YOLOv5改进---注意力机制:DoubleAttention注意力,SENet进阶版本
原创
YOLOv5改进---注意力机制:DoubleAttention注意力,SENet进阶版本
原创
AI小怪兽
发布于 2023-11-30 15:40:52
发布于 2023-11-30 15:40:52
摘要:DoubleAttention注意力助力YOLOv5,即插即用,性能优于SENet
1. DoubleAttention

论文: https://arxiv.org/pdf/1810.11579.pdf
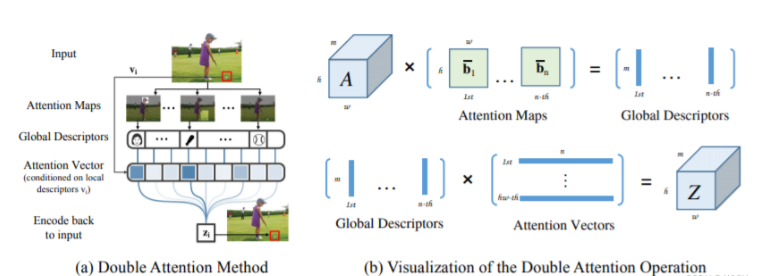
DoubleAttention网络结构是一种用于计算机视觉领域的深度学习网络结构,主要用于图像的分割和识别任务。该网络结构采用双重注意力机制,包括Spatial Attention和Channel Attention。Spatial Attention用于捕获图像中不同空间位置的重要性,而Channel Attention用于捕获图像中不同通道的重要性。
本文贡献:
- 这次是复现NeurIPS2018的一篇论文,本论文也是非常的简单呢,是一个涨点神器,也是一个即插即用的小模块。
- 本文的主要创新点是提出了一个新的注意力机制,你可以看做SE的进化版本,在各CV任务测试性能如下
1.1 加入 common.py中
###################### DoubleAttention #### end by AI&CV ###############################
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
###################### DoubleAttention #### end by AI&CV ###############################1.2 加入yolo.py中:
elif m is DoubleAttention:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, *args[1:]]1.3 yolov5s_DoubleAttention.yaml
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, DoubleAttention, [1024]], # 24
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
by CSDN AI小怪兽 http://cv2023.blog.csdn.net
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号