中间数据。因此,在查询执行过程中,我们可以保证中间数据保留在GPU设备内存中,并且缓存替换只会发生在输入表数据之间。
性能表现
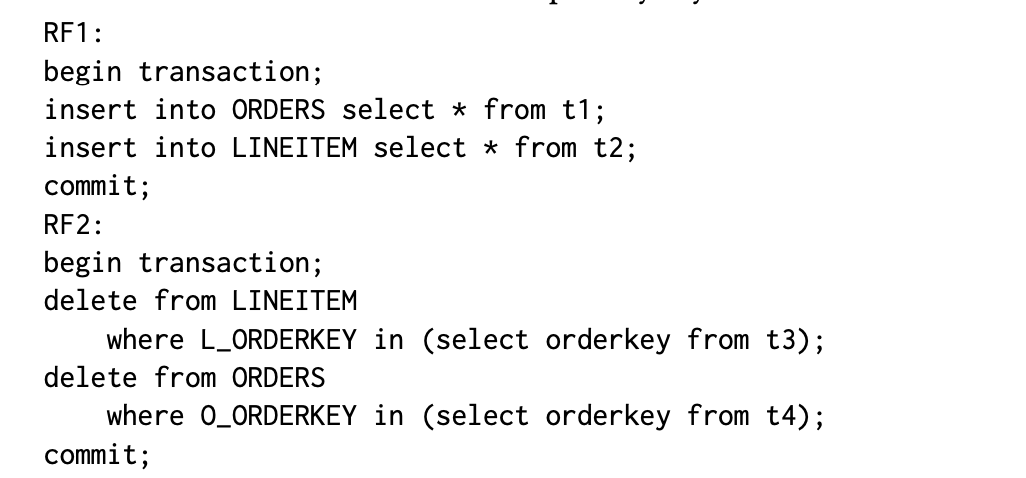
TPC-H要求使用两个刷新函数(RF1和RF2)来执行对ORDEERS和LINEITEM表进行并发插入和删除操作。在RateupDB中,我们使用两个快照隔离事务来实现这两个函数。新插入的数据项和被删除的数据项的键首先存储在几个临时表中,然后由事务使用。RF1和RF2的代码部分展示了它们的逻辑流程,其中t1-t4是临时表。对于TPC-H的规模因子100,被插入或删除的行数为ORDEERS表为15万行,而LINEITEM表为ORDEERS表的1-7倍。我们为这两个表使用主键,但不使用任何连接两个表的外键。这在TPC-H规范中是允许的。在执行RF1时,插入操作将执行额外的主键冲突约束检查。
根据OmniSci的文档,它不支持事务。因此,我们无法将其性能与RateupDB进行比较。此外,目前没有任何GPU加速数据库产品的公开TPC-H结果。因此,我们选择已发布的CPU数据库的性能结果进行比较。由于RateupDB是一个非集群系统,我们选择了TPC网站上相同规模因子(Actian VectorWise 3.0.0)的最快非集群结果。表3列出了两个系统在TPC-H Power Test中执行RF1和RF2的时间,其中事务是独立执行而没有任何干扰。结果显示执行时间是可比较的。然而,考虑到索引构建、约束检查和事务实现等多个因素,两个系统中RF1和RF2的实现不一定相同。
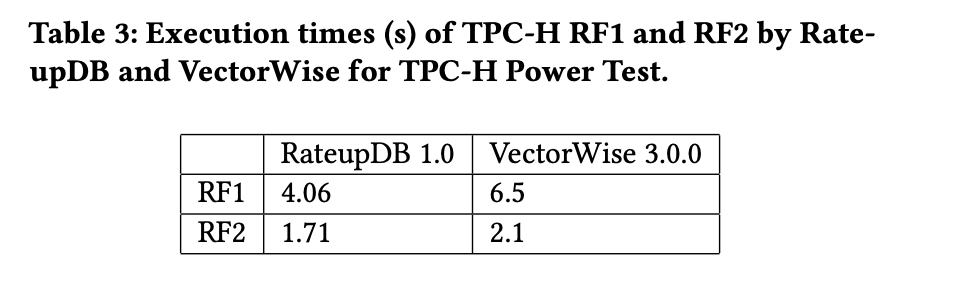
Table 3: Execution times (s) of TPC-H RF1 and RF2 by Rate- upDB and VectorWise for TPC-H Power Test.
RateupDB for Complete TPC-H Test
在介绍了OLAP性能和事务性能之后,我们现在可以探讨RateupDB如何处理同时包含OLAP和OLTP操作的混合工作负载。我们使用完整的、行业标准的TPC-H基准测试作为工作负载,与各种研究文献中常用的性能特征工作负载相比,它具有三个明显的特点。首先,其Power Test部分采用严格的顺序执行22个查询。其次,其吞吐量测试部分需要显式的事务执行流和查询执行流,以便检查同时运行OLAP和OLTP的效果。第三,它要求最少数量的并发OLAP查询流,以便查询引擎必须在整体吞吐量和单个查询响应时间之间取得平衡。
表4显示了RateupDB与其他三个数据库系统的完整TPC-H性能对比,这些结果可以在TPC网站上公开获取。我们选择了(1)最快的一个(EXASOL EXASolution 5.0),不考虑硬件配置,(2)最快的单节点非集群系统(Actian VectorWise 3.0.0),以及(3)最近发布的与规模相匹配的一个(Goldilocks v3.1)。与这三个仅使用CPU的数据库系统相比,RateupDB目前处于高度优化的分析数据库(即VectorWise)和混合数据库(即Goldilocks)之间。由于篇幅限制,详细分析超出了本文的范围。表4中的RateupDB的TPC-H性能受到其未经优化的定点算术实现和单个GPU设备的使用的限制。
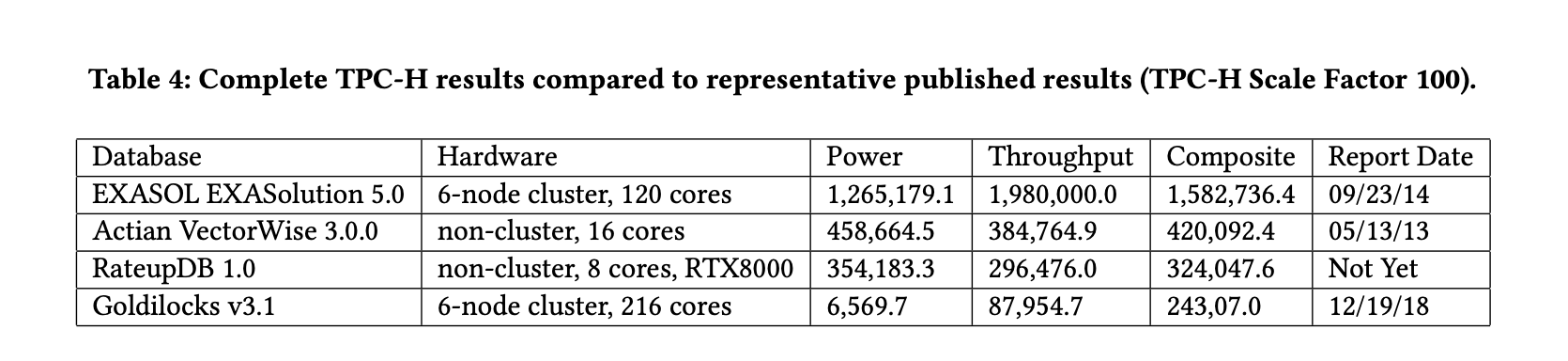
Table 4: Complete TPC-H results compared to representative published results (TPC-H Scale Factor 100).
相反观点的说明
我们遵循一种批判性思维的风格,通过讨论谬误和陷阱[54, 60]来基于我们在构建RateupDB过程中的经验所得到的关于重要问题的教训和见解。
谬误
- 谬误(1):算法在产品中的采用仅取决于其性能。实际上,算法的选择取决于底层系统和开发成本。具体而言,我们必须考虑多个因素,包括执行性能、适应不同动态情况(如数据分布和硬件参数)、实现的简易性以及与其他系统组件的解耦程度。另一个挑战是制定清晰且经得起考验的规则,以判断在什么条件下应该使用该算法。
- 谬误(2):HTAP数据库管理系统只需要统一的混合数据格式。尽管存在各种统一的混合数据格式,将行存储和列存储的优点结合起来,但异构HTAP(H2TAP)数据库管理系统的兴起给数据存储带来了新的挑战,包括硬件效率、性能隔离和工程成本等一系列新要求。正如一些行业级HTAP数据库产品所展示的那样,分区、多阶段和组合的数据存储可以有效地支持混合工作负载,特别是在GPU加速系统中。
- 谬误(3):GPU数据库管理系统的性能仅取决于如何在GPU上执行数据库操作。现有的研究导向的GPU数据库项目通常关注如何最佳利用GPU加速某些数据库操作。然而,显著的性能改进通常是在数据库的逻辑层面上进行的,这与GPU的实现无关。TPC-H Q21就是一个例子,它展示了最佳利用查询内相关信息的好处。
陷阱
- 陷阱(1):确定何时使用算法比如何实现算法更困难。查询优化的角色已经研究了几十年,但仍存在未解决的问题。在一个统一的成本函数中考虑多个因素来估计物理运算符的执行成本。然而,由于存在不同的动态因素,实现这个目标是一项非常困难的任务。RateupDB的经验倾向于避免这个问题(如果可能的话),而不是直接解决它。
- 陷阱(2):GPU查询性能与底层数据类型密切相关。GPU数据类型的实现必须考虑存储开销和计算效率。CUDA原始数据类型和用户定义的复杂数据类型的性能差异很大,例如十进制类型,它需要固定点算术运算,而不是GPU固有的浮点支持。如果不考虑数据类型的实现而比较GPU性能,可能会得出误导性的结论。
- 陷阱(3):GPU查询引擎不能仅依赖于封装各种CUDA库。Nvidia CUDA生态系统的快速发展提供了有效的功能,例如统一内存API和其他库函数(如CUB或Thrust)。然而,这些CUDA库无法完全满足完整数据库的关键需求,例如处理任意大小和类型的数据。GPU查询引擎应该有自己的解决方案,而不仅仅依赖于CUDA库。
- 陷阱(4):先进的GPU虚拟机设施不足以管理设备内存的局部性。设备内存和主机内存之间的分离给GPU内存管理带来了挑战。仅使用GPU的虚拟机设施的查询引擎可能会出现无法控制的性能下降。RateupDB的解决方案是手动管理设备内存空间,以实现数据局部性和查询性能的优化。
综述
我们对RateupDB进行了全面的研究,这是一个面向CPU/GPU的高性能数据库系统,适用于OLAP和OLTP工作负载。本文的一个重要贡献是确定了RateupDB的设计和实现中的大量可能性,旨在证明设计和实现中的平衡之道。基于我们的产品开发经验,我们对多个谬误和陷阱进行了一系列重要的讨论。据我们所知,这是第一篇系统地解释GPU HTAP系统设计和实现以及通过行业标准数据库基准测试(TPC-H)进行整体性能评估的论文。我们相信,我们构建和评估RateupDB的经验将有益于学术界和工业界的高性能数据库的研究和开发。
参考
[1] [n.d.]. BigQuery ML. https://cloud.google.com/bigquery-ml/docs/introduction
[2] [n.d.]. Brytlyt. https://www.brytlyt.com/
[3] [n.d.]. CUB. https://nvlabs.github.io/cub/ [4] [n.d.]. HeteroDB. https://www.heterodb.com [5] [n.d.].IntroducingAresDB:Uber’sGPU-PoweredOpenSource,Real-timeAnalytics Engine. https://eng.uber.com/aresdb/ [6] [n.d.]. Kinetica. https://www.kinetica.com/ [7] [n.d.]. Nvidia Quadro RTX 8000. https://www.nvidia.com/en-us/design- visualization/quadro/rtx- 8000/ [8] [n.d.]. NVLINK AND NVSWITCH. https://www.nvidia.com/en-us/data-center/ nvlink/ [9] [n.d.]. OmniSci. https://www.omnisci.com/ [10] [n.d.]. SQream. https://www.sqream.com/ [11] [n.d.]. TPC-H. http://tpc.org/tpch/default5.asp [12] [n.d.]. USPS Deploys Kinetica to Optimize its Business Operations. https://www.kinetica.com/wp-content/uploads/2016/12/Kinetica_CaseStudy_ USPS_1.0_WEB.pdf [13] Daniel J Abadi, Samuel R Madden, and Nabil Hachem. 2008. Column-stores vs. row-stores: how different are they really?. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data. 967–980. [14] Athena Ahmadi, Alexander Behm, Nagesh Honnalli, Chen Li, Lingjie Weng, and Xiaohui Xie. 2012. Hobbes: optimized gram-based methods for efficient read alignment. Nucleic acids research 40, 6 (2012), e41–e41. [15] AnastassiaAilamaki,DavidJDeWitt,MarkDHill,andMariosSkounakis.2001. Weaving Relations for Cache Performance.. In VLDB, Vol. 1. 169–180. [16] Ablimit Aji, George Teodoro, and Fusheng Wang. 2014. Haggis: turbocharge a MapReduce based spatial data warehousing system with GPU engine. In Proceedings of the 3rd ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data. 15–20. [17] Martina-CezaraAlbutiu,AlfonsKemper,andThomasNeumann.2012.Massively Parallel Sort-Merge Joins in Main Memory Multi-Core Database Systems. Proc. VLDB Endow. 5, 10 (June 2012), 1064–1075. [18] RajaAppuswamy,ManosKarpathiotakis,DanicaPorobic,andAnastasiaAila- maki. 2017. The case for heterogeneous HTAP. In 8th Biennial Conference on Innovative Data Systems Research. [19] Manos Athanassoulis, Michael S Kester, Lukas M Maas, Radu Stoica, Stratos Idreos, Anastasia Ailamaki, and Mark Callaghan. 2016. Designing Access Meth- ods: The RUM Conjecture.. In EDBT, Vol. 2016. 461–466. [20] Rachata Ausavarungnirun, Joshua Landgraf, Vance Miller, Saugata Ghose, Jayneel Gandhi, Christopher J Rossbach, and Onur Mutlu. 2017. Mosaic: a GPU memory manager with application-transparent support for multiple page sizes. In Proceedings of the 50th Annual IEEE/ACM International Symposium on Microarchitecture. 136–150. [21] Cagri Balkesen, Gustavo Alonso, Jens Teubner, and M Tamer Özsu. 2013. Multi- core, main-memory joins: Sort vs. hash revisited. Proceedings of the VLDB Endowment 7, 1 (2013), 85–96. [22] NagenderBandi,ChengyuSun,DivyakantAgrawal,andAmrElAbbadi.2004. Hardware acceleration in commercial databases: A case study of spatial opera- tions. In Proceedings of the Thirtieth international conference on Very large data bases-Volume 30. 1021–1032. [23] Srikanth Bellamkonda, Rafi Ahmed, Andrew Witkowski, Angela Amor, Mo- hamed Zait, and Chun-Chieh Lin. 2009. Enhanced subquery optimizations in oracle. Proceedings of the VLDB Endowment 2, 2 (2009), 1366–1377. [24] HalBerenson,PhilBernstein,JimGray,JimMelton,ElizabethO’Neil,andPatrick O’Neil. 1995. A critique of ANSI SQL isolation levels. ACM SIGMOD Record 24, 2 (1995), 1–10. [25] Spyros Blanas, Yinan Li, and Jignesh M Patel. 2011. Design and evaluation of main memory hash join algorithms for multi-core CPUs. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of data. 37–48. [26] PeterBoncz,ThomasNeumann,andOrriErling.2013.TPC-Hanalyzed:Hidden messages and lessons learned from an influential benchmark. In Technology Conference on Performance Evaluation and Benchmarking. Springer, 61–76. [27] Peter A Boncz, Stefan Manegold, Martin L Kersten, et al. 1999. Database ar- chitecture optimized for the new bottleneck: Memory access. In VLDB, Vol. 99. 54–65. [28] Sebastian Breß. 2014. The design and implementation of CoGaDB: A column- oriented GPU-accelerated DBMS. Datenbank-Spektrum 14, 3 (2014), 199–209. [29] Zhichao Cao, Siying Dong, Sagar Vemuri, and David HC Du. 2020. Character- izing, modeling, and benchmarking rocksdb key-value workloads at facebook. In 18th {USENIX} Conference on File and Storage Technologies ({FAST} 20). 209–223. [30] Jatin Chhugani, Anthony D Nguyen, Victor W Lee, William Macy, Mostafa Hagog, Yen-Kuang Chen, Akram Baransi, Sanjeev Kumar, and Pradeep Dubey. 2008. Efficient implementation of sorting on multi-core SIMD CPU architecture. Proceedings of the VLDB Endowment 1, 2 (2008), 1313–1324. [31] Steven WD Chien, Ivy B Peng, and Stefano Markidis. 2019. Performance evaluation of advanced features in CUDA unified memory. arXiv preprint
[32] EshaChoukse,MichaelBSullivan,MikeO’Connor,MattanErez,JeffPool,David Nellans, and Stephen W Keckler. 2020. Buddy compression: Enabling larger memory for deep learning and HPC workloads on gpus. In 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA). IEEE, 926–939. [33] UmeshwarDayal,MaluCastellanos,AlkisSimitsis,andKevinWilkinson.2009. Data integration flows for business intelligence. In Proceedings of the 12th Inter- national Conference on Extending Database Technology: Advances in Database Technology. 1–11. [34] JustinDeBrabant,AndrewPavlo,StephenTu,MichaelStonebraker,andStan Zdonik. 2013. Anti-caching: A new approach to database management system architecture. Proceedings of the VLDB Endowment 6, 14 (2013), 1942–1953. [35] Harish Doraiswamy and Juliana Freire. 2020. A gpu-friendly geometric data model and algebra for spatial queries. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 1875–1885. [36] Songyun Duan, Vamsidhar Thummala, and Shivnath Babu. 2009. Tuning data- base configuration parameters with iTuned. Proceedings of the VLDB Endowment 2, 1 (2009), 1246–1257. [37] MostafaElhemali,CésarAGalindo-Legaria,TorstenGrabs,andMilindMJoshi. 2007. Execution strategies for SQL subqueries. In Proceedings of the 2007 ACM SIGMOD international conference on Management of data. 993–1004. [38] Wenbin Fang, Bingsheng He, and Qiong Luo. 2010. Database compression on graphics processors. Proceedings of the VLDB Endowment 3, 1-2 (2010), 670–680. [39] FranzFärber,SangKyunCha,JürgenPrimsch,ChristofBornhövd,StefanSigg, and Wolfgang Lehner. 2012. SAP HANA database: data management for modern business applications. ACM Sigmod Record 40, 4 (2012), 45–51. [40] AlanFekete,DimitriosLiarokapis,ElizabethO’Neil,PatrickO’Neil,andDennis Shasha. 2005. Making snapshot isolation serializable. ACM Transactions on Database Systems (TODS) 30, 2 (2005), 492–528. [41] SofoklisFloratos,MengbaiXiao,HaoWang,ChengxinGuo,YuanYuan,Rubao Lee, and Xiaodong Zhang. 2021. Nestgpu: Nested query processing on gpu. In 2021 IEEE 37th International Conference on Data Engineering (ICDE). IEEE, 1008–1019. [42] Phil Francisco. 2011. IBM PureData System for Analytics Architecture A Platform for High Performance Data Warehousing and Analytics. In https://www.redbooks.ibm.com/redpapers/pdfs/redp4725.pdf. [43] HenningFunke,SebastianBreß,StefanNoll,VolkerMarkl,andJensTeubner. 2018. Pipelined query processing in coprocessor environments. In Proceedings of the 2018 International Conference on Management of Data. 1603–1618. [44] Henning Funke and Jens Teubner. 2020. Data-parallel query processing on non-uniform data. Proceedings of the VLDB Endowment 13, 6 (2020), 884–897. [45] OdedGreen,RobertMcColl,andDavidABader.2012.GPUmergepath:aGPU merging algorithm. In Proceedings of the 26th ACM international conference on Supercomputing. 331–340. [46] Stephen Lien Harrell, Joy Kitson, Robert Bird, Simon John Pennycook, Jason Sewall, Douglas Jacobsen, David Neill Asanza, Abaigail Hsu, Hector Carrillo Carrillo, Hessoo Kim, et al. 2018. Effective performance portability. In 2018 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC). IEEE, 24–36. [47] Mark Harris. 2017. Unified Memory for CUDA Beginners. In https://developer.nvidia.com/blog/unified-memory-cuda-beginners/. [48] BingshengHe,MianLu,KeYang,RuiFang,NagaKGovindaraju,QiongLuo, and Pedro V Sander. 2009. Relational query coprocessing on graphics processors. ACM Transactions on Database Systems (TODS) 34, 4 (2009), 1–39. [49] BingshengHe,KeYang,RuiFang,MianLu,NagaGovindaraju,QiongLuo,and Pedro Sander. 2008. Relational joins on graphics processors. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data. ACM, 511–524. [50] BingshengHeandJeffreyXuYu.2011.High-ThroughputTransactionExecutions on Graphics Processors. Proceedings of the VLDB Endowment 4, 5 (2011). [51] YongqiangHe,RubaoLee,YinHuai,ZhengShao,NamitJain,XiaodongZhang, and Zhiwei Xu. 2011. RCFile: A fast and space-efficient data placement struc- ture in MapReduce-based warehouse systems. In 2011 IEEE 27th International Conference on Data Engineering. IEEE, 1199–1208. [52] MaxHeimelandVolkerMarkl.2012.AFirstStepTowardsGPU-assistedQuery Optimization. ADMS@ VLDB 2012 (2012), 33–44. [53] MaxHeimel,MichaelSaecker,HolgerPirk,StefanManegold,andVolkerMarkl. 2013. Hardware-oblivious parallelism for in-memory column-stores. Proceedings of the VLDB Endowment 6, 9 (2013), 709–720. [54] John L Hennessy and David A Patterson. 2018. Computer architecture: a quanti- tative approach, 6th edition. Elsevier. [55] Herodotos Herodotou, Yuxing Chen, and Jiaheng Lu. 2020. A survey on au- tomatic parameter tuning for big data processing systems. ACM Computing Surveys (CSUR) 53, 2 (2020), 1–37. [56] Tayler H Hetherington, Mike O’Connor, and Tor M Aamodt. 2015. Mem- cachedgpu: Scaling-up scale-out key-value stores. In Proceedings of the Sixth ACM Symposium on Cloud Computing. 43–57. [57] Yin Huai, Ashutosh Chauhan, Alan Gates, Gunther Hagleitner, Eric N Hanson, Owen O’Malley, Jitendra Pandey, Yuan Yuan, Rubao Lee, and Xiaodong Zhang. 2014. Major technical advancements in apache hive. In Proceedings of the 2014 ACM SIGMOD international conference on Management of data. 1235–1246. [58] YinHuai,SiyuanMa,RubaoLee,OwenO’Malley,andXiaodongZhang.2013. Understanding insights into the basic structure and essential issues of table placement methods in clusters. Proceedings of the VLDB Endowment 6, 14 (2013), 1750–1761. [59] DongxuHuang,QiLiu,QiuCui,ZhuheFang,XiaoyuMa,FeiXu,LiShen,Liu Tang, Yuxing Zhou, Menglong Huang, et al. 2020. TiDB: a Raft-based HTAP database. Proceedings of the VLDB Endowment 13, 12 (2020), 3072–3084. [60] NormanPJouppi,CliffYoung,NishantPatil,DavidPatterson,GauravAgrawal, Raminder Bajwa, Sarah Bates, Suresh Bhatia, Nan Boden, Al Borchers, et al. 2017. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th annual international symposium on computer architecture. 1–12. [61] Tomas Karnagel, René Müller, and Guy M Lohman. 2015. Optimizing GPU- accelerated Group-By and Aggregation. ADMS@ VLDB 8 (2015), 20. [62] Alfons Kemper and Thomas Neumann. 2011. HyPer: A hybrid OLTP&OLAP main memory database system based on virtual memory snapshots. In 2011 IEEE 27th International Conference on Data Engineering. IEEE, 195–206. [63] ChangkyuKim,TimKaldewey,VictorWLee,EricSedlar,AnthonyDNguyen, Nadathur Satish, Jatin Chhugani, Andrea Di Blas, and Pradeep Dubey. 2009. Sort vs. hash revisited: Fast join implementation on modern multi-core CPUs. Proceedings of the VLDB Endowment 2, 2 (2009), 1378–1389. [64] KangnyeonKim,TianzhengWang,RyanJohnson,andIppokratisPandis.2016. Ermia: Fast memory-optimized database system for heterogeneous workloads. In Proceedings of the 2016 International Conference on Management of Data. 1675–1687. [65] Won Kim. 1982. On optimizing an SQL-like nested query. ACM Transactions on Database Systems (TODS) 7, 3 (1982), 443–469. [66] Andreas Kipf, Thomas Kipf, Bernhard Radke, Viktor Leis, Peter Boncz, and Alfons Kemper. 2018. Learned cardinalities: Estimating correlated joins with deep learning. arXiv preprint arXiv:1809.00677 (2018). [67] TimKraska,MohammadAlizadeh,AlexBeutel,HChi,AniKristo,Guillaume Leclerc, Samuel Madden, Hongzi Mao, and Vikram Nathan. 2019. Sagedb: A learned database system. In CIDR. [68] SanjayKrishnan,ZonghengYang,KenGoldberg,JosephHellerstein,andIon Stoica. 2018. Learning to optimize join queries with deep reinforcement learning. arXiv preprint arXiv:1808.03196 (2018). [69] Hsiang-Tsung Kung and John T Robinson. 1981. On optimistic methods for concurrency control. ACM Transactions on Database Systems (TODS) 6, 2 (1981), 213–226. [70] TirthankarLahiri,ShasankChavan,MariaColgan,DineshDas,AmitGanesh, Mike Gleeson, Sanket Hase, Allison Holloway, Jesse Kamp, Teck-Hua Lee, et al. 2015. Oracle database in-memory: A dual format in-memory database. In 2015 IEEE 31st International Conference on Data Engineering. IEEE, 1253–1258. [71] ChoudurLakshminarayan,ThiagarajanRamakrishnan,AwnyAl-Omari,Khaled Bouaziz, Faraz Ahmad, Sri Raghavan, and Prama Agarwal. 2019. Enterprise-wide Machine Learning using Teradata Vantage: An Integrated Analytics Platform. In 2019 IEEE International Conference on Big Data (Big Data). IEEE, 2043–2046. [72] AndrewLamb,MattFuller,RamakrishnaVaradarajan,NgaTran,BenVandier, Lyric Doshi, and Chuck Bear. 2012. The vertica analytic database: C-store 7 years later. arXiv preprint arXiv:1208.4173 (2012). [73] Janghaeng Lee, Mehrzad Samadi, and Scott Mahlke. 2014. VAST: The illusion of a large memory space for GPUs. In 2014 23rd International Conference on Parallel Architecture and Compilation Techniques (PACT). IEEE, 443–454. [74] RubaoLee,XiaoningDing,FengChen,QingdaLu,andXiaodongZhang.2009. MCC-DB: Minimizing cache conflicts in multi-core processors for databases. Proceedings of the VLDB Endowment 2, 1 (2009), 373–384. [75] RubaoLee,TianLuo,YinHuai,FushengWang,YongqiangHe,andXiaodong Zhang. 2011. Ysmart: Yet another sql-to-mapreduce translator. In 2011 31st International Conference on Distributed Computing Systems. IEEE, 25–36. [76] Jyoti Leeka and Kaushik Rajan. 2019. Incorporating super-operators in big-data query optimizers. Proceedings of the VLDB Endowment 13, 3 (2019), 348–361. [77] ViktorLeis,AndreyGubichev,AtanasMirchev,PeterBoncz,AlfonsKemper,and Thomas Neumann. 2015. How good are query optimizers, really? Proceedings of the VLDB Endowment 9, 3 (2015), 204–215. [78] JingLi,Hung-WeiTseng,ChunbinLin,YannisPapakonstantinou,andSteven Swanson. 2016. Hippogriffdb: Balancing i/o and gpu bandwidth in big data analytics. Proceedings of the VLDB Endowment 9, 14 (2016), 1647–1658. [79] Yanhui Liang, Hoang Vo, Ablimit Aji, Jun Kong, and Fusheng Wang. 2016. Scalable 3d spatial queries for analytical pathology imaging with mapreduce. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems. 1–4. [80] Chi-ManLiu,ThomasWong,EdwardWu,RuibangLuo,Siu-MingYiu,Yingrui Li, Bingqiang Wang, Chang Yu, Xiaowen Chu, Kaiyong Zhao, et al. 2012. SOAP3: ultra-fast GPU-based parallel alignment tool for short reads. Bioinformatics 28, 6 (2012), 878–879.
[81] DarkoMakreshanski,JanaGiceva,ClaudeBarthels,andGustavoAlonso.2017. BatchDB: Efficient isolated execution of hybrid OLTP+ OLAP workloads for interactive applications. In Proceedings of the 2017 ACM International Conference on Management of Data. 37–50.
[82] RyanMarcus,ParimarjanNegi,HongziMao,ChiZhang,MohammadAlizadeh, Tim Kraska, Olga Papaemmanouil, and Nesime Tatbul23. 2019. Neo: A Learned Query Optimizer. Proceedings of the VLDB Endowment 12, 11 (2019), 1705–1718.
[83] Andreas Meister. 2015. GPU-accelerated join-order optimization. In The VLDB PhD workshop, PVLDB, Vol. 176. 1.
[84] Todd Mostak. 2013. An overview of MapD (massively parallel database). White paper. Massachusetts Institute of Technology (2013).
[85] Thomas Neumann. 2015. The price of correctness. In http://databasearchitects.blogspot.com/2015/12/the-price-of-correctness.html.
[86] Thomas Neumann and Alfons Kemper. 2015. Unnesting arbitrary queries. Datenbanksysteme für Business, Technologie und Web (BTW 2015) (2015). [87] Saher Odeh, Oded Green, Zahi Mwassi, Oz Shmueli, and Yitzhak Birk. 2012. Merge path-parallel merging made simple. In 2012 IEEE 26th International Parallel and Distributed Processing Symposium Workshops & PhD Forum. IEEE, 1611– 1618.
[88] ChristopherOlston,BenjaminReed,UtkarshSrivastava,RaviKumar,andAn- drew Tomkins. 2008. Pig latin: a not-so-foreign language for data processing. In Proceedings of the 2008 ACM SIGMOD international conference on Management of data. 1099–1110. [89] John Ousterhout, Parag Agrawal, David Erickson, Christos Kozyrakis, Jacob Leverich, David Mazières, Subhasish Mitra, Aravind Narayanan, Guru Parulkar, Mendel Rosenblum, et al. 2010. The case for RAMClouds: scalable high- performance storage entirely in DRAM. ACM SIGOPS Operating Systems Review 43, 4 (2010), 92–105.
[90] JohnsPaul,BingshengHe,ShengliangLu,andChiewTongLau.2020.Improving execution efficiency of just-in-time compilation based query processing on GPUs. Proceedings of the VLDB Endowment 14, 2 (2020), 202–214.
[91] SukhadaPendse,VasudhaKrishnaswamy,KartikKulkarni,YunruiLi,Tirthankar Lahiri, Vivekanandhan Raja, Jing Zheng, Mahesh Girkar, and Akshay Kulkarni. 2020. Oracle Database In-Memory on Active Data Guard: Real-time Analytics on a Standby Database. In 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 1570–1578. [92] Simon J Pennycook, Jason D Sewall, and Victor W Lee. 2016. A metric for performance portability. arXiv preprint arXiv:1611.07409 (2016).
[93] AnQin,MengbaiXiao,JinMa,DaiTan,RubaoLee,andXiaodongZhang.2019. DirectLoad: A Fast Web-scale Index System across Large Regional Centers. In 2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 1790–1801.
[94] AnQin,YuanYuan,DaiTan,PengyuSun,XiangZhang,HaoCao,RubaoLee, and Xiaodong Zhang. 2017. Feisu: Fast Query Execution over Heterogeneous Data Sources on Large-Scale Clusters. In 2017 IEEE 33rd International Conference on Data Engineering (ICDE). IEEE, 1173–1182.
[95] SyedMohammadAunnRaza,PeriklisChrysogelos,PanagiotisSioulas,Vladimir Indjic, Angelos Christos Anadiotis, and Anastasia Ailamaki. 2020. GPU- accelerated data management under the test of time. In Online proceedings of the 10th Conference on Innovative Data Systems Research (CIDR).
[96] LucasCVillaRealandBrunoSilva.2018.FullSpeedAhead:3DSpatialDatabase Acceleration with GPUs. Proceedings of the VLDB Endowment 11, 9 (2018).
[97] RanRui,HaoLi,andYi-ChengTu.2021.EficientJoinAlgorithmsForLargeData- base Tables in a Multi-GPU Environment. Proceedings of the VLDB Endowment 14 (2021). [98] Ran Rui and Yi-Cheng Tu. 2017. Fast equi-join algorithms on gpus: Design and implementation. In Proceedings of the 29th international conference on scientific and statistical database management. 1–12. [99] Anil Shanbhag, Samuel Madden, and Xiangyao Yu. 2020. A Study of the Funda- mental Performance Characteristics of GPUs and CPUs for Database Analytics. In Proceedings of the 2020 ACM SIGMOD international conference on Management of data. 1617–1632. [100] Vishal Sikka, Franz Färber, Wolfgang Lehner, Sang Kyun Cha, Thomas Peh, and Christof Bornhövd. 2012. Efficient transaction processing in SAP HANA database: the end of a column store myth. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. 731–742.
[101] Panagiotis Sioulas, Periklis Chrysogelos, Manos Karpathiotakis, Raja Ap- puswamy, and Anastasia Ailamaki. 2019. Hardware-conscious hash-joins on gpus. In 2019 IEEE 35th International Conference on Data Engineering (ICDE). IEEE, 698–709. [102] Elias Stehle and Hans-Arno Jacobsen. 2017. A memory bandwidth-efficient hybrid radix sort on gpus. In Proceedings of the 2017 ACM International Conference on Management of Data. 417–432. [103] MikeStonebraker,DanielJAbadi,AdamBatkin,XuedongChen,MitchCher- niack, Miguel Ferreira, Edmond Lau, Amerson Lin, Sam Madden, Elizabeth O’Neil, et al. 2005. C-store: a column-oriented DBMS. In Proceedings of the 31st international conference on Very large data bases. 553–564.
[104] Ji Sun and Guoliang Li. 2019. An End-to-End Learning-based Cost Estimator. Proceedings of the VLDB Endowment 13, 3 (2019), 307–319. [105] Diego G Tomé, Tim Gubner, Mark Raasveldt, Eyal Rozenberg, and Peter A Boncz. 2018. Optimizing Group-By and Aggregation using GPU-CPU Co-Processing.. In ADMS@ VLDB. 1–10. [106] Luan Tran, Min Y Mun, and Cyrus Shahabi. 2020. Real-time distance-based outlier detection in data streams. Proceedings of the VLDB Endowment 14, 2 (2020), 141–153. [107] Immanuel Trummer, Junxiong Wang, Deepak Maram, Samuel Moseley, Saehan Jo, and Joseph Antonakakis. 2019. Skinnerdb: Regret-bounded query evaluation via reinforcement learning. In Proceedings of the 2019 International Conference on Management of Data. 1153–1170. [108] Stephen Tu, Wenting Zheng, Eddie Kohler, Barbara Liskov, and Samuel Madden. 2013. Speedy transactions in multicore in-memory databases. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles. 18–32. [109] Kaibo Wang, Xiaoning Ding, Rubao Lee, Shinpei Kato, and Xiaodong Zhang. 2014. GDM: Device memory management for GPGPU computing. ACM SIG- METRICS Performance Evaluation Review 42, 1 (2014), 533–545. [110] Kaibo Wang, Yin Huai1 Rubao Lee, Fusheng Wang, Xiaodong Zhang, and Joel H Saltz. 2012. Accelerating Pathology Image Data Cross-Comparison on CPU-GPU Hybrid Systems. Proceedings of the VLDB Endowment 5, 11 (2012). [111] Kaibo Wang, Kai Zhang, Yuan Yuan, Siyuan Ma, Rubao Lee, Xiaoning Ding, and Xiaodong Zhang. 2014. Concurrent analytical query processing with GPUs. Proceedings of the VLDB Endowment 7, 11 (2014), 1011–1022. [112] Wei Wang, Meihui Zhang, Gang Chen, HV Jagadish, Beng Chin Ooi, and Kian- Lee Tan. 2016. Database meets deep learning: Challenges and opportunities. ACM SIGMOD Record 45, 2 (2016), 17–22.
[113] Haicheng Wu, Gregory Diamos, Tim Sheard, Molham Aref, Sean Baxter, Michael Garland, and Sudhakar Yalamanchili. 2014. Red fox: An execution environment for relational query processing on gpus. In Proceedings of Annual IEEE/ACM International Symposium on Code Generation and Optimization. 44–54.
[114] Xiang Yu, Guoliang Li, Chengliang Chai, and Nan Tang. 2020. Reinforcement learning with tree-lstm for join order selection. In 2020 IEEE 36th International Conference on Data Engineering (ICDE). IEEE, 1297–1308. [115] Yuan Yuan, Rubao Lee, and Xiaodong Zhang. 2013. The Yin and Yang of pro- cessing data warehousing queries on GPU devices. Proceedings of the VLDB Endowment 6, 10 (2013), 817–828.
[116] Yuan Yuan, Meisam Fathi Salmi, Yin Huai, Kaibo Wang, Rubao Lee, and Xiaodong Zhang. 2016. Spark-GPU: An accelerated in-memory data processing engine on clusters. In 2016 IEEE International Conference on Big Data (Big Data). IEEE, 273–283.
[117] Yuan Yuan, Kaibo Wang, Rubao Lee, Xiaoning Ding, Jing Xing, Spyros Blanas, and Xiaodong Zhang. 2016. Bcc: Reducing false aborts in optimistic concur- rency control with low cost for in-memory databases. Proceedings of the VLDB Endowment 9, 6 (2016), 504–515.
[118] Matei Zaharia, Mosharaf Chowdhury, Michael J Franklin, Scott Shenker, and Ion Stoica. 2010. Spark: cluster computing with working sets. In Proceedings of the 2nd USENIX conference on Hot topics in cloud computing. 10–10. [119] Chaoqun Zhan, Maomeng Su, Chuangxian Wei, Xiaoqiang Peng, Liang Lin, Sheng Wang, Zhe Chen, Feifei Li, Yue Pan, Fang Zheng, et al. 2019. Analyticdb: Real-time olap database system at alibaba cloud. Proceedings of the VLDB Endowment 12, 12 (2019), 2059–2070.
[120] Hao Zhang, Gang Chen, Beng Chin Ooi, Kian-Lee Tan, and Meihui Zhang. 2015. In-memory big data management and processing: A survey. IEEE Transactions on Knowledge and Data Engineering 27, 7 (2015), 1920–1948. [121] Kai Zhang, Kaibo Wang, Yuan Yuan, Lei Guo, Rubao Lee, and Xiaodong Zhang. 2015. Mega-kv: A case for gpus to maximize the throughput of in-memory key-value stores. Proceedings of the VLDB Endowment 8, 11 (2015), 1226–1237.
[122] Tianhao Zheng, David Nellans, Arslan Zulfiqar, Mark Stephenson, and Stephen W Keckler. 2016. Towards high performance paged memory for GPUs. In 2016 IEEE International Symposium on High Performance Computer Architec- ture (HPCA). IEEE, 345–357.
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文系外文翻译,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号